深入理解Kafka必知必会(上)
Kafka的用途有哪些?使用场景如何?
消息系统: Kafka 和传统的消息系统(也称作消息中间件)都具备系统解耦、冗余存储、流量削峰、缓冲、异步通信、扩展性、可恢复性等功能。与此同时,Kafka 还提供了大多数消息系统难以实现的消息顺序性保障及回溯消费的功能。
存储系统: Kafka 把消息持久化到磁盘,相比于其他基于内存存储的系统而言,有效地降低了数据丢失的风险。也正是得益于 Kafka 的消息持久化功能和多副本机制,我们可以把 Kafka 作为长期的数据存储系统来使用,只需要把对应的数据保留策略设置为“永久”或启用主题的日志压缩功能即可。
流式处理平台: Kafka 不仅为每个流行的流式处理框架提供了可靠的数据来源,还提供了一个完整的流式处理类库,比如窗口、连接、变换和聚合等各类操作。
Kafka中的ISR、AR又代表什么?ISR的伸缩又指什么
分区中的所有副本统称为 AR(Assigned Replicas)。所有与 leader 副本保持一定程度同步的副本(包括 leader 副本在内)组成ISR(In-Sync Replicas),ISR 集合是 AR 集合中的一个子集。
ISR的伸缩:
leader 副本负责维护和跟踪 ISR 集合中所有 follower 副本的滞后状态,当 follower 副本落后太多或失效时,leader 副本会把它从 ISR 集合中剔除。如果 OSR 集合中有 follower 副本“追上”了 leader 副本,那么 leader 副本会把它从 OSR 集合转移至 ISR 集合。默认情况下,当 leader 副本发生故障时,只有在 ISR 集合中的副本才有资格被选举为新的 leader,而在 OSR 集合中的副本则没有任何机会(不过这个原则也可以通过修改相应的参数配置来改变)。
replica.lag.time.max.ms : 这个参数的含义是 Follower 副本能够落后 Leader 副本的最长时间间隔,当前默认值是 10 秒。
unclean.leader.election.enable:是否允许 Unclean 领导者选举。开启 Unclean 领导者选举可能会造成数据丢失,但好处是,它使得分区 Leader 副本一直存在,不至于停止对外提供服务,因此提升了高可用性。
Kafka中的HW、LEO、LSO、LW等分别代表什么?
HW 是 High Watermark 的缩写,俗称高水位,它标识了一个特定的消息偏移量(offset),消费者只能拉取到这个 offset 之前的消息。
LSO是LogStartOffset,一般情况下,日志文件的起始偏移量 logStartOffset 等于第一个日志分段的 baseOffset,但这并不是绝对的,logStartOffset 的值可以通过 DeleteRecordsRequest 请求(比如使用 KafkaAdminClient 的 deleteRecords()方法、使用 kafka-delete-records.sh 脚本、日志的清理和截断等操作进行修改。
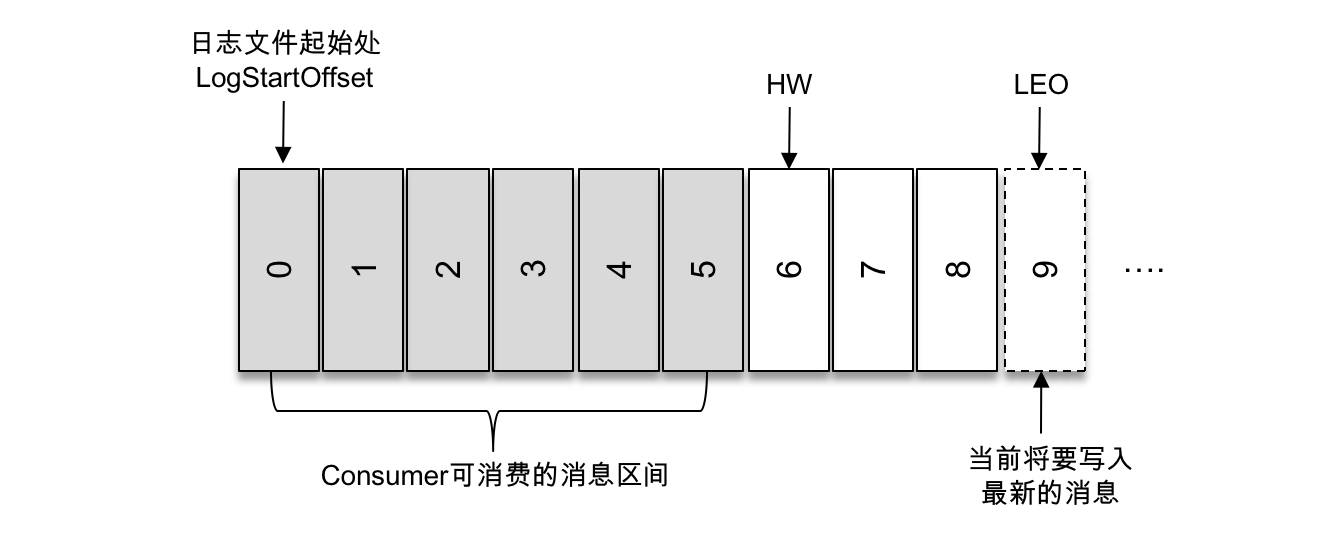
如上图所示,它代表一个日志文件,这个日志文件中有9条消息,第一条消息的 offset(LogStartOffset)为0,最后一条消息的 offset 为8,offset 为9的消息用虚线框表示,代表下一条待写入的消息。日志文件的 HW 为6,表示消费者只能拉取到 offset 在0至5之间的消息,而 offset 为6的消息对消费者而言是不可见的。
LEO 是 Log End Offset 的缩写,它标识当前日志文件中下一条待写入消息的 offset,上图中 offset 为9的位置即为当前日志文件的 LEO,LEO 的大小相当于当前日志分区中最后一条消息的 offset 值加1。分区 ISR 集合中的每个副本都会维护自身的 LEO,而 ISR 集合中最小的 LEO 即为分区的 HW,对消费者而言只能消费 HW 之前的消息。
LW 是 Low Watermark 的缩写,俗称“低水位”,代表 AR 集合中最小的 logStartOffset 值。副本的拉取请求(FetchRequest,它有可能触发新建日志分段而旧的被清理,进而导致 logStartOffset 的增加)和删除消息请求(DeleteRecordRequest)都有可能促使 LW 的增长。
Kafka中是怎么体现消息顺序性的?
可以通过分区策略体现消息顺序性。
分区策略有轮询策略、随机策略、按消息键保序策略。
按消息键保序策略:一旦消息被定义了 Key,那么你就可以保证同一个 Key 的所有消息都进入到相同的分区里面,由于每个分区下的消息处理都是有顺序的,故这个策略被称为按消息键保序策略
List<PartitionInfo> partitions = cluster.partitionsForTopic(topic);return Math.abs(key.hashCode()) % partitions.size();
Kafka中的分区器、序列化器、拦截器是否了解?它们之间的处理顺序是什么?
- 序列化器:生产者需要用序列化器(Serializer)把对象转换成字节数组才能通过网络发送给 Kafka。而在对侧,消费者需要用反序列化器(Deserializer)把从 Kafka 中收到的字节数组转换成相应的对象。
- 分区器:分区器的作用就是为消息分配分区。如果消息 ProducerRecord 中没有指定 partition 字段,那么就需要依赖分区器,根据 key 这个字段来计算 partition 的值。
- Kafka 一共有两种拦截器:生产者拦截器和消费者拦截器。
- 生产者拦截器既可以用来在消息发送前做一些准备工作,比如按照某个规则过滤不符合要求的消息、修改消息的内容等,也可以用来在发送回调逻辑前做一些定制化的需求,比如统计类工作。
- 消费者拦截器主要在消费到消息或在提交消费位移时进行一些定制化的操作。
消息在通过 send() 方法发往 broker 的过程中,有可能需要经过拦截器(Interceptor)、序列化器(Serializer)和分区器(Partitioner)的一系列作用之后才能被真正地发往 broker。拦截器(下一章会详细介绍)一般不是必需的,而序列化器是必需的。消息经过序列化之后就需要确定它发往的分区,如果消息 ProducerRecord 中指定了 partition 字段,那么就不需要分区器的作用,因为 partition 代表的就是所要发往的分区号。
处理顺序 :拦截器->序列化器->分区器
KafkaProducer 在将消息序列化和计算分区之前会调用生产者拦截器的 onSend() 方法来对消息进行相应的定制化操作。
然后生产者需要用序列化器(Serializer)把对象转换成字节数组才能通过网络发送给 Kafka。
最后可能会被发往分区器为消息分配分区。
Kafka生产者客户端的整体结构是什么样子的?

整个生产者客户端由两个线程协调运行,这两个线程分别为主线程和 Sender 线程(发送线程)。
在主线程中由 KafkaProducer 创建消息,然后通过可能的拦截器、序列化器和分区器的作用之后缓存到消息累加器(RecordAccumulator,也称为消息收集器)中。
Sender 线程负责从 RecordAccumulator 中获取消息并将其发送到 Kafka 中。
RecordAccumulator 主要用来缓存消息以便 Sender 线程可以批量发送,进而减少网络传输的资源消耗以提升性能。
Kafka生产者客户端中使用了几个线程来处理?分别是什么?
整个生产者客户端由两个线程协调运行,这两个线程分别为主线程和 Sender 线程(发送线程)。在主线程中由 KafkaProducer 创建消息,然后通过可能的拦截器、序列化器和分区器的作用之后缓存到消息累加器(RecordAccumulator,也称为消息收集器)中。Sender 线程负责从 RecordAccumulator 中获取消息并将其发送到 Kafka 中。
Kafka的旧版Scala的消费者客户端的设计有什么缺陷?
老版本的 Consumer Group 把位移保存在 ZooKeeper 中。Apache ZooKeeper 是一个分布式的协调服务框架,Kafka 重度依赖它实现各种各样的协调管理。将位移保存在 ZooKeeper 外部系统的做法,最显而易见的好处就是减少了 Kafka Broker 端的状态保存开销。
ZooKeeper 这类元框架其实并不适合进行频繁的写更新,而 Consumer Group 的位移更新却是一个非常频繁的操作。这种大吞吐量的写操作会极大地拖慢 ZooKeeper 集群的性能
“消费组中的消费者个数如果超过topic的分区,那么就会有消费者消费不到数据”这句话是否正确?如果正确,那么有没有什么hack的手段?
一般来说如果消费者过多,出现了消费者的个数大于分区个数的情况,就会有消费者分配不到任何分区。
开发者可以继承AbstractPartitionAssignor实现自定义消费策略,从而实现同一消费组内的任意消费者都可以消费订阅主题的所有分区:
public class BroadcastAssignor extends AbstractPartitionAssignor{@Overridepublic String name() {return "broadcast";}private Map<String, List<String>> consumersPerTopic(Map<String, Subscription> consumerMetadata) {(具体实现请参考RandomAssignor中的consumersPerTopic()方法)}@Overridepublic Map<String, List<TopicPartition>> assign(Map<String, Integer> partitionsPerTopic,Map<String, Subscription> subscriptions) {Map<String, List<String>> consumersPerTopic =consumersPerTopic(subscriptions);Map<String, List<TopicPartition>> assignment = new HashMap<>();//Java8subscriptions.keySet().forEach(memberId ->assignment.put(memberId, new ArrayList<>()));//针对每一个主题,为每一个订阅的消费者分配所有的分区consumersPerTopic.entrySet().forEach(topicEntry->{String topic = topicEntry.getKey();List<String> members = topicEntry.getValue();Integer numPartitionsForTopic = partitionsPerTopic.get(topic);if (numPartitionsForTopic == null || members.isEmpty())return;List<TopicPartition> partitions = AbstractPartitionAssignor.partitions(topic, numPartitionsForTopic);if (!partitions.isEmpty()) {members.forEach(memberId ->assignment.get(memberId).addAll(partitions));}});return assignment;}}
注意组内广播的这种实现方式会有一个严重的问题—默认的消费位移的提交会失效。
消费者提交消费位移时提交的是当前消费到的最新消息的offset还是offset+1?
在旧消费者客户端中,消费位移是存储在 ZooKeeper 中的。而在新消费者客户端中,消费位移存储在 Kafka 内部的主题__consumer_offsets 中。
当前消费者需要提交的消费位移是offset+1
有哪些情形会造成重复消费?
- Rebalance
一个consumer正在消费一个分区的一条消息,还没有消费完,发生了rebalance(加入了一个consumer),从而导致这条消息没有消费成功,rebalance后,另一个consumer又把这条消息消费一遍。 - 消费者端手动提交
如果先消费消息,再更新offset位置,导致消息重复消费。 - 消费者端自动提交
设置offset为自动提交,关闭kafka时,如果在close之前,调用 consumer.unsubscribe() 则有可能部分offset没提交,下次重启会重复消费。 - 生产者端
生产者因为业务问题导致的宕机,在重启之后可能数据会重发
那些情景下会造成消息漏消费?
- 自动提交
设置offset为自动定时提交,当offset被自动定时提交时,数据还在内存中未处理,此时刚好把线程kill掉,那么offset已经提交,但是数据未处理,导致这部分内存中的数据丢失。 - 生产者发送消息
发送消息设置的是fire-and-forget(发后即忘),它只管往 Kafka 中发送消息而并不关心消息是否正确到达。不过在某些时候(比如发生不可重试异常时)会造成消息的丢失。这种发送方式的性能最高,可靠性也最差。 - 消费者端
先提交位移,但是消息还没消费完就宕机了,造成了消息没有被消费。自动位移提交同理 - acks没有设置为all
如果在broker还没把消息同步到其他broker的时候宕机了,那么消息将会丢失
KafkaConsumer是非线程安全的,那么怎么样实现多线程消费?
- 线程封闭,即为每个线程实例化一个 KafkaConsumer 对象
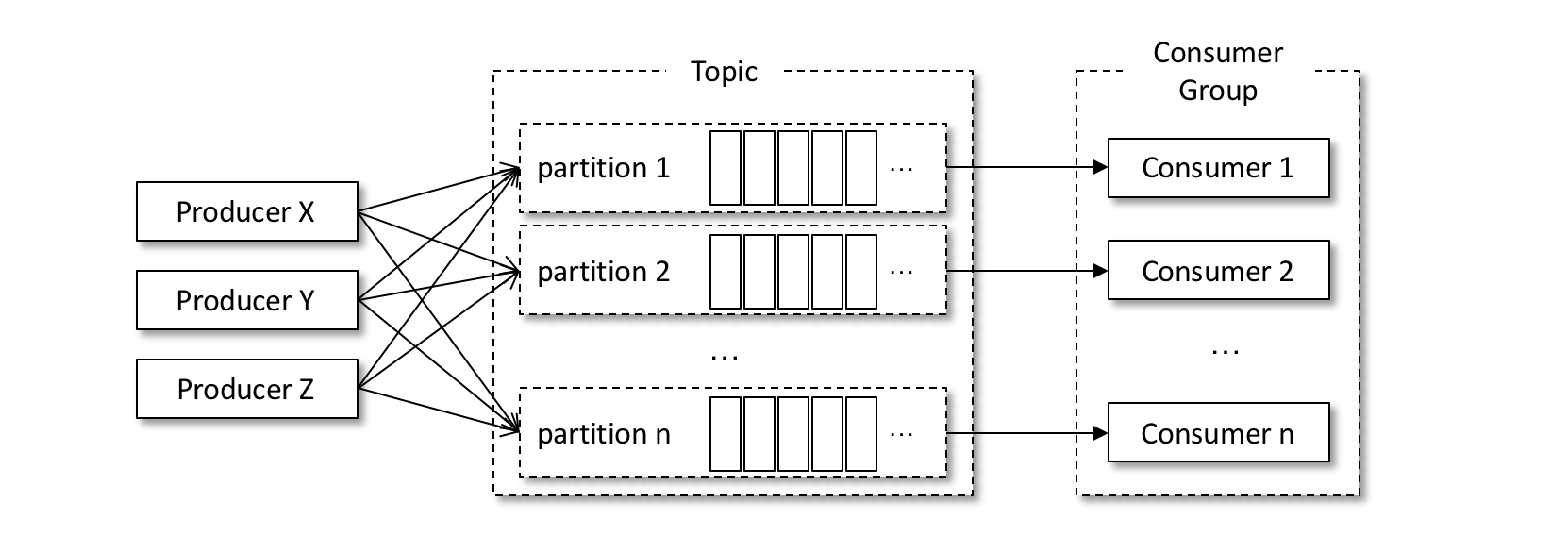
一个线程对应一个 KafkaConsumer 实例,我们可以称之为消费线程。一个消费线程可以消费一个或多个分区中的消息,所有的消费线程都隶属于同一个消费组。
- 消费者程序使用单或多线程获取消息,同时创建多个消费线程执行消息处理逻辑。
获取消息的线程可以是一个,也可以是多个,每个线程维护专属的 KafkaConsumer 实例,处理消息则交由特定的线程池来做,从而实现消息获取与消息处理的真正解耦。具体架构如下图所示:
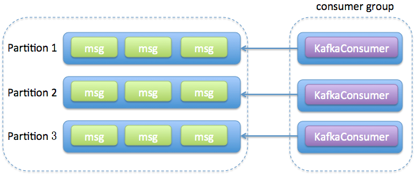
两个方案对比:
简述消费者与消费组之间的关系
- Consumer Group 下可以有一个或多个 Consumer 实例。这里的实例可以是一个单独的进程,也可以是同一进程下的线程。在实际场景中,使用进程更为常见一些。
- Group ID 是一个字符串,在一个 Kafka 集群中,它标识唯一的一个 Consumer Group。
- Consumer Group 下所有实例订阅的主题的单个分区,只能分配给组内的某个 Consumer 实例消费。这个分区当然也可以被其他的 Group 消费。
当你使用kafka-topics.sh创建(删除)了一个topic之后,Kafka背后会执行什么逻辑?
在执行完脚本之后,Kafka 会在 log.dir 或 log.dirs 参数所配置的目录下创建相应的主题分区,默认情况下这个目录为/tmp/kafka-logs/。
在 ZooKeeper 的/brokers/topics/目录下创建一个同名的实节点,该节点中记录了该主题的分区副本分配方案。示例如下:
[zk: localhost:2181/kafka(CONNECTED) 2] get /brokers/topics/topic-create{"version":1,"partitions":{"2":[1,2],"1":[0,1],"3":[2,1],"0":[2,0]}}
topic的分区数可不可以增加?如果可以怎么增加?如果不可以,那又是为什么?
可以增加,使用 kafka-topics 脚本,结合 --alter 参数来增加某个主题的分区数,命令如下:
bin/kafka-topics.sh --bootstrap-server broker_host:port --alter --topic <topic_name> --partitions <新分区数>
当分区数增加时,就会触发订阅该主题的所有 Group 开启 Rebalance。
首先,Rebalance 过程对 Consumer Group 消费过程有极大的影响。在 Rebalance 过程中,所有 Consumer 实例都会停止消费,等待 Rebalance 完成。这是 Rebalance 为人诟病的一个方面。
其次,目前 Rebalance 的设计是所有 Consumer 实例共同参与,全部重新分配所有分区。其实更高效的做法是尽量减少分配方案的变动。
最后,Rebalance 实在是太慢了。
topic的分区数可不可以减少?如果可以怎么减少?如果不可以,那又是为什么?
不支持,因为删除的分区中的消息不好处理。如果直接存储到现有分区的尾部,消息的时间戳就不会递增,如此对于 Spark、Flink 这类需要消息时间戳(事件时间)的组件将会受到影响;如果分散插入现有的分区,那么在消息量很大的时候,内部的数据复制会占用很大的资源,而且在复制期间,此主题的可用性又如何得到保障?与此同时,顺序性问题、事务性问题,以及分区和副本的状态机切换问题都是不得不面对的。
创建topic时如何选择合适的分区数?
在 Kafka 中,性能与分区数有着必然的关系,在设定分区数时一般也需要考虑性能的因素。对不同的硬件而言,其对应的性能也会不太一样。
可以使用Kafka 本身提供的用于生产者性能测试的 kafka-producer- perf-test.sh 和用于消费者性能测试的 kafka-consumer-perf-test.sh来进行测试。
增加合适的分区数可以在一定程度上提升整体吞吐量,但超过对应的阈值之后吞吐量不升反降。如果应用对吞吐量有一定程度上的要求,则建议在投入生产环境之前对同款硬件资源做一个完备的吞吐量相关的测试,以找到合适的分区数阈值区间。
分区数的多少还会影响系统的可用性。如果分区数非常多,如果集群中的某个 broker 节点宕机,那么就会有大量的分区需要同时进行 leader 角色切换,这个切换的过程会耗费一笔可观的时间,并且在这个时间窗口内这些分区也会变得不可用。
分区数越多也会让 Kafka 的正常启动和关闭的耗时变得越长,与此同时,主题的分区数越多不仅会增加日志清理的耗时,而且在被删除时也会耗费更多的时间。
java学习笔记/Kafka
深入理解Kafka必知必会(上)的更多相关文章
- 第3节:Java基础 - 必知必会(上)
第3节:Java基础 - 必知必会(上) 本篇是基础篇的第一小节,我们从最基础的java知识点开始学习.本节涉及的知识点包括面向对象的三大特征:封装,继承和多态,并且对常见且容易混淆的重要概念覆盖和重 ...
- Android必知必会-使用okhttp的PUT方式上传文件
注:如果移动端排版有问题,请看 简书版 (<-点击左边),希望CSDN能更好的支持移动端. 背景 公司的文件上传接口使用PUT协议,之前一直用的都是老项目中的上传类,现在项目中使用了okhttp ...
- 数据库学习之中的一个: 在 Oracle sql developer上执行SQL必知必会脚本
1 首先在開始菜单中打开sql developer: 2. 创建数据库连接 点击左上角的加号 在弹出的对话框中填写username和password 測试假设成功则点击连接,记得角色要写SYSDBA ...
- 《MySQL 必知必会》读书总结
这是 <MySQL 必知必会> 的读书总结.也是自己整理的常用操作的参考手册. 使用 MySQL 连接到 MySQL shell>mysql -u root -p Enter pas ...
- 《SQL必知必会》学习笔记(一)
这两天看了<SQL必知必会>第四版这本书,并照着书上做了不少实验,也对以前的概念有得新的认识,也发现以前自己有得地方理解错了.我采用的数据库是SQL Server2012.数据库中有一张比 ...
- 2015 前端[JS]工程师必知必会
2015 前端[JS]工程师必知必会 本文摘自:http://zhuanlan.zhihu.com/FrontendMagazine/20002850 ,因为好东东西暂时没看懂,所以暂时保留下来,供以 ...
- [ 学习路线 ] 2015 前端(JS)工程师必知必会 (2)
http://segmentfault.com/a/1190000002678515?utm_source=Weibo&utm_medium=shareLink&utm_campaig ...
- 《MySQL必知必会》[01] 基本查询
<MySQL必知必会>(点击查看详情) 1.写在前面的话 这本书是一本MySQL的经典入门书籍,小小的一本,也受到众多网友推荐.之前自己学习的时候是啃的清华大学出版社的计算机系列教材< ...
- mysql必知必会
春节放假没事,找了本电子书mysql必知必会敲了下.用的工具是有道笔记的markdown文档类型. 下面是根据大纲已经敲完的章节,可复制到有道笔记的查看,更美观. # 第一章 了解SQL## 什么是S ...
- 关于TCP/IP,必知必会的十个经典问题[转]
关于TCP/IP,必知必会的十个问题 原创 2018-01-25 Ruheng 技术特工队 本文整理了一些TCP/IP协议簇中需要必知必会的十大问题,既是面试高频问题,又是程序员必备基础素养. 一 ...
随机推荐
- while 格式化输出 编码初识
1.while循环 while 关键字 空格 条件 冒号 缩进 循环体 while 3>2: print("好嗨呦") print("你的骆驼") pri ...
- ng 点击事件
执行事件获取数据 <div class="shijian"> <p>ng 事件</p> <p><button (click)= ...
- Scala 多继承问题
多继承问题: object LoadIssueDemo extends App { import java.io.PrintWriter trait Logger { def log(msg: Str ...
- Springboot之初入江湖
Hello,各位小伙伴大家好,我是小栈君. 今天的分享主题是关于Springboot主题分享,其实在写这个系列主题之前有想过一些关于分享技术的顺序问题,因为我在创建"IT干货栈"这 ...
- A-02 梯度下降法
目录 梯度下降法 一.梯度下降法详解 1.1 梯度 1.2 梯度下降法和梯度上升法 1.3 梯度下降 1.4 相关概念 1.4.1 步长 1.4.2 假设函数 1.4.3 目标函数 二.梯度下降法流程 ...
- linux分区与挂载
分区是将一个硬盘驱动器分成若干个逻辑驱动器,分区是把硬盘连续的区块当做一个独立的磁盘使用.分区表是一个硬盘分区的索引,分区的信息都会写进分区表.通常情况下,为磁盘分区通常使用fdisk,它是对基于MB ...
- Go语言及Beego框架环境搭建
在开始环境搭建之前,我们先一起来看看: Go有什么优势: 不用虚拟机,它可直接编译成机器码,除了glibc外没有其他外部依赖,部署十分方便,就是扔一个文件就完成了. 天生支持并发,可以充分的利用多核, ...
- 数据挖掘:python数据清洗cvs里面带中文字符
数据清洗,使用python数据清洗cvs里面带中文字符,意图是用字典对应中文字符,即key值是中文字符,value值是index,自增即可:利用字典数据结构没有重复key值的特性,把中文字符映射到了数 ...
- CSS核心问题
本文将讲述 CSS 中最核心的几个概念,包括:盒模型.position.float等.这些是 CSS 的基础,也是最常用的几个属性,它们之间看似独立却又相辅相成.为了掌握它们,有必要写出来探讨一下,如 ...
- 七、springBoot 简单优雅是实现文件上传和下载
前言 好久没有更新spring Boot 这个项目了.最近看了一下docker 的知识,后期打算将spring boot 和docker 结合起来.刚好最近有一个上传文件的工作呢,刚好就想起这个脚手架 ...