django之分页算法实现(Paginator)
导入模块:from django.core.paginator import Paginator
一、Paginator的基本用法:
from django.core.paginator import Paginator
objects = ['john','paul','george','ringo','lucy','meiry','checy','wind','flow','rain']<br>
p = Paginator(objects,3) # 3条数据为一页,实例化分页对象
print p.count # 10 对象总共10个元素
print p.num_pages # 4 对象可分4页
print p.page_range # xrange(1, 5) 对象页的可迭代范围 page1 = p.page(1) # 取对象的第一分页对象
print page1.object_list # 第一分页对象的元素列表['john', 'paul', 'george']
print page1.number # 第一分页对象的当前页值 1 page2 = p.page(2) # 取对象的第二分页对象
print page2.object_list # 第二分页对象的元素列表 ['ringo', 'lucy', 'meiry']
print page2.number # 第二分页对象的当前页码值 2 print page1.has_previous() # 第一分页对象是否有前一页 False
print page1.has_other_pages() # 第一分页对象是否有其它页 True print page2.has_previous() # 第二分页对象是否有前一页 True
print page2.has_next() # 第二分页对象是否有下一页 True
print page2.next_page_number() # 第二分页对象下一页码的值 3
print page2.previous_page_number() # 第二分页对象的上一页码值 1
print page2.start_index() # 第二分页对象的元素开始索引 4
print page2.end_index() # 第2分页对象的元素结束索引 6
二、分页功能实现实例:
模型:model.py
# 新闻 数据库模型
class News(models.Model):
# 标题
title = models.CharField(max_length=100, null=False)
# 发布日期
pub_time = models.DateTimeField(auto_now_add=True) class Meta:
# 在去模型数据的时候,按照 pub_time 字段降序排序
ordering = ['-pub_time']
视图函数:view.py
from django.core.paginator import Paginator
from datetime import datetime
# 需要导入模型:News
# 时区转换
from django.utils.timezone import make_aware
class news_list_View(View):
def get(self, request):try:
# request.GET.get('category',默认值):这个默认值只有在没有category这个属性的时候才会使用
# 如果传入的是一个 "" 空字符串,也不会使用默认值
# 所以需要 or 0 保证不为空
# category_id = int(request.GET.get('category', 0) or 0)
page = int(request.GET.get('p', 1))
except:
return HttpResponseRedirect("/cms/news_list/?p=1")
news_all = News.objects.all()# 创建 Paginator对象
# 参数1:一个可遍历的object对象
# 参数2:指定多少条数据为一页
paginator = Paginator(news_all, 10)
# 获取分页对象
# 参数page:int(第几页数据)
page_obj = paginator.page(page)
# 分页算法逻辑方法
getdata = self.get_pagination_data(page_obj, paginator)
content = {# 直接将分页对象 page_obj 对象发送给前端
'page_obj': page_obj,# 获取一个可遍历的对象:range(1,paginator.count)
# 'count_page': paginator.page_range
}
# 更新字典
content.update(getdata)
return render(request, 'cms/news_list.html', context=content) def get_pagination_data(self, page_boj, paginator, page_news_count=2):
"""
分页优化
:param page_boj:当前页面对象
:param paginator: Paginator 分页对象
:param page_news_count: 左右两边显示多少页面(前端页数) “[1] [...] [5] [6] [7] [8] [9] [...] [99]”
:return:
"""
# 获取当前页码
page_num = page_boj.number
# 得到当前可以分为多少页,获取总页数
count = paginator.num_pages
# 判断分页是否显示 “ ... ”
left_has_more = False
right_has_more = True
# 返回左右显示的页码区间 range(start,end+1) 如: 1 ... 5 6 7 8 9 ... 99
# left_page_count
# right_page_count
# 如果当前页码 >= 最大页码 -1 - page_news_count,那么就不显示 ...
if page_num >= count - page_news_count - 1:
right_has_more = False
right_page_count = range(page_num + 1, count + 1)
else:
right_page_count = range(page_num + 1, page_num + 1 + page_news_count)
#
if page_num >= 2 + page_news_count:
left_has_more = True
left_page_count = range(page_num - page_news_count, page_num)
else:
left_page_count = range(1, page_num)
return {
# 是否显示 ...
'left_has_more': left_has_more,
'right_has_more': right_has_more,
# 左边应该显示的页码
'left_page_count': left_page_count,
# 右边应该显示的页码
'right_page_count': right_page_count,
# 最大页数
'count': count
前端HTML模板:
备注:使用的是 adminLTE插件完成,需要下载和导入文件如下:
下载:adminLTE 源码
<link rel="stylesheet" href="{% static 'adminlte/bower_components/bootstrap/dist/css/bootstrap.min.css' %}">
<link rel="stylesheet" href="{% static 'adminlte/bower_components/font-awesome/css/font-awesome.min.css' %}">
<link rel="stylesheet" href="{% static 'adminlte/bower_components/Ionicons/css/ionicons.min.css' %}">
<link rel="stylesheet" href="{% static 'adminlte/dist/css/AdminLTE.min.css' %}">
<link rel="stylesheet" href=" {% static 'adminlte/dist/css/skins/_all-skins.min.css' %}">
<link rel="stylesheet" href="{% static 'adminlte/plugins/bootstrap-wysihtml5/bootstrap3-wysihtml5.min.css' %}">
{# <link rel="stylesheet" href="{% static 'css_dist/common/sweetalert.min.css' %}">#}
<link rel="stylesheet" href="http://mishengqiang.com/sweetalert/css/sweetalert.css">
<!--[if lt IE 9]>
<script src="https://oss.maxcdn.com/html5shiv/3.7.3/html5shiv.min.js"></script>
<script src="https://oss.maxcdn.com/respond/1.4.2/respond.min.js"></script>
<![endif]-->
<script src="{% static 'adminlte/bower_components/jquery/dist/jquery.min.js' %}"></script>
<script src="{% static 'adminlte/bower_components/bootstrap/dist/js/bootstrap.min.js' %}"></script>
<script src="{% static 'adminlte/bower_components/jquery-slimscroll/jquery.slimscroll.min.js' %}"></script>
<script src="{% static 'adminlte/bower_components/fastclick/lib/fastclick.js' %}"></script>
<script src="{% static 'adminlte/dist/js/adminlte.min.js' %}"></script>
<script src="{% static 'adminlte/dist/js/demo.js' %}"></script>
<body>
<div class="content-wrapper">
<section class="content-header">
<h1>新闻列表</h1>
</section>
<section class="content">
<div class="row">
<div class="col-md-12">
<div class="box box-primary">
<div class="box-header">
<!-- form-inline:横向排列 -->
</div>
<div class="box-body">
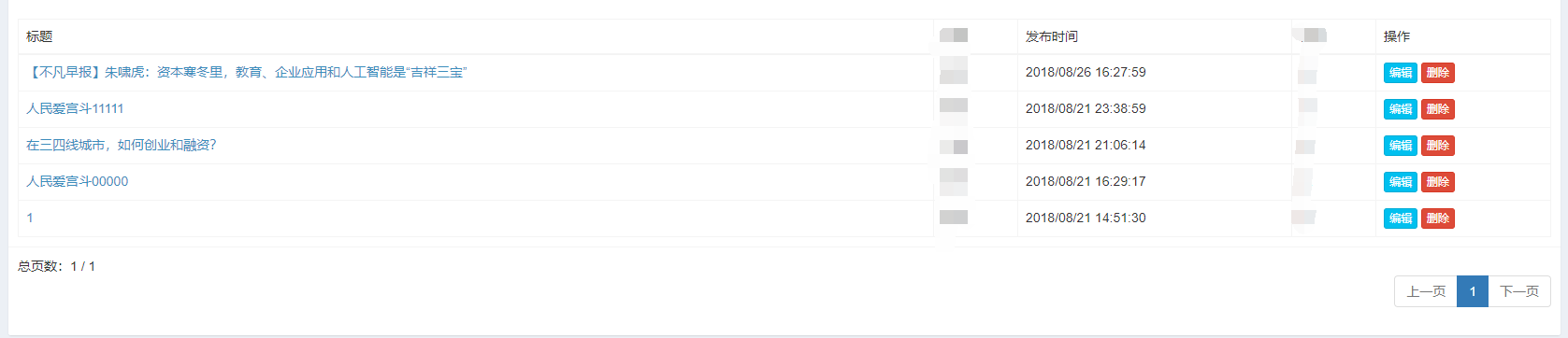
<table class="table table-bordered">
<thead>
<tr role="row">
<td>标题</td>
<td>发布时间</td>
<td>操作</td>
</tr>
</thead>
<tbody>
{% for news in page_obj %}
<tr>
<td><a href="{% url 'news:news_detail' news_id=news.id %}">{{ news.title }}</a></td>
<td>{{ news.pub_time|time_format }}</td>
<td>
<a href="#" class="btn btn-info btn-xs">编辑</a>
<button class="btn btn-danger btn-xs delete-btn" data-news-id="{{ news.pk }}">
删除
</button>
</td>
</tr>
{% endfor %}
</tbody>
</table>
</div>
<div class="box-footer">
<!-- page_obj:当前页面的对象 -->
<lable>总页数:{{ page_obj.number }} / {{ count }}</lable>
<ul class="pagination pull-right">
<!-- page_obj.has_previous:判断是否还有上一页 -->
{% if page_obj.has_previous %}
<!-- page_obj.previous_page_number:获得上一页页码 -->
<li><a href="?p={{ page_obj.previous_page_number }}">上一页</a></li>
{% else %}
<li class="disabled"><a href="javascript:void(0)">上一页</a></li>
{% endif %}
{% if left_has_more %}
<li><a href="?p=1">1</a></li>
<li><a href="javascript:void(0)">...</a></li>
{% endif %}
{% for left_page in left_page_count %}
<li><a href="?p={{ left_page }}">{{ left_page }}</a></li>
{% endfor %}
<li class="active"><a href="?p={{ page_obj.number }}">{{ page_obj.number }}</a>
</li>
{% for right_page in right_page_count %}
<li><a href="?p={{ right_page }}">{{ right_page }}</a></li>
{% endfor %}
{% if right_has_more %}
<li><a href="javascript:void(0)">...</a></li>
<li><a href="?p={{ count }}">{{ count }}</a></li>
{% endif %}
<!-- page_obj.has_next:判断是否还有下一页 -->
{% if page_obj.has_next %}
<!-- page_obj.next_page_number:获得下一页页码 -->
<li><a href="?p={{ page_obj.next_page_number }}">下一页</a></li>
{% else %}
<li class="disabled"><a href="javascript:void(0)">下一页</a></li>
{% endif %}
</ul>
</div>
</div>
</div>
</div>
</section>
</div>
</body>
效果:
All I had was dreams and unfounded self-confidence. But everything starts here.
django之分页算法实现(Paginator)的更多相关文章
- django 百度分页算法
效果如下: 脚本: 1. 脚本结构 2.pagination.py from django.utils.safestring import mark_safe class Page: ''' curr ...
- Python Django的分页,Form验证,中间件
本节内容 Django的分页 Form 中间件 1 Django 分页 1.1 Django自带的分页 1.首先来看下我的测试数据环境 ############ models.py ######### ...
- Django----列表分页(使用Django的分页组件)
目的:是为了实现列表分页 1.定制URL http://127.0.0.1:8000/blog/get_article?page=3之前定制URL是在url后增加了/id,这次使用参数的方式 def ...
- django网页分页
blog/views.py from django.core.paginator import Paginator, EmptyPage, PageNotAnInteger #导入分页插件包 def ...
- Django—自定义分页
分页功能在每个网站都是必要的,对于分页来说,其实就是根据用户的输入计算出应该显示在页面上的数据在数据库表中的起始位置. 确定分页需求: 1. 每页显示的数据条数 2. 每页显示页号链接数 3. 上一页 ...
- Django 实现分页功能(django 2.2.7 python 3.7.5 )
Django 自带名为 Paginator 的分页工具, 方便我们实现分页功能.本文就讲解如何使用 Paginator 实现分页功能. 一. Paginator Paginator 类的作用是将我们需 ...
- ASP的高效率的分页算法.net,php同样可以参考
一般习惯使用的有两种分页算法,一是传统的ADO分页,二是SELECT TOP分页算法.对于小型数据表,比如一两万的数据量的表,我倾向使用ADO算法,对于大型的数据表,则必须采用后者的算法了. 先来说说 ...
- 基于视觉的Web页面分页算法VIPS的实现源代码下载
基于视觉的Web页面分页算法VIPS的实现源代码下载 - tingya的专栏 - 博客频道 - CSDN.NET 基于视觉的Web页面分页算法VIPS的实现源代码下载 分类: 技术杂烩 2006-04 ...
- VIPS:基于视觉的页面分割算法[微软下一代搜索引擎核心分页算法]
VIPS:基于视觉的页面分割算法[微软下一代搜索引擎核心分页算法] - tingya的专栏 - 博客频道 - CSDN.NET VIPS:基于视觉的页面分割算法[微软下一代搜索引擎核心分页算法] 分类 ...
随机推荐
- 【LeetCode】96. Unique Binary Search Trees 解题报告(Python & C++)
作者: 负雪明烛 id: fuxuemingzhu 个人博客: http://fuxuemingzhu.cn/ 目录 题目描述 题目大意 解题方法 记忆化递归 动态规划 卡特兰数 日期 题目地址:ht ...
- 【LeetCode】796. Rotate String 解题报告(Python)
作者: 负雪明烛 id: fuxuemingzhu 个人博客: http://fuxuemingzhu.cn/ 目录 题目描述 题目大意 解题方法 日期 题目地址:https://leetcode.c ...
- 【LeetCode】227. Basic Calculator II 解题报告(Python)
[LeetCode]227. Basic Calculator II 解题报告(Python) 标签(空格分隔): LeetCode 作者: 负雪明烛 id: fuxuemingzhu 个人博客: h ...
- [数学]高数部分-Part V 多元函数微分学
Part V 多元函数微分学 回到总目录 Part V 多元函数微分学 多元函数微分的极限定义 多元函数微分的连续性 多元函数微分的偏导数 z=f(x, y) 多元函数微分-链式求导规则 多元函数-高 ...
- 新手入门typeScript
强类型与弱类型(类型安全) 强类型不允许随意的隐士类型转换,而弱类型是允许的 变量类型允许随时改变的特点,不是强弱类型的差异 静态类型与动态类型(类型检查) 静态类型:一个变量声明时它的类型就是明确的 ...
- 对接网易云信音视频2.0呼叫组件集成到vue中,实现web端呼叫app,视频语音通话。
项目中需要实现视频通话功能,经过公司的赛选,采用网易云信的视频通话服务,app小伙伴集成很顺利.web端需要实现呼叫app端用户.网易云信文档介绍不全,vue的demo满足不了需求,和客服人员沟通,只 ...
- 黑客帝国纯js版
明天就回家过年了,今天没什么心思上班,看了下博客,发现一个黑客帝国额js版本,地址:https://blog.csdn.net/zhongyi_yang/article/details/5384180 ...
- STM32时钟系统的配置寄存器和源码分析
一.时钟系统 概述 时钟是单片机运行的基础,时钟信号推动单片机内各个部分执行相应的指令,时钟系统就是CPU的脉搏,决定cpu速率. STM32有多个时钟来源的选择,为什么 STM32 要有多个时钟源呢 ...
- 初识python 之 爬虫:爬取双色球中奖号码信息
人生还是要有梦想的,毕竟还有python.比如,通过python来搞一搞彩票(双色球).注:此文仅用于python学习,结果仅作参考.用到知识点:1.爬取网页基础数据2.将数据写入excel文件3.将 ...
- HTTP 状态码整理