DFS和BFS的比较
DFS(Depth First Search,深度优先搜索)和BFS(Breadth First Search,广度优先搜索)是两种典型的搜索算法。下面通过一个实例来比较一下深度优先搜索和广度优先搜索的搜索过程。
【例1】马的行走路径
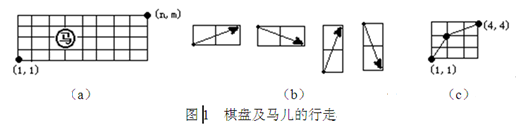
设有一个n*m的棋盘(2<=n<=50,2<=m<=50),在棋盘上任一点有一个中国象棋马,如图1(a)所示。马行走的规则为:(1)马走日字;(2)马只能向右走,即如图1(b)所示的4种走法。
编写一个程序,输入n和m,找出一条马从棋盘左下角(1,1)到右上角(n,m)的路径。例如:输入n=4、m=4时,输出路径 (1,1)->(2,3)->(4,4)。这一路经如图1(c)所示。若不存在路径,则输出"No!"
(1)编程思路。
将棋盘的横坐标规定为i,纵坐标规定为j,对于一个n×m的棋盘,i的值从1到n,j的值从1到m。棋盘上的任意点都可以用坐标(i,j)表示。
马有四种移动方向,每种移动方法用偏移值来表示,将这些偏移值分别保存在数组dx和dy中,可定义数组int dx[4]={1,1,2,2}和int dy[4]={-2,2,-1,1}。
定义数组int visit[51][51]标记某位置马儿是否已走过,初始时visit数组的所有元素值均为0,visit[i][j]=0表示坐标(i,j)处马儿未走过。同时为了后面输出路径方便,在标记visit[i][j]的值时,可以将其设置为其前一个位置的信息,例如visit[i][j] = x*100+y,它表示马儿由坐标(x,y)走到坐标(i,j)处。
(2)采用深度优先搜索编写的源程序。
#include <iostream>
using namespace std;
#define N 51
struct Node
{
int x;
int y;
};
int main()
{
int n,m;
int dx[4]={1,1,2,2};
int dy[4]={-2,2,-1,1};
int visit[N][N]={0};
Node s[N*N],cur,next; // s为栈
int top,i,x,y,t; // top为栈顶指针
cin>>n>>m;
top=-1; // 栈S初始化
cur.x=1; cur.y=1;
visit[1][1]=-1; // 点(1,1)为出发点,无前驱结点
s[++top]=cur; // 初始结点入栈;
bool flag= false; // 置搜索成功标志flag为假
while(top>=0 && !flag) // 栈不为空
{
cur=s[top--]; // 栈顶元素出栈
if (cur.x==n && cur.y==m)
{
flag=true;
x=n; y=m;
while (visit[x][y]!=-1)
{
cout<<"("<<x<<","<<y<<") <-- ";
t=visit[x][y];
x=t/100;
y=t%100;
}
cout<<"(1,1)"<<endl;
break;
}
for (i=0;i<4;i++)
{
x=cur.x+dx[i]; y=cur.y+dy[i];
if(x >=1 && x<=n && y>=0 && y<=m && visit[x][y]==0)
{
visit[x][y] = (cur.x)*100+cur.y; // 映射保存前驱结点信息
next.x=x; next.y=y; // 由cur扩展出新结点next
s[++top]=next; // next结点入栈
}
}
}
if (!flag)
cout<<"No path!"<<endl;
return 0;
}
为理解深度优先搜索的结点访问顺序,可以在上面源程序中的出栈语句后加上一条语句
cout<<"("<<cur.x<<","<<cur.y<<") -- "; 输出结点的出栈访问顺序。
(3)DFS的搜索过程。
以输入5,5为例,用树形结构表示马可能走的所有过程(如下图),求从起点到终点的路径,实际上就是从根结点开始搜索这棵树。
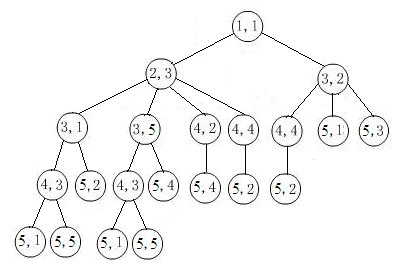
马从(1,1)开始,按深度优先搜索法,扩展出两个结点(2,3)和(3,2)依次入栈,之后(3,2)出栈,即走一步到达(3,2),判断是否到达终点,若没有,则继续往前走,扩展出结点(4,4)、(5,1)、(5,3)依次入栈,再走一步到达(5,3),没有到达终点,继续往前走,(5,3)的下一步所走的位置不在棋盘上,则另选一条路径再走;(5,1)出栈,即走到(5,1);…,直到到达(5,5),搜索过程结束。
以输入5,5为例,输出的深度优先访问顺序为:
(1,1) -- (3,2) -- (5,3) -- (5,1) -- (4,4) -- (5,2) -- (2,3) -- (4,2) -- (5,4) -- (3,5) -- (4,3) -- (5,5)。
(4)采用广度优先搜索编写的源程序。
#include <iostream>
using namespace std;
#define N 51
struct Node
{
int x;
int y;
};
int main()
{
int n,m;
int dx[4]={1,1,2,2};
int dy[4]={-2,2,-1,1};
int visit[N][N]={0};
Node q[N*N],cur,next; // q为队列
int front,rear,i,x,y,t; // front为队头指针,rear队尾指针
cin>>n>>m;
front=rear=0; // 队列q初始化
cur.x=1; cur.y=1;
visit[1][1]=-1; // 点(1,1)为出发点,无前驱结点
q[rear++]=cur; // 初始结点入队
bool flag= false; // 置搜索成功标志flag为假
cout<<"结点访问顺序为:";
while(rear!=front && !flag) // 队列不为空
{
cur=q[front++]; // 队头元素出队
cout<<"("<<cur.x<<","<<cur.y<<") -- ";
if (cur.x==n && cur.y==m)
{
flag=true;
x=n; y=m;
cout<<endl;
cout<<"行走路径为:";
while (visit[x][y]!=-1)
{
cout<<"("<<x<<","<<y<<") <-- ";
t=visit[x][y];
x=t/100;
y=t%100;
}
cout<<"(1,1)"<<endl;
break;
}
for (i=0;i<4;i++)
{
x=cur.x+dx[i]; y=cur.y+dy[i];
if(x >=1 && x<=n && y>=1 && y<=m && visit[x][y]==0)
{
visit[x][y] = (cur.x)*100+cur.y; // 映射保存前驱结点信息
next.x=x; next.y=y; // 由cur扩展出新结点next
q[rear++]=next; // next结点入栈
}
}
}
if (!flag)
cout<<"No path!"<<endl;
return 0;
}
(5)BFS的搜索过程。
结合上面的搜索图,广度优先搜索采用自上而下,从左到右的顺序搜素结点。因此,结点访问顺序为:(1,1) -- (2,3) -- (3,2) -- (3,1) -- (3,5) -- (4,2) -- (4,4) -- (5,1) -- (5,3) -- (4,3) -- (5,2) -- (5,4) -- (5,5)。
DFS和BFS的比较的更多相关文章
- Clone Graph leetcode java(DFS and BFS 基础)
题目: Clone an undirected graph. Each node in the graph contains a label and a list of its neighbors. ...
- 数据结构(12) -- 图的邻接矩阵的DFS和BFS
//////////////////////////////////////////////////////// //图的邻接矩阵的DFS和BFS ////////////////////////// ...
- 数据结构(11) -- 邻接表存储图的DFS和BFS
/////////////////////////////////////////////////////////////// //图的邻接表表示法以及DFS和BFS //////////////// ...
- 在DFS和BFS中一般情况可以不用vis[][]数组标记
开始学dfs 与bfs 时一直喜欢用vis[][]来标记有没有访问过, 现在我觉得没有必要用vis[][]标记了 看代码 用'#'表示墙,'.'表示道路 if(所有情况都满足){ map[i][j]= ...
- 图论中DFS与BFS的区别、用法、详解…
DFS与BFS的区别.用法.详解? 写在最前的三点: 1.所谓图的遍历就是按照某种次序访问图的每一顶点一次仅且一次. 2.实现bfs和dfs都需要解决的一个问题就是如何存储图.一般有两种方法:邻接矩阵 ...
- 图论中DFS与BFS的区别、用法、详解?
DFS与BFS的区别.用法.详解? 写在最前的三点: 1.所谓图的遍历就是按照某种次序访问图的每一顶点一次仅且一次. 2.实现bfs和dfs都需要解决的一个问题就是如何存储图.一般有两种方法:邻接矩阵 ...
- 数据结构基础(21) --DFS与BFS
DFS 从图中某个顶点V0 出发,访问此顶点,然后依次从V0的各个未被访问的邻接点出发深度优先搜索遍历图,直至图中所有和V0有路径相通的顶点都被访问到(使用堆栈). //使用邻接矩阵存储的无向图的深度 ...
- dfs和bfs的区别
详见转载博客:https://www.cnblogs.com/wzl19981116/p/9397203.html 1.dfs(深度优先搜索)是两个搜索中先理解并使用的,其实就是暴力把所有的路径都搜索 ...
- 邻接矩阵实现图的存储,DFS,BFS遍历
图的遍历一般由两者方式:深度优先搜索(DFS),广度优先搜索(BFS),深度优先就是先访问完最深层次的数据元素,而BFS其实就是层次遍历,每一层每一层的遍历. 1.深度优先搜索(DFS) 我一贯习惯有 ...
- 判断图连通的三种方法——dfs,bfs,并查集
Description 如果无向图G每对顶点v和w都有从v到w的路径,那么称无向图G是连通的.现在给定一张无向图,判断它是否是连通的. Input 第一行有2个整数n和m(0 < n,m < ...
随机推荐
- WPF太阳、地球、月球运动轨迹模拟
原文:WPF太阳.地球.月球运动轨迹模拟 版权声明:本文为博主原创文章,未经博主允许不得转载. https://blog.csdn.net/yangyisen0713/article/details/ ...
- 经典数字图像处理(matlab 实现)
Ivan Selesnick(Software) Sparsity / Total variation / Denoising Software - Michael Elad's Personal P ...
- 莱杰:期刊进口流程(文件 ID 1591640.1)
文档内容 概要 _afrLoop=2068767096030752&id=1591640.1&_afrWindowMode=0&_adf.ctrl-state=qivv ...
- Logback 专题
logback-spring.xml <?xml version="1.0" encoding="UTF-8"?> <configuratio ...
- redis 从0 到 1 键值相关命令 服务器相关命令
keys * 获取所有的key 忽略其数据类型 数据为空 返回(empty list or set) keys a* .*b 获取以a开头 或者 以b结尾的key 返回(empty list ...
- jquery hover()的使用
<!DOCTYPE html><html><head><meta http-equiv="Content-Type" content=&q ...
- Lambda表达式的参数捕获
以常用的Action委托为例: 有如下3个无参数的方法: public void Function() { //Do something } public void Function2() { //D ...
- WPF Layout 系统概述——Measure
原文:WPF Layout 系统概述--Measure 前言 在WPF/Silverlight当中,如果已经存在的Element无法满足你特殊的需求,你可能想自定义Element,那么就有可能会面临重 ...
- C#可扩展编程之MEF学习笔记(五):MEF高级进阶(转)
好久没有写博客了,今天抽空继续写MEF系列的文章.有园友提出这种系列的文章要做个目录,看起来方便,所以就抽空做了一个,放到每篇文章的最后. 前面四篇讲了MEF的基础知识,学完了前四篇,MEF中比较常用 ...
- 第一个kotlin程序
class ccc { companion object { @JvmStatic fun main(args: Array<String>) { println("hello! ...