集合系列 Map(十五):TreeMap
TreeMap 是 Map 集合的有序实现,其底层是基于红黑树的实现,能够早 log(n) 时间内完成 get、put 和 remove 操作。
public class TreeMap<K,V>
extends AbstractMap<K,V>
implements NavigableMap<K,V>, Cloneable, java.io.Serializable
TreeMap 继承自 AbstractMap,还实现了 NavigableMap接口。NavigableMap 接口继承了SortedMap接口,SortedMap 最终继承自Map接口。整体来说 TreeMap 的继承体系如下图所示。
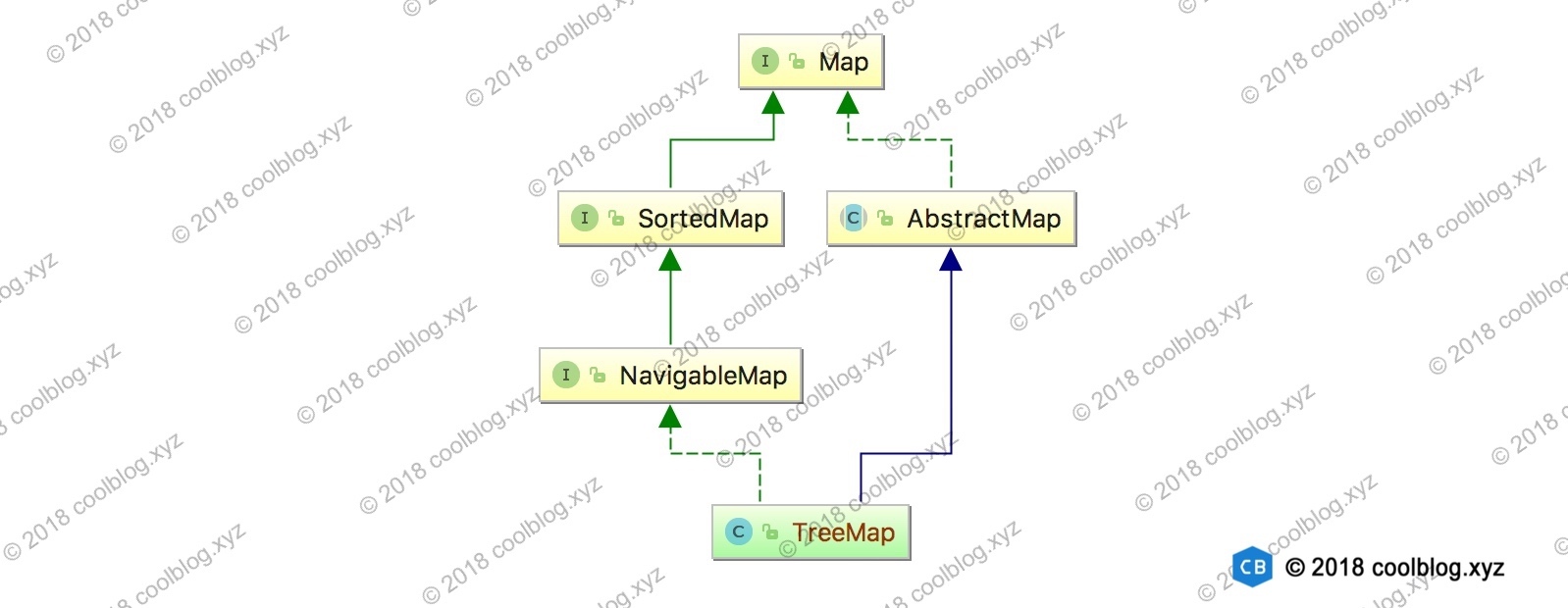
原理
我们将从类成员变量、构造方法、核心方法几个方面来解析 TreeMap 的实现。
类成员变量
// 比较器。根据这个比较器决定TreeMap的排序。
// 如果为空,表示按照key做自然排序(最小的在根节点)。
private final Comparator<? super K> comparator;
// 根节点
private transient Entry<K,V> root;
// 大小
private transient int size = 0;
// Node节点声明
static final class Entry<K,V> implements Map.Entry<K,V> {
K key;
V value;
Entry<K,V> left;
Entry<K,V> right;
Entry<K,V> parent;
boolean color = BLACK;
}
我们可以看到 TreeMap 有一个 Entry 类型的 root 节点,而 Entry 则是 TreeMap 的内部类。从 TreeMap.Entry 的属性我们可以知道其实一个红黑树节点的实现。
构造方法
TeeMap 一共有四个构造方法:
public TreeMap() {
comparator = null;
}
public TreeMap(Comparator<? super K> comparator) {
this.comparator = comparator;
}
public TreeMap(Map<? extends K, ? extends V> m) {
comparator = null;
putAll(m);
}
public TreeMap(SortedMap<K, ? extends V> m) {
comparator = m.comparator();
try {
buildFromSorted(m.size(), m.entrySet().iterator(), null, null);
} catch (java.io.IOException cannotHappen) {
} catch (ClassNotFoundException cannotHappen) {
}
}
核心方法
我们将从查找、插入、删除、遍历四个方法研究 TreeMap 的实现。
查找
TreeMap基于红黑树实现,而红黑树是一种自平衡二叉查找树,所以 TreeMap 的查找操作流程和二叉查找树一致。二叉树的查找流程是这样的,先将目标值和根节点的值进行比较,如果目标值小于根节点的值,则再和根节点的左孩子进行比较。如果目标值大于根节点的值,则继续和根节点的右孩子比较。在查找过程中,如果目标值和二叉树中的某个节点值相等,则返回 true,否则返回 false。
TreeMap 查找和此类似,只不过在 TreeMap 中,节点(Entry)存储的是键值对<k,v>。在查找过程中,比较的是键的大小,返回的是值,如果没找到,则返回null。TreeMap 中的查找方法是get,具体实现在getEntry方法中,相关源码如下:
public V get(Object key) {
Entry<K,V> p = getEntry(key);
return (p==null ? null : p.value);
}
final Entry<K,V> getEntry(Object key) {
// Offload comparator-based version for sake of performance
if (comparator != null)
return getEntryUsingComparator(key);
if (key == null)
throw new NullPointerException();
@SuppressWarnings("unchecked")
Comparable<? super K> k = (Comparable<? super K>) key;
Entry<K,V> p = root;
// 核心查找逻辑
while (p != null) {
int cmp = k.compareTo(p.key);
if (cmp < 0)
p = p.left;
else if (cmp > 0)
p = p.right;
else
return p;
}
return null;
}
插入
TreeMap 的插入其实就是红黑树的插入,因此搞懂了红黑树插入的各个情况,看懂 TreeMap 的插入源码就不在话下了。
public V put(K key, V value) {
Entry<K,V> t = root;
// 1. 如果根节点为 null,将新节点设为根节点
if (t == null) {
compare(key, key); // type (and possibly null) check
root = new Entry<>(key, value, null);
size = 1;
modCount++;
return null;
}
int cmp;
Entry<K,V> parent;
// 2.为 key 在红黑树找到合适的位置
Comparator<? super K> cpr = comparator;
if (cpr != null) {
do {
parent = t;
cmp = cpr.compare(key, t.key);
if (cmp < 0)
t = t.left;
else if (cmp > 0)
t = t.right;
else
return t.setValue(value);
} while (t != null);
}
else {
if (key == null)
throw new NullPointerException();
@SuppressWarnings("unchecked")
Comparable<? super K> k = (Comparable<? super K>) key;
do {
parent = t;
cmp = k.compareTo(t.key);
if (cmp < 0)
t = t.left;
else if (cmp > 0)
t = t.right;
else
return t.setValue(value);
} while (t != null);
}
// 3.将新节点链入红黑树中
Entry<K,V> e = new Entry<>(key, value, parent);
if (cmp < 0)
parent.left = e;
else
parent.right = e;
// 4.插入新节点可能会破坏红黑树性质,这里修正一下
fixAfterInsertion(e);
size++;
modCount++;
return null;
}
删除
TreeMap 的删除其实就是红黑树的删除,因此搞懂了红黑树删除的各个情况,看懂 TreeMap 的删除源码就不在话下了。
public V remove(Object key) {
Entry<K,V> p = getEntry(key);
if (p == null)
return null;
V oldValue = p.value;
deleteEntry(p);
return oldValue;
}
private void deleteEntry(Entry<K,V> p) {
modCount++;
size--;
/*
* 1. 如果 p 有两个孩子节点,则找到后继节点,
* 并把后继节点的值复制到节点 P 中,并让 p 指向其后继节点
*/
if (p.left != null && p.right != null) {
Entry<K,V> s = successor(p);
p.key = s.key;
p.value = s.value;
p = s;
} // p has 2 children
// Start fixup at replacement node, if it exists.
Entry<K,V> replacement = (p.left != null ? p.left : p.right);
if (replacement != null) {
/*
* 2. 将 replacement parent 引用指向新的父节点,
* 同时让新的父节点指向 replacement。
*/
replacement.parent = p.parent;
if (p.parent == null)
root = replacement;
else if (p == p.parent.left)
p.parent.left = replacement;
else
p.parent.right = replacement;
// Null out links so they are OK to use by fixAfterDeletion.
p.left = p.right = p.parent = null;
// 3. 如果删除的节点 p 是黑色节点,则需要进行调整
if (p.color == BLACK)
fixAfterDeletion(replacement);
} else if (p.parent == null) { // 删除的是根节点,且树中当前只有一个节点
root = null;
} else { // 删除的节点没有孩子节点
// p 是黑色,则需要进行调整
if (p.color == BLACK)
fixAfterDeletion(p);
// 将 P 从树中移除
if (p.parent != null) {
if (p == p.parent.left)
p.parent.left = null;
else if (p == p.parent.right)
p.parent.right = null;
p.parent = null;
}
}
}
遍历
TreeMap 有一个特性,即可以保证键的有序性,默认是正序。所以在遍历过程中,大家会发现 TreeMap 会从小到大输出键的值。那么,接下来就来分析一下keySet方法,以及在遍历 keySet 方法产生的集合时,TreeMap 是如何保证键的有序性的。相关代码如下:
public Set<K> keySet() {
return navigableKeySet();
}
public NavigableSet<K> navigableKeySet() {
KeySet<K> nks = navigableKeySet;
return (nks != null) ? nks : (navigableKeySet = new KeySet<>(this));
}
static final class KeySet<E> extends AbstractSet<E> implements NavigableSet<E> {
private final NavigableMap<E, ?> m;
KeySet(NavigableMap<E,?> map) { m = map; }
public Iterator<E> iterator() {
if (m instanceof TreeMap)
return ((TreeMap<E,?>)m).keyIterator();
else
return ((TreeMap.NavigableSubMap<E,?>)m).keyIterator();
}
// 省略非关键代码
}
Iterator<K> keyIterator() {
return new KeyIterator(getFirstEntry());
}
final class KeyIterator extends PrivateEntryIterator<K> {
KeyIterator(Entry<K,V> first) {
super(first);
}
public K next() {
return nextEntry().key;
}
}
abstract class PrivateEntryIterator<T> implements Iterator<T> {
Entry<K,V> next;
Entry<K,V> lastReturned;
int expectedModCount;
PrivateEntryIterator(Entry<K,V> first) {
expectedModCount = modCount;
lastReturned = null;
next = first;
}
public final boolean hasNext() {
return next != null;
}
final Entry<K,V> nextEntry() {
Entry<K,V> e = next;
if (e == null)
throw new NoSuchElementException();
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
// 寻找节点 e 的后继节点
next = successor(e);
lastReturned = e;
return e;
}
// 其他方法省略
}
上面的代码比较多,keySet 涉及的代码还是比较多的,大家可以从上往下看。从上面源码可以看出 keySet 方法返回的是 KeySet 类的对象。这个类实现了Iterable接口,可以返回一个迭代器。该迭代器的具体实现是 KeyIterator,而 KeyIterator 类的核心逻辑是在PrivateEntryIterator中实现的。上面的代码虽多,但核心代码还是 KeySet 类和 PrivateEntryIterator 类的 nextEntry方法。KeySet 类就是一个集合,这里不分析了。而 nextEntry 方法比较重要,下面简单分析一下。
在初始化 KeyIterator 时,默认情况下会将 TreeMap 中包含最小键或最大值(取决于传入的比较器)的 Entry 传给 PrivateEntryIterator。当调用 nextEntry 方法时,通过调用 successor 方法找到当前 entry 的后继,并让 next 指向后继,最后返回当前的 entry。通过这种方式即可实现按正序返回键值的的逻辑。
总结
TreeMap 是 Map 集合的经典红黑树实现,所以弄懂了红黑树的查询、插入、删除,TreeMap 的源码自然不再话下。但要注意的是,TreeMap 的遍历并不是从根节点开始遍历,而是根据 key 的大小从小到大输出,或者从大到小输出。到底是升序还是降序,取决于传入的 Comparator,默认是升序,即从小到大输出。
- TreeMap 是哈希的红黑树经典实现,是Map的哈希有序实现。
集合系列 Map(十五):TreeMap的更多相关文章
- webpack4 系列教程(十五):开发模式与webpack-dev-server
作者按:因为教程所示图片使用的是 github 仓库图片,网速过慢的朋友请移步<webpack4 系列教程(十五):开发模式与 webpack-dev-server>原文地址.更欢迎来我的 ...
- Java 设计模式系列(十五)观察者模式(Observer)
Java 设计模式系列(十五)观察者模式(Observer) Java 设计模式系列目录(https://www.cnblogs.com/binarylei/p/10198698.html) Java ...
- Java 设计模式系列(十五)迭代器模式(Iterator)
Java 设计模式系列(十五)迭代器模式(Iterator) 迭代器模式又叫游标(Cursor)模式,是对象的行为模式.迭代子模式可以顺序地访问一个聚集中的元素而不必暴露聚集的内部表象(interna ...
- JAVA基础学习-集合三-Map、HashMap,TreeMap与常用API
森林森 一份耕耘,一份收获 博客园 首页 新随笔 联系 管理 订阅 随笔- 397 文章- 0 评论- 78 JAVA基础学习day16--集合三-Map.HashMap,TreeMap与常用A ...
- Unity3D脚本中文系列教程(十五)
http://dong2008hong.blog.163.com/blog/static/4696882720140322449780/ Unity3D脚本中文系列教程(十四) ◆ LightRend ...
- SQL注入之Sqli-labs系列第二十五关(过滤 OR & AND)和第二十五A关(过滤逻辑运算符注释符)
开始挑战第二十五关(Trick with OR & AND) 第二十五关A(Trick with comments) 0x1先查看源码 (1)这里的or和and采用了i正则匹配,大小写都无法绕 ...
- SQL注入之Sqli-labs系列第十五关和第十六关(基于POST的时间盲注)
开始挑战第十五关(Blind- Boolian Based- String)和 第十六关(Blind- Time Based- Double quotes- String) 访问地址,输入报错语句 ' ...
- Dubbo学习系列之十五(Seata分布式事务方案TCC模式)
上篇的续集. 工具: Idea201902/JDK11/Gradle5.6.2/Mysql8.0.11/Lombok0.27/Postman7.5.0/SpringBoot2.1.9/Nacos1.1 ...
- java集合系列——Map之TreeMap介绍(九)
一.TreeMap的简介 TreeMap是一个有序的key-value集合,基于红黑树(Red-Black tree)的 NavigableMap实现.该映射根据其键的自然顺序进行排序,或者根据创建映 ...
随机推荐
- linux+docker+nginx如何配置环境并配置域名访问
一.环境准备 1)下载php环境包,下载地址为:https://www.php.net/downloads.php 2)安装docker,这个主要的作用就是用来安装mysql.你也可以不需要安装这个东 ...
- thinkPHP5开发智慧软文遇到的分页第二页不显示数据的问题
在进行结果查询进行分页的时候,发现分页第一页数据正常,第二页没有数据,后面问题一样,这个是因为直接使用了: 如果此处使用如下语句: $lst=NewsModel::order('sendtime de ...
- JavaScript实现返回顶部效果
仿淘宝回到顶部效果 需求:当滚动条到一定位置时侧边栏固定在某个位置,再往下滑动到某一位置时显示回到顶部按钮.点击按钮后页面会动态滑到顶部,速度由快到慢向上滑. 思路: 1.页面加载完毕才能执行js代码 ...
- 神奇的 SQL 之 联表细节 → MySQL JOIN 的执行过程(一)
开心一刻 我:嗨,老板娘,有冰红茶没 老板娘:有 我:多少钱一瓶 老板娘:3块 我:给我来一瓶,给,3块 老板娘:来,你的冰红茶 我:玩呐,我要冰红茶,你给我个瓶盖干哈? 老板娘:这是再来一瓶,我家卖 ...
- 【Python3网络爬虫开发实战】6.4-分析Ajax爬取今日头条街拍美图【华为云技术分享】
[摘要] 本节中,我们以今日头条为例来尝试通过分析Ajax请求来抓取网页数据的方法.这次要抓取的目标是今日头条的街拍美图,抓取完成之后,将每组图片分文件夹下载到本地并保存下来. 1. 准备工作 在本节 ...
- 你知道,HTTPS用的是对称加密还是非对称加密?
1.引言 随着互联网安全意识的普遍提高,对安全要求稍高的应用中,HTTPS的使用是很常见的,甚至在1年前,苹果公司就将使用HTTPS作为APP上架苹果应用市场的先决条件之一(详见<苹果即将强制实 ...
- STM32F4 阿波罗寄存器 进阶版LED灯
上一节通过使用操作地址的方式进行了寄存器的操作,接下来通过两个部分,实现进阶版的操作寄存器(将寄存器的地址进行命名,然后使用名字进行调用 比如商场的A座5楼345号为卖玩具的,我们可以定义地址为sh ...
- Redis面试热点之底层实现篇
通过本文你将了解到以下内容: Redis的作者.发展演进和江湖地位 Redis面试问题的概况 Redis底层实现相关的问题包括:常用数据类型底层实现.SDS的原理和优势.字典的实现原理.跳表和有序集合 ...
- 初步认知jQuery
jQuery:是JavaScript的一个类库全写JavaScript query write less do more JavaScript查询写的更少做的更多 第一步先导入js文件: < ...
- python列表式推导
1.基本语法 [表达式 for 变量 in 列表] 或者 : [表达式 for 变量 in 列表 if 条件] 2.示例 生成列表 li=[x for x in range(10)] print(l ...