【集合系列】- 深入浅出分析Collection中的List接口
作者:炸鸡可乐
原文出处:www.pzblog.cn
一、List简介
List 的数据结构就是一个序列,存储内容时直接在内存中开辟一块连续的空间,然后将空间地址与索引对应。
以下是List集合简易架构图

由图中的继承关系,可以知道,ArrayList、LinkedList、Vector、Stack都是List的四个实现类。
- AbstractCollection 是一个抽象类,它唯一实现Collection接口的类。AbstractCollection主要实现了toArray()、toArray(T[] a)、remove()等方法。
- AbstractList 也是一个抽象类,它继承于AbstractCollection。AbstractList实现List接口中除size()、get(int location)之外的函数,比如特定迭代器ListIterator。
- AbstractSequentialList 是一个抽象类,它继承于AbstractList。AbstractSequentialList 实现了“链表中,根据index索引值操作链表的全部函数”。
- ArrayList 是一个动态数组,它由数组实现。随机访问效率高,随机插入、随机删除效率低。
- LinkedList 是一个双向链表。它也可以被当作堆栈、队列或双端队列进行操作。LinkedList随机访问效率低,但随机插入、随机删除效率高。
- Vector 也是一个动态数组,和ArrayList一样,也是由数组实现。但是ArrayList是非线程安全的,而Vector是线程安全的。
- Stack 是栈,它继承于Vector。它的特性是:先进后出(FILO, First In Last Out)。
下面对各个实现类进行方法剖析!
二、ArrayList
ArrayList实现了List接口,也是顺序容器,即元素存放的数据与放进去的顺序相同,允许放入null元素,底层通过数组实现。
除该类未实现同步外,其余跟Vector大致相同。
在Java1.5之后,集合还提供了泛型,泛型只是编译器提供的语法糖,方便编程,对程序不会有实质的影响。因为所有的类都默认继承至Object,所以这里的数组是一个Object数组,以便能够容纳任何类型的对象。
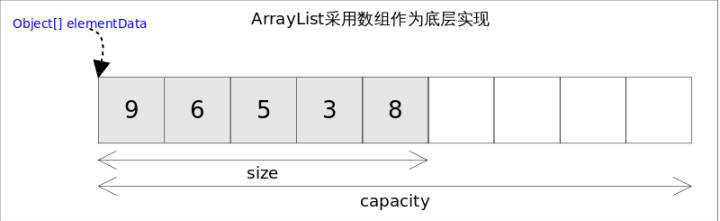
常用方法介绍
2.1、get方法
get()方法同样很简单,先判断传入的下标是否越界,再获取指定元素。
public E get(int index) {rangeCheck(index);return elementData(index);}/*** 检查传入的index是否越界*/private void rangeCheck(int index) {if (index >= size)throw new IndexOutOfBoundsException(outOfBoundsMsg(index));}
2.2、set方法
set()方法也非常简单,直接对数组的指定位置赋值即可。
public E set(int index, E element) {rangeCheck(index);E oldValue = elementData(index);elementData[index] = element;return oldValue;}
2.3、add方法
ArrayList添加元素有两个方法,一个是add(E e),另一个是add(int index, E e)。
这两个方法都是向容器中添加新元素,可能会出现容量(capacity)不足,因此在添加元素之前,都需要进行剩余空间检查,如果需要则自动扩容。扩容操作最终是通过grow()方法完成的。
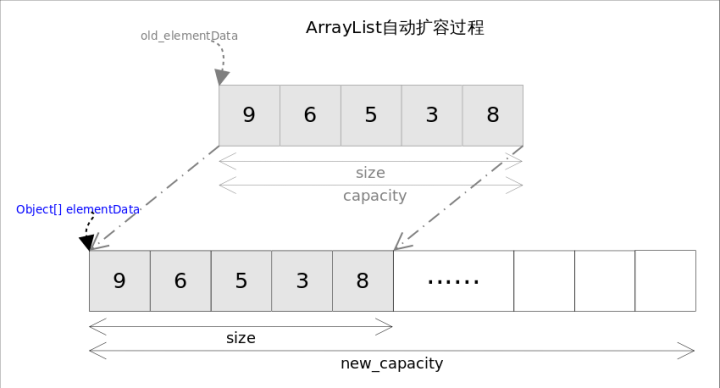
grow方法实现
private void grow(int minCapacity) {// overflow-conscious codeint oldCapacity = elementData.length;int newCapacity = oldCapacity + (oldCapacity >> 1);//原来的1.5倍if (newCapacity - minCapacity < 0)newCapacity = minCapacity;if (newCapacity - MAX_ARRAY_SIZE > 0)newCapacity = hugeCapacity(minCapacity);// minCapacity is usually close to size, so this is a win:elementData = Arrays.copyOf(elementData, newCapacity);}
添加元素还有另外一个addAll()方法,addAll()方法能够一次添加多个元素,根据位置不同也有两个方法,一个是在末尾添加的addAll(Collection<? extends E> c)方法,一个是从指定位置开始插入的addAll(int index, Collection<? extends E> c)方法。
**不同点:addAll()的时间复杂度不仅跟插入元素的多少有关,也跟插入的位置相关,时间复杂度是线性增长!
**
2.4、remove方法
remove()方法也有两个版本,一个是remove(int index)删除指定位置的元素;另一个是remove(Object o),通过o.equals(elementData[index])来删除第一个满足的元素。
需要将删除点之后的元素向前移动一个位置。需要注意的是为了让GC起作用,必须显式的为最后一个位置赋null值。
- remove(int index)方法
public E remove(int index) {rangeCheck(index);modCount++;E oldValue = elementData(index);int numMoved = size - index - 1;if (numMoved > 0)System.arraycopy(elementData, index+1, elementData, index,numMoved);elementData[--size] = null; //赋null值,方便GC回收return oldValue;}
- remove(Object o)方法
public boolean remove(Object o) {if (o == null) {for (int index = 0; index < size; index++)if (elementData[index] == null) {fastRemove(index);return true;}} else {for (int index = 0; index < size; index++)if (o.equals(elementData[index])) {fastRemove(index);return true;}}return false;}
三、LinkedList
在上篇文章中,我们知道LinkedList同时实现了List接口和Deque接口,也就是说它既可以看作一个顺序容器,又可以看作一个队列(Queue),同时又可以看作一个栈(Stack)。
LinkedList底层通过双向链表实现,通过first和last引用分别指向链表的第一个和最后一个元素,注意这里没有所谓的哑元(某个参数如果在子程序或函数中没有用到,那就被称为哑元),当链表为空的时候first和last都指向null。

public class LinkedList<E>extends AbstractSequentialList<E>implements List<E>, Deque<E>, Cloneable, java.io.Serializable{/**容量*/transient int size = 0;/**链表第一个元素*/transient Node<E> first;/**链表最后一个元素*/transient Node<E> last;......}
/*** 内部类Node*/private static class Node<E> {E item;//元素Node<E> next;//后继Node<E> prev;//前驱Node(Node<E> prev, E element, Node<E> next) {this.item = element;this.next = next;this.prev = prev;}}
常用方法介绍
3.1、get方法
get()方法同样很简单,先判断传入的下标是否越界,再获取指定元素。
public E get(int index) {checkElementIndex(index);return node(index).item;}/*** 检查传入的index是否越界*/private void checkElementIndex(int index) {if (!isElementIndex(index))throw new IndexOutOfBoundsException(outOfBoundsMsg(index));}
3.2、set方法
set(int index, E element)方法将指定下标处的元素修改成指定值,也是先通过node(int index)找到对应下表元素的引用,然后修改Node中item的值。
public E set(int index, E element) {checkElementIndex(index);Node<E> x = node(index);E oldVal = x.item;x.item = element;return oldVal;}
3.3、add方法
同样的,add()方法有两方法,一个是add(E e),另一个是add(int index, E element)。
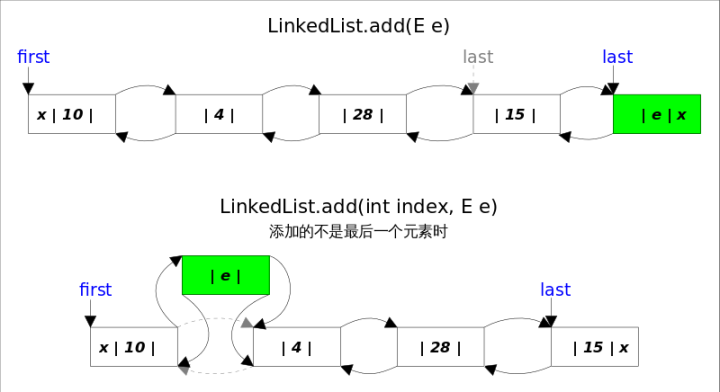
- add(E e)方法
该方法在LinkedList的末尾插入元素,因为有last指向链表末尾,在末尾插入元素的花费是常数时间,只需要简单修改几个相关引用即可。
public boolean add(E e) {linkLast(e);return true;}/*** 添加元素*/void linkLast(E e) {final Node<E> l = last;final Node<E> newNode = new Node<>(l, e, null);last = newNode;if (l == null)//原来链表为空,这是插入的第一个元素first = newNode;elsel.next = newNode;size++;modCount++;}
- add(int index, E element)方法
该方法是在指定下表处插入元素,需要先通过线性查找找到具体位置,然后修改相关引用完成插入操作。
具体分成两步,1.先根据index找到要插入的位置;2.修改引用,完成插入操作。
public void add(int index, E element) {checkPositionIndex(index);if (index == size)//调用add方法,直接在末尾添加元素linkLast(element);else//根据index找到要插入的位置linkBefore(element, node(index));}/*** 插入位置*/void linkBefore(E e, Node<E> succ) {// assert succ != null;final Node<E> pred = succ.prev;final Node<E> newNode = new Node<>(pred, e, succ);succ.prev = newNode;if (pred == null)first = newNode;elsepred.next = newNode;size++;modCount++;}
同样的,添加元素还有另外一个addAll()方法,addAll()方法能够一次添加多个元素,根据位置不同也有两个方法,一个是在末尾添加的addAll(Collection<? extends E> c)方法,另一个是从指定位置开始插入的addAll(int index, Collection<? extends E> c)方法。
里面也for循环添加元素,addAll()的时间复杂度不仅跟插入元素的多少有关,也跟插入的位置相关,时间复杂度是线性增长!
3.4、remove方法
同样的,remove()方法也有两个方法,一个是删除指定下标处的元素remove(int index),另一个是删除跟指定元素相等的第一个元素remove(Object o)。
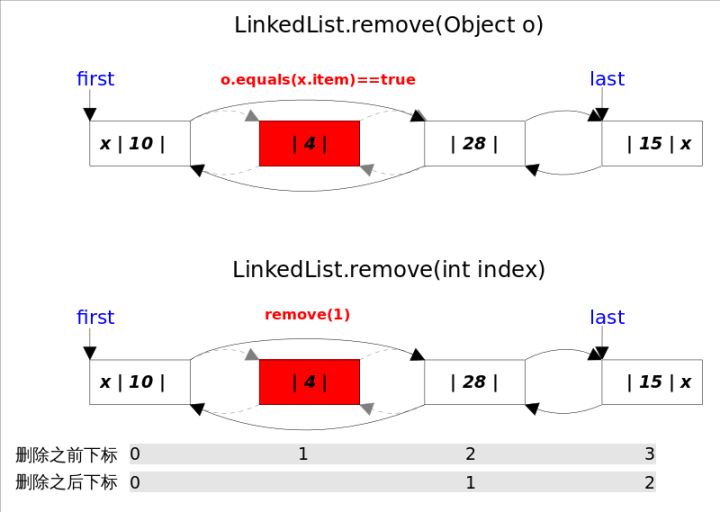
两个删除操作都是,1.先找到要删除元素的引用;2.修改相关引用,完成删除操作。
- remove(int index)方法
通过下表,找到对应的节点,然后将其删除
public E remove(int index) {checkElementIndex(index);return unlink(node(index));}
- remove(Object o)方法
通过equals判断找到对应的节点,然后将其删除
public boolean remove(Object o) {if (o == null) {for (Node<E> x = first; x != null; x = x.next) {if (x.item == null) {unlink(x);return true;}}} else {for (Node<E> x = first; x != null; x = x.next) {if (o.equals(x.item)) {unlink(x);return true;}}}return false;}
删除操作都是通过unlink(Node<E> x)方法完成的。这里需要考虑删除元素是第一个或者最后一个时的边界情况。
/*** 删除一个Node节点方法*/E unlink(Node<E> x) {// assert x != null;final E element = x.item;final Node<E> next = x.next;final Node<E> prev = x.prev;//删除的是第一个元素if (prev == null) {first = next;} else {prev.next = next;x.prev = null;}//删除的是最后一个元素if (next == null) {last = prev;} else {next.prev = prev;x.next = null;}x.item = null;size--;modCount++;return element;}
四、Vector
Vector类属于一个挽救的子类,早在jdk1.0的时候,就已经存在此类,但是到了jdk1.2之后重点强调了集合的概念,所以,先后定义了很多新的接口,比如ArrayList、LinkedList,但考虑到早期大部分已经习惯使用Vector类,所以,为了兼容性,java的设计者,就让Vector多实现了一个List接口,这才将其保留下来。
在使用方面,Vector的get、set、add、remove方法实现,与ArrayList基本相同,不同的是Vector在方法上加了线程同步锁synchronized,所以,执行效率方面,会比较慢!
4.1、get方法
public synchronized E get(int index) {if (index >= elementCount)throw new ArrayIndexOutOfBoundsException(index);return elementData(index);}
4.2、set方法
public synchronized E set(int index, E element) {if (index >= elementCount)throw new ArrayIndexOutOfBoundsException(index);E oldValue = elementData(index);elementData[index] = element;return oldValue;}
4.3、add方法
public synchronized boolean add(E e) {modCount++;ensureCapacityHelper(elementCount + 1);elementData[elementCount++] = e;return true;}
4.4、remove方法
public synchronized boolean removeElement(Object obj) {modCount++;int i = indexOf(obj);if (i >= 0) {removeElementAt(i);return true;}return false;}
五、Stack
在 Java 中 Stack 类表示后进先出(LIFO)的对象堆栈。栈是一种非常常见的数据结构,它采用典型的先进后出的操作方式完成的;在现实生活中,手枪弹夹的子弹就是一个典型的后进先出的结构。
在使用方面,主要方法有push 、peek 、pop 。
5.1、push方法
push方法表示,向栈中添加元素
public E push(E item) {addElement(item);return item;}
5.2、peek方法
peek方法表示,查看栈顶部的对象,但不从栈中移除它
public synchronized E peek() {int len = size();if (len == 0)throw new EmptyStackException();return elementAt(len - 1);}
5.3、pop方法
pop方法表示,移除元素,并将要移除的元素方法
public synchronized E pop() {E obj;int len = size();obj = peek();removeElementAt(len - 1);return obj;}
关于 Java 中 Stack 类,有很多的质疑声,栈更适合用队列结构来实现,这使得Stack在设计上不严谨,因此,官方推荐使用Deque下的类来是实现栈!
六、总结
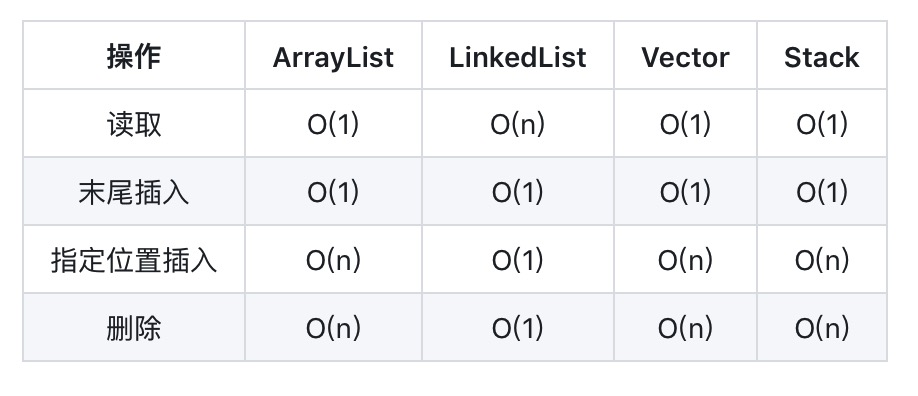
- ArrayList(动态数组结构),查询快(随意访问或顺序访问),增删慢,但在末尾插入,速度与LinkedList相差无几!
- LinkedList(双向链表结构),查询慢,增删快!
- Vector(动态数组结构),相比ArrayList都慢,被ArrayList替代,基本不在使用。优势是线程安全(函数都是synchronized),如果需要在多线程下使用,推荐使用并发容器中的工具类来操作,效率高!
- Stack(栈结构)继承于Vector,数据是先进后出,基本不在使用,如果要实现栈,推荐使用Deque下的ArrayDeque,效率比Stack高!
七、参考
1、JDK1.7&JDK1.8 源码
3、博客园 - 朽木 - ArrayList、LinkedList、Vector、Stack的比较
【集合系列】- 深入浅出分析Collection中的List接口的更多相关文章
- Java 集合系列02之 Collection架构
概要 首先,我们对Collection进行说明.下面先看看Collection的一些框架类的关系图: Collection是一个接口,它主要的两个分支是:List 和 Set. List和Set都是接 ...
- 【转】Java 集合系列02之 Collection架构
概要 首先,我们对Collection进行说明.下面先看看Collection的一些框架类的关系图: Collection是一个接口,它主要的两个分支是:List 和 Set. List和Set都是接 ...
- Java 集合系列目录(Category)
下面是最近总结的Java集合(JDK1.6.0_45)相关文章的目录. 01. Java 集合系列01之 总体框架 02. Java 集合系列02之 Collection架构 03. Java 集合系 ...
- 【集合系列】- 深入浅出的分析TreeMap
一.摘要 在集合系列的第一章,咱们了解到,Map的实现类有HashMap.LinkedHashMap.TreeMap.IdentityHashMap.WeakHashMap.Hashtable.Pro ...
- 【集合系列】- 深入浅出的分析 Hashtable
一.摘要 在集合系列的第一章,咱们了解到,Map 的实现类有 HashMap.LinkedHashMap.TreeMap.IdentityHashMap.WeakHashMap.Hashtable.P ...
- 【集合系列】- 深入浅出分析HashMap
一.摘要 在集合系列的第一章,咱们了解到,Map的实现类有HashMap.LinkedHashMap.TreeMap.IdentityHashMap.WeakHashMap.Hashtable.Pro ...
- 【集合系列】- 深入浅出的分析 Set集合
一.摘要 关于 Set 接口,在实际开发中,其实很少用到,但是如果你出去面试,它可能依然是一个绕不开的话题. 言归正传,废话咱们也不多说了,相信使用过 Set 集合类的朋友都知道,Set集合的特点主要 ...
- 【集合系列】- 深入浅出分析 ArrayDeque
一.摘要 在 jdk1.5 中,新增了 Queue 接口,代表一种队列集合的实现,咱们继续来聊聊 java 集合体系中的 Queue 接口. Queue 接口是由大名鼎鼎的 Doug Lea 创建,中 ...
- 【集合系列】- 深入浅出分析LinkedHashMap
一.摘要 在集合系列的第一章,咱们了解到,Map的实现类有HashMap.LinkedHashMap.TreeMap.IdentityHashMap.WeakHashMap.Hashtable.Pro ...
随机推荐
- MSSQL提权之xp_cmdshell
0x01 前提 getshell或者存在sql注入并且能够执行命令. sql server是system权限,sql server默认就是system权限. 0x02 xp_cmdshell 有了xp ...
- Python之单例模式的多种实现
单例模式 单例模式(Singleton Pattern)是一种常用的软件设计模式,该模式的主要目的是确保某一个类只有一个实例存在.当你希望在整个系统中,某个类只能出现一个实例时,单例对象就能派上用场. ...
- eclipse中最有用的10个快捷键
这里列出一些在使用eclipse的过程中最有用的10个快捷键,通过灵活使用这些快捷键可以提高开发效率和开发质量. 1. [ctrl+shift+r]打开资源 这可能是所有快捷键中最省时间的了.这个快捷 ...
- 手机号码格式化显示javascript
/*手机代码格式化一般与Object.oninput=function(){}连用*/ function phoneFormat(phone){ if(phone.length <= 3 ){ ...
- 为什么重写equals必须重写hoshCode的基础分析
为什么重写equals必须重写hoshCode的基础分析 1.我们先来了解下原生的equals和hashCode代码 原生equals:它判断的是两个对象是否相等 原生hashCode值:它是根据内存 ...
- .Net Core3.0 配置Configuration
准备 .NET core和.NET项目配置上有了很大的改变,支持的也更加丰富了比如命令行,环境变量,内存中.NET对象,设置文件等等..NET项目我们常常把配置信息放到webConfig 或者appC ...
- Arduino学习笔记⑧ 红外通信
1.前言 红外通信是一种利用红外光编码进行数据传输的无线通信方式,在目前来说是使用非常广泛的.生活中常见电视遥控器,空调遥控器,DVD遥控器(现在估计是老古董了),均使用红外线遥控.使用红外线 ...
- 向net core 3.0进击——项目发布与部署
目录 前言 发布 测试 小结 前言 在经历过好多折腾后,总算是把部署走通了一遍,之前只是简单创建个工程在linux下部署,后来一直将这件事搁置,直到最近刚好团队入手一个小服务器,很显然是linux的, ...
- JVM - 复习
内存模型图 程序计数器(PC) 程序计数器的特点 PC是一小块内存空间,用于记录当前线程执行的字节码指令的地址.如果执行的是本地方法(native),PC里此时显示Undefined 优点: 控制程序 ...
- 3D切割轮播图
预览图: 实现原理:将图片切割构建一个和ul(电脑屏幕)同一个轴的立方体,利用延时旋转实现切割效果 知识点:transform-style属性(必须搭配transform属性使用) 值 描述 flat ...