Spark学习之路(三)—— 弹性式数据集RDDs
弹性式数据集RDDs
一、RDD简介
RDD全称为Resilient Distributed Datasets,是Spark最基本的数据抽象,它是只读的、分区记录的集合,支持并行操作,可以由外部数据集或其他RDD转换而来,它具有以下特性:
- 一个RDD由一个或者多个分区(Partitions)组成。对于RDD来说,每个分区会被一个计算任务所处理,用户可以在创建RDD时指定其分区个数,如果没有指定,则默认采用程序所分配到的CPU的核心数;
- RDD拥有一个用于计算分区的函数compute;
- RDD会保存彼此间的依赖关系,RDD的每次转换都会生成一个新的依赖关系,这种RDD之间的依赖关系就像流水线一样。在部分分区数据丢失后,可以通过这种依赖关系重新计算丢失的分区数据,而不是对RDD的所有分区进行重新计算;
- Key-Value型的RDD还拥有Partitioner(分区器),用于决定数据被存储在哪个分区中,目前Spark中支持HashPartitioner(按照哈希分区)和RangeParationer(按照范围进行分区);
- 一个优先位置列表(可选),用于存储每个分区的优先位置(prefered location)。对于一个HDFS文件来说,这个列表保存的就是每个分区所在的块的位置,按照“移动数据不如移动计算“的理念,Spark在进行任务调度的时候,会尽可能的将计算任务分配到其所要处理数据块的存储位置。
RDD[T]抽象类的部分相关代码如下:
// 由子类实现以计算给定分区
def compute(split: Partition, context: TaskContext): Iterator[T]
// 获取所有分区
protected def getPartitions: Array[Partition]
// 获取所有依赖关系
protected def getDependencies: Seq[Dependency[_]] = deps
// 获取优先位置列表
protected def getPreferredLocations(split: Partition): Seq[String] = Nil
// 分区器 由子类重写以指定它们的分区方式
@transient val partitioner: Option[Partitioner] = None
二、创建RDD
RDD有两种创建方式,分别介绍如下:
2.1 由现有集合创建
这里使用spark-shell进行测试,启动命令如下:
spark-shell --master local[4]
启动spark-shell后,程序会自动创建应用上下文,相当于执行了下面的Scala语句:
val conf = new SparkConf().setAppName("Spark shell").setMaster("local[4]")
val sc = new SparkContext(conf)
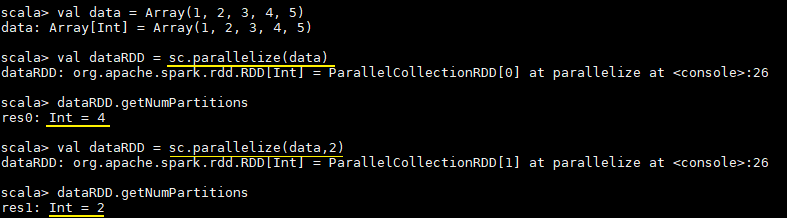
由现有集合创建RDD,你可以在创建时指定其分区个数,如果没有指定,则采用程序所分配到的CPU的核心数:
val data = Array(1, 2, 3, 4, 5)
// 由现有集合创建RDD,默认分区数为程序所分配到的CPU的核心数
val dataRDD = sc.parallelize(data)
// 查看分区数
dataRDD.getNumPartitions
// 明确指定分区数
val dataRDD = sc.parallelize(data,2)
执行结果如下:
2.2 引用外部存储系统中的数据集
引用外部存储系统中的数据集,例如本地文件系统,HDFS,HBase或支持Hadoop InputFormat的任何数据源。
val fileRDD = sc.textFile("/usr/file/emp.txt")
// 获取第一行文本
fileRDD.take(1)
使用外部存储系统时需要注意以下两点:
- 如果在集群环境下从本地文件系统读取数据,则要求该文件必须在集群中所有机器上都存在,且路径相同;
- 支持目录路径,支持压缩文件,支持使用通配符。
2.3 textFile & wholeTextFiles
两者都可以用来读取外部文件,但是返回格式是不同的:
- textFile:其返回格式是
RDD[String],返回的是就是文件内容,RDD中每一个元素对应一行数据; - wholeTextFiles:其返回格式是
RDD[(String, String)],元组中第一个参数是文件路径,第二个参数是文件内容; - 两者都提供第二个参数来控制最小分区数;
- 从HDFS上读取文件时,Spark会为每个块创建一个分区。
def textFile(path: String,minPartitions: Int = defaultMinPartitions): RDD[String] = withScope {...}
def wholeTextFiles(path: String,minPartitions: Int = defaultMinPartitions): RDD[(String, String)]={..}
三、操作RDD
RDD支持两种类型的操作:transformations(转换,从现有数据集创建新数据集)和 actions(在数据集上运行计算后将值返回到驱动程序)。RDD中的所有转换操作都是惰性的,它们只是记住这些转换操作,但不会立即执行,只有遇到 action 操作后才会真正的进行计算,这类似于函数式编程中的惰性求值。
val list = List(1, 2, 3)
// map 是一个transformations操作,而foreach是一个actions操作
sc.parallelize(list).map(_ * 10).foreach(println)
// 输出: 10 20 30
四、缓存RDD
4.1 缓存级别
Spark速度非常快的一个原因是RDD支持缓存。成功缓存后,如果之后的操作使用到了该数据集,则直接从缓存中获取。虽然缓存也有丢失的风险,但是由于RDD之间的依赖关系,如果某个分区的缓存数据丢失,只需要重新计算该分区即可。
Spark支持多种缓存级别 :
| Storage Level (存储级别) |
Meaning(含义) |
|---|---|
MEMORY_ONLY |
默认的缓存级别,将 RDD以反序列化的Java对象的形式存储在 JVM 中。如果内存空间不够,则部分分区数据将不再缓存。 |
MEMORY_AND_DISK |
将 RDD 以反序列化的Java对象的形式存储JVM中。如果内存空间不够,将未缓存的分区数据存储到磁盘,在需要使用这些分区时从磁盘读取。 |
MEMORY_ONLY_SER |
将 RDD 以序列化的Java对象的形式进行存储(每个分区为一个 byte 数组)。这种方式比反序列化对象节省存储空间,但在读取时会增加CPU的计算负担。仅支持Java和Scala 。 |
MEMORY_AND_DISK_SER |
类似于MEMORY_ONLY_SER,但是溢出的分区数据会存储到磁盘,而不是在用到它们时重新计算。仅支持Java和Scala。 |
DISK_ONLY |
只在磁盘上缓存RDD |
MEMORY_ONLY_2, MEMORY_AND_DISK_2, etc |
与上面的对应级别功能相同,但是会为每个分区在集群中的两个节点上建立副本。 |
OFF_HEAP |
与MEMORY_ONLY_SER类似,但将数据存储在堆外内存中。这需要启用堆外内存。 |
启动堆外内存需要配置两个参数:
- spark.memory.offHeap.enabled :是否开启堆外内存,默认值为false,需要设置为true;
- spark.memory.offHeap.size : 堆外内存空间的大小,默认值为0,需要设置为正值。
4.2 使用缓存
缓存数据的方法有两个:persist和cache 。cache内部调用的也是persist,它是persist的特殊化形式,等价于persist(StorageLevel.MEMORY_ONLY)。示例如下:
// 所有存储级别均定义在StorageLevel对象中
fileRDD.persist(StorageLevel.MEMORY_AND_DISK)
fileRDD.cache()
4.3 移除缓存
Spark会自动监视每个节点上的缓存使用情况,并按照最近最少使用(LRU)的规则删除旧数据分区。当然,你也可以使用RDD.unpersist()方法进行手动删除。
五、理解shuffle
5.1 shuffle介绍
在Spark中,一个任务对应一个分区,通常不会跨分区操作数据。但如果遇到reduceByKey等操作,Spark必须从所有分区读取数据,并查找所有键的所有值,然后汇总在一起以计算每个键的最终结果 ,这称为Shuffle。
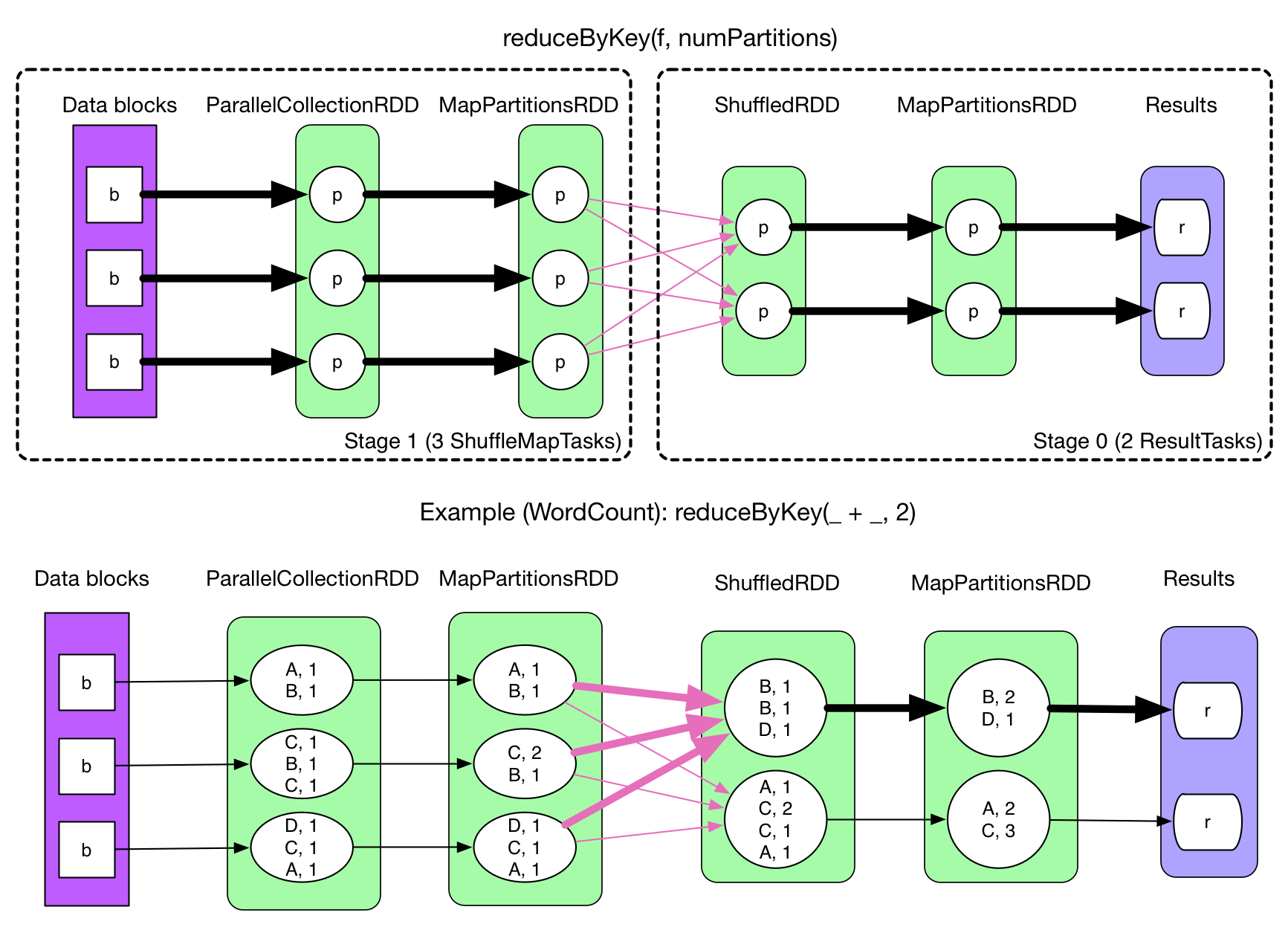
5.2 Shuffle的影响
Shuffle是一项昂贵的操作,因为它通常会跨节点操作数据,这会涉及磁盘I/O,网络I/O,和数据序列化。某些Shuffle操作还会消耗大量的堆内存,因为它们使用堆内存来临时存储需要网络传输的数据。Shuffle还会在磁盘上生成大量中间文件,从Spark 1.3开始,这些文件将被保留,直到相应的RDD不再使用并进行垃圾回收,这样做是为了避免在计算时重复创建Shuffle文件。如果应用程序长期保留对这些RDD的引用,则垃圾回收可能在很长一段时间后才会发生,这意味着长时间运行的Spark作业可能会占用大量磁盘空间,通常可以使用spark.local.dir参数来指定这些临时文件的存储目录。
5.3 导致Shuffle的操作
由于Shuffle操作对性能的影响比较大,所以需要特别注意使用,以下操作都会导致Shuffle:
- 涉及到重新分区操作: 如
repartition和coalesce; - 所有涉及到ByKey的操作:如
groupByKey和reduceByKey,但countByKey除外; - 联结操作:如
cogroup和join。
五、宽依赖和窄依赖
RDD和它的父RDD(s)之间的依赖关系分为两种不同的类型:
- 窄依赖(narrow dependency):父RDDs的一个分区最多被子RDDs一个分区所依赖;
- 宽依赖(wide dependency):父RDDs的一个分区可以被子RDDs的多个子分区所依赖。
如下图,每一个方框表示一个RDD,带有颜色的矩形表示分区:
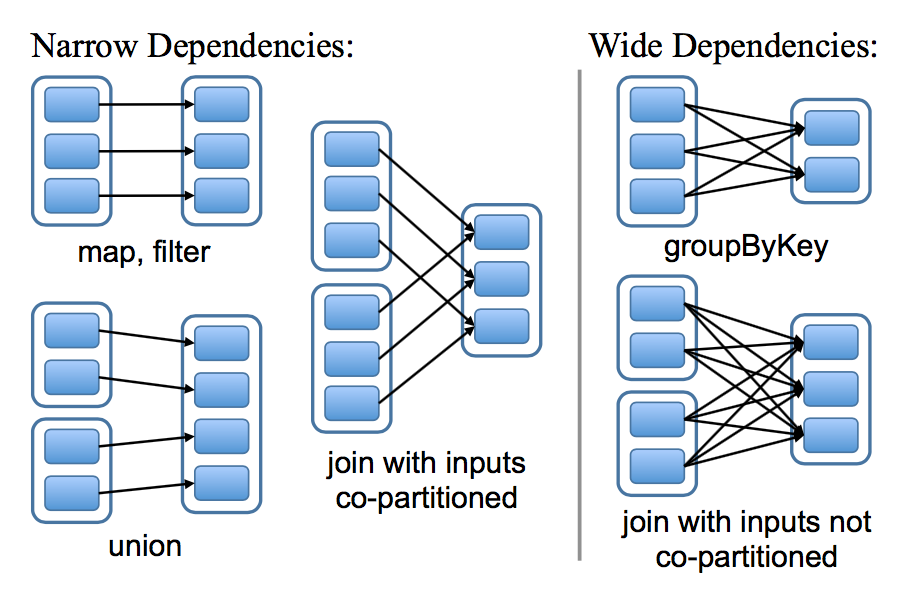
区分这两种依赖是非常有用的:
- 首先,窄依赖允许在一个集群节点上以流水线的方式(pipeline)对父分区数据进行计算,例如先执行map操作,然后执行filter操作。而宽依赖则需要计算好所有父分区的数据,然后再在节点之间进行Shuffle,这与MapReduce类似。
- 窄依赖能够更有效地进行数据恢复,因为只需重新对丢失分区的父分区进行计算,且不同节点之间可以并行计算;而对于宽依赖而言,如果数据丢失,则需要对所有父分区数据进行计算并再次Shuffle。
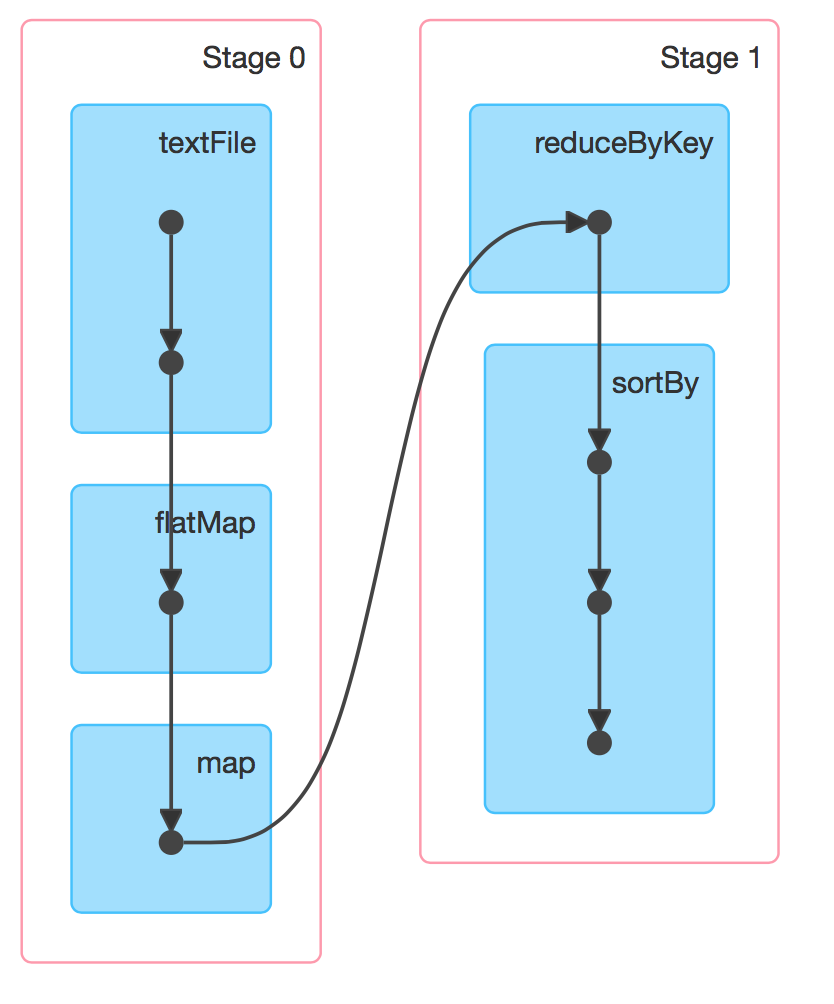
六、DAG的生成
RDD(s)及其之间的依赖关系组成了DAG(有向无环图),DAG定义了这些RDD(s)之间的Lineage(血统)关系,通过血统关系,如果一个RDD的部分或者全部计算结果丢失了,也可以重新进行计算。那么Spark是如何根据DAG来生成计算任务呢?主要是根据依赖关系的不同将DAG划分为不同的计算阶段(Stage):
- 对于窄依赖,由于分区的依赖关系是确定的,其转换操作可以在同一个线程执行,所以可以划分到同一个执行阶段;
- 对于宽依赖,由于Shuffle的存在,只能在父RDD(s)被Shuffle处理完成后,才能开始接下来的计算,因此遇到宽依赖就需要重新划分阶段。
参考资料
- 张安站 . Spark技术内幕:深入解析Spark内核架构设计与实现原理[M] . 机械工业出版社 . 2015-09-01
- RDD Programming Guide
- RDD:基于内存的集群计算容错抽象
更多大数据系列文章可以参见个人 GitHub 开源项目: 程序员大数据入门指南
Spark学习之路(三)—— 弹性式数据集RDDs的更多相关文章
- Spark 系列(三)—— 弹性式数据集RDDs
一.RDD简介 RDD 全称为 Resilient Distributed Datasets,是 Spark 最基本的数据抽象,它是只读的.分区记录的集合,支持并行操作,可以由外部数据集或其他 RDD ...
- [转]Spark学习之路 (三)Spark之RDD
Spark学习之路 (三)Spark之RDD https://www.cnblogs.com/qingyunzong/p/8899715.html 目录 一.RDD的概述 1.1 什么是RDD? ...
- 弹性式数据集RDD
弹性式数据集RDD 一.RDD简介二.创建RDD 2.1 由现有集合创建 2.2 引用外部存储系统中的数据集 2.3 textFile & who ...
- 学习之路三十九:新手学习 - Windows API
来到了新公司,一开始就要做个程序去获取另外一个程序里的数据,哇,挑战性很大. 经过两周的学习,终于搞定,主要还是对Windows API有了更多的了解. 文中所有的消息常量,API,结构体都整理出来了 ...
- Spark学习之路 (三)Spark之RDD
一.RDD的概述 1.1 什么是RDD? RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是Spark中最基本的数据抽象,它代表一个不可变.可分区.里面的元素 ...
- Spark学习之路 (三)Spark之RDD[转]
RDD的概述 什么是RDD? RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是Spark中最基本的数据抽象,它代表一个不可变.可分区.里面的元素可并行计算的 ...
- Spark学习之路 (一)Spark初识
目录 一.官网介绍 1.什么是Spark 二.Spark的四大特性 1.高效性 2.易用性 3.通用性 4.兼容性 三.Spark的组成 四.应用场景 正文 回到顶部 一.官网介绍 1.什么是Spar ...
- Spark学习之路 (十一)SparkCore的调优之Spark内存模型
摘抄自:https://www.ibm.com/developerworks/cn/analytics/library/ba-cn-apache-spark-memory-management/ind ...
- Spark学习之路 (十一)SparkCore的调优之Spark内存模型[转]
概述 Spark 作为一个基于内存的分布式计算引擎,其内存管理模块在整个系统中扮演着非常重要的角色.理解 Spark 内存管理的基本原理,有助于更好地开发 Spark 应用程序和进行性能调优.本文旨在 ...
随机推荐
- ValueStack和OGNL达到Struts2形式的数据存储原理
(1)最近学习struts相框,我们在快乐struts强大.为了便于使用转发,但不了解详细的内部数据存储: (2)网上找了很多关于struts数据存储的原理,但我还没有找到一个具体的解释,本书上找到了 ...
- WPF 走马灯 文字滚动 自定义控件
原文:WPF 走马灯 文字滚动 自定义控件 /// <summary> /// Label走马灯自定义控件 /// </summary> [ToolboxBitmap(type ...
- sdut 5-1 继承和派生
5-1 继承与派生 Time Limit: 1000MS Memory limit: 65536K 题目描写叙述 通过本题目的练习能够掌握继承与派生的概念.派生类的定义和用法.当中派生类构造函数的定义 ...
- asp .net 页面跳转
ajax异步 通过ajax去请求数据,然后在js里面得到返回结果,赋值location.href <div> <input id="url" /> < ...
- abp项目 从sql server迁移至mysql
官方资料:https://aspnetboilerplate.com/Pages/Documents/EF-MySql-Integration 实验发现,还差了两步 整理一下,步骤如下: 1.引用My ...
- Stream转Byte数组
//获得当前文件目录 string rootPath = Directory.GetCurrentDirectory(); string path = rootPath + "Your Fi ...
- 多线程Parallel和Task
不管是Parallel还是Task,最里面都是线程池(里面是线程)当开启多个任务后,系统会根据当前的线程池的资源进行分配,任务则进行等待Parallel可以对系统的CPU进行设置,可以最大程度上榨干系 ...
- linuxC动态内存泄漏追踪方法
C里面没有垃圾回收机制,有时候你申请了动态内存却忘记释放,这就尴尬了(你的程序扮演了强盗角色,有借有还才是好孩子).当你想找出内存泄露的地方时,有的投入海量的代码中,头痛不已.还好GNU C库提供了些 ...
- Win10 如何以管理员身份设置开机自启程序(2)
原文:Win10 如何以管理员身份设置开机自启程序(2) 自己水平太菜,对Windows的权限问题一直不是特别了解.之前在<Win10 如何以管理员身份设置开机自启程序(1)>一文中介绍了 ...
- delphi备份恢复剪切板(使用了GlobalLock API函数和CopyMemory)
看了季世平老兄的C++代码后翻译过来的 unit clipbak; interface uses SysUtils, Classes, Clipbrd, Windows, Contnrs; type ...