Python selenium+phantomjs的js动态爬取
Selenium是一个用于Web应用程序测试的工具。Selenium测试直接运行在浏览器中,就像真正的用户在操作一样。支持的浏览器包括IE、Mozilla Firefox、Chrome等。
Phantom JS是一个服务器端的 JavaScript API 的 WebKit。其支持各种Web标准: DOM 处理, CSS 选择器, JSON, Canvas, 和 SVG。
基于js动态加载内容爬取的另一种方法——模拟浏览器
安装过程略。
下面写上最简单基础的
from selenium import webdriver
driver = webdriver.PhantomJS()
driver.get('http://www.baidu.com/')
print driver.title
driver.quit()
输出结果:
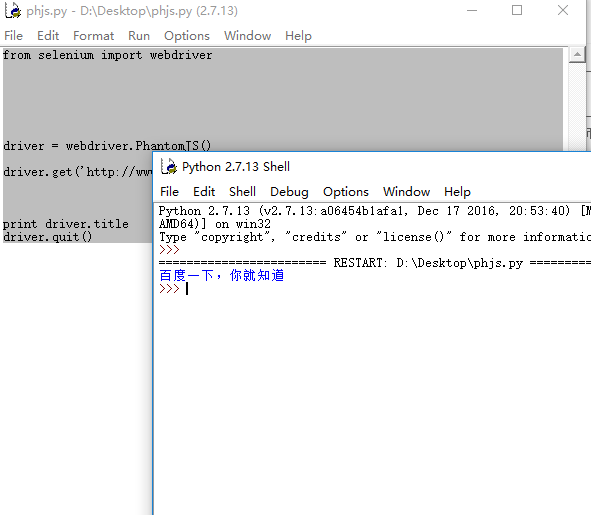
这样最基本的实现能解决了。
参考
http://www.cnblogs.com/front-Thinking/p/4321720.html
http://blog.csdn.net/qinglu000/article/details/52240508
——————
遇到问题————phantomjs没有输出,输出看不到内容
fromseleniumimportwebdriver importsys
reload(sys)
sys.setdefaultencoding('utf-8') driver=webdriver.PhantomJS() #这要可能需要制定phatomjs可执行文件的位置
driver.get("http://www.ip.cn/125.95.26.81")
#print driver.current_url
#print driver.page_source
printdriver.find_element_by_id('result').text.split('\n')[0].split('来自:')[1]
driver.quit
就是像开始因为编码问题加入这几行代码,输出看不到内容,一直以为哪里出错了,一番折腾删除后正常显示。
importsys
reload(sys)
sys.setdefaultencoding('utf-8')
Python selenium+phantomjs的js动态爬取的更多相关文章
- 学习用java基于webMagic+selenium+phantomjs实现爬虫Demo爬取淘宝搜索页面
由于业务需要,老大要我研究一下爬虫. 团队的技术栈以java为主,并且我的主语言是Java,研究时间不到一周.基于以上原因固放弃python,选择java为语言来进行开发.等之后有时间再尝试pytho ...
- Python爬虫(二十)_动态爬取影评信息
本案例介绍从JavaScript中采集加载的数据.更多内容请参考:Python学习指南 #-*- coding:utf-8 -*- import requests import re import t ...
- python爬虫:了解JS加密爬取网易云音乐
python爬虫:了解JS加密爬取网易云音乐 前言 大家好,我是"持之以恒_liu",之所以起这个名字,就是希望我自己无论做什么事,只要一开始选择了,那么就要坚持到底,不管结果如何 ...
- Node.js 爬虫爬取电影信息
Node.js 爬虫爬取电影信息 我的CSDN地址:https://blog.csdn.net/weixin_45580251/article/details/107669713 爬取的是1905电影 ...
- Python爬虫学习三------requests+BeautifulSoup爬取简单网页
第一次第一次用MarkDown来写博客,先试试效果吧! 昨天2018俄罗斯世界杯拉开了大幕,作为一个伪球迷,当然也得为世界杯做出一点贡献啦. 于是今天就编写了一个爬虫程序将腾讯新闻下世界杯专题的相关新 ...
- 初识python 之 爬虫:使用正则表达式爬取“糗事百科 - 文字版”网页数据
初识python 之 爬虫:使用正则表达式爬取"古诗文"网页数据 的兄弟篇. 详细代码如下: #!/user/bin env python # author:Simple-Sir ...
- selenium模块获得js动态数据-17track为例
通过selenium模块驱动Chrome浏览器,获得js动态数据,以17track为例:通过运单号查询最新的物流信息 1 import re 2 from time import sleep 3 fr ...
- python+selenium+PhantomJS爬取网页动态加载内容
一般我们使用python的第三方库requests及框架scrapy来爬取网上的资源,但是设计javascript渲染的页面却不能抓取,此时,我们使用web自动化测试化工具Selenium+无界面浏览 ...
- python+selenium实现动态爬取及selenuim的常用操作
应用实例可以参考博客中的12306自动抢票应用 https://www.cnblogs.com/mumengyun/p/10001109.html 动态网页数据抓取 什么是AJAX: AJAX(Asy ...
随机推荐
- 09 Scrapy框架在爬虫中的使用
一.简介 Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架.它集成高性能异步下载,队列,分布式,解析,持久化等. Scrapy 是基于twisted框架开发而来,twisted是一个 ...
- poj1273 Drainage Ditches (最大流板子
网络流一直没学,来学一波网络流. https://vjudge.net/problem/POJ-1273 题意:给定点数,边数,源点,汇点,每条边容量,求最大流. 解法:EK或dinic. EK:每次 ...
- 【牛客多校】Han Xin and His Troops
题目: His majesty chatted with Han Xin about the capabilities of the generals. Each had their shortcom ...
- codeforces 389 D. Fox and Minimal path(构造+思维)
题目链接:https://vjudge.net/contest/175446#problem/J 题解:显然要用最多n个点构成的图要使的得到的最短路条数有1e9次个,显然要有几个数相乘容易想到2的几进 ...
- poj 2352 & Ural 1028 数星星 题解
一道水题,由于x坐标递增y坐标也递增于是前缀和统计即可,用树状数组实现. #include<bits/stdc++.h> using namespace std; const int ma ...
- Java获取两个日期之间的所有日期集合
1.返回Date的list private List<Date> getBetweenDates(Date start, Date end) { List<Date> resu ...
- Navicate for mysql如何导入一个sql文件
我在做的项目是宜立方商城的项目,现在需要把见表的sql文件导入到navicate中去,步骤如下: ①新建一个数据库,如下: ②在数据库名字上右键,选择运行sql文件 ③选择如下sql文件 ④刷新之后:
- 个人IP「Android大强哥」上线啦!
自从入职新公司之后就一直忙得不行,一边熟悉开发的流程,一边熟悉各种网站工具的使用,一边又在熟悉业务代码,好长时间都没有更文了. 不过新公司的 mentor(导师)还是很不错的,教给我很多东西,让我也能 ...
- HTML+CSS+JavaScript实现2048小游戏
相信很多人都玩过2048小游戏,规则易懂.操作简单,我曾经也“痴迷”于它,不到2048不罢休,最高成绩合成了4096,现在正好拿它来练练手. 我对于2048的实现,除了使用了现有2048小游戏的配色, ...
- Centos7 C++ 安装使用googletest单元测试
废话不多说,直接开始吧. 环境说明 系统环境:centos7.0 g++ 版本: g++ (GCC) 4.8.5 20150623 (Red Hat 4.8.5-36) 查看方法: g++ -vers ...