(转)Amazon Aurora MySQL 数据库配置最佳实践
转自:https://zhuanlan.zhihu.com/p/165047153
Amazon Aurora MySQL 数据库配置最佳实践

在AWS Cloud当中迁移或启动新的Amazon Aurora MySQL实例之后,您是否考虑过以下几个问题?
- “接下来该做什么?我该如何让实例保持最佳运行状态?”
- “是否需要对现有参数做出修改?”
- “具体该对哪些参数做出修改?”
如果这些问题确实困扰着您,希望本篇文章能给大家带来一点有意义的指导与启发。
在本文中,我们将探讨、阐述并总结Amazon Aurora(兼容MySQL)当中的参数配置建议。这些数据库参数本身及其取值,将在AWS Cloud内新创建或迁移实例的存留、调优及重新配置当中发挥重要作用。另外,我们还将讨论应该将Amazon RDS for MySQL中的哪些参数保留至Aurora实例当中。最后,本文还将论述参数的默认值、哪些参数对您实例的稳定性及性能优化至关重要等具体问题。
在执行变更之前,首先需要明确的就是变更背后的需求与动机。尽管大多数参数设置已经具有不错的默认值,但应用程序工作负载本身的变化可能要求我们对参数做出具体调整。因此在着手修改之前,请先回答以下几个问题:
- 当前是否存在稳定性问题,例如重新启动或者故障转移?
- 我能让应用程序的查询运行速度更快一些吗?
Aurora参数组快速入门
Aurora MySQL参数组分为两种类型:数据库参数组与数据库集群参数组。其中某些参数会对整个数据库集群的配置产生影响,例如二进制日志格式、时区与字集集默认值等。其他参数的影响范围则仅限于单一数据库实例。
在本文中,我们将结合不同的上下文对各项参数进行分类,聊聊哪些参数会影响Aurora集群的行为、稳定性及功能,而哪些参数会在变更之后影响性能表现。
需要强调的是,这两种参数类型都具有预设默认值,而且只有部分参数允许修改。
要深入了解参数组的修改与使用基础知识,请参阅《Aurora用户指南》中的以下主题:
在对生产数据库“下手”之前
参数变更往往会产生意想不到的结果,包括性能下降或者系统不稳定等。在对任何数据库配置参数做出变更之前,请首先思考以下最佳实践:
- 在测试环境中为生产实例创建克隆或还原快照(详见说明文档)。通过这种方式,您既获得高度近似于生产环境的测试条件,又不致对实际业务造成影响。
- 为测试实例生成可模拟生产工作负载的工作负载。
- 根据各项关键性能指标检查系统性能,具体包括CPU利用率、数据库连接数量、内存利用率、缓存命中率、查询吞吐量以及延迟等。请在执行变更之前提取这些基准数据,并在变更之后观察结果变化。
- 一次只变更一项参数,以避免发生歧义。
- 如果变更未能对测试系统产生可以直接测量的影响,请考虑将参数恢复为默认值。
- 记录哪些参数能够产生积极影响,以及哪些性能指标因变更而发生了切实改善。
默认参数值及其重要性
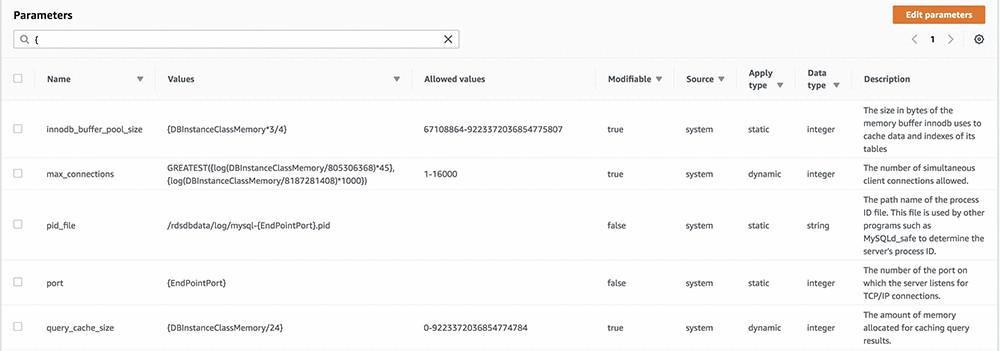
某些数据库实例参数当中包含变量或者公式,其值则由常量确定——例如实例大小、内存占用量、实例的网络端口及其分配到的存储容量等。大家最好不要变动这些设置,因为这些参数会随着实例的规模伸缩而自动调整。
例如,Aurora数据库参数innodb_buffer_pool_size的默认值为:
{DBInstanceClassMemory*3/4}
DBInstanceClassMemory
是一项变量,以GiB为单位设置为您实例的内存大小。例如:对于拥有30.5 GiB内存的db.r4.xlarge实例来说,此值为20090716160 bytes,即18.71 GiB。
假如我们决定将此参数设置为一个固定值,例如18000000000 bytes,而后对db.r4.large实例执行缩容操作,那么实例总内存将降低至原本的一半(15.2 GiB)。在对数据库引擎的修改完成之后,我们很可能遭遇内存不足问题,并导致实例无法正确启动。
要快速浏览由系统变量自动计算得出的参数,大家可以在参数组定义中搜索这些参数,具体方法为:搜索大括号字符“{”。
如果您打算查询实例所使用的实际值,可以通过两种方式在命令行上实现。具体方法为使用SHOW GLOBAL VARIABLES 或者 SELECT语句:
mysql> SHOW GLOBAL VARIABLES where Variable_Name='innodb_buffer_pool_size';
+-------------------------+------------+
| Variable_name | Value |
+-------------------------+------------+
| innodb_buffer_pool_size | 8001683456 |
+-------------------------+------------+
1 row in set (0.01 sec)
mysql> SELECT @@innodb_buffer_pool_size;
+---------------------------+
| @@innodb_buffer_pool_size |
+---------------------------+
| 8001683456 |
+---------------------------+
1 row in set (0.00 sec)参数值设置错误的症状与诊断
当某些参数发生设置错误时,有可能在MySQL错误日志中被记录为内存不足。在这种情况下,实例会进入滚动重启状态并生成类似于以下形式的事件日志,同时就需要调整的参数值提供相应建议:
2018-12-29 19:05:16 UTC [-]MySQL has been crashing due to incompatible parameters. Please check your memory parameters, in particular the max_connections, innodb_buffer_pool_size, key_buffer_size, query_cache_size, tmp_table_size, innodb_additional_mem_pool_size and innodb_log_buffer_size. Modify the memory parameter and reboot the instance.参数分类
在本文的讨论范围之内,我们将Aurora MySQL参数分为两大类:
- 负责控制数据库行为与功能,但对资源利用率及实例稳定性没有影响的参数。
- 通过管理实例中资源(例如缓存及基于内存内的缓冲区)的分配方式,对性能造成影响的参数。
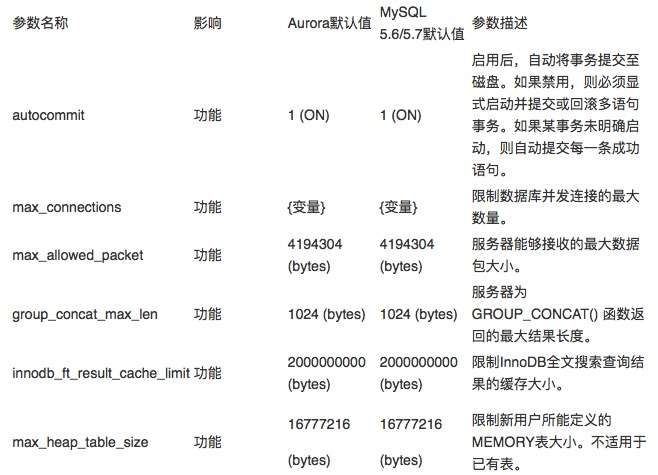
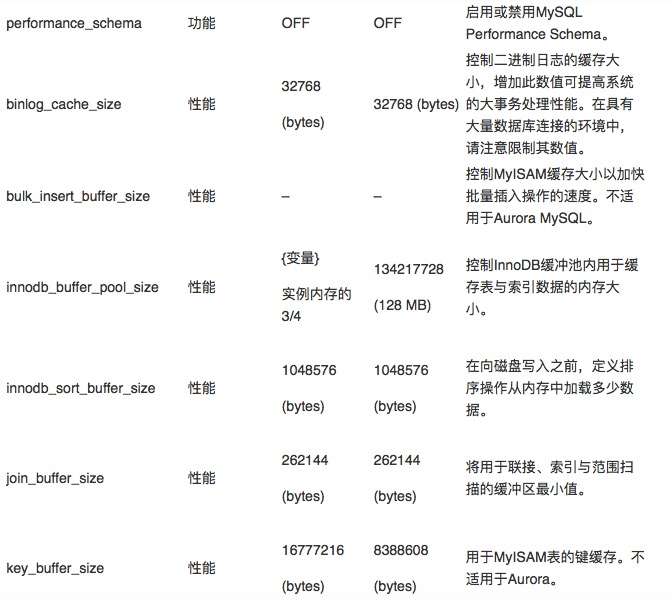
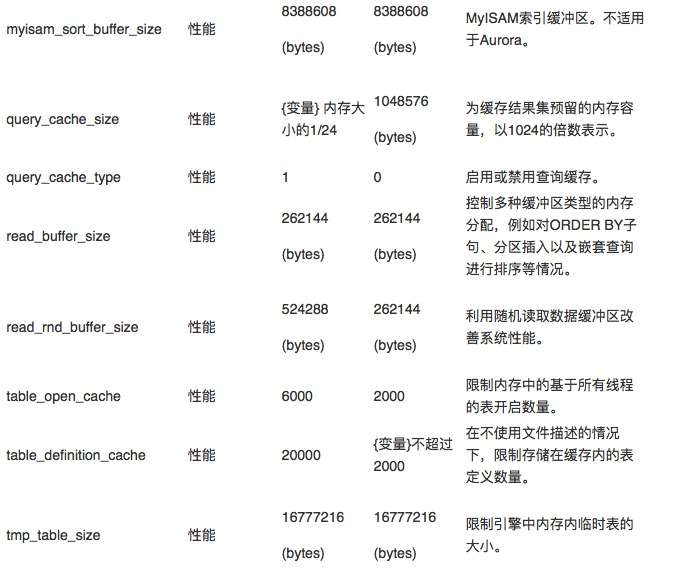
下面,我们一起来看其中一部分具有代表性的参数、对应默认值,以及对它们做出修改后会给实例的行为或性能造成哪些影响。下表所示,为参数组中列出的参数名称、Aurora与MySQL默认值、以及受此参数影响的功能摘要。
建议与影响
下面我们对各项关键参数给数据库带来的具体影响做出简要说明,同时通过具体用例介绍这些参数的调整方式:
autocommit
推荐设置:使用默认值(1或ON)以保证每条SQL语句(除非属于由用户开启的事务的组成部分)在运行时可自动提交。
影响:将值设置为OFF可能导致使用模式错误,例如未决事务的打开速度减慢、未被关闭甚至无法正确提交。这会影响到数据库的性能与稳定性。
max_connections
建议设置:使用默认值(可变值)。在使用自定义值时,请保证只配置为应用程序实际用于任务执行的连接数量。
影响:将连接限制数量设置得过高,有可能占用更多内存容量,且其中大部分资源被浪费在未使用连接上。此外,这种设置还可能引发数据库连接峰值,进而影响数据库的性能与稳定性。
系统会根据您的实例内存分配方式与大小,利用以下公式自动填充此变量参数,因此建议您优先使用默认值:
GREATEST({log(DBInstanceClassMemory/805306368,2)*45},{log(DBInstanceClassMemory/8187281408,2)*1000})例如,对于拥有15.25 GiB内存的Aurora MySQL db.r4.large实例而言,此项参数将被设置为1000:
DBInstanceClassMemory = 16374562816 bytes
max_connections = GREATEST({log(16374562816/805306368,2)*45},{log(16374562816/8187281408,2)*1000})
max_connections = GREATEST(195.56,1000) = 1000如果遇到连接错误,且连接错误日志中显示大量Too many connections,可将此项参数设置为固定值(而非变量值)。
如果您的应用程序需要更多连接,因此有必要将max_connections设置为固定值时,请考虑在应用程序与数据库之间建立连接池或代理。这种方式同样适用于难以可靠预测或控制连接数量的场景。
当大家将这项参数手动配置为超过建议连接数的值时,Amazon CloudWatch中的数据库连接指标会在超出阈值的部分显示红线。CloudWatch的判断标准源自以下公式:
Threshold value for max_connections = {DBInstanceClassMemory/12582880}例如,对于具有15.25 GiB内存( 15.25 x 1024 x 1024 x 1024 = 16374562816 bytes)的db.r4.large实例,警戒阈值大约为1300条连接。当然,如果实例资源充足,您仍然可以使用配置中指定的最大连接数。
max_allowed_packet
建议设置:使用默认值(4194304 bytes)。仅在数据库工作负载有明确需求时,才使用自定义值。在处理会返回大元素(例如长字符串或BLOB)的查询时,请调整此项参数。
影响:在此处设置较大的值,并不会影响到消息缓冲区的初始大小。相反,此参数只是在查询负载增加时,允许系统将消息缓冲区扩容至预先定义的上限。如果设定较大的参数值,一旦出现大量合法的并发查询,则可能引发内存不足问题。
如果将此项参数设置得太小,则会显示以下错误:
ERROR 1153 (08S01) at line 3: Got a packet bigger than 'max_allowed_packet' bytes
group_concat_max_len
建议设置:使用默认值(1024 bytes)。仅在工作负载有明确需求时使用自定义值。具体而言,只在您希望变更GROUP_CONCAT()语句的返回值并允许引擎返回更长的列值时,才对此项参数做出调整。此值应与max_allowed_packet并行使用,后者负责确定响应的最大大小。
影响:将这项参数设置得过高,可能导致内存占用量过高以及内存不足等问题。而设置得太低则可能导致查询失败。
innodb_ft_result_cache_limit
建议设置:使用默认值(2000000000 bytes)。在工作负载有明确需求时使用自定义值。
影响:由于该值已经接近1.9 GiB,进一步增大该值有可能导致内存不足。
max_heap_table_size
建议设置:使用默认值(16777216 bytes)。限制用户在内存内创建表时指定的最大大小。变更此值只会影响新创建的表,原有表不受影响。
影响:将此参数设置过高会导致内存利用率提升,并在内存内表量激增时导致内存不足问题。
performance_schema
建议设置:由于会大量占用内存,请在t2实例上禁用此参数。
影响:在Aurora MySQL 5.6当中,系统已经通过启发式方式对Performance Schema内存进行了预分配。这项预分配以其他配置参数为基础,具体包括max_connections, table_open_cache及table_definition_cache等。在Aurora MySQL 5.7中,Perofmrance Schema内存采用按需分配模式。Performance Schema通常会消耗1到3 GB内存。如果数据库实例的内存不足,则启用Performance Schema有可能引发内存不足问题。
binlog_cache_size
建议设置:使用默认值(32768 bytes)。这项参数负责控制二进制日志缓存所能使用的内存量。调高这项参数可利用缓冲区避免大量磁盘写入,从而提升系统对大型事务的处理性能。此缓存按连接进行分配。
影响:对于数据库连接数量较大的环境,请控制此项参数以避免导致内存不足问题。
bulk_insert_buffer_size
建议设置:使用默认值,此参数并不适用于Aurora MySQL。
innodb_buffer_pool_size
建议设置:使用默认值(可变值),此参数在Aurora中被预配置为实例内存总量的75%。您可以在SHOW ENGINE INNODB STATUS的输出结果中查看缓冲池的使用情况。
影响:较大的缓冲池可在系统重复访问同一表内数据时减少磁盘I/O操作,进而提高整体性能。由于需要容纳InnoDB引擎本体,因此实际分配的内存量可能略高于实际配置值。
innodb_sort_buffer_size
建议设置:使用默认值(1048576 bytes)。
影响:高于默认值可能会给具有大量并发查询的系统带来整体内存压力。
join_buffer_size
建议设置:使用默认值(262144 bytes)。各种类型的操作(包括JOIN)中已经预先分配有该值,且单一查询可对缓冲区内的多个实例进行分配。如果需要提高联接性能,建议大家向相应表中添加索引。
影响:在具有大量并发查询的环境中,更改此参数可能带来严重的内存压力。即使增加索引,调高此值也无法实现更好的JOIN查询性能。
key_buffer_size
建议设置:使用默认值(16777216 bytes),因为此项参数与Aurora无关,且仅影响MyISAM表的性能。
影响:不会对Aurora性能造成影响。
myisam_sort_buffer_size
建议设置:使用默认值(8388608 bytes)。由于不会影响到InnoDB,因此这项参数不适用于Aurora。
影响:不会对Aurora性能造成影响。
query_cache_size
建议设置:使用默认值(可变值)。此项参数在Aurora中已经预先调整,且实际值远大于MySQL默认值。Aurora的查询缓存不会出现可扩展性问题(MySQL中的查询缓存同样不会出现此类问题)。但您也可以根据实际需求,修改此项参数以适应高吞吐量、高需求工作负载。
影响:通过此缓存访问查询时,会对查询性能造成影响。您可以在“QCache”部分下SHOW STATUS命令的输出结果中查看查询缓存的使用情况。
query_cache_type
建议设置:启用。在默认情况下,查询缓存在Aurora中处于启用状态,我们建议您保留这种启用状态,从而提高性能并降低运营成本。但如果您确定当前工作负载无法因此受益,则可禁用查询缓存。此类用例之一为高强度写入型工作负载,其中不涉及任何读取查询。
影响:如果您的工作负载会复用查询内容(例如可重复的SQL语句),那么在Aurora中禁用查询缓存可能会影响数据库性能。您可以在“QCache”部分SHOW STTUS命令的输出结果中查看查询缓存的使用情况。
read_buffer_size
建议设置:使用默认值(262144 bytes)。
影响:设置较大的值可提升整体内存压力,并可能导致内存不足问题。除非您确定能够在不损害系统稳定性的前提下改善性能,否则请不要调高此值。
read_rnd_buffer_size
建议设置:使用默认值(524288 bytes)。由于底层存储集群的性能特点,这里我们无需改动Aurora的默认设置。
影响:设置较大的值可能导致内存不足问题。
table_open_cache
建议设置:除非您的工作负载需要同时访问大量表,否则请不要改动此项参数。表缓存会占用大量内存,而Aurora中的默认值已经远高于MySQL默认值。此项参数会根据实例大小自动调整。
影响:对于包含大量表(数十万级别)的数据库,可能需要调高此项参数,这是因为某些表可能不适合保存在内存中。但将此值设置得过高可能导致内存不足。如果您启用了Performance Schema,此项设置也会间接影响到Performance Schema的可用内存量。
table_definition_cache
建议设置:使用默认值。此项参数在Aurora中的默认值已经远高于MySQL默认值,并会根据实例大小与类型进行自动调整。如果您的工作负载要求使用此参数,且数据库需要同时打开大量表,则调高参数可能会加快表开启操作的速度。此参数需要与table_open_cache配合使用。
影响:如果您启用了Performance Schema,此项设置也会间接影响到Performance Schema的可用内存量。如果使用高于默认值的设置量,可能会导致内存不足问题。
tmp_table_size
建议设置:使用默认值(16777216 bytes)。与max_heap_table_size配合,此项参数会限制用于查询处理的内存内表大小。当超出临时表容量上限时,表将被交换至磁盘。
影响:如果值设置得过高(数百MB以上)可能导致内存问题甚至内存不足。此项参数不会影响由MEMORY引擎创建的表。
结论与要点
在部署新的Aurora MySQL实例时,大部分参数已经完成预优化,足以作为后续参数变更前的良好基准。不同参数值的具体组合主要取决于系统实际情况、应用程序工作负载以及所需要的吞吐量等因素。此外,在变化率高、增长速度快、数据摄取量大且工作负载动态程度较强的数据库系统上,大家也需要对这些参数进行持续监控与评估。我们建议您每隔几个月(或者几周)进行一轮监控与评估,确保数据库始终适应应用程序与业务的实际需求。
要将参数调整成功转化为可量化的性能提升,我们建议您不断试验、建立基准并认真比较每变更后的性能结果。此外,我们还建议您在向实时生产系统提交变更之前,做好测试与性能比较工作。
如果您希望了解关于特定参数的更多详细信息,请参阅AWS支持文档或联系AWS技术客户团队。如果你喜欢今天的文章,请多多点赞评论和我们互动哦~
本篇作者
 Fabio Higa 是一名数据库专家技术账户经理,AWS 的专精方向为 RDS Aurora/MySQL 引擎。他与全球的诸多企业级客户已有逾 3 年的合作经验。在闲暇时间,他喜欢摆弄自己的汽车,并开着它们参加当地的比赛。
Fabio Higa 是一名数据库专家技术账户经理,AWS 的专精方向为 RDS Aurora/MySQL 引擎。他与全球的诸多企业级客户已有逾 3 年的合作经验。在闲暇时间,他喜欢摆弄自己的汽车,并开着它们参加当地的比赛。
(转)Amazon Aurora MySQL 数据库配置最佳实践的更多相关文章
- 解开发者之痛:中国移动MySQL数据库优化最佳实践(转)
开源数据库MySQL比较容易碰到性能瓶颈,为此经常需要对MySQL数据库进行优化,而MySQL数据库优化需要运维DBA与相关开发共同参与,其中MySQL参数及服务器配置优化主要由运维DBA完成,开发则 ...
- 中国移动MySQL数据库优化最佳实践
原创 2016-08-12 章颖 DBAplus社群 本文根据DBAplus社群第69期线上分享整理而成,文末还有书送哦~ 讲师介绍章颖 数据研发工程师 现任中国移动杭州研发中心数据研发工程师,擅长M ...
- Linux实战教学笔记29:MySQL数据库企业级应用实践
第二十九节 MySQL数据库企业级应用实践 一,概述 1.1 MySQL介绍 MySQL属于传统关系型数据库产品,它开放式的架构使得用户选择性很强,同时社区开发与维护人数众多.其功能稳定,性能卓越,且 ...
- [转帖]12条用于Linux的MySQL/MariaDB安全最佳实践
12条用于Linux的MySQL/MariaDB安全最佳实践 2018-01-04 11:05:56作者:凉凉_,soaring稿源:开源中国社区 https://ywnz.com/linuxysjk ...
- MySQL数据库企业级应用实践(主从复制)
MySQL数据库企业级应用实践(主从复制) 链接:https://pan.baidu.com/s/1ANGg3Kd_28BzQrA5ya17fQ 提取码:ekpy 复制这段内容后打开百度网盘手机App ...
- MySQL数据库企业级应用实践(多实例源码编译)
MySQL数据库企业级应用实践(多实例源码编译) 链接:https://pan.baidu.com/s/1ANGg3Kd_28BzQrA5ya17fQ 提取码:ekpy 复制这段内容后打开百度网盘手机 ...
- SQL Server系统数据库备份最佳实践
原文:SQL Server系统数据库备份最佳实践 首先了解主要的系统数据库: 系统数据库 master 包含登录信息和其他数据库的核心信息 msdb 存储作业.操作员.警报.备份还原历史.数据库邮件信 ...
- atitit.spring3 mvc url配置最佳实践
atitit.spring3 mvc url配置最佳实践 1. Url-pattern bp 1 2. 通用星号url pattern的问题 1 3. Other code 1 4. 参考 2 1. ...
- [Java Performance] 数据库性能最佳实践 - JPA和读写优化
数据库性能最佳实践 当应用须要连接数据库时.那么应用的性能就可能收到数据库性能的影响. 比方当数据库的I/O能力存在限制,或者因缺失了索引而导致运行的SQL语句须要对整张表进行遍历.对于这些问题.只相 ...
随机推荐
- PUToast - 使用PopupWindow在Presentation上模拟Toast
PUToast Android10 (API 29) 之前 Toast 组件默认只能展示在主 Display 上,PUToast 通过构造一个 PopupWindoww 在 Presentation ...
- js和c#小数四舍五入
<script language="javascript"> document.write("<h1>JS保留两位小数例子</h1>& ...
- 微信小程序自定义Tabber,附详细源码
目录 1,前言 2,说明 3,核心代码 1,前言 分享一个完整的微信小程序自定义Tabber,tabber按钮可以设置为跳转页面,也可以设置为功能按钮.懒得看文字的可以直接去底部,博主分享了小程序代码 ...
- Nebula Storage 2.0 存储格式
随着 2.0 各版本的陆续发布,Nebula Graph 迎来了一系列的改动,在存储方面,影响最大的改动就是底层编码格式进行了修改.Nebula Graph 的底层存储是基于 KV 保存在 Rocks ...
- FreeBSD ports 多线程编译
FreeBSD ports 多线程编译FORCE_MAKE_JOBS=yesMAKE_JOBS_NUMBER=4写入/etc/make.conf没有就新建.4是处理器核心数,不知道就别改.
- Java方法:命令行传参,重载,可变参数,递归
Java方法:System.out.println()//系统类.out对象.输出方法Java方法是语句的集合,他们在一起执行一个功能方法是解决一类问题的步骤的有序组合方法包含于类或对象中方法在程序中 ...
- addEventListener的第三个参数详解
示例代码 element.addEventListener("mousedown", func, { passive: true }); element.addEventList ...
- 【odoo14】第五章、服务器侧开发-基础
本章包含如下内容: 定义模型方法和使用api装饰器 向用户反馈错误信息 针对不同的对象获取空数据集 创建新纪录 更新数据集数据 搜索数据 组合数据集 过滤数据集 遍历记录集 排序数据集 重写已有业务逻 ...
- 【Django笔记1】-视图(views)与模板(templates)
视图(views)与模板(templates) 1,视图(views) 将接收到的数据赋值给模板(渲染),再传递给浏览器.HTML代码可以直接放在views.py(文件名可任意更换),也可以放在t ...
- 图片的黑魔法——GitHub 热点速览 v.21.13
作者:HelloGitHub-小鱼干 图片的黑魔法并不是图片修复.旧照上色,而是将任意文件打包成图片的样子,上传到推特.看过去这张图片平平无奇,那么普通却深藏不露,工程师 DavidBuchanan ...