【流行前沿】联邦学习 Partial Model Averaging in Federated Learning: Performance Guarantees and Benefits
Sunwoo Lee, , Anit Kumar Sahu, Chaoyang He, and Salman Avestimehr. "Partial Model Averaging in Federated Learning: Performance Guarantees and Benefits." (2022).
简介
传统FedAvg算法下,SGD的多轮本地训练会导致模型差异增大,从而使全局loss收敛缓慢。本文作者提出每次本地用户更新后,仅对部分网络参数进行聚合,从而降低模型间参数差异。在128个用户时,验证准确率比FedAvg提高了2.2%,loss的下降速度也更快。但是该算法并没有减少传输的参数量,甚至会增加传输的次数,从而可能会提高总的延迟。
核心算法

每次更新所有用户网络的同一个部分,在周期\(\tau\)内完成网络所有参数的更新。和FedAvg相比,同样是交换了所有参数,只是改成了高频分部更新,所以差异会小一些。
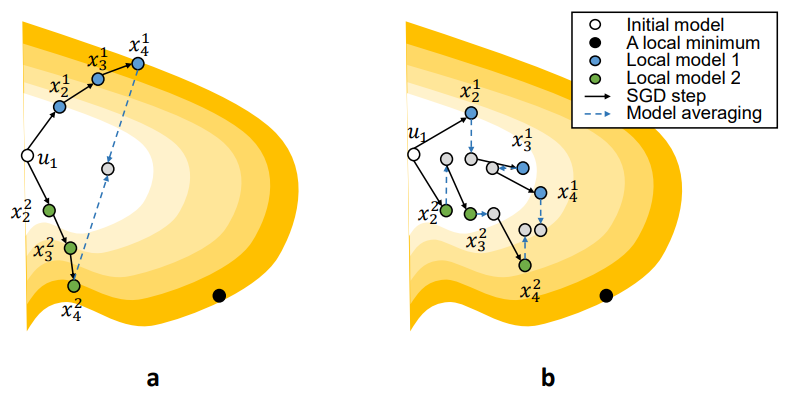
理论推导
非常高深的理论推导,如何对部分网络进行操作值得学习【挖坑】
目前来看,根据数据进行优化,和贝叶斯学习,似乎是两种不同的理论分析思路。
仿真效果
- 用Dirichlet's distribution来生成异构数据分布
- cross-silo和cross-device的区别:cross-device表示每个时间节点只有部分客户端在线,cross-silo表示所有用户一直在线。
- variance reduction的技术会损害泛化性能
- 附录中的仿真设置非常详细,可以参考
评价
价值 = 新意100×有效性1×问题大小10
- 新意主要来源于理论推导部分,很硬核
- 网络更新的划分与数据分布并没有建立联系
【流行前沿】联邦学习 Partial Model Averaging in Federated Learning: Performance Guarantees and Benefits的更多相关文章
- 联邦学习 Federated Learning 相关资料整理
本文链接:https://blog.csdn.net/Sinsa110/article/details/90697728代码微众银行+杨强教授团队的联邦学习FATE框架代码:https://githu ...
- 【一周聚焦】 联邦学习 arxiv 2.16-3.10
这是一个新开的每周六定期更新栏目,将本周arxiv上新出的联邦学习等感兴趣方向的文章进行总结.与之前精读文章不同,本栏目只会简要总结其研究内容.解决方法与效果.这篇作为栏目首发,可能不止本周内容(毕竟 ...
- 【流行前沿】联邦学习 Federated Learning with Only Positive Labels
核心问题:如果每个用户只有一类数据,如何进行联邦学习? Felix X. Yu, , Ankit Singh Rawat, Aditya Krishna Menon, and Sanjiv Kumar ...
- 【论文考古】联邦学习开山之作 Communication-Efficient Learning of Deep Networks from Decentralized Data
B. McMahan, E. Moore, D. Ramage, S. Hampson, and B. A. y Arcas, "Communication-Efficient Learni ...
- 百度Paddle会和Python一样,成为最流行的深度学习引擎吗?
PaddlePaddle会和Python一样流行吗? 深度学习引擎最近经历了开源热.2013年Caffe开源,很快成为了深度学习在图像处理中的主要框架,但那时候的开源框架还不多.随着越来越多的开发者开 ...
- django学习之Model(二)
继续(一)的内容: 1-跨文件的Models 在文件头部import进来,然后用ForeignKey关联上: from django.db import models from geography.m ...
- 联邦学习开源框架FATE助力腾讯神盾沙箱,携手打造数据安全合作生态
近日,微众银行联邦学习FATE开源社区迎来了两位新贡献者——来自腾讯的刘洋及秦姝琦,作为云计算安全领域的专家,两位为FATE构造了新的功能点,并在Github上提交修复了相关漏洞.(Github项目地 ...
- 联邦学习(Federated Learning)
联邦学习简介 联邦学习(Federated Learning)是一种新兴的人工智能基础技术,在 2016 年由谷歌最先提出,原本用于解决安卓手机终端用户在本地更新模型的问题,其设计目标是 ...
- 腾讯数据安全专家谈联邦学习开源项目FATE:通往隐私保护理想未来的桥梁
数据孤岛.数据隐私以及数据安全,是目前人工智能和云计算在大规模产业化应用过程中绕不开的“三座大山”. “联邦学习”作为新一代的人工智能算法,能在数据不出本地的情况下,实现共同建模,提升AI模型的效果, ...
随机推荐
- 遍历hashmap的6种方法
1. 通过ForEach循环进行遍历 mport java.io.IOException; import java.util.HashMap; import java.util.Map; public ...
- LINUX学习-Mysql集群-多主一从备份
基本原理:从服务器开启两个线程,一个备份主1,一个备份主2. 一.准备 主1:192.168.88.20 主2:192.168.88.30 从:192.168.88.40 两个主服务器开启binlog ...
- Typora+PicGo-Core实现图片自动上传gitee图床
说明: 使用gitee作为图床: 客户机为Mac M1: Typora版本:1.0.2 (5990). gitee配置步骤 需要拥有一个gitee账号,创建一个公有仓库用于存储图片,然后需要生成一个t ...
- 【数据结构】图的基本操作——图的构造(邻接矩阵,邻接表),遍历(DFS,BFS)
邻接矩阵实现如下: /* 主题:用邻接矩阵实现 DFS(递归) 与 BFS(非递归) 作者:Laugh 语言:C++ ***************************************** ...
- EF4中多表关联查询Include的写法
大家好,好久没有写作了,最近遇到了个问题,最终是靠自己的尝试写出来的,希望可以帮到有需要的人. 在我们查询时通常会遇到多级表关联的情况,很多时候有人会想写一个from LINQ语句来解决,那么冗长的代 ...
- vscode设置vue结构的初始代码片段
{ "Print to console": { "prefix": "vue", "body": [ "< ...
- 机器学习&恶意代码动态检测
目录 写在前面 1 基于API调用的统计特征 2 API序列特征 3 API调用图 4 基于行为的特征 references: 写在前面 对恶意程序动态检测方法做了概述, 关于方法1和2可以参考阿里云 ...
- C# 基本控件使用练习
自己设计并编写一个 Windows 应用程序,要求用到 TextBox.GroupBox.RadioButton.CheckBox.ComboBox.ListBox 控件. 代码如下: 页面1: us ...
- 一些Markdown扩展语法
相信很多人跟我一样,对Markdown是"一知半解",会打一点,知道一点,但是其实从没花哪怕一分钟了解过.其实除了标题粗体插入代码,Markdown还有很多有趣的基础语法和扩展语法 ...
- netty基础知识
参考 http://www.infoq.com/cn/articles/netty-high-performance 1. 传统 RPC 调用性能差的三宗罪 1)网络传输方式问题 2)序列化方式问题 ...