《机器学习实战》kNN算法及约会网站代码详解
使用kNN算法进行分类的原理是:从训练集中选出离待分类点最近的kkk个点,在这kkk个点中所占比重最大的分类即为该点所在的分类。通常kkk不超过202020
kNN算法步骤:
- 计算数据集中的点与待分类点之间的距离
- 按照距离升序排序
- 选出距离最小的kkk个点
- 计算这kkk个点所在类别出现的频率(次数)
- 返回出现频率最高的点的类别
代码的实现:
首先导入numpy模块和operator模块,建立一个数据集
from numpy import *
import operator
def createDataSet():
group = array([[1.0, 1.1], [1.0, 1.0], [0, 0], [0, 0.1]])
labels = ['A', 'A', 'B', 'B']
return group, labels
kNN算法的核心代码
# inX-用于分类的输入向量;dataSet-训练样本集;labels-标签向量;k-选择最近邻居的个数
# 实现kNN算法
def classify0(inX, dataSet, labels, k):
# shape返回各个维度的维数,shape[0]表示最外围的数组的维数,shape[1]表示次外围的数组的维数,数字不断增大,维数由外到内。
# 例如:二维数组中,shape[0]表示行数,shape[1]表示列数
dataSetSize = dataSet.shape[0]
# tile([n1,n2](a,b))表示在行的方向上重复[n1,n2]a次,在列的方向上重复b次
# 两个矩阵大小相同的矩阵相减
diffMat = tile(inX, (dataSetSize, 1)) - dataSet
# 对应位置的元素直接相乘
# 如果需要矩阵乘法,使用dot(a,b)
sqDiffMat = diffMat ** 2
# sum(axis=1)表示按行(第二维度)相加,axis=0表示按列(第一维度)相加
# 此处得到inX到dataSet各点的距离的平方
sqDistances = sqDiffMat.sum(axis=1)
distances = sqDistances ** 0.5
# 升序排序后返回其下标
sortedDistIndicies = distances.argsort()
classCound = {}
for i in range(k):
# 当前点的标签
voteIlabel = labels[sortedDistIndicies[i]]
# 将点的标签数+1
classCound[voteIlabel] = classCound.get(voteIlabel, 0) + 1
# 将字典分解成元组列表,并按照第二个元素进行降序排序
sortedClassCount = sorted(classCound.items(), key=operator.itemgetter(1), reverse=True)
return sortedClassCount[0][0]
使用K-近邻算法改进约会网站的配对效果
数据集的处理
首先我们需要处理数据集,将其转换成训练样本矩阵和类标签向量
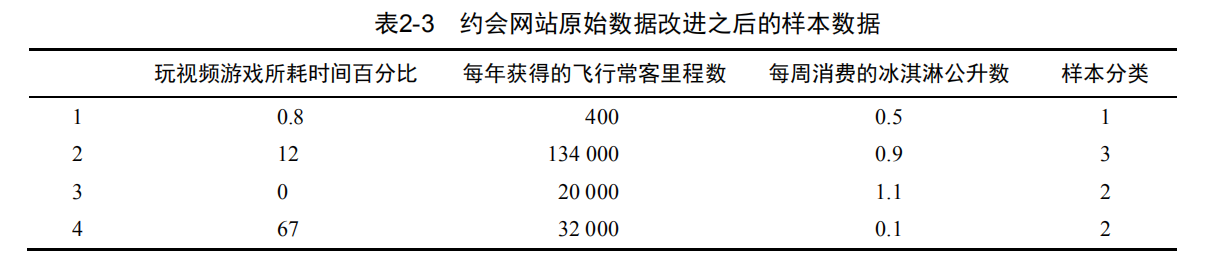
约会网站的数据集对应的文件名是datingTestSet2.txt,每列对应的标签分别是:每年获得的飞行常客里程数;玩视频游戏所耗时间百分比;每周消费的冰淇淋公升数;属于哪一类型的人
# 将文本记录转换成Numpy的解析程序
def file2matrix(filename):
fr = open(filename)
arrar0Lines = fr.readlines()
# 获得文件行数
number0fLines = len(arrar0Lines)
# 创建一个number0fLines行3列的全是0的矩阵
retrunMat = zeros((number0fLines, 3))
classLabelVector = []
index = 0
for line in arrar0Lines:
line = line.strip()
listFromLine = line.split('\t')
# 选取每行的前三个元素放入returnMat中
retrunMat[index, :] = listFromLine[0:3]
# 将所属类别放入classLabelVector
classLabelVector.append(int(listFromLine[-1]))
index += 1
return retrunMat, classLabelVector
使用Matplotlib创建散点图
在命令行环境中,输入:
import kNN
from numpy import *
import matplotlib
import matplotlib.pyplot as plt
datingDataMat,datingLabels=kNN.file2matrix('datingTestSet2.txt')
# 创建一个画布
fig=plt.figure()
# 111的含义是将画布分割成1行1列,画像在从左到右,从上到下第一块
ax=fig.add_subplot(111)
# 以第二列和第三列为x,y轴画出散列点,给予不同的颜色和大小
# scatter(x,y,s=1,c="g",marker="s",linewidths=0)
# s:散列点的大小,c:散列点的颜色,marker:形状,linewidths:边框宽度
ax.scatter(datingDataMat[:,1],datingDataMat[:,2],15.0*array(datingLabels),15.0*array(datingLabels))
plt.show()
此时,可以得到数据集的散点图:(横坐标是玩视频游戏所耗时间百分比,纵坐标是每周消费的冰淇淋公升数)
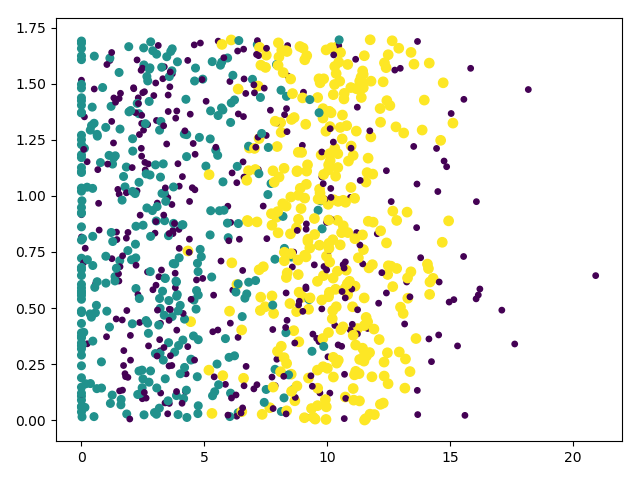
归一化数据
可以看出,在计算点的距离时,里程数对于距离的影响特别大,为了减小这个影响,需要将所有的数据范围处理到000到111或−1-1−1到111之间,利用下面的公式,可以实现将特征值转化为[0,1][0,1][0,1]区间内的值:
newValue=(oldValue−min)/(max−min)
newValue=(oldValue-min)/(max-min)
newValue=(oldValue−min)/(max−min)
代码如下:
# 归一化特征值
def autoNorm(dataSet)
# 按列查找最大值和最小值
minVals = dataSet.min(0)
maxVals = dataSet.max(0)
ranges = maxVals - minVals
# 创建一个和dataSet大小相同的全是0的数组
normDataSet = zeros(shape(dataSet))
m = dataSet.shape[0]
# 获得值为oldValue-min的数组
normDataSet = dataSet - tile(minVals, (m, 1))
# 归一化的数组
normDataSet = normDataSet / tile(ranges, (m, 1))
return normDataSet, ranges, minVals
分类器针对约会网站的测试代码
使用数据集中的10%10\%10%的数据作为测试数据,剩余的90%90\%90%作为数据集
# 对于数据的测试
# 选出10%作为测试数据,剩余90%作为数据集
def datingClassTest():
hoRatio = 0.10
datingDataMat, datingLabels = file2matrix('datingTestSet2.txt')
normMat, ranges, minVals = autoNorm(datingDataMat)
m = normMat.shape[0]
# 获得测试数据的组数
numTestVecs = int(m * hoRatio)
errorCount = 0.0
for i in range(numTestVecs):
classifierResult = classify0(normMat[i, :], normMat[numTestVecs:m, :], datingLabels[numTestVecs:m], 3)
print("the classifier came back with: %d, the real answer is: %d" % (classifierResult, datingLabels[i]))
if (classifierResult != datingLabels[i]):
errorCount += 1.0
print("the total error rate is: %f" % (errorCount / float(numTestVecs)))
约会网站预测函数
def classifyPerson():
resultList = ['not at all', 'in small doses', 'in large doses']
percentTats = float(input("percentage of time spent palying video games?"))
ffMiles = float(input("fregunt flier miles earned per year?"))
iceCream = float(input("liters of ice cream consumed per year?"))
datingDataMat, datingLabels = file2matrix('datingTestSet2.txt')
normMat, ranges, minVals = autoNorm(datingDataMat)
inArr = array([ffMiles, percentTats, iceCream])
classifierResult = classify0((inArr - minVals) / ranges, normMat, datingLabels, 3)
print("You will probably like this person: ", resultList[classifierResult - 1])
《机器学习实战》kNN算法及约会网站代码详解的更多相关文章
- k-近邻(KNN)算法改进约会网站的配对效果[Python]
使用Python实现k-近邻算法的一般流程为: 1.收集数据:提供文本文件 2.准备数据:使用Python解析文本文件,预处理 3.分析数据:可视化处理 4.训练算法:此步骤不适用与k——近邻算法 5 ...
- "二分法"-"折半法"-查找算法-之通俗易懂,图文+代码详解-java编程
转自http://blog.csdn.net/nzfxx/article/details/51615439 1.特点及概念介绍 下面给大家讲解一下"二分法查找"这个java基础查找 ...
- 实现迁徙学习-《Tensorflow 实战Google深度学习框架》代码详解
为了实现迁徙学习,首先是数据集的下载 #利用curl下载数据集 curl -o flower_photos.tgz http://download.tensorflow.org/example_ima ...
- 机器学习实战笔记一:K-近邻算法在约会网站上的应用
K-近邻算法概述 简单的说,K-近邻算法采用不同特征值之间的距离方法进行分类 K-近邻算法 优点:精度高.对异常值不敏感.无数据输入假定. 缺点:计算复杂度高.空间复杂度高. 适用范围:数值型和标称型 ...
- BM算法 Boyer-Moore高质量实现代码详解与算法详解
Boyer-Moore高质量实现代码详解与算法详解 鉴于我见到对算法本身分析非常透彻的文章以及实现的非常精巧的文章,所以就转载了,本文的贡献在于将两者结合起来,方便大家了解代码实现! 算法详解转自:h ...
- Kaggle网站流量预测任务第一名解决方案:从模型到代码详解时序预测
Kaggle网站流量预测任务第一名解决方案:从模型到代码详解时序预测 2017年12月13日 17:39:11 机器之心V 阅读数:5931 近日,Artur Suilin 等人发布了 Kaggl ...
- SSD算法及Caffe代码详解(最详细版本)
SSD(single shot multibox detector)算法及Caffe代码详解 https://blog.csdn.net/u014380165/article/details/7282 ...
- 基础 | batchnorm原理及代码详解
https://blog.csdn.net/qq_25737169/article/details/79048516 https://www.cnblogs.com/bonelee/p/8528722 ...
- 非极大值抑制(NMS,Non-Maximum Suppression)的原理与代码详解
1.NMS的原理 NMS(Non-Maximum Suppression)算法本质是搜索局部极大值,抑制非极大值元素.NMS就是需要根据score矩阵和region的坐标信息,从中找到置信度比较高的b ...
随机推荐
- 🚀 RabbitMQ课程发布-KuangStudy
RabbitMQ课程上线(44集) 视频教程地址:https://www.kuangstudy.com/course/detail/1323452886432944129 专栏地址:https://w ...
- C#筛选项联动,联动筛选
protected void Page_Load(object sender, EventArgs e) { if (!IsPostBack) { FillDep(); } // FillDG(); ...
- linux 内存变量的分布
我们知道,linux通过虚拟内存管理进程的内存(进程的地址空间),而进程的地址空间分布如下 : 从进程的空间中可以看出,内存中的变量有的来自可执行elf文件,在elf文件中已经分配好存储空间,有的是在 ...
- C语言大小端判定
要判定大小端?需要弄清以下几个问题: 1.当一个变量占多个字节时,变量的指针指向的是低地址 2.什么是大小端? 大端模式:是指数据的高字节保存在内存的低地址中,而数据的低字节保存在内存的高地址中. 小 ...
- Elasticsearch【基础入门】
目录 一.操作index 1.查看index 2.增加index 3.删除index 二.操作index 1.新增document 2.查询type 全部数据 3.查找指定 id 的 document ...
- mysql触发器实例说明
触发器是一类特殊的事务 ,可以监视某种数据操作(insert/update/delete),并触发相关操作(insert/update/delete). 看以下事件: 完成下单与减少库存的逻辑 Ins ...
- mybatis-插件开发
在Executor.StatementHandler.parameterHandler.resultSetHandler创建的时候都有一步这样的操作xxxHandler=interceptorChai ...
- linux网络相关命令之脚本和centos启动流程
nice 功用:设置优先权,可以改变程序执行的优先权等级.等级的范围从-19(最高优先级)到20(最低优先级).优先级为操作系统决定cpu分配的参数,优先级越高,所可能获得的 cpu时间越长. 语法: ...
- 【Java 与数据库】How to Timeout JDBC Queries
How to Timeout JDBC Queries JDBC queries by default do not have any timeout, which means that a quer ...
- BigDecimal 中 关于RoundingMode介绍
RoundingMode介绍 RoundingMode是一个枚举类,有以下几个常量:UP.DOWN.CEILING.FLOOR.HALF_UP.HALF_DOWN.HALF_EVEN.UNNECESS ...