jdk1.8 HashMap底层数据结构:深入解析为什么jdk1.8 HashMap的容量一定要是2的n次幂
前言
1.本文根据jdk1.8源码来分析HashMap的容量取值问题;
2.本文有做 jdk1.8 HashMap.resize()扩容方法的源码解析:见下文“一、3.扩容:同样需要保证扩容后的容量是2的n次幂”;
3.目录:
一、jdk1.8中,对“HashMap的容量一定是2的n次幂”做了严格控制
1.默认初始容量
2.使用HashMap的有参构造函数来自定义容量的大小(保证容量是2的n次幂)
3.扩容:同样需要保证扩容后的容量是2的n次幂( jdk1.8 HashMap.resize()扩容方法的源码解析)
二、为什么HashMap的容量一定要是2的n次幂?或者说,保证“HashMap的容量一定是2的n次幂”有什么好处?
1.关系到元素在桶中的位置计算问题
2.关系到扩容后元素在newCap中的放置问题
2.1 源码解析
2.2 深入分析(含图解)
一、jdk1.8中,对“HashMap的容量一定要是2的n次幂”做了严格控制
1.默认初始容量:
/**
* The default initial capacity - MUST be a power of two.(默认初始容量——必须是2的n次幂。)
*/
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16(16 = 2^4)
2.使用HashMap的有参构造函数来自定义容量的大小(保证容量是2的n次幂):
HashMap总共有4个构造函数,其中有2个构造函数可以自定义容量的大小:
①HashMap(int initialCapacity):底层调用的是②HashMap(int initialCapacity, float loadFactor)构造函数
public HashMap(int initialCapacity) {
this(initialCapacity, DEFAULT_LOAD_FACTOR);
}
②HashMap(int initialCapacity, float loadFactor)
public HashMap(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " + initialCapacity);
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " + loadFactor);
this.loadFactor = loadFactor;
this.threshold = tableSizeFor(initialCapacity);//tableSizeFor(initialCapacity)方法是重点!!!
}
这里有个问题:使用①或②构造函数来自定义容量时,怎么能够保证传入的容量一定是2的n次幂呢?
答案就在标记出来的tableSizeFor(initialCapacity)方法中:
/**
* Returns a power of two size for the given target capacity.
*/
static final int tableSizeFor(int cap) {
int n = cap - 1;
n |= n >>> 1;
n |= n >>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
}
上面这段代码的作用:
假如你传的cap是5,那么最终的初始容量为8;假如你传的cap是24,那么最终的初始容量为32。
这是因为5并非是2的n次幂,而大于等于5且距离5最近的2的n次幂是8(8 = 2^3);同样的,24也并非2的n次幂,大于等于24且距离24最近的2的n次幂是32(32 = 2^5)。
假如你传的cap是64,那么最终的初始容量就是64,因为64是2^6,它就是等于cap的最小2的n次幂。
总结起来就一句话:通过位移运算,找到大于或等于 cap 的 最小2的n次幂。
jdk1.7的初始容量处理机制和上面jdk1.8具有相同的作用,但1.7的代码好懂很多:
public HashMap(int initialCapacity, float loadFactor) {
……
int capacity = 1;
while (capacity < initialCapacity) {
capacity <<= 1;
}
……
}
3.扩容:同样需要保证扩容后的容量是2的n次幂( jdk1.8 HashMap.resize()扩容方法的源码解析)
resize()扩容方法主要做了三件事(这里这里重点讲前两件事,第三件事在下文的“三、2.”中讲):
①计算新容量(新桶) newCap 和新阈值 newThr;
②根据计算出的 newCap 创建新的桶数组table,并对table做初始化;
③将键值对节点重新放到新的桶数组里;
final Node<K,V>[] resize() { //扩容
//---------------- -------------------------- 1.计算新容量(新桶) newCap 和新阈值 newThr。 ---------------------------------
Node<K,V>[] oldTab = table;
int oldCap = (oldTab == null) ? 0 : oldTab.length;//看容量是否已初始化
int oldThr = threshold;//下次扩容要达到的阈值。threshold(阈值) = capacity * loadFactor。
int newCap, newThr = 0;
if (oldCap > 0) {//容量已初始化过了:检查容量和阈值是否达到上限《==========
if (oldCap >= MAXIMUM_CAPACITY) {//oldCap >= 2^30,已达到扩容上限,停止扩容
threshold = Integer.MAX_VALUE;
return oldTab;
}
// newCap < 2^30 && oldCap > 16,还能再扩容:2倍扩容
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY && oldCap >= DEFAULT_INITIAL_CAPACITY)
newThr = oldThr << 1; // 扩容:阈值*2。(注意:阈值是有可能越界的)
}
//容量未初始化 && 阈值 > 0。
//【啥时会满足层判断:使用HashMap(int initialCapacity, float loadFactor)或 HashMap(int initialCapacity)构造函数实例化HashMap时,threshold才会有值。】
else if (oldThr > 0)
newCap = oldThr;//初始容量设为阈值
else { //容量未初始化 && 阈值 <= 0 :
//【啥时会满足这层判断:①使用无参构造函数实例化HashMap时;②在“if (oldCap > 0)”判断层newThr溢出了。】
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
if (newThr == 0) {//什么情况下才会进入这个判断框:前面执行了else if (oldThr > 0),并没有为newThr赋值,就会进入这个判断框。
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ? (int)ft : Integer.MAX_VALUE);
}
threshold = newThr;
//------------------------------------------------------2.扩容:------------------------------------------------------------------
@SuppressWarnings({"rawtypes","unchecked"})
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];//扩容
table = newTab;
//--------------------------------------------- 3.将键值对节点重新放到新的桶数组里。------------------------------------------------
……//此处源码见下文“二、2.”
return newTab;
}
通过resize()扩容方法的源码可以知道:每次扩容,都是将容量扩大一倍,所以新容量依旧是2的n次幂。如oldCap是16的话,那么newCap则为32。
通过上面三点可以确定,不论是默认初始容量,还是自定义容量大小,又或者是扩容后的容量,都必须保证一定是2的n次幂。
二、为什么HashMap的容量一定要是2的n次幂?或者说,保证“HashMap的容量一定是2的n次幂”有什么好处?
原因有两个:
1.关系到元素在桶中的位置计算问题:
简单来讲,一个元素放到哪个桶中,是通过 “hash % capacity” 取模运算得到的余数来确定的(注:“元素的key的哈希值”在本文统一简称为“hash”)。
hashMap用另一种方式来替代取模运算——位运算:(capacity - 1) & hash。这种运算方式为什么可以得到跟取模一样的结果呢? 答案是capacity是2的N次幂。(计算机做位运算的效率远高于做取模运算的效率,测试见:https://www.cnblogs.com/laipimei/p/11316812.html)
证明取模和位运算结果的一致性:

2.关系到扩容后元素在newCap中的放置问题:
扩容后,如何实现将oldCap中的元素重新放到newCap中?
我们不难想到的实现方式是:遍历所有Node,然后重新put到新的table中, 中间会涉及计算新桶位置、处理hash碰撞等处理。这里有个不容忽视的问题——哈希碰撞。在元素put进桶中时,就已经处理过了哈希碰撞问题:哈希值一样但通过equals()比较确定内容不同的元素,会在同一个桶中形成链表,链表长度 >=8 时将链表转为红黑树;扩容时,需要重新处理这些元素的哈希碰撞问题,如果数据量一大.......要完……
jdk1.8用了优雅又高效的方式来处理扩容后元素的放置问题,下面我们一起来看看jdk1.8到底是怎么做的。
2.1 先看jdk1.8源码实现:
1 final Node<K,V>[] resize() { //扩容方法
2
3 //---------------- -------------------------- 1.计算新容量(新桶) newCap 和新阈值 newThr: -------------------------------------------
4
5 …… //此处源码见前文“一、3.”
6
7 //---------------------------------------------------------2.扩容:------------------------------------------------------------------
8
9 …… //此处源码见前文“一、3.”
10
11 //--------------------------------------------- 3.将键值对节点重新放到新的桶数组里:------------------------------------------------
12
13 if (oldTab != null) {//容量已经初始化过了:
14 for (int j = 0; j < oldCap; ++j) {//一个桶一个桶去遍历,j 用于记录oldCap中当前桶的位置
15 Node<K,V> e;
16 if ((e = oldTab[j]) != null) {//当前桶上有节点,就赋值给e节点
17 oldTab[j] = null;//把该节点置为null(现在这个桶上什么都没有了)
18 if (e.next == null)//e节点后没有节点了:在新容器上重新计算e节点的放置位置《===== ①桶上只有一个节点
19 newTab[e.hash & (newCap - 1)] = e;
20 else if (e instanceof TreeNode)//e节点后面是红黑树:先将红黑树拆成2个子链表,再将子链表的头节点放到新容器中《===== ②桶上是红黑树
21 ((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
22 else { // preserve order
23 Node<K,V> loHead = null, loTail = null;
24 Node<K,V> hiHead = null, hiTail = null;
25 Node<K,V> next;
26 do { //遍历链表,并将链表节点按原顺序进行分组《===== ③桶上是链表
27 next = e.next;
28 if ((e.hash & oldCap) == 0) {//“定位值等于0”的为一组:
29 if (loTail == null)
30 loHead = e;
31 else
32 loTail.next = e;
33 loTail = e;
34 }
35 else {//“定位值不等于0”的为一组:
36 if (hiTail == null)
37 hiHead = e;
38 else
39 hiTail.next = e;
40 hiTail = e;
41 }
42 } while ((e = next) != null);
//将分好的子链表放到newCap中:
43 if (loTail != null) {
44 loTail.next = null;
45 newTab[j] = loHead;//原链表在oldCap的什么位置,“定位值等于0”的子链表的头节点就放到newCap的什么位置
46 }
47 if (hiTail != null) {
48 hiTail.next = null;
49 newTab[j + oldCap] = hiHead; //“定位值不等于0”的子节点的头节点在newCap的位置 = 原链表在oldCap中的位置 + oldCap
50 }
51 }
52 }
53 }
54 }
55 return newTab;
56 }
2.2 深入分析(含图解)
① 如果桶上只有一个节点(后面即没链表也没树):元素直接做 “hash & (newCap - 1)” 运算,根据结果将元素节点放到newCap的相应位置;
②如果桶上是链表:
将链表上的所有节点做 “hash & oldCap” 运算(注意,这里oldCap没有-1),会得到一个定位值(“定位值”这个名字是我自己取的,为了更好理解该值的意义)。定位值要么是“0”,要么是“小于capacity的正整数”!这是个规律,之所以能得此规律和capacity取值一定是2的n次幂有直接关系,如果容量不是2的n次幂,那么定位值就不再要么是“0”,要么是“小于capacity的正整数”,它还有可能是其他的数;
根据定位值的不同,会将链表一分为二得到两个子链表,这两个子链表根据各自的定位值直接放到newCap中:
子链表的定位值 == 0: 则链表在oldCap中是什么位置,就将子链表的头节点直接放到newCap的什么位置;
子链表的定位值 == 小于capacity的正整数:则将子链表的头节点放到newCap的“oldCap + 定位值”的位置;
这么做的好处:链表在被拆分成两个子链表前就已经处理过了元素的哈希碰撞问题,子链表不用重新处理哈希碰撞问题,可以直接将头节点直接放到newCap的合适的位置上,完成 “扩容后将元素放到newCap”这一工作。正因为如此,大大提高了jdk1.8的HashMap的扩容效率。
下面将通过画图的形式,进一步理解HashMap到底是怎么将元素放到newCap中的。
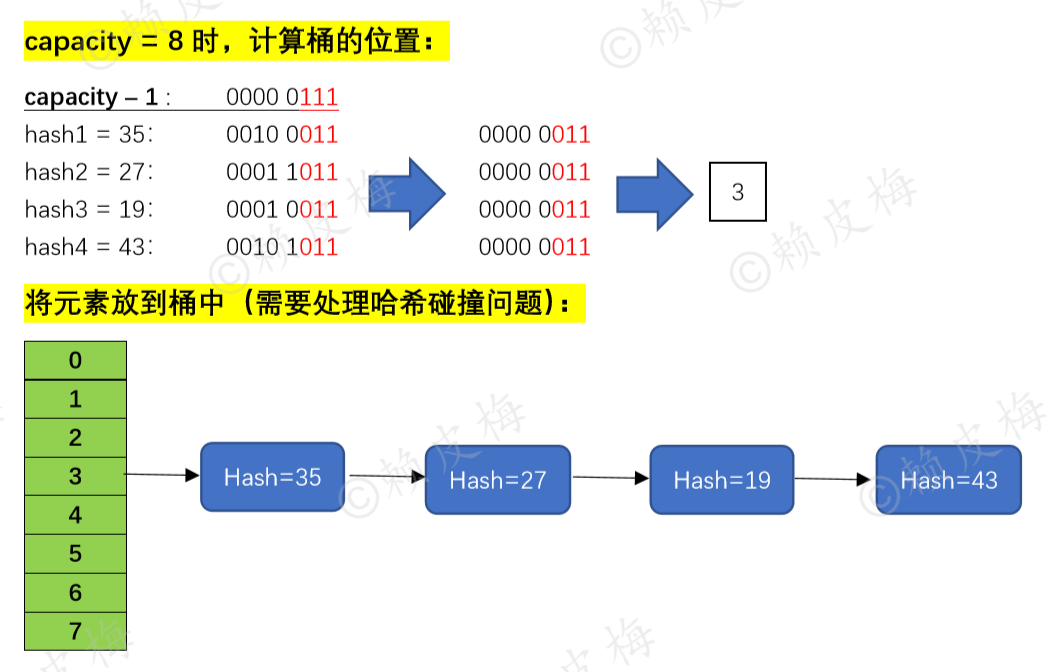
前面我们说了jdk1.8的HashMap元素放到哪个桶中哪个位置,是通过计算 “(capacity - 1) & hash” 得到的余数来确定的。现在有四个元素,哈希值分别为35、27、19、43,当“容量 = 8”时,计算所得余数都等于3,所以这4个元素会被放到 table[3] 的位置,如下图所示:
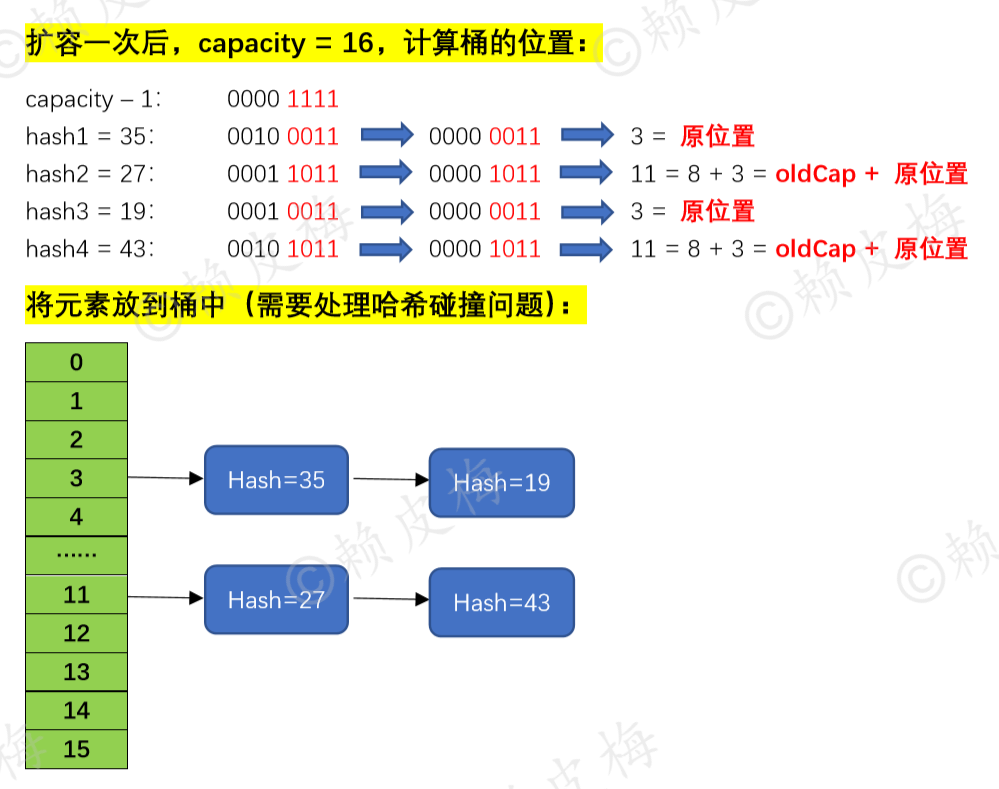
进行一次扩容后,现在容量 = 16,再次计算“(capacity - 1) & hash”后,这四个元素在newCap中的位置会有所变化:要么在原位置,要么在“oldCap + 原位置”;也就是说这四个元素被分成了两组。如下图所示:
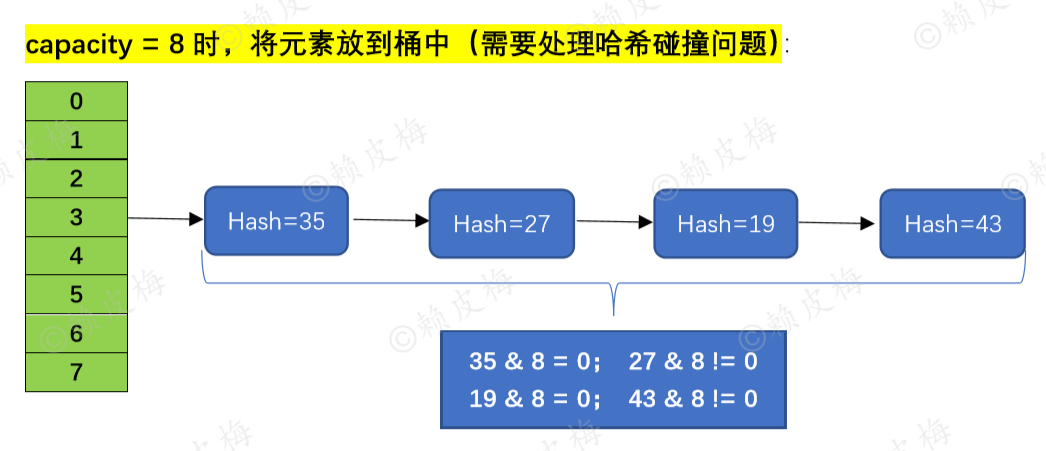
下面我们不用 “(capacity - 1) & hash” 的方式来放置元素,而是根据jdk1.8中HashMap.resize()扩容方法来放置元素:先通过 “hash & oldCap” 得到定位值,再根据定位值同样能将链表一分为二(见证奇迹的时候到了):
“定位值 = 0”的为一组,这组元素就是前面将容量从8扩到16后,通过“(newCap - 1) & hash” 计算确定 “放回原位置” 的那些元素;
“定位值 != 0”的为一组,这组元素就是扩容后,确定 “oldCap + 原位置”的那些元素。 如下图所示:
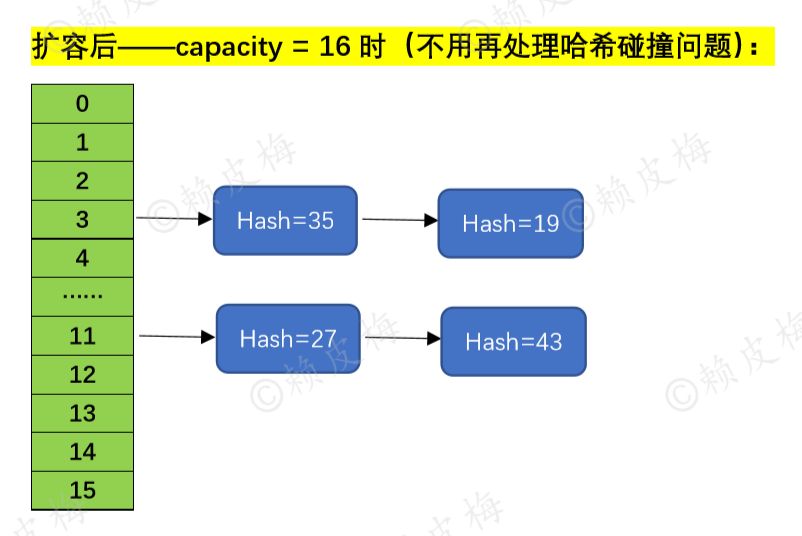
再将这两组元素节点分别连接成子链表:loHead是 “定位值 == 0” 的子链表的头节点;hiHead是 “定位值 != 0” 的子链表的头节点。如下图所示:

最后,将子链表的头节点loHead放到newCap中,位置和在oldCap中的原位置一致;将另一个子链表的头节点hiHead放到newCap的“oldCap + 原位置”上。到这里HashMap就完成了扩容后将元素重新放到newCap中的工作了。如下图所示:
到这里其实我们已经把 “容量一定是2的n次幂是 提高扩容后将元素重新放到newCap中的效率 的前提”解释完了,现在还有一个小小的问题——通过定位值将链表一分为二,会分得均匀吗?如果分得很不均匀会怎么样?
众所周知,要想HashMap的查询速度快,那就得尽量做到让元素均匀地散落到每个桶里。将链表平均分成两个子链表,就意味着让元素更均匀地放到桶中了,增加了元素散列性,从而提高了元素的查找效率。那jdk1.8又是如何将链表分得更平均的呢?这关系到两点:①元素的哈希值更随机、散列;②通过“hash & oldCap”中的oldCap再次增加元素放置位置的随机性。第①点和哈希算法的实现直接相关,这里不细说;第②点的意思如下:
以 “capacity = 8” 为例,下面这些都是当 “容量 = 8” 时放在table[3]位置上的元素的hash值。扩容时做“hash & oldCap” 运算,通过下图我们可以发现,oldCap所在的位上(即倒数第4位),元素的hash值在这个位是0还是1具有随机性。

也就是说,jdk1.8在元素通过哈希算法使hash值已经具有随机性的前提下,再做了一个增加元素放置位置随机性的运算。
③如果桶上是红黑树:
将红黑树重新放到newCap中的逻辑和将链表重新放到newCap的的逻辑差不多。不同之处在于,重新放后,会将红黑树拆分成两条由 TreeNode 组成的子链表:
此时,如果子链表长度 <= UNTREEIFY_THRESHOLD(即 <= 6 ),则将由 TreeNode组成的子链表 转换成 由Node组成的普通子链表,然后再根据定位值将子链表的头节点放到newCap中;
否则,根据条件重新将“由 TreeNode 组成的子链表”重新树化,然后再根据定位值将树的头节点放到newCap中。
本文不对“HashMap扩容时红黑树在newCap中的重新放置”做详细解释,后面我会再写一篇有关《红黑树转回链表的具体时机》的博文,在这篇博文中会做详细的源码解析。
一言蔽之:jdk1.8 HashMap的容量一定要是2的n次幂,是为了提高“计算元素放哪个桶”的效率,也是为了提高扩容效率(避免了扩容后再重复处理哈希碰撞问题)。
jdk1.8 HashMap底层数据结构:深入解析为什么jdk1.8 HashMap的容量一定要是2的n次幂的更多相关文章
- jdk1.8源码解析:HashMap底层数据结构之链表转红黑树的具体时机
本文从三个部分去探究HashMap的链表转红黑树的具体时机: 一.从HashMap中有关“链表转红黑树”阈值的声明: 二.[重点]解析HashMap.put(K key, V value)的源码: 三 ...
- HashMap底层数据结构详解
一.HashMap底层数据结构 JDK1.7及之前:数组+链表 JDK1.8:数组+链表+红黑树 关于HashMap基本的大家都知道,但是为什么数组的长度必须是2的指数次幂,为什么HashMap的加载 ...
- [转]java 的HashMap底层数据结构
java 的HashMap底层数据结构 HashMap也是我们使用非常多的Collection,它是基于哈希表的 Map 接口的实现,以key-value的形式存在.在HashMap中,key-v ...
- HashMap底层数据结构和算法解析
1.Hash Map的数据结构? A:哈希表结构(链表散列:数组+链表)实现,结合数组和链表的优点.当链表长度超过8时,链表转换为红黑树. transient Node<K,V>[] ta ...
- java 的HashMap底层数据结构
HashMap也是我们使用非常多的Collection,它是基于哈希表的 Map 接口的实现,以key-value的形式存在.在HashMap中,key-value总是会当做一个整体来处理,系统会根据 ...
- Java泛型底层源码解析--ConcurrentHashMap(JDK1.7)
1. Concurrent相关历史 JDK5中添加了新的concurrent包,相对同步容器而言,并发容器通过一些机制改进了并发性能.因为同步容器将所有对容器状态的访问都串行化了,这样保证了线程的安全 ...
- 从HashMap的执行流程开始 揭开HashMap底层实现
心得:如何学习源码: 从某个执行过程入手,建议先从整体入手,了解底层的数据结构是怎么一步一步优化的.最后,在了解完底层的数据结构优化过程后,从重要的核心方法入手,从它的执行流程入手,先去网上搜索了解它 ...
- HashMap底层实现原理
HashMap底层实现 HashMap底层数据结构如下图,HashMap由“hash函数+数组+单链表”3个要素构成 通过写一个迷你版的HashMap来深刻理解 MyMap接口,定义一个接口,对外暴露 ...
- Redis学习笔记(二)redis 底层数据结构
在上一节提到的图中,我们知道,可以通过 redisObject 对象的 type 和 encoding 属性.可以决定Redis 主要的底层数据结构:SDS.QuickList.ZipList.Has ...
随机推荐
- web前端css(二)
一. 标准文档流 标准文档流中会有一些现象: 空白折叠 和 高低不齐边底对齐的现象 标准文档流等级森严, 标签分为两种等级: 行内元素 和 块级元素. 1. 行内元素 和 块级元素的区别: 行内元素 ...
- Nginx正向代理和反向代理
关于代理 说到代理,首先我们要明确一个概念,所谓代理就是一个代表.一个渠道: 此时就设计到两个角色,一个是被代理角色,一个是目标角色,被代理角色通过这个代理访问目标角色完成一些任务的过程称为代理操作过 ...
- WPF 入门笔记之事件
一.事件路由 1. 直接路由事件 起源于一个元素,并且不能传递给其他元素 MouserEnter 和MouserLeave 就是直接事件路由 2. 冒泡路由事件 在包含层次中向上传递,首先由引发的元素 ...
- cogs.12运输问题2题解
乍一看貌似和运输问题1没有任何区别,但本题有一个有意思的东西叫做下限,我个人称之为非强制下限,因为本题中要求的实际是我走这条边这条边才至少走下限的流,虽然出题人没说,但从样例来看确实是这样的,而强制下 ...
- [NOIP2013]华容道 题解(搜索)
[NOIP2013]华容道 [题目描述] 这道题根据小时候玩华容道不靠谱的经验还以为是并查集,果断扑街.考后想想也是,数据这么小一定有他的道理. 首先由于是最小步数,所以BFS没跑了.那么我们大可把这 ...
- 硬件笔记之Thinkpad T470P更换2K屏幕
0x00 前言 手上的Thinkpad T470P屏幕是1920x1080的屏幕,色域范围NTSC 45%,作为一块办公用屏是正常配置,但是考虑到色彩显示和色域范围,计划升级到2K屏幕. 2k屏幕参数 ...
- RabbitMQ 从入门到精通(二)
目录 1. 消息如何保障百分之百的投递成功? 1.1 方案一:消息落库,对消息状态进行打标 1.2 方案二:消息的延迟投递,做二次确认,回调检查 2. 幂等性 2.1 幂等性是什么? 2.2 消息端幂 ...
- 题解 P2949 【[USACO09OPEN]工作调度Work Scheduling】
P2949 [USACO09OPEN]工作调度Work Scheduling 题目标签是单调队列+dp,萌新太弱不会 明显的一道贪心题,考虑排序先做截止时间早的,但我们发现后面可能会出现价值更高却没有 ...
- restapi(2)- generic restful CRUD:通用的restful风格数据库表维护工具
研究关于restapi的初衷是想搞一套通用的平台数据表维护http工具.前面谈过身份验证和使用权限.文件的上传下载,这次来到具体的数据库表维护.我们在这篇示范里设计一套通用的对平台每一个数据表的标准维 ...
- sql nvarchar类型和varchar类型存储中文字符长度
今天遇到了,随手记录一下. sql server 存储数据里面 NVARCHAR 记录中文的时候是 一个中文对应一个字符串长度,记录英文也是一个字母一个长度 标点符号也是一样. ...