【Elastic-1】ELK基本概念、环境搭建、快速开始文档
TODO
- 快速开始文档
- SpringBoot整合ELK(Logstash收集日志、应用主动向ES写入)
- ELK接入Kafka
基本概念
ElasticSearch
什么是ElasticSearch?
首推官网的解释: https://www.elastic.co/guide/en/elasticsearch/reference/7.11/elasticsearch-intro.html
我简单总结下,ES(ElasticSearch的缩写,下文大写的ES都表示ElasticSearch)是一个分布式的搜索和分析引擎,可以通过Logstash、Beats收集数据,并将其存储在ES中。然后通过Kibana可视化的展示、分析你存储的数据。上述就著名的ELK三件套,当然L不是必需的,数据也可以自己写入。
ES不同于传统关系型数据库(RDBMS),ES不是将数据转为一列列的数据行,而是存储已经序列化为JSON文档的复杂数据结构。这些文档分布在集群中,可以从任何节点上立即访问。当文档被存储时,它就会被编入索引,并且在1秒内就可以被搜索到,可以做到近实时。
ES使用的是一种被称为倒排索引的数据结构,倒排索引会列出文档中每一个单词,并标识出这些单词出现过的所有文档。所以,如果拿ES当搜索引擎使用,怎么分词是非常重要的。
应用场景
搜索类场景,比如电商网站、招聘网站、新闻资讯等各类应用,只要涉及到搜索功能,都可以用ES来做。
日志平台,经典的ELK三件套,日志的收集、存储、分析一套完成,省心又省力。
数据分析,比如筛选出topN访问量的页面。
核心概念
索引(Index):类似关系型数据库中的数据库,通常一类数据只放到一个索引中。比如A系统的日志,就放到log_a索引中。系统B的访问量统计,就放到pv_b中。
类型(type):这个概念每个版本变动都比较大,ES5.X中一个index可以有多种type,6.X中一个index只能有一个type,7.X中要逐渐移除这个概念。type表示这个文档是该index中,哪一个类别的。如果非要和关系型数据库做个类比,可以想象成表。
文档(document):文档就是一条JSON数据,类似于关系型数据库中的一行数据。
映射(mapping):mapping定义了文档中,每个字段的类型等信息,类似于关系型数据库中的表结构。
Kibana
Kibana是一个基于Node.js的可视化工具,可以利用ES的聚合功能,生成柱状图、饼图、折线图等各类图标。而且还提供了操作ES的控制台(Dev Tools),可以直接在控制台中输入RESTful API来操作ES,并且提供了一定的API提示和语法高亮,有助于我们对ES API的学习。
Kibana没有太多复杂的概念,我们只要会用即可。最后整合ELK时,我会介绍一些基本的用法。也可以看看官方文档,里面还有视频教程:https://www.elastic.co/guide/en/kibana/7.11/introduction.html
Logstash
贴一张官方的图,Logstash的作用一目了然:
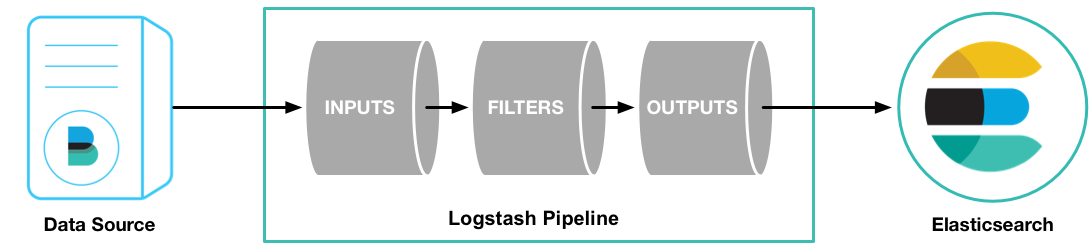
Logstash是一个具有实时收集数据的开源引擎,Logstash可以收集不同的数据源,然后将数据规范化的输出到你的目的地,也就是ES。
Logstash有三个重要的组成部分,inputs、filters、outputs。inputs和outputs是必需的,需要我们配置数据的输入源和数据的输出源。而在实际中,filters更为重要,它可以按照你指定的规则,过滤、操作数据。数据的格式统一,存入到ES后,有助于我们分析、查询这些数据。
系统环境和软件准备
操作系统
CentOS7
JDK
JDK8
yum install -y java-1.8.0-openjdk
ElasticSearch
版本号7.11,Kibana、Logstash和ES版本保持一致。
#下载es7.11压缩包
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.11.0-linux-x86_64.tar.gz
Kibana
wget https://artifacts.elastic.co/downloads/kibana/kibana-7.11.0-linux-x86_64.tar.gz
Logstash
wget https://artifacts.elastic.co/downloads/logstash/logstash-7.11.0-linux-x86_64.tar.gz
快速开始
ElasticSearch
# 解压压缩包
tar -zxvf elasticsearch-7.11.0-linux-x86_64.tar.gz
# 移至你专门放软件的目录,尽量别在root根目录
mv elasticsearch-7.11.0 /usr/elasticsearch/
# 修改配置文件
vim /usr/elasticsearch/elasticsearch-7.11.0/config/elasticsearch.yml
单机启动只需简单修改如下几项配置即可。如果是运维的朋友,可以去官方文档了解更多的配置信息:https://www.elastic.co/guide/en/elasticsearch/reference/7.11/settings.html 根据右侧目录可以快速找到自己想看的配置主题,比如Network settings。
node.name: node-1
# 因为我部署在云服务器上,想要外网访问这里要配置成0.0.0.0
# 如果是虚拟机的话就配置成ip地址,
# 如果是本机可以不改此项,默认绑到本机
# 可参考文档:https://www.elastic.co/guide/en/elasticsearch/reference/7.11/modules-network.html
network.host: 0.0.0.0
# 如果是云服务器记得在防火墙里添加9200、9300,后面Kibana用到的5601端口也要记得添加
http.port: 9200
cluster.initial_master_nodes: ["node-1"]
根据自己的机器配置,按需修改JVM内存配置。ES默认配置是1G,考虑到后面会启动Kibana,可以增加一些。
vim /usr/elasticsearch/elasticsearch-7.11.0/config/jvm.options
# 配置初始和最大堆内存
-Xms2g
-Xmx2g
添加es用户,es默认root用户无法启动,所以需要新建一个用户
useradd es # 新建用户
passwd es # 修改密码
chown -R es /usr/elasticsearch/ #赋予软件包所在目录的权限
Elasticsearch 默认情况下使用 mmapfs 目录来存储其索引。mmap 计数的默认限制可能太低,这可能导致内存不足异常。可以以root身份运行以下命令增加限制
sysctl -w vm.max_map_count=655360
如果要永久更改这个限制可以去系统文件中修改
vim /etc/sysctl.conf # 末尾添加如下内容vm.max_map_count=655360
# :wq后,使新增内容生效
sysctl -p
ES同样会用到大量线程池,所以我们也需要修改一些配置,确保ES可以创建的线程数量至少为4096个。
vim /etc/security/limits.conf# 文末添加es - nofile 65535
切换到es用户,然后启动ES
su es/usr/elasticsearch/elasticsearch-7.11.0/bin/elasticsearch
观察启动日志,如果你的版本和我一样,并且没有遗漏什么配置,应该都能正常启动。如果没有正常启动,根据日志解决问题即可。如果看不明白日志,自行Google。
新建一个终端,或者打开浏览器,访问ip:port,如果返回如下信息,就表示启动成功。
curl http://ip:9200/
# 响应信息
{
"name" : "node-1",
"cluster_name" : "elasticsearch",
"cluster_uuid" : "uAIt_QYIQTy0YkATySbDhw",
"version" : {
"number" : "7.11.0",
"build_flavor" : "default",
"build_type" : "tar",
"build_hash" : "8ced7813d6f16d2ef30792e2fcde3e755795ee04",
"build_date" : "2021-02-08T22:44:01.320463Z",
"build_snapshot" : false,
"lucene_version" : "8.7.0",
"minimum_wire_compatibility_version" : "6.8.0",
"minimum_index_compatibility_version" : "6.0.0-beta1"
},
"tagline" : "You Know, for Search"
}
到此为止,单机版ES启动完毕,说的比较详细,后面的Kibana会适当简略一点。建议有能力的,还是根据自己的需求过一遍文档。可以不用全部看完,运维的朋友可以着重看看配置、集群管理、监控等相关章节。开发的朋友可以着重看看API、client、Mapping、DSL等。
Kibana
解压、移动
tar -zxvf kibana-7.11.0-linux-x86_64.tar.gzmv kibana-7.11.0-linux-x86_64 /usr/kibana/
赋予es用户Kibana目录权限
chown -R es /usr/kibana/
修改配置文件
vim /usr/kibana/kibana-7.11.0-linux-x86_64/config/kibana.yml
配置内容如下:
server.port: 5601server.host: "0.0.0.0" # 如果ES和Kibana不在同一台机器上,这里改成ES所在机器的IP
elasticsearch.hosts: ["http://localhost:9200"]
启动Kibana,观察日志有没有报错
su es/usr/kibana/kibana-7.11.0-linux-x86_64/bin/kibana
进入Kibana可视化页面,打开浏览器,输入ip:5601
Logstash
解压、移动、赋予目录权限
tar -zxvf logstash-7.11.0-linux-x86_64.tar.gzmv logstash-7.11.0 /usr/logstash/chown -R es /usr/logstash/
配置input、output。filter我们暂时不配置,下面的SpringBoot整合ELK再演示filter。
su es
# 先进到配置文件目录,复制一份配置模板
cd /usr/logstash/logstash-7.11.0/config/cp logstash-sample.conf logstash.conf
# 配置输入输出
vim logstash.conf
填入如下内容:
input {
file {
path => ["/usr/log/movies.csv"] # 待导入数据的目录
start_position => "beginning" # 头从开始
}
}
filter {
csv {
separator => ","
columns => ["id","content","genre"]
}
mutate {
split => { "genre" => "|" }
remove_field => ["path", "host","@timestamp","message"]
}
mutate {
split => ["content", "("]
add_field => { "title" => "%{[content][0]}"}
add_field => { "year" => "%{[content][1]}"}
}
mutate {
convert => {
"year" => "integer"
}
strip => ["title"]
remove_field => ["path", "host","@timestamp","message","content"]
}
}
output {
elasticsearch {
hosts => "http://localhost:9200"
index => "movies"
document_id => "%{id}"
}
}
上述配置文件中,我简单说说它们的意思。其中input、filter和output就是Logstash管道的三个组件。组件里面的file、csv、mutate、elasticsearch等,是各自组件的插件,它们有不同的功能。比如file插件就是读取文件,而filter里面的mutate插件可以对数据进行常规的操作,比如重命名、删除、修改等。具体的插件用法和解释可见如下链接:
Input Plugins:https://www.elastic.co/guide/en/logstash/7.11/input-plugins.html
Filter Plugins:https://www.elastic.co/guide/en/logstash/7.11/filter-plugins.html
Output Plugins:https://www.elastic.co/guide/en/logstash/7.11/output-plugins.html
在启动Logstash前我们先往/usr/log/目录中放些数据,数据集我是在网上找的,地址:https://grouplens.org/datasets/movielens/ 大家可以根据自己的网速、硬盘大小下载,网速慢的就下个小点的数据集。然后复制到/usr/log/目录下即可。
# 下载测试的数据集
wget https://files.grouplens.org/datasets/movielens/ml-latest-small.zipunzip ml-latest-small.zip cd ml-latest-small/cp movies.csv /usr/log/
# 加载指定配置文件,启动Logstash
/usr/logstash/logstash-7.11.0/bin/logstash -f /usr/logstash/logstash-7.11.0/config/logstash.conf
观察日志,看是否正常启动。我第一次启动时,由于ELK都部署在同一台云服务(4G内存),内存不足启动失败,可以去Logstash的jvm配置文件里面适当减小最小堆内存即可。
导入成功后,就可以去Kibana的Index Management页面看到这个数据集了。
【Elastic-1】ELK基本概念、环境搭建、快速开始文档的更多相关文章
- 传智播客C/C++各种开发环境搭建视频工具文档免费教程
传智播客作为中国IT培训的领军品牌,一直把握技术趋势,给大家带来最新的技术分享!传智播客C/C++主流开发环境免费分享视频文档中,就有写一个helloworld程序的示范.火速前来下载吧 所谓&quo ...
- Win10环境下,告别MarkdownPad,用Notepad++搭建编写md文档的环境
1. 为什么抛弃MarkdownPad 2 ? MarkdownPad坊间号称 Windows 环境下最好用的markdown编辑器-EXO me??? 博主入MarkdownPad 2 坑就是因为这 ...
- Docker最全教程之使用Node.js搭建团队技术文档站(二十三)
前言 各种编程语言均有其优势和生态,有兴趣的朋友完全可以涉猎多门语言.在平常的工作之中,也可以尝试选择相对适合的编程语言来完成相关的工作. 在团队技术文档站搭建这块,笔者尝试了许多框架,最终还是选择了 ...
- Vitepress搭建组件库文档(上)—— 基本配置
在 vite 出现以前,vuepress 是搭建组件库文档不错的工具,支持以 Markdown 方式编写文档.伴随着 vite 的发展,vitepress 已经到了 1.0.0-alpha.22 版本 ...
- Vitepress搭建组件库文档(下)—— 组件 Demo
上文 <Vitepress搭建组件库文档(上)-- 基本配置>已经讨论了 vitepress 搭建组件库文档的基本配置,包括站点 Logo.名称.首页 home 布局.顶部导航.左侧导航等 ...
- 数据库 PSU,SPU(CPU),Bundle Patches 和 Patchsets 补丁号码快速参考 (文档 ID 1922396.1)
数据库 PSU,SPU(CPU),Bundle Patches 和 Patchsets 补丁号码快速参考 (文档 ID 1922396.1)
- oracle数据库 PSU,SPU(CPU),Bundle Patches 和 Patchsets 补丁号码快速参考 (文档 ID 1922396.1)
数据库 PSU,SPU(CPU),Bundle Patches 和 Patchsets 补丁号码快速参考 (文档 ID 1922396.1) 文档内容 用途 详细信息 Patchsets ...
- 01-S3C2440学习入门概念+环境搭建【转】
本文转载自:http://blog.csdn.net/fengyuwuzu0519/article/details/54754812 一.心得: 这两年学过很多东西,有点杂,总感觉不够踏实,于是准备写 ...
- L18 如何快速查找文档获得帮助
原地址:http://www.howzhi.com/course/286/lesson/2121 查找文档快速 苹果提供了丰富的文档,以帮助您成功构建和部署你的应用程序,包括示例代码,常见问题解答,技 ...
随机推荐
- 智能集成接口:I3 ISA-95 的应用
介绍 多年来,使用基于制造运营管理 (MOM) 的应用程序的制造 IT 顾问试图说服制造商这些类型的应用的高价值.实时 MOM 解决方案是唯一一组能够精确优化工厂日常运营的 IT 应用程序,可为其可用 ...
- day 17 i++优先级大于 *i
(1).有下列定义语句,int *p[4];以下选项中与此语句等价的是[C] (A).int p[4]; (B).int **P; (C).int *(p[4]); (D).int (*p)[4]; ...
- Solon 开发,六、提取Bean的函数进行定制开发
Solon 开发 一.注入或手动获取配置 二.注入或手动获取Bean 三.构建一个Bean的三种方式 四.Bean 扫描的三种方式 五.切面与环绕拦截 六.提取Bean的函数进行定制开发 七.自定义注 ...
- 《剑指offer》面试题04. 二维数组中的查找
问题描述 在一个 n * m 的二维数组中,每一行都按照从左到右递增的顺序排序,每一列都按照从上到下递增的顺序排序.请完成一个函数,输入这样的一个二维数组和一个整数,判断数组中是否含有该整数. 示例: ...
- 用Python实现一个Picgo图床工具
PyPicGo PyPicGo 是一款图床工具,是PicGo是Python版实现,并支持各种插件自定义插件,目前PyPicGo自带了gitee.github.SM.MS和七牛云图传,以及rename. ...
- SQL查询字段,起别名,列参与数学运算
13.简单查询 13.1.查询一个字段? select 字段名 from 表名: 其中要注意: select和from都是关键字 字段名和表名都是标识符. 强调: 对于SQL语句说,是通用的 所有的S ...
- sysctl内核参数
sysctl命令用来配置与显示/proc/sys目录中的内核参数.如果想使参数长期保存,可以通过编辑/etc/sysctl.conf文件来实现. -a 显示所有的系统参数 -p 从指定的文件加载系统参 ...
- K8S SVC 转发原理
在前面的文章中,我们已经多次使用到了 Service 这个 Kubernetes 里重要的服务对象.而 Kubernetes 之所以需要 Service,一方面是因为 Pod 的 IP 不是固定的,另 ...
- a-b转换A-B
- 在Linux虚拟机上挂载文件卷
一 通过跳板机 将卷挂载在ec2 实例上的方法. 1 查询 机器上挂载了那些卷? // lsblk 是否已经是挂载卷 查看后面的目录 如果没有就是未挂载. 2 操作未挂载卷? /* sudo file ...