Hadoop 学习之路(四)—— Hadoop单机伪集群环境搭建
一、前置条件
Hadoop的运行依赖JDK,需要预先安装,安装步骤见:
二、配置免密登录
Hadoop组件之间需要基于SSH进行通讯。
2.1 配置映射
配置ip地址和主机名映射:
vim /etc/hosts
# 文件末尾增加
192.168.43.202 hadoop001
2.2 生成公私钥
执行下面命令行生成公匙和私匙:
ssh-keygen -t rsa
3.3 授权
进入~/.ssh目录下,查看生成的公匙和私匙,并将公匙写入到授权文件:
[root@@hadoop001 sbin]# cd ~/.ssh
[root@@hadoop001 .ssh]# ll
-rw-------. 1 root root 1675 3月 15 09:48 id_rsa
-rw-r--r--. 1 root root 388 3月 15 09:48 id_rsa.pub
# 写入公匙到授权文件
[root@hadoop001 .ssh]# cat id_rsa.pub >> authorized_keys
[root@hadoop001 .ssh]# chmod 600 authorized_keys
三、Hadoop(HDFS)环境搭建
3.1 下载并解压
下载Hadoop安装包,这里我下载的是CDH版本的,下载地址为:http://archive.cloudera.com/cdh5/cdh/5/
# 解压
tar -zvxf hadoop-2.6.0-cdh5.15.2.tar.gz
3.2 配置环境变量
# vi /etc/profile
配置环境变量:
export HADOOP_HOME=/usr/app/hadoop-2.6.0-cdh5.15.2
export PATH=${HADOOP_HOME}/bin:$PATH
执行source命令,使得配置的环境变量立即生效:
# source /etc/profile
3.3 修改Hadoop配置
进入${HADOOP_HOME}/etc/hadoop/目录下,修改以下配置:
1. hadoop-env.sh
# JDK安装路径
export JAVA_HOME=/usr/java/jdk1.8.0_201/
2. core-site.xml
<configuration>
<property>
<!--指定namenode的hdfs协议文件系统的通信地址-->
<name>fs.defaultFS</name>
<value>hdfs://hadoop001:8020</value>
</property>
<property>
<!--指定hadoop存储临时文件的目录-->
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/tmp</value>
</property>
</configuration>
3. hdfs-site.xml
指定副本系数和临时文件存储位置:
<configuration>
<property>
<!--由于我们这里搭建是单机版本,所以指定dfs的副本系数为1-->
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
4. slaves
配置所有从属节点的主机名或IP地址,由于是单机版本,所以指定本机即可:
hadoop001
3.4 关闭防火墙
不关闭防火墙可能导致无法访问Hadoop的Web UI界面:
# 查看防火墙状态
sudo firewall-cmd --state
# 关闭防火墙:
sudo systemctl stop firewalld.service
3.5 初始化
第一次启动Hadoop时需要进行初始化,进入${HADOOP_HOME}/bin/目录下,执行以下命令:
[root@hadoop001 bin]# ./hdfs namenode -format
3.6 启动HDFS
进入${HADOOP_HOME}/sbin/目录下,启动HDFS:
[root@hadoop001 sbin]# ./start-dfs.sh
3.7 验证是否启动成功
方式一:执行jps查看NameNode和DataNode服务是否已经启动:
[root@hadoop001 hadoop-2.6.0-cdh5.15.2]# jps
9137 DataNode
9026 NameNode
9390 SecondaryNameNode
方式二:查看Web UI界面,端口为50070:
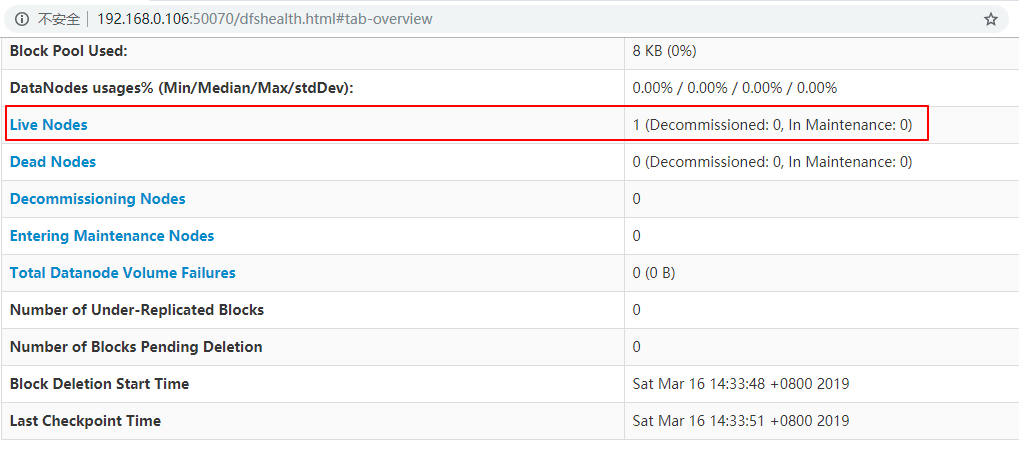
四、Hadoop(YARN)环境搭建
4.1 修改配置
进入${HADOOP_HOME}/etc/hadoop/目录下,修改以下配置:
1. mapred-site.xml
# 如果没有mapred-site.xml,则拷贝一份样例文件后再修改
cp mapred-site.xml.template mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
2. yarn-site.xml
<configuration>
<property>
<!--配置NodeManager上运行的附属服务。需要配置成mapreduce_shuffle后才可以在Yarn上运行MapReduce程序。-->
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
4.2 启动服务
进入${HADOOP_HOME}/sbin/目录下,启动YARN:
./start-yarn.sh
4.3 验证是否启动成功
方式一:执行jps命令查看NodeManager和ResourceManager服务是否已经启动:
[root@hadoop001 hadoop-2.6.0-cdh5.15.2]# jps
9137 DataNode
9026 NameNode
12294 NodeManager
12185 ResourceManager
9390 SecondaryNameNode
方式二:查看Web UI界面,端口号为8088:
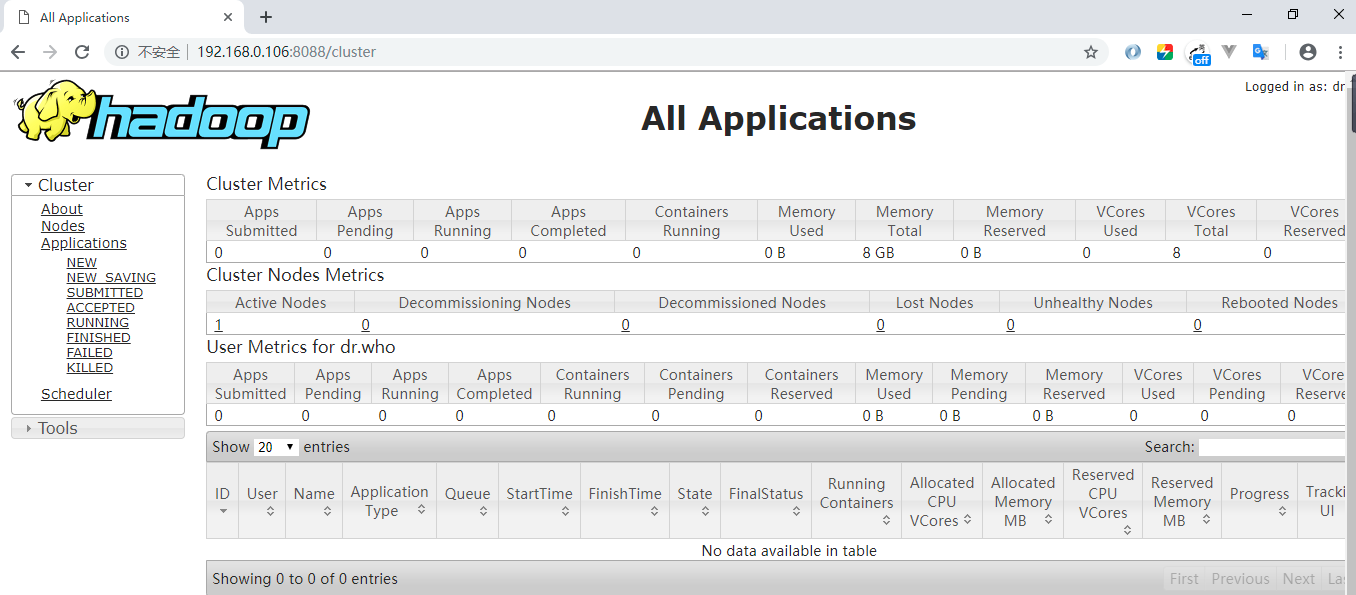
更多大数据系列文章可以参见个人 GitHub 开源项目: 程序员大数据入门指南
Hadoop 学习之路(四)—— Hadoop单机伪集群环境搭建的更多相关文章
- Hadoop学习(一):完全分布式集群环境搭建
1. 设置免密登录 (1) 新建普通用户hadoop:useradd hadoop(2) 在主节点master上生成密钥对,执行命令ssh-keygen -t rsa便会在home文件夹下生成 .ss ...
- ZooKeeper伪集群环境搭建
1.从官网下载程序包. 2.解压. [dev@localhost software]$ tar xzvf zookeeper-3.4.6.tar.gz 3.进入zookeeper文件夹后创建data文 ...
- Storm 学习之路(四)—— Storm集群环境搭建
一.集群规划 这里搭建一个3节点的Storm集群:三台主机上均部署Supervisor和LogViewer服务.同时为了保证高可用,除了在hadoop001上部署主Nimbus服务外,还在hadoop ...
- ZooKeeper学习之路(二)—— Zookeeper单机环境和集群环境搭建
一.单机环境搭建 1.1 下载 下载对应版本Zookeeper,这里我下载的版本3.4.14.官方下载地址:https://archive.apache.org/dist/zookeeper/ # w ...
- 大数据 -- Hadoop集群环境搭建
首先我们来认识一下HDFS, HDFS(Hadoop Distributed File System )Hadoop分布式文件系统.它其实是将一个大文件分成若干块保存在不同服务器的多个节点中.通过联网 ...
- Zookeeper集群搭建(多节点,单机伪集群,Docker集群)
Zookeeper介绍 原理简介 ZooKeeper是一个分布式的.开源的分布式应用程序协调服务.它公开了一组简单的原语,分布式应用程序可以在此基础上实现更高级别的同步.配置维护.组和命名服务.它的设 ...
- Hadoop集群环境搭建步骤说明
Hadoop集群环境搭建是很多学习hadoop学习者或者是使用者都必然要面对的一个问题,网上关于hadoop集群环境搭建的博文教程也蛮多的.对于玩hadoop的高手来说肯定没有什么问题,甚至可以说事“ ...
- redis在Windows下以后台服务一键搭建集群(单机--伪集群)
redis在Windows下以后台服务一键搭建集群(单机--伪集群) 一.概述 此教程介绍如何在windows系统中同一台机器上布置redis伪集群,同时要以后台服务的模式运行.布置以脚本的形式,一键 ...
- Hadoop完全分布式集群环境搭建
1. 在Apache官网下载Hadoop 下载地址:http://hadoop.apache.org/releases.html 选择对应版本的二进制文件进行下载 2.解压配置 以hadoop-2.6 ...
随机推荐
- AVL 树的插入、删除、旋转归纳
参考链接: http://blog.csdn.net/gabriel1026/article/details/6311339 1126号注:先前有一个概念搞混了: 节点的深度 Depth 是指从根 ...
- Android 测试 Appium、Robotium、monkey而其他的框架或工具控制
1. Appium測试 (功能測试,用户接受度測试,黑盒測试) - Rating: 8 Website: http://appium.io/ Appium測试相当于黑盒測试. 仅仅是測试UI逻辑正确性 ...
- User-Agent 列表
<useragentswitcher> <folder description="Internet Explorer"> <useragent des ...
- 如何把Go调用C的性能提升10倍?
目前,当Go需要和C/C++代码集成的时候,大家最先想到的肯定是CGO.毕竟是官方的解决方案,而且简单. 但是CGO是非常慢的.因为CGO其实一个桥接器,通过自动生成代码,CGO在保留了C/C++运行 ...
- MVC 组件之间的关系
View和Controller都可以直接请求Model 但是Model不依赖View和controller lController可以直接请求View来显示具体页面 View不依赖Controller ...
- 获取控件中应用的模版的内部的控件,使用LoadContent()方法获取模版跟节点
treeview获取内部控件元素 Button btnAdd = ((tvks.HeaderTemplate as DataTemplate).LoadContent() as StackPanel) ...
- 【Linux】简单明了查看内存使用和ubuntu的版本号及位数
1.查看ubuntu的版本号:cat /etc/issue 2.查看系统是32位的还是64位:getconf LONG_BIT 3.查看内存使用 free free命令可以用来查看系统内存使用情况,- ...
- /etc/passwd和/etc/group文件详解
用户管理 想要知道, 系统中有哪些用户, 可以查看这个文件: /etc/passwd root:x:::root:/root:/bin/bash bin:x:::bin:/bin:/sbin/nolo ...
- 纯CSS3创意loading文字特效
快速使用Romanysoft LAB的技术实现 HTML 开发Mac OS App,并销售到苹果应用商店中. <HTML开发Mac OS App 视频教程> 土豆网同步更新:http: ...
- elasticsearch.yml 常用参数说明
cluster.name: 指定node所属的cluster. node.name: 本机的hostname. node.master: 是否可以被选举为master节点.(true or false ...