配置 Elasticsearch 集群
Elasticsearch 的安装非常简单,笔者在前文《单机部署 ELK》中已经介绍过了,本文主要介绍集群的配置,并解释常见配置参数的含义。
要配置集群,最简单的情况下,设置下面几个参数就可以了:
cluster.name: es-cluster
node.name: es-node-
discovery.zen.ping.unicast.hosts: ["192.168.1.101","192.168.1.102"]
discovery.zen.minimum_master_nodes:
本文的演示环境为 Ubuntu Server 18.04,Elasticsearch 的版本为 6.2.4。
配置文件
在 Ubuntu 中使用 deb 包安装的 Elasticsearch 的默认安装目录为:
/usr/share/elasticsearch
但是 Elasticsearch 的配置文件确不在这里,配置文件的目录为:
/etc/elasticsearch
注意,这个目录及其所有内容的所有者都是 root,属于 elasticsearch 用户组。本文我们主要关注的配置文件为 /etc/elasticsearch/elasticsearch.yml。
配置集群的名称
一个节点只有与集群中的所有其他节点拥有相同的 master.name 时才能加入集群。默认的集群名称是 elasticsearch,最好是设置为合适的名字,否则可能和现有的集群同名。下面的配置把集群命名为 es-cluster:
cluster.name: es-cluster
注意:确保不要在不同的环境中重用相同的集群名称,否则可能会导致节点加入错误的集群。
配置节点的名称
如果不设置节点的名称 node.name,默认情况下,Elasticsearch 将使用随机生成的 UUID 的前七个字符作为节点的 ID,并且这个随机的字符串会被持久化下来,即使重启系统也不会丢失。但是为了提高系统的可读性,我们最好是为每个节点设置一个合适的名字:
node.name: es-node-
或者是干脆设置为主机的名称:
node.name: ${HOSTNAME}
列出集群中的所有节点
Elasticsearch 自己实现了一个名称为 "Zen Discovery" 的发现节点并从集群的节点间选取主节点的功能。在集群的配置中一定要配置两个与 "Zen Discovery" 相关的配置项,其中的一个为 discovery.zen.ping.unicast.hosts。
在不进行任何网络配置的情况下,Elasticsearch 将绑定到可用的环回地址,并扫描端口 9300 到 9305,以尝试连接到同一服务器上运行的其他节点。这提供了一种无需进行任何配置的自动集群体验。当需要在其他服务器上使用节点组成集群时,必须通过 discovery.zen.ping.unicast.hosts 提供集群中其他节点的列表:
discovery.zen.ping.unicast.hosts: ["192.168.1.101","192.168.1.102"]
除了 IP 地址,这里也可以使用主机名(hostname)。
配置最小 master 节点数
另一个必须要设置的 "Zen Discovery" 相关的配置项为 discovery.zen.minimum_master_nodes。它的默认值是1,该属性定义的是为了组成一个集群,相互连接的候选主结点的最小数目,强烈推荐该属性的设置使用多数原则:(master_eligible_nodes / 2) + 1,既能避免出现脑裂(split-brain),又能在故障发生后,快速选举出新的主结点。例如:有 5 个候选主结点,推荐把该属性设置为 3。由于本文演示的 demo 中只有两个节点,因此把该值设置为 1:
discovery.zen.minimum_master_nodes:
脑裂(split-brain):
为了解释,假设您有一个由两个候选节点组成的集群。网络故障中断了这两个节点之间的通信。每个节点都看到一个符合主节点资格的节点,此时如果 minimum_master_nodes 设置为默认值 1,这就足以形成一个集群。每个节点都选择自己作为新的主节点(认为另一个候选节点已经死亡),结果是两个集群,或一个分裂的大脑。在重新启动一个节点之前,这两个节点永远不会重新连接。如果重新启动其中的一个节点,那么已写入该节点的任何数据都将丢失。
假设您有一个集群,其中有三个候选节点,minimum_master_nodes 被设置为 2。如果网络分裂将一个节点与其他两个节点分开,则拥有一个节点的一方无法看到足够的符合主控资格的节点,并将意识到它无法选择自己作为主控节点。拥有两个节点的端将选择一个新的主节点(如果需要)并继续正常工作。一旦网络分裂得到解决,单个节点将重新加入集群并再次开始服务请求。
至此一个非常简单的双节点集群就配置完成了,重启节点上的 Elasticsearch 服务,就可在 Kibana 上看到集群中节点的信息了:
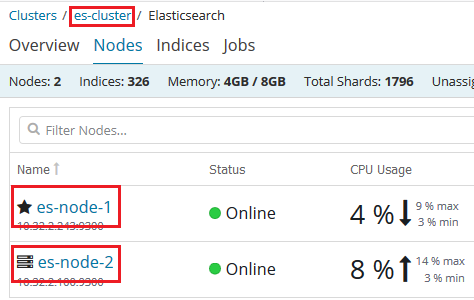
其它重要的配置
只配置上面的四个属性就可以把集群搭建起来了。但是理解并配置另外一些重要的信息能让 Elasticsearch 节点及整个集群更加高效,下面是个人认为一些比较重要的配置。
候选节点(Master Eligible Node)
主节点负责在集群范围内执行轻量级操作,比如创建或删除索引、跟踪哪些节点是集群的一部分,以及决定将哪些分片分配给哪些节点。对于集群健康来说,拥有一个稳定的主节点非常重要。
任何候选节点(默认情况下所有节点都是候选节点)都可以被选举为主节点。也就是说节点默认的 node.master 值为 true:
node.master: true
索引和搜索数据是 CPU、内存和 I/O 密集型操作,这会对节点的资源造成压力。为了确保主节点是稳定的,并且没有压力,在规模比较大的集群中,最好把节点划分为不同的角色,比如专用的候选节点和专用的数据节点。因此精细一点的配置会让主节点只负责轻量级的操作:
node.master: true
node.data: false
node.ingest: false
search.remote.connect: false
虽然主节点也可以作为协调节点,将客户机的搜索和索引请求路由到数据节点,但是最好不要让主节点做这样的事情。对于集群的稳定性来说,主节点所做的工作越少越好。因此可以设置专门的协调节点做这些工作,后面会有介绍。
数据节点(Data Node)
数据节点持有包含已索引文档的切片。数据节点处理与数据相关的操作,如 CRUD、搜索和聚合。这些操作是 CPU、内存和 I/O 密集型操作。因此需要监视这些资源,并在它们过载时添加更多的数据节点。下面的配置把节点设置为专用的 Data Node:
node.master: false
node.data: true
node.ingest: false
search.remote.connect: false
摄取节点(Ingest Node)
摄取节点可以执行由一个或多个摄取处理器组成的预处理管道。根据摄取处理器执行的操作类型和所需的资源,使用专用的摄取节点可能是有意义的,这些节点只执行这个特定的任务。下面的配置把节点设置为专用的 Ingest Node:
node.master: false
node.data: false
node.ingest: true
search.remote.connect: false
协调节点(Cordinating only node)
搜索请求或批量索引请求等请求可能涉及不同数据节点上的数据。例如,搜索请求分两个阶段执行,这两个阶段由接收客户机请求的节点(协调节点)协调。
在分散阶段,协调节点将请求转发给持有数据的数据节点。每个数据节点在本地执行请求并将结果返回给协调节点。在收集阶段,协调节点将每个数据节点的结果简化为单个全局结果集。
每个节点都是隐式的协调节点。如果取消了节点的候选资格、保存数据的能力和预处理文档的能力,那么它就只剩下一个协调节点的功能,它只能路由请求、处理 search reduce 阶段和分发批量索引。
只有协调节点才能从数据节点和候选节点中卸载协调节点角色,从而使大型集群受益。它们加入集群后,像其他节点一样接收完整的集群状态,并使用集群状态将请求直接路由到适当的位置。下面的配置把节点设置为专用的协调节点:
node.master: false
node.data: false
node.ingest: false
search.remote.connect: false
配置节点的 IP 地址
默认情况下,Elasticsearch 只绑定到回环地址,例如:127.0.0.1 (::1)。这样只能从该服务器上访问 Elasticsearch。事实上,可以从单个节点上相同的 $ES_HOME 位置启动多个节点。这对于测试 Elasticsearch 形成集群的能力很有用,但不推荐用于生产环境。
为了与其他服务器上的节点通信并形成集群,需要把节点绑定到一个非回环地址。虽然有许多网络配置项,但通常只需要配置:
network.host: 192.168.1.101
注意,一旦为 network.host 提供了自定义设置。Elasticsearch 就假设您正在从开发模式转移到生产模式,并将许多系统启动检查从警告升级到异常。
一个简要的示例
下面是一个简要的 3 节点机器的配置示例:
# node
cluster.name: es-cluster
node.name: es-node-
node.master: true
path.data: /var/lib/elasticsearch
path.logs: /var/log/elasticsearch
network.host: 10.32.2.100
discovery.zen.ping.unicast.hosts: ["10.32.2.101", "10.32.2.102"]
discovery.zen.minimum_master_nodes: # node
cluster.name: es-cluster
node.name: es-node-
node.master: true
path.data: /var/lib/elasticsearch
path.logs: /var/log/elasticsearch
network.host: 10.32.2.101
discovery.zen.ping.unicast.hosts: ["10.32.2.100", "10.32.2.102"]
discovery.zen.minimum_master_nodes: # node
cluster.name: es-cluster
node.name: es-node-
node.master: true
path.data: /var/lib/elasticsearch
path.logs: /var/log/elasticsearch
network.host: 10.32.2.102
discovery.zen.ping.unicast.hosts: ["10.32.2.100", "10.32.2.101"]
discovery.zen.minimum_master_nodes:
参考:
Important Elasticsearch configuration
elasticsearch 集群搭建及参数详解
ElasticSearch入门 第二篇:集群配置
Elasticsearch Node
配置 Elasticsearch 集群的更多相关文章
- ELK5+redhat7.4配置elasticsearch集群
ELK介绍 ELK是三个开源软件的缩写,即elasticsearch.logstack.kibana. Elasticsearch:开源分布式搜索引擎,提供搜集.分析.存储数据三大功能.它的特点有:分 ...
- ES2:ElasticSearch 集群配置
ElasticSearch共有两个配置文件,都位于config目录下,分别是elasticsearch.yml和logging.yml,其中,elasticsearch.yml 用来配置Elastic ...
- Elasticsearch集群搭建教程及生产环境配置
Elasticsearch 是一个极其强大的搜索和分析引擎,其强大的部分在于能够对其进行扩展以获得更好的性能和稳定性. 本教程将提供有关如何设置 Elasticsearch 集群的一些信息,并将添加一 ...
- 我的ElasticSearch集群部署总结--大数据搜索引擎你不得不知
摘要:世上有三类书籍:1.介绍知识,2.阐述理论,3.工具书:世间也存在两类知识:1.技术,2.思想.以下是我在部署ElasticSearch集群时的经验总结,它们大体属于第一类知识“techknow ...
- 01篇ELK日志系统——升级版集群之elasticsearch集群的搭建
[ 前言:以前搭了个简单的ELK日志系统,以我个人的感觉来说,ELK日志系统还是非常好用的.以前没有弄这个ELK日志系统的时候,线上的项目出了bug,报错了,要定位错误是什么,错误出现在哪个java代 ...
- Ubuntu 14.04中Elasticsearch集群配置
Ubuntu 14.04中Elasticsearch集群配置 前言:本文可用于elasticsearch集群搭建参考.细分为elasticsearch.yml配置和系统配置 达到的目的:各台机器配置成 ...
- Elasticsearch集群配置以及REST API使用
ES安装与启动 在官网下载压缩包,解压后直接运行bin目录下的.bat文件即可.下载地址戳这里. ES配置集群 Elasticsearch配置集群很简单,只要配置一个集群的 名称 ,ES就会自动寻找并 ...
- elasticsearch 集群配置
2015-10-10 09:56 by 轩脉刃, 999 阅读, 1 评论, 收藏, 编辑 elasticsearch 集群 搭建elasticsearch的集群 现在假设我们有3台es机器,想要把他 ...
- Elasticsearch集群节点配置详解
注意:如果是在局域网中运行elasticsearch集群也是很简单的,只要cluster.name设置一致,并且机器在同一网段下,启动的es会自动发现对方,组成集群. 2.elasticsearch- ...
随机推荐
- 【CSS】398- 原生JS实现DOM爆炸效果
爆炸动效分享 前言 此次分享是一次自我组件开发的总结,还是有很多不足之处,望各位大大多提宝贵意见,互相学习交流. 分享内容介绍 通过原生js代码,实现粒子爆炸效果组件 组件开发过程中,使用到了公司内部 ...
- rails 中各种去重查询操作
Table.select("DISTINCT name").map(&:name) : DISTINCT name去重查询name Table.active.map{|x| ...
- JS基础-事件
事件机制 事件触发三阶段 事件触发有三个阶段: window 往事件触发处传播,遇到注册的捕获事件会触发 传播到事件触发处时触发注册的事件 从事件触发处往 window 传播,遇到注册的冒泡事件会触发 ...
- 35个Java代码优化的细节,你知道几个?
前言 代码 优化 ,一个很重要的课题.可能有些人觉得没用,一些细小的地方有什么好修改的,改与不改对于代码的运行效率有什么影响呢?这个问题我是这么考虑的,就像大海里面的鲸鱼一样,它吃一条小虾米有用吗?没 ...
- Redis面试热点工程架构篇之数据同步
温馨提示 更佳阅读体验:[决战西二旗]|Redis面试热点之工程架构篇[2] 前言 前面用了3篇文章介绍了一些底层实现和工程架构相关的问题,鉴于Redis的热点问题还是比较多的,因此今天继续来看工程架 ...
- Django 之day02,必会知识点
静态文件配置******* 为什么用户在浏览器中输入的网址能够访问到对应的资源, 前提是后端提前开设该资源的访问,在urls.py文件中进行配置该路由, 如果我的后端没有开设相关的资源,用户是无法访问 ...
- 聊一聊看似简单的Promise.prototype.then()方法
Promise.prototype.then() Proise实例的then方法是定义在原型对象Promise.prototype上的,它的作用是为Promise实例添加状态改变时的回调函数. 该方法 ...
- python基础知识第二篇(字符串)
基本数据类型 数字 整形 int ---int 将字符串 ...
- Poco的介绍和入门教学
版权声明:该文章为AirtestProject原创文章:允许转载,但转载必须注明“转载”并保留原链接 前言 前面我们已经介绍了基于图像识别的测试框架Airtest,通过图像识别,已经可以编写大部分的测 ...
- QT--TCP网络编程(客户端/服务器)
QT -----TCP网络编程 1.主要流程 1.客户端 创建QTcpSocket对象 连接到服务器 --connectToHost() 发送数据 ---write() 读取数据 ---readA ...