Storm 系列(八)—— Storm 集成 HDFS 和 HBase
一、Storm集成HDFS
1.1 项目结构
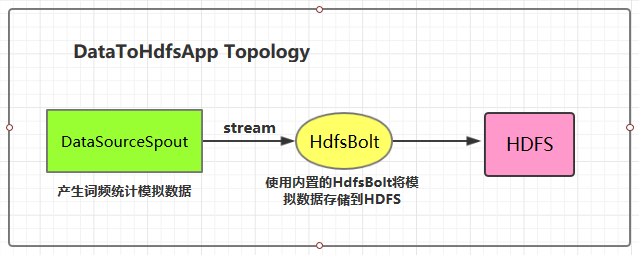
本用例源码下载地址:storm-hdfs-integration
1.2 项目主要依赖
项目主要依赖如下,有两个地方需要注意:
- 这里由于我服务器上安装的是 CDH 版本的 Hadoop,在导入依赖时引入的也是 CDH 版本的依赖,需要使用
<repository>标签指定 CDH 的仓库地址; hadoop-common、hadoop-client、hadoop-hdfs均需要排除slf4j-log4j12依赖,原因是storm-core中已经有该依赖,不排除的话有 JAR 包冲突的风险;
<properties>
<storm.version>1.2.2</storm.version>
</properties>
<repositories>
<repository>
<id>cloudera</id>
<url>https://repository.cloudera.com/artifactory/cloudera-repos/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>org.apache.storm</groupId>
<artifactId>storm-core</artifactId>
<version>${storm.version}</version>
</dependency>
<!--Storm 整合 HDFS 依赖-->
<dependency>
<groupId>org.apache.storm</groupId>
<artifactId>storm-hdfs</artifactId>
<version>${storm.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.6.0-cdh5.15.2</version>
<exclusions>
<exclusion>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.6.0-cdh5.15.2</version>
<exclusions>
<exclusion>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.6.0-cdh5.15.2</version>
<exclusions>
<exclusion>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
</exclusion>
</exclusions>
</dependency>
</dependencies>1.3 DataSourceSpout
/**
* 产生词频样本的数据源
*/
public class DataSourceSpout extends BaseRichSpout {
private List<String> list = Arrays.asList("Spark", "Hadoop", "HBase", "Storm", "Flink", "Hive");
private SpoutOutputCollector spoutOutputCollector;
@Override
public void open(Map map, TopologyContext topologyContext, SpoutOutputCollector spoutOutputCollector) {
this.spoutOutputCollector = spoutOutputCollector;
}
@Override
public void nextTuple() {
// 模拟产生数据
String lineData = productData();
spoutOutputCollector.emit(new Values(lineData));
Utils.sleep(1000);
}
@Override
public void declareOutputFields(OutputFieldsDeclarer outputFieldsDeclarer) {
outputFieldsDeclarer.declare(new Fields("line"));
}
/**
* 模拟数据
*/
private String productData() {
Collections.shuffle(list);
Random random = new Random();
int endIndex = random.nextInt(list.size()) % (list.size()) + 1;
return StringUtils.join(list.toArray(), "\t", 0, endIndex);
}
}产生的模拟数据格式如下:
Spark HBase
Hive Flink Storm Hadoop HBase Spark
Flink
HBase Storm
HBase Hadoop Hive Flink
HBase Flink Hive Storm
Hive Flink Hadoop
HBase Hive
Hadoop Spark HBase Storm1.4 将数据存储到HDFS
这里 HDFS 的地址和数据存储路径均使用了硬编码,在实际开发中可以通过外部传参指定,这样程序更为灵活。
public class DataToHdfsApp {
private static final String DATA_SOURCE_SPOUT = "dataSourceSpout";
private static final String HDFS_BOLT = "hdfsBolt";
public static void main(String[] args) {
// 指定 Hadoop 的用户名 如果不指定,则在 HDFS 创建目录时候有可能抛出无权限的异常 (RemoteException: Permission denied)
System.setProperty("HADOOP_USER_NAME", "root");
// 定义输出字段 (Field) 之间的分隔符
RecordFormat format = new DelimitedRecordFormat()
.withFieldDelimiter("|");
// 同步策略: 每 100 个 tuples 之后就会把数据从缓存刷新到 HDFS 中
SyncPolicy syncPolicy = new CountSyncPolicy(100);
// 文件策略: 每个文件大小上限 1M,超过限定时,创建新文件并继续写入
FileRotationPolicy rotationPolicy = new FileSizeRotationPolicy(1.0f, Units.MB);
// 定义存储路径
FileNameFormat fileNameFormat = new DefaultFileNameFormat()
.withPath("/storm-hdfs/");
// 定义 HdfsBolt
HdfsBolt hdfsBolt = new HdfsBolt()
.withFsUrl("hdfs://hadoop001:8020")
.withFileNameFormat(fileNameFormat)
.withRecordFormat(format)
.withRotationPolicy(rotationPolicy)
.withSyncPolicy(syncPolicy);
// 构建 Topology
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout(DATA_SOURCE_SPOUT, new DataSourceSpout());
// save to HDFS
builder.setBolt(HDFS_BOLT, hdfsBolt, 1).shuffleGrouping(DATA_SOURCE_SPOUT);
// 如果外部传参 cluster 则代表线上环境启动,否则代表本地启动
if (args.length > 0 && args[0].equals("cluster")) {
try {
StormSubmitter.submitTopology("ClusterDataToHdfsApp", new Config(), builder.createTopology());
} catch (AlreadyAliveException | InvalidTopologyException | AuthorizationException e) {
e.printStackTrace();
}
} else {
LocalCluster cluster = new LocalCluster();
cluster.submitTopology("LocalDataToHdfsApp",
new Config(), builder.createTopology());
}
}
}1.5 启动测试
可以用直接使用本地模式运行,也可以打包后提交到服务器集群运行。本仓库提供的源码默认采用 maven-shade-plugin 进行打包,打包命令如下:
# mvn clean package -D maven.test.skip=true运行后,数据会存储到 HDFS 的 /storm-hdfs 目录下。使用以下命令可以查看目录内容:
# 查看目录内容
hadoop fs -ls /storm-hdfs
# 监听文内容变化
hadoop fs -tail -f /strom-hdfs/文件名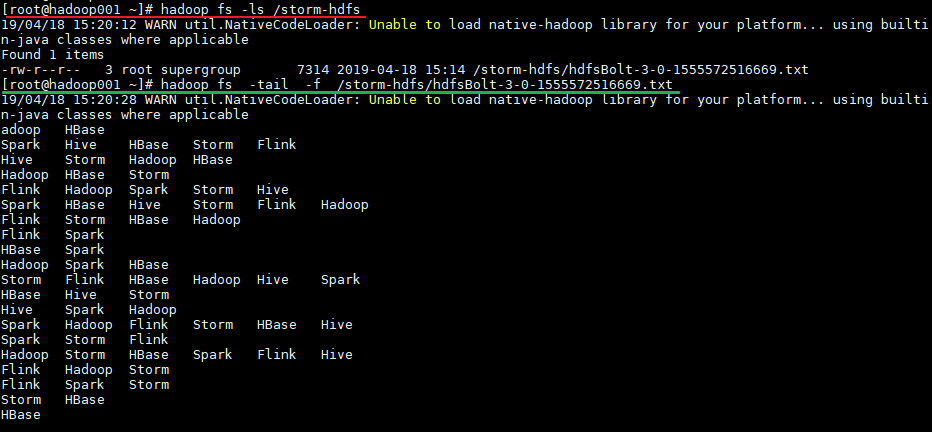
二、Storm集成HBase
2.1 项目结构
集成用例: 进行词频统计并将最后的结果存储到 HBase,项目主要结构如下:
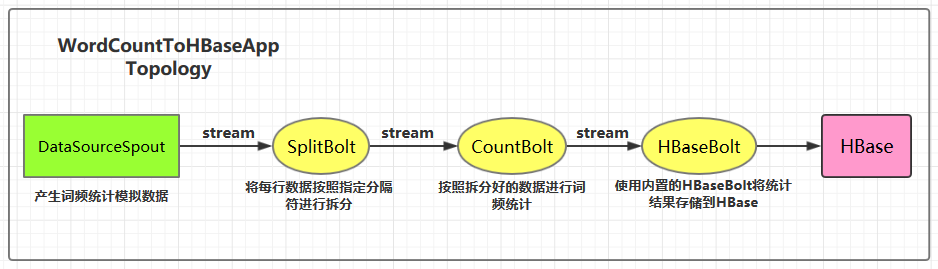
本用例源码下载地址:storm-hbase-integration
2.2 项目主要依赖
<properties>
<storm.version>1.2.2</storm.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.storm</groupId>
<artifactId>storm-core</artifactId>
<version>${storm.version}</version>
</dependency>
<!--Storm 整合 HBase 依赖-->
<dependency>
<groupId>org.apache.storm</groupId>
<artifactId>storm-hbase</artifactId>
<version>${storm.version}</version>
</dependency>
</dependencies>2.3 DataSourceSpout
/**
* 产生词频样本的数据源
*/
public class DataSourceSpout extends BaseRichSpout {
private List<String> list = Arrays.asList("Spark", "Hadoop", "HBase", "Storm", "Flink", "Hive");
private SpoutOutputCollector spoutOutputCollector;
@Override
public void open(Map map, TopologyContext topologyContext, SpoutOutputCollector spoutOutputCollector) {
this.spoutOutputCollector = spoutOutputCollector;
}
@Override
public void nextTuple() {
// 模拟产生数据
String lineData = productData();
spoutOutputCollector.emit(new Values(lineData));
Utils.sleep(1000);
}
@Override
public void declareOutputFields(OutputFieldsDeclarer outputFieldsDeclarer) {
outputFieldsDeclarer.declare(new Fields("line"));
}
/**
* 模拟数据
*/
private String productData() {
Collections.shuffle(list);
Random random = new Random();
int endIndex = random.nextInt(list.size()) % (list.size()) + 1;
return StringUtils.join(list.toArray(), "\t", 0, endIndex);
}
}产生的模拟数据格式如下:
Spark HBase
Hive Flink Storm Hadoop HBase Spark
Flink
HBase Storm
HBase Hadoop Hive Flink
HBase Flink Hive Storm
Hive Flink Hadoop
HBase Hive
Hadoop Spark HBase Storm2.4 SplitBolt
/**
* 将每行数据按照指定分隔符进行拆分
*/
public class SplitBolt extends BaseRichBolt {
private OutputCollector collector;
@Override
public void prepare(Map stormConf, TopologyContext context, OutputCollector collector) {
this.collector = collector;
}
@Override
public void execute(Tuple input) {
String line = input.getStringByField("line");
String[] words = line.split("\t");
for (String word : words) {
collector.emit(tuple(word, 1));
}
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word", "count"));
}
}2.5 CountBolt
/**
* 进行词频统计
*/
public class CountBolt extends BaseRichBolt {
private Map<String, Integer> counts = new HashMap<>();
private OutputCollector collector;
@Override
public void prepare(Map stormConf, TopologyContext context, OutputCollector collector) {
this.collector=collector;
}
@Override
public void execute(Tuple input) {
String word = input.getStringByField("word");
Integer count = counts.get(word);
if (count == null) {
count = 0;
}
count++;
counts.put(word, count);
// 输出
collector.emit(new Values(word, String.valueOf(count)));
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word", "count"));
}
}2.6 WordCountToHBaseApp
/**
* 进行词频统计 并将统计结果存储到 HBase 中
*/
public class WordCountToHBaseApp {
private static final String DATA_SOURCE_SPOUT = "dataSourceSpout";
private static final String SPLIT_BOLT = "splitBolt";
private static final String COUNT_BOLT = "countBolt";
private static final String HBASE_BOLT = "hbaseBolt";
public static void main(String[] args) {
// storm 的配置
Config config = new Config();
// HBase 的配置
Map<String, Object> hbConf = new HashMap<>();
hbConf.put("hbase.rootdir", "hdfs://hadoop001:8020/hbase");
hbConf.put("hbase.zookeeper.quorum", "hadoop001:2181");
// 将 HBase 的配置传入 Storm 的配置中
config.put("hbase.conf", hbConf);
// 定义流数据与 HBase 中数据的映射
SimpleHBaseMapper mapper = new SimpleHBaseMapper()
.withRowKeyField("word")
.withColumnFields(new Fields("word","count"))
.withColumnFamily("info");
/*
* 给 HBaseBolt 传入表名、数据映射关系、和 HBase 的配置信息
* 表需要预先创建: create 'WordCount','info'
*/
HBaseBolt hbase = new HBaseBolt("WordCount", mapper)
.withConfigKey("hbase.conf");
// 构建 Topology
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout(DATA_SOURCE_SPOUT, new DataSourceSpout(),1);
// split
builder.setBolt(SPLIT_BOLT, new SplitBolt(), 1).shuffleGrouping(DATA_SOURCE_SPOUT);
// count
builder.setBolt(COUNT_BOLT, new CountBolt(),1).shuffleGrouping(SPLIT_BOLT);
// save to HBase
builder.setBolt(HBASE_BOLT, hbase, 1).shuffleGrouping(COUNT_BOLT);
// 如果外部传参 cluster 则代表线上环境启动,否则代表本地启动
if (args.length > 0 && args[0].equals("cluster")) {
try {
StormSubmitter.submitTopology("ClusterWordCountToRedisApp", config, builder.createTopology());
} catch (AlreadyAliveException | InvalidTopologyException | AuthorizationException e) {
e.printStackTrace();
}
} else {
LocalCluster cluster = new LocalCluster();
cluster.submitTopology("LocalWordCountToRedisApp",
config, builder.createTopology());
}
}
}2.7 启动测试
可以用直接使用本地模式运行,也可以打包后提交到服务器集群运行。本仓库提供的源码默认采用 maven-shade-plugin 进行打包,打包命令如下:
# mvn clean package -D maven.test.skip=true运行后,数据会存储到 HBase 的 WordCount 表中。使用以下命令查看表的内容:
hbase > scan 'WordCount'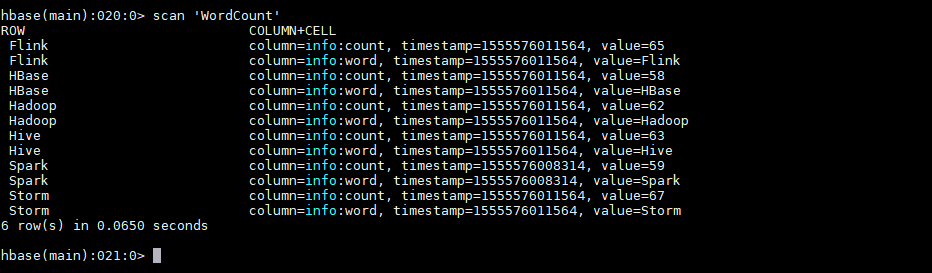
2.8 withCounterFields
在上面的用例中我们是手动编码来实现词频统计,并将最后的结果存储到 HBase 中。其实也可以在构建 SimpleHBaseMapper 的时候通过 withCounterFields 指定 count 字段,被指定的字段会自动进行累加操作,这样也可以实现词频统计。需要注意的是 withCounterFields 指定的字段必须是 Long 类型,不能是 String 类型。
SimpleHBaseMapper mapper = new SimpleHBaseMapper()
.withRowKeyField("word")
.withColumnFields(new Fields("word"))
.withCounterFields(new Fields("count"))
.withColumnFamily("cf");参考资料
更多大数据系列文章可以参见 GitHub 开源项目: 大数据入门指南
Storm 系列(八)—— Storm 集成 HDFS 和 HBase的更多相关文章
- Storm 学习之路(八)—— Storm集成HDFS和HBase
一.Storm集成HDFS 1.1 项目结构 本用例源码下载地址:storm-hdfs-integration 1.2 项目主要依赖 项目主要依赖如下,有两个地方需要注意: 这里由于我服务器上安装的是 ...
- Storm系列一: Storm初步
初入Storm 前言 学习Storm已经有两周左右的时间,但是认真来说学习过程确实是零零散散,遇到问题去百度一下,找到新概念再次学习,在这样的一个循环又不成体系的过程中不断学习Storm. 前人栽树, ...
- Storm系列之一——Storm Topology并发
1.是什么构成一个可运行的topology? worker processes(worker进程),executors(线程)和tasks. 一台Storm集群里面的机器可能运行一个或多个worker ...
- Spring Boot系列 八、集成Kafka
一.引入依赖 <dependency> <groupId>org.springframework.kafka</groupId> <artifactId> ...
- Storm 系列(七)—— Storm 集成 Redis 详解
一.简介 Storm-Redis 提供了 Storm 与 Redis 的集成支持,你只需要引入对应的依赖即可使用: <dependency> <groupId>org.apac ...
- Storm 系列(二)实时平台介绍
Storm 系列(二)实时平台介绍 本章中的实时平台是指针对大数据进行实时分析的一整套系统,包括数据的收集.处理.存储等.一般而言,大数据有 4 个特点: Volumn(大量). Velocity(高 ...
- Storm 系列(一)基本概念
Storm 系列(一)基本概念 Apache Storm(http://storm.apache.org/)是由 Twitter 开源的分布式实时计算系统. Storm 可以非常容易并且可靠地处理无限 ...
- Storm 系列(六)—— Storm 项目三种打包方式对比分析
一.简介 在将 Storm Topology 提交到服务器集群运行时,需要先将项目进行打包.本文主要对比分析各种打包方式,并将打包过程中需要注意的事项进行说明.主要打包方式有以下三种: 第一种:不加任 ...
- Storm 系列(五)—— Storm 编程模型详解
一.简介 下图为 Strom 的运行流程图,在开发 Storm 流处理程序时,我们需要采用内置或自定义实现 spout(数据源) 和 bolt(处理单元),并通过 TopologyBuilder 将它 ...
随机推荐
- layui上传Excel更新数据并下载
前言: 最近做项目遇到了一个需求,上传Excel获取数据更新Excel文档,并直接返回更新完的Excel到前端下载:其实需求并没有什么问题,关键是前端用到的是layui上传组件(layui.uploa ...
- 释放你的硬盘空间!——Windows 磁盘清理技巧
引言 用了Windows系统的各位都知道,作为系统盘的C盘的空间总是一天比一天少.就拿本人的例子来说,自从安装了Win10,就发现,C盘从一开始的10几G占用,到现在慢慢变成了20G.30G….占用只 ...
- Windows 纠错
4:在Windows应用程序中,当需要将窗体显示为模式对话框时,需要调用窗体的()方法.(选择一项)A:Activate()B:ShowDialog()C:Show()D:Close()正确答案是 B ...
- AUTOSAR学习之RTE - 可运行实体
本文介绍RTE的运行体(runnable). An AUTOSAR component defines one or more "runnable entities". A run ...
- mac安装ElasticSearch+head+node+一个例子~
1.下载ElasticSearch 官网下载链接:https://www.elastic.co/cn/downloads/past-releases(进去的可能会比较慢,网络好的情况下会好一些) 我下 ...
- java并发编程(十七)----(线程池)java线程池架构和原理
前面我们简单介绍了线程池的使用,但是对于其如何运行我们还不清楚,Executors为我们提供了简单的线程工厂类,但是我们知道ThreadPoolExecutor是线程池的具体实现类.我们先从他开始分析 ...
- 牛客多校训练第八场C.CDMA(思维+构造)
题目传送门 题意: 输入整数m( m∈2k ∣ k=1,2,⋯,10),构造一个由1和-1组成的m×m矩阵,要求对于任意两个不同的行的内积为0. 题解: Code: #include<bits/ ...
- 使用top查看进程和系统负载信息
引言 使用top命令,可以查看正在运行的进程和系统负载信息,包括cpu负载.内存使用.各个进程所占系统资源等,top可以以一定频率更新这些统计信息.下面我们来学习top命令的具体使用方法. ...
- 容易上手搭建vue2.0开发环境
第一步:安装node 前端开发框架和环境都是需要 Node.js ,先安装node.js开发环境,vue的运行是要依赖于node的npm的管理工具来实现,下载https://nodejs.org/en ...
- cs224d---词向量表示
1 Word meaning 1. 1 word meaning的两种定义 Definition meaning:单词的含义指代了客观存在的具体事物,如眼镜. Distributional simil ...