面试中问你MySql,这一篇就够了
说一说主键索引与唯一索引
- 主键是一种约束,唯一索引是一种索引,两者在本质上是不同的。
- 主键索引默认是聚簇索引、唯一索引一般是非聚簇索引。
- 主键索引不能为空,唯一索引在InnoDB中可以出现多个null。
- innoDB的表,优先使用用户自定义主键作为主键、如果用户没有定义主键,则选取一个Unique键作为主键、如果表中连Unique键都没有定义的话,则InnoDB会为表默认添加一个名为row_id的隐藏列作为主键。
- 主键索引每个表只能有一个,唯一索引可以有多个。
- 主键的顺序为数据的物理顺序!
为什么要使用自增主键?
- 首先索引是帮助MySQL高效获取数据的排好序的数据结构。
- 主键的顺序为数据的物理顺序!
- 使用自增主键,那么每次插入新的记录,记录就会顺序添加到当前索引节点的后续位置,主键的顺序按照数据记录的插入顺序排列,自动有序。当一页写满,就会自动开辟一个新的页。
- 如果使用非自增主键:由于每次插入主键的值近似于随机,因此每次新记录都要被插到现有索引页的中间某个位置,此时MySQL不得不为了将新记录插到合适位置而移动数据,甚至目标页面可能已经被回写到磁盘上而从缓存中清掉,此时又要从磁盘上读回来,这增加了很多开销,同时频繁的移动、分页操作造成了大量的碎片,得到了不够紧凑的索引结构,后续不得不通过OPTIMIZE TABLE来重建表并优化填充页面。
为什么InnoDB使用B+Tree?
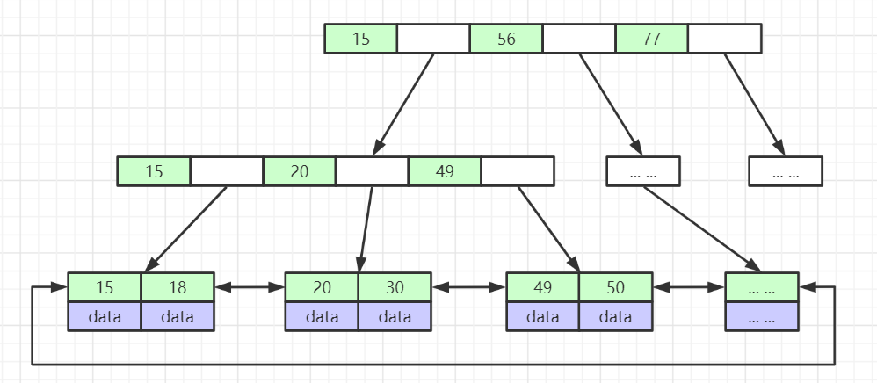
- 核心点:索引是帮助MySQL高效获取数据的排好序的数据结构。
- 普通二叉树:树的深度不好控制,查找过程中可能需要多次的随机IO!
- 红黑树:维护红黑树的成本太高!同时树的深度不好控制!
- B-Tree:页的大小固定,每个节点包含索引列值和行数据,导致存储量小!相对普通二叉树和红黑树的深度有降低。
- Hash:hash冲突问题、仅能满足 “=”,“IN”,不支持范围查询。
- B+Tree:非叶子节点不存储data,只存储索引(冗余),可以放更多的索引、叶子节点包含所有索引字段、叶子节点用指针连接,提高区间访问的性能。
平时如何做MySQL的数据优化的?
- 避免使用null。可以用0,-1作为默认值替代。
- 尽可能使用更小的字段!
- 字段有索引:count(*)≈count(1)>count(字段)>count(主键 id) //字段有索引,count(字段)统计走二级索引,二级索引存储数据比主键索引少,所以count(字段)>count(主键 id)
- 字段无索引:count(*)≈count(1)>count(主键 id)>count(字段) //字段没有索引count(字段)统计走不了索引,count(主键 id)还可以走主键索引,所以count(主键 id)>count(字段)
- 优化子查询:尽量处理为小表驱动大表的连接查询。
说一说BLOB与TEXT?
- BLOB是一个二进制对象!
- TEXT是一个不区分大小写的BLOB!
- 不能有默认值!
MySQL服务器性能分析,你用过哪些命令?
- show [globals] status like '变量名' : 查看会话中的各种信息,也能看到全局的变量。
- show profile:分析当前会话中sql语句执行的资源消耗情况的工具,可用于sql调优的测量。默认情况下处于关闭状态,并保存最近15次的运行结果。
- show processlist :显示哪些线程正在运行
MySQL中MyISAM和InnoDB的区别
- InnoDB支持事务,MyISAM不支持
- InnoDB支持外键,而MyISAM不支持
- InnoDB支持MVCC,而MyISAM不支持
- InnoDB支持行级锁,而MyISAM不支持
- InnoDB不支持全文索引,而MyISAM支持
- InnoDB由oracle开发,MyISAM由IBM开发
MySQL中MyISAM和InnoDB的select count(*) 那个更快?
- MyISAM内部维护了一个计数器,可以直接调用!
InnoDB中你了解多少日志?
- 错误日志:记录错误信息
- 查询日志:记录所有对数据区请求的信息
- 慢查询日志:查询超出变量 long_query_time 指定时间值的信息。
- 二进制日志:针对数据库改变的所有操作、中继日志(主从复制,复制过去的就是中继日志,读取中继日志加载数据,保证同步后数据一致)、事务日志(redo log是重做日志,提供前滚操作,undo log是回滚日志,提供回滚操作)
InnoDB的行级锁如何加的?了解乐观锁悲观锁么?
- 在语句后面加 for update
- 乐观锁:版本控制,每次在数据提交的时候做版本校验。
- 悲观锁:MySql的悲观锁就是打开事务,当启动事务时,如果事务中的sql语句涉及到索引并用索引进行了条件判断,那么会使用行级锁锁定所要修改的行,否则使用表锁锁住整张表。
- 简单说:乐观锁就是每次更新的时候判断版本号并加一,悲观锁就是先取锁再访问。
说一说你对视图的了解
- 视图是一种虚拟的表,具有和物理表相同的功能!
- 视图通常是有一个表或者多个表的行和列的子集!
- 视图可以做修改,但是不建议!
- 可以提高重用性、简化查询:比如要从俩张表获取信息,可以改为从视图中直接获取。
说一说drop、delete、truncate
- 这三个都表示删除!
- delete和truncate只删除表的数据,不删除表结构。drop删除表结构!
- 速度一般来说:drop > truncate > delete
- delete是dml语句,事务提交后才会生效!drop、truncate操作是ddl,直接生效,无事务的说法!
- MyISAM,InnoDB的truncate操作会重置auto_increment的值为1。delete如果清空整个表,重启后的auto_increment会从 SELECT 1+MAX(ai_col) FROM t 开始。
MySQL有哪些隔离级别,默认隔离级别是什么?
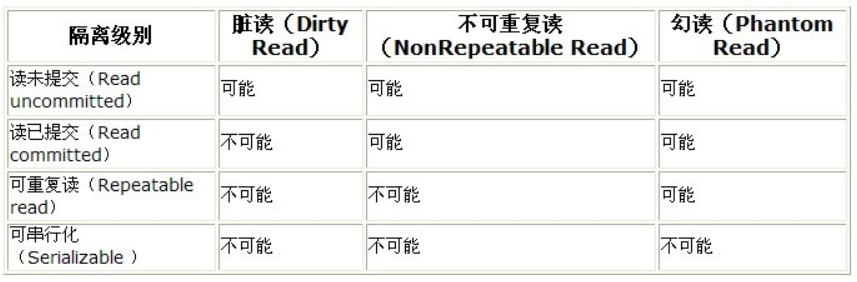
- MySQL默认的隔离级别是可重复读
说一说事务的4个特性
- 原子性(Atomicity) :事务是一个原子操作单元,其对数据的修改,要么全都执行,要么全都不执行。重点是操作!
- 一致性(Consistent) :在事务开始和完成时,数据都必须保持一致状态。这意味着所有相关的数据规则都必须应用于事务的修改,以保持数据的完整性。重点是数据!
- 隔离性(Isolation) :数据库系统提供一定的隔离机制,保证事务在不受外部并发操作影响的“独立”环境执行。这意味着事务处理过程中的中间状态对外部是不可见的,反之亦然。
- 持久性(Durable) :事务完成之后,它对于数据的修改是永久性的,即使出现系统故障也能够保持。
如何查询sql的执行计划
- 使用explain + sql语句
MySQL索引的原理是什么?
- 核心点:索引是帮助MySQL高效获取数据的排好序的数据结构
- InnoDB默认的是使用B+Tree
- 以索引记录20个字节、一行记录1kb计算,一个3层B+Tree可以存放至少500万数据。将第一层与第二层的也放在缓存中,mysql在定位一条数据的时候,只需要一次随机IO就可以找到。mysql的页是连续存放在磁盘上,由于mysql的预读机制,查询一个范围的时候,可以将大量随机IO变为顺序IO,从而大幅度的提高性能!
索引的类型有什么?
- 普通索引:加速查询
- 组合(联合)索引:加速查询
- 唯一索引:建议使用hash,InnoDB中可以有多个null,可以加速查询,列值唯一
- 主键索引:不能为null,列值唯一,表中只有一个
- 全文索引:对文本内容分词,进行搜索(只有MyISAM引擎支持)
in和exsits有什么去区别?
- 核心点:小表驱动大表,即小的数据集驱动大的数据集
- in:in里面的数据较小,in优于exists
- exists:exists数据量较大,exists优于in。
- 数据量差不多的时候,这俩个的效率也差不多
VARCHAR(N)实际能存多少数据
- 如果可以为null,值需要一个字节去区分是不是为null
- 如果N大于255,需要俩个字节去记录长度
- UTF-8一个字符三个字节,实际字符需要除以3
说一说MySQL中InnoDB引擎的行级锁
- 只有通过索引条件检索数据,才会使用行级锁,否则使用表级锁。
- 行级锁加在索引上!
MySQL支持的复制类型有哪些?
- Statement:每一条会修改数据的sql都会记录在binlog中。不需要记录每一行的变化,减少了binlog日志量,节约了IO,提高性能。可能导致(主从复制)的结果不一致。
- Row:不记录sql语句上下文相关信息,仅保存哪条记录被修改。不会出现(主从复制)的结果不一致!所有的执行的语句当记录到日志中的时候,都将以每行记录的修改来记录,这样可能会产生大量的日志内容。
- Mixed:折中处理方案,实际上就是Statement与Row的结合。一般的语句修改使用statment格式保存binlog,如一些函数,statement无法完成主从复制的操作,则采用row格式保存binlog。
说一说MySQL复制的原理以及流程
- 在Slave 服务器上执行sart slave命令开启主从复制开关,开始进行主从复制。
- 此时,Slave服务器的IO线程会通过在master上已经授权的复制用户权限请求连接master服务器,并请求从执行binlog日志文件的指定位置(日志文件名和位置就是在配置主从复制服务时执行change master命令指定的)之后开始发送binlog日志内容
- Master服务器接收到来自Slave服务器的IO线程的请求后,二进制转储IO线程会根据Slave服务器的IO线程请求的信息分批读取指定binlog日志文件指定位置之后的binlog日志信息,然后返回给Slave端的IO线程。返回的信息中除了binlog日志内容外,还有在master服务器端记录的新的binlog文件名称,以及在新的binlog中的下一个指定更新位置。
- 当Slave服务器的IO线程获取到Master服务器上IO线程发送的日志内容、日志文件及位置点后,会将binlog日志内容依次写到Slave端自身的Relay Log(即中继日志)文件(MySQL-relay-bin.xxx)的最末端,并将新的binlog文件名和位置记录到master-info文件中,以便下一次读取master端新binlog日志时能告诉Master服务器从新binlog日志的指定文件及位置开始读取新的binlog日志内容
- Slave服务器端的SQL线程会实时检测本地Relay Log 中IO线程新增的日志内容,然后及时把Relay LOG 文件中的内容解析成sql语句,并在自身Slave服务器上按解析SQL语句的位置顺序执行应用这样sql语句,并在relay-log.info中记录当前应用中继日志的文件名和位置。
说一说你对数据库范式的理解
核心点
- 灵活使用,优先范式设计,当范式设计成为系统的性能瓶颈的时候,使用反范式设计。
第一范式
- 定义:属于第一范式关系的所有属性都不可再分,即数据项不可分。
- 简单理解:每个列都不可以再拆分。
第二范式
- 定义:要求数据库表中的每个实例或行必须可以被惟一地区分。
- 简单理解:不要有部分依赖。该多对多就去做多对多,不要把多对多关系放在一张表
第三范式
- 定义:每一个非主属性既不部分依赖于也不传递依赖于业务主键,也就是在第二范式的基础上消除了非主键对主键的传递依赖。
- 简单理解:表关联有个主键就行,不要放除关联主键之外的其他关联表数据。
反范式设计
- 为了性能和读取效率的考虑而适当的对数据库设计范式的要求进行违反。
- 允许存在少量的冗余,换句话来说反范式化就是使用空间来换取时间。
说一说表锁与行锁
表锁
- 每次操作锁住整张表。
- 开销小(不需要定位到某个元素,只需要定位到表),加锁快;
- 不会出现死锁;
- 锁定粒度大,发生锁冲突的概率最高,并发度最低;
- 一般用在整表数据迁移的场景。
表锁操作方式
- 手动增加表锁: lock table 表名称 read(write),表名称2 read(write);
- 查看表上加过的锁 show open tables;
- 删除表锁 unlock tables;
行锁
- 每次操作锁住一行数据。
- 开销大,加锁慢;
- 会出现死锁;
- 锁定粒度最小,发生锁冲突的概率最低,并发度高。
- InnoDB与MYISAM的最大不同点:InnoDB支持行级锁、支持事务
- MyISAM在执行查询语句SELECT前,会自动给涉及的所有表加读锁,在执行update、insert、delete操作会自动给涉及的表加写锁。
- InnoDB在执行查询语句SELECT时(非串行隔离级别),不会加锁。但是update、insert、delete操作会加行锁。
行锁操作方式
- sql后增加for update来实现行锁。
- for update在不走索引的时候会锁表!但是当要修改或者查询的数据不存在的时候,不会锁表,也不会锁定行!
说一说间隙锁
- 间隙锁,锁的就是两个值之间的空隙。
- 间隙锁是在可重复读隔离级别下才会生效。
- 在普通索引列上,不管是何种查询,只要加锁,都会产生间隙锁,这跟唯一索引不一样;
- 在普通索引和唯一索引中,数据间隙的分析,数据行是优先根据普通索引排序,再根据唯一索引排序。
说一说临键锁
- 行锁与间隙锁的组合,它的封锁范围,既包含索引记录,又包含索引区间。。
- 这是Innodb在可重复读提交下为了解决幻读问题时引入的锁机制。
说一说读锁与写锁
- 读锁会阻塞写,但是不会阻塞读。而写锁则会把读和写都阻塞。
什么是非标准字符串类型?
- TINYTEXT
- TEXT
- MEDIUMTEXT
- LONGTEXT
说一说MySQL的时间函数

- now()(current_timestamp())函数获得的是语句开始执行时的时间,而sysdate()函数是这个函数执行时候的时间。
- CURRENT_DATE:年月日;其他:年月日时分秒
索引列的数量有没有限制?
- 有限制
- 默认16个列!
MySQL的sql语句区分大小写么?
- 不区分,下面一个sql是等价的
- SELECT NOW();
- select now();
- sElEcT nOw();
- 性能比较:关键字大写>所有语句大写>所有语句小写
说一说left join和left semi join
- left join等价于left outer join,可以直接执行。
- left semi join是MySQL内部优化的in、exist的方式。
- left join将结果集会逐条匹配,left semi join只要存在一个就算匹配上。

说一说union与union all
- 结果集:union数据不重复,union all数据可能有重复
- union:如果查询字段的顺序的第一个字段是聚集索引(或者主键),UNION的双方就会以merge的方式去重。如果查询字段的顺序非聚集索引,UNION的过程是现将两个结果集合并起来(上文提到的Concatenation),然后再做sort排序去重。
- 合并结果集,需要去重就用UNION,不需要去重就用UNION ALL,如果两个结果集中没有重复的结果集,就用UNION ALL
mysql如何记录货币
- 主要使用三种类型:float、double、decimal
| 类型 | 大小 | 范围(有符号) | 范围(无符号) | 用途 |
|---|---|---|---|---|
| float | 4bytes | (-3.402 823 466 E+38,-1.175 494 351 E-38),0,(1.175 494 351 E-38,3.402 823 466 351 E+38) | 0,(1.175 494 351 E-38,3.402 823 466 E+38) | 单精度 浮点数值 |
| double | 8 bytes | (-1.797 693 134 862 315 7 E+308,-2.225073858507 2014E-308),0,(2.225 073 858 507 201 4 E-308,1.797 693 134 862 315 7 E+308) | 0,(2.225 073 858 507 201 4 E-308,1.797 693 134 862 315 7 E+308) | 双精度 浮点数值 |
| decimal | 对decimal(M,D) ,如果M>D,为M+2否则为D+2 | 依赖于M和D的值 | 依赖于M和D的值 | 小数值 |
什么是通用sql函数
- CONCAT(A, B):连接两个字符串值以创建单个字符串输出。通常用于将两个或多个字段合并为一个字段。
- FORMAT(X, D):将数据内容格式化的,可以将数据格式化为整数或者带几位小数的浮点数(四舍五入)。
- CURRDATE(), CURRTIME():返回当前日期或时间。
- NOW():将当前日期和时间作为一个值返回。
- MONTH(),DAY(),YEAR(),WEEK(),WEEKDAY():从日期值中提取给定数据。
- HOUR(),MINUTE(),SECOND():从时间值中提取给定数据。
- DATEDIFF(A,B):确定两个日期之间的差异,通常用于计算年龄
- SUBTIMES(A,B):确定两次之间的差异。
- FROMDAYS(INT) – 将整数天数转换为日期值。
mysql有关权限的表都有哪几个?
- 权限表存放在mysql数据库里,由mysql_install_db脚本初始化。
- 这些权限表分别user,db,table_priv,columns_priv和host。
MySQL那ACID靠什么保证的?
- A原子性由undo log日志保证,它记录了需要回滚的日志信息,事务回滚时撤销已经执行成功的sql
- C一致性一般由代码层面来保证
- I隔离性由MVCC来保证
- D持久性由内存+redo log来保证,mysql修改数据同时在内存和redo log记录这次操作,事务提交的时候通过redo log刷盘,宕机的时候可以从redo log恢复
结束语
- 获取更多有价值的文章,让我们一起成为架构师!
- 关注公众号,可以让你逐步对MySQL以及并发编程有更深入的理解!
- 这个公众号,无广告!!!每日更新!!!

面试中问你MySql,这一篇就够了的更多相关文章
- 互联网公司面试必问的mysql题目(下)
这是mysql系列的下篇,上篇文章地址我附在文末. 什么是数据库索引?索引有哪几种类型?什么是最左前缀原则?索引算法有哪些?有什么区别? 索引是对数据库表中一列或多列的值进行排序的一种结构.一个非常恰 ...
- 互联网公司面试必问的mysql题目(上)
又到了招聘的旺季,被要求准备些社招.校招的题库.(如果你是应届生,尤其是东北的某大学,绝对福利哦) 介绍:MySQL是一个关系型数据库管理系统,目前属于 Oracle 旗下产品.虽然单机性能比不上or ...
- 面试必问的MySQL锁与事务隔离级别
之前多篇文章从mysql的底层结构分析.sql语句的分析器以及sql从优化底层分析, 还有工作中常用的sql优化小知识点.面试各大互联网公司必问的mysql锁和事务隔离级别,这篇文章给你打神助攻,一飞 ...
- 如何回答面试中问到的Hibernate和MyBatis的区别
这边主要是写给那些准备去面试的(没什么经验的)应聘者看的,为了在面试中更好的回答这个问题,我做一个简单的梳理和总结. 作为一名职场新人,经历过多次的面试,由于在简历中提及了Hibernate和MyBa ...
- 面试官问你MySQL的优化,看这篇文章就够了
作者:zhangqh segmentfault.com/a/1190000012155267 一.EXPLAIN 做MySQL优化,我们要善用 EXPLAIN 查看SQL执行计划. 下面来个简单的示例 ...
- 面试官问我MySQL索引,我
面试官:我看你简历上写了MySQL,对MySQL InnoDB引擎的索引了解吗? 候选者:嗯啊,使用索引可以加快查询速度,其实上就是将无序的数据变成有序(有序就能加快检索速度) 候选者:在InnoDB ...
- 面试官问我MySQL调优,我真的是
面试官:要不你来讲讲你们对MySQL是怎么调优的? 候选者:哇,这命题很大阿...我认为,对于开发者而言,对MySQL的调优重点一般是在「开发规范」.「数据库索引」又或者说解决线上慢查询上. 候选者: ...
- java开发中的重中之重-------mysql(基础篇)
介绍: mysql是目前世界上最流行的关系型数据库,在国内大的互联网公司都在使用mysql数据库,mysql经常被我们这样概述,“mysql是轻量级关系型数据库”,其实轻量级并不是说mysql是中小型 ...
- 面试中的老大难-mysql事务和锁,一次性讲清楚!
众所周知,事务和锁是mysql中非常重要功能,同时也是面试的重点和难点.本文会详细介绍事务和锁的相关概念及其实现原理,相信大家看完之后,一定会对事务和锁有更加深入的理解. 本文主要内容是根据掘金小册& ...
随机推荐
- Java SSLSocket
Java SSLSocket JSSE(Java Security Socket Extension)是Sun公司为了解决互联网信息安全传输提出的一个解决方案,它实现了SSL和TSL协议,包含了数据加 ...
- 100个Shell脚本——【脚本9】统计ip
[脚本9]统计ip 有一个日志文件,日志片段:如下: 112.111.12.248 – [25/Sep/2013:16:08:31 +0800]formula-x.haotui.com "/ ...
- Oracle中的加解密函数
对Oracle内部数据的加密,可以简单得使用DBMS_CRYPTO来进行,效果还是不错的,而且使用也比较方便,所以今天专门来学习一下这个包的使用方法.在使用之前,要注意两件事情: 1.DBMS_CRY ...
- 转 MessageDigest来实现数据加密
转自 https://www.cnblogs.com/androidsuperman/p/10296668.html MessageDigest MessageDigest 类为应用程序提供信息摘要算 ...
- JDK1.8新特性(一): 接口的默认方法default
前言 今天在学习mysql分区优化时,发现一个博客专家大神,对其发布的文章简单学习一下: 一:简介 我们通常所说的接口的作用是用于定义一套标准.约束.规范等,接口中的方法只声明方法的签名,不提供相应的 ...
- java中的原子操作类AtomicInteger及其实现原理
/** * 一,AtomicInteger 是如何实现原子操作的呢? * * 我们先来看一下getAndIncrement的源代码: * public final int getAndIncremen ...
- hive 启动不成功,报错:hive 启动报 Exception in thread "main" java.lang.NoClassDefFoundError: org/apache/hadoop/mapred/MRVersi
1. 现象:在任意位置输入 hive,准备启动 hive 时,报错: Exception in thread "main" java.lang.NoClassDefFoundErr ...
- 注册页面html版本
<!DOCTYPE html><html lang="en"><head> <meta charset="UTF-8" ...
- C#获取Windows10屏幕的缩放比例
现在1920x1080以上分辨率的高分屏电脑渐渐普及了.我们会在Windows的显示设置里看到缩放比例的设置.在Windows桌面客户端的开发中,有时会想要精确计算窗口的面积或位置.然而在默认情况下, ...
- C# 温故知新 第二篇 C# 程序的通用结构
C# 程序由一个或多个文件组成. 每个文件均包含零个或多个命名空间. 一个命名空间包含类.结构.接口.枚举.委托等类型或其他命名空间. 以下示例是包含所有这些元素的 C# 程序主干. 主要包括 1. ...