Python爬虫 爬取Web页面图片
从网页页面上批量下载jpg格式图片,并按照数字递增命名保存到指定的文件夹
Web地址:http://news.weather.com.cn/2017/12/2812347.shtml
打开网页,点击F12查看

代码实现:
import urllib
import urllib.request
import re #解析页面
def load_page(url):
request=urllib.request.Request(url) #发送网络请求
response=urllib.request.urlopen(request) #根据url打开页面
data=response.read() #获取页面响应数据
return data #下载图片
def get_image(html):
regx=r'http://[\S]*jpg' #定义正则表达式
pattern=re.compile(regx) #编译表达式构造匹配模式
get_image=re.findall(pattern,repr(html)) #进行正则匹配并返回结果 num = 1
#遍历获取的图片
for img in get_image:
image=load_page(img)
#将图片存入到指定文件夹
with open('E:\\Photo\\%s.jpg' %num,'wb') as fb:
fb.write(image)
print("正在下载第%s张图片" %num)
num = num + 1
print("下载完成!") url='http://news.weather.com.cn/2017/12/2812347.shtml'
html=load_page(url)
get_image(html)
结果:
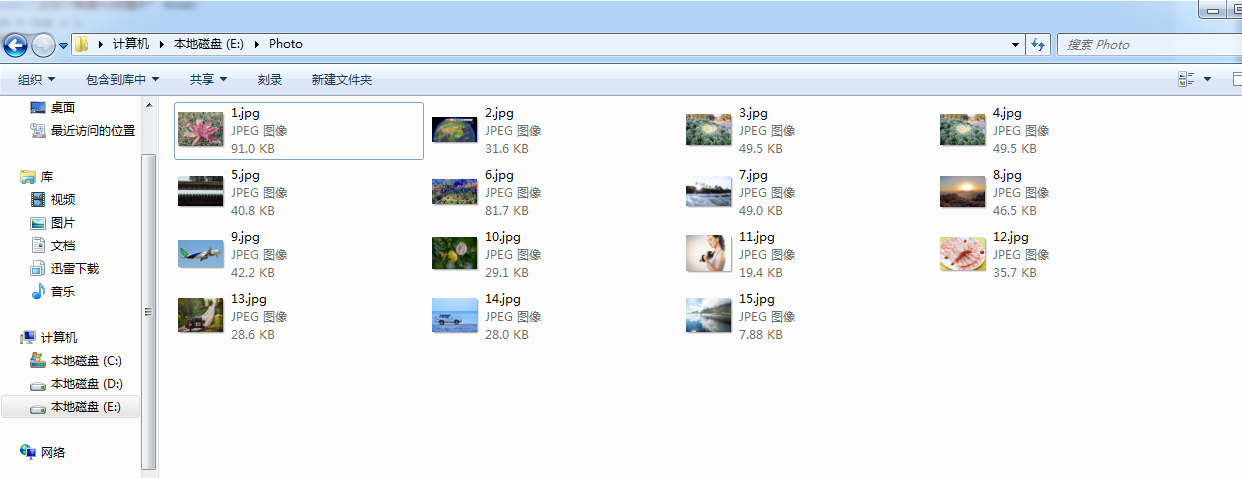
Python爬虫 爬取Web页面图片的更多相关文章
- 使用Python爬虫爬取网络美女图片
代码地址如下:http://www.demodashi.com/demo/13500.html 准备工作 安装python3.6 略 安装requests库(用于请求静态页面) pip install ...
- python爬虫——爬取NUS-WIDE数据库图片
实验室需要NUS-WIDE数据库中的原图,数据集的地址为http://lms.comp.nus.edu.sg/research/NUS-WIDE.htm 由于这个数据只给了每个图片的URL,所以需 ...
- python爬虫爬取汽车页面信息,并附带分析(静态爬虫)
环境: windows,python3.4 参考链接: https://blog.csdn.net/weixin_36604953/article/details/78156605 代码:(亲测可以运 ...
- python爬虫-爬取百度图片
python爬虫-爬取百度图片(转) #!/usr/bin/python# coding=utf-8# 作者 :Y0010026# 创建时间 :2018/12/16 16:16# 文件 :spider ...
- python爬虫---爬取王者荣耀全部皮肤图片
代码: import requests json_headers = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win ...
- 用Python爬虫爬取广州大学教务系统的成绩(内网访问)
用Python爬虫爬取广州大学教务系统的成绩(内网访问) 在进行爬取前,首先要了解: 1.什么是CSS选择器? 每一条css样式定义由两部分组成,形式如下: [code] 选择器{样式} [/code ...
- Python爬虫爬取全书网小说,程序源码+程序详细分析
Python爬虫爬取全书网小说教程 第一步:打开谷歌浏览器,搜索全书网,然后再点击你想下载的小说,进入图一页面后点击F12选择Network,如果没有内容按F5刷新一下 点击Network之后出现如下 ...
- python爬虫—爬取英文名以及正则表达式的介绍
python爬虫—爬取英文名以及正则表达式的介绍 爬取英文名: 一. 爬虫模块详细设计 (1)整体思路 对于本次爬取英文名数据的爬虫实现,我的思路是先将A-Z所有英文名的连接爬取出来,保存在一个cs ...
- 一个简单的python爬虫,爬取知乎
一个简单的python爬虫,爬取知乎 主要实现 爬取一个收藏夹 里 所有问题答案下的 图片 文字信息暂未收录,可自行实现,比图片更简单 具体代码里有详细注释,请自行阅读 项目源码: # -*- cod ...
随机推荐
- 题解报告:hdu 1398 Square Coins(母函数或dp)
Problem Description People in Silverland use square coins. Not only they have square shapes but also ...
- android 系统的时间间隔和睡眠用哪个?
原文 : https://developer.android.com/reference/android/os/SystemClock.html SystemClock.elapsedRealtime ...
- Vue自定义过滤器格式化数字三位加一逗号
<template> <div class="index-compont"> <div class="totalCount"> ...
- 转 Docker和hadoop
2017-06-21 朱洁 Docker很热,怎么形容?感觉开源除了spark技术,就是docker了,甚至把Go语言也带火了,把Go在TIOBE的排名从百名外带入主流语言的行列. Docker快成救 ...
- DB buffer bussy wait 分析一例
####sample 1: DB层分析OI DB层分析OI的信息如下: 1. 异常时间段, Logical reads:/ Physical reads/ Physical write 指标都低于 ...
- office doc/xls/ppt 和 docx/xlsx/pptx 区别
经同事告诉,今天才真正明白两都区别: doc/xls/ppt 是office2007以前的扩展名: docx/xlsx/pptx 是office2007版本及以后的扩展名,是基于xml的文件格式,x ...
- for循环的两种写法哪个快
结果如下: 其实工作中,也没有这么多数据需要遍历,基本上用foreach
- 2017.5.20欢(bei)乐(ju)赛解题报告
预计分数:100+20+50=first 实际分数:20+0+10=gg 水灾(sliker.cpp/c/pas) 1000MS 64MB 大雨应经下了几天雨,却还是没有停的样子.土豪CCY刚从外地 ...
- ios开发介绍
iOS开发概述 •什么是IOS •什么是IOS开发 •为什么要选择IOS开发 •学习IOS开发的准备 1.什么是iOS •iOS是一款由苹果公司开发的操作系统(OS是Operating Sys ...
- 使用Latex插入数学公式(二)
初级运算 关系运算符 希腊字母 集合运算符逻辑运算符 空格问题 矩阵格式 矩阵格式有三种: 无括号的矩阵 matrix 是 Latex 的矩阵命令,矩阵命令中每一行以 \\ 结束,矩阵的元素之间用 & ...