MySQL 为什么使用 B+ 树来作索引?
什么是索引?
所谓的索引,就是帮助 MySQL 高效获取数据的排好序的数据结构。因此,根据索引的定义,构建索引其实就是数据排序的过程。
平时常见的索引数据结构有:
- 二叉树
- 红黑树
- 哈希表
- B Tree
谈谈一个潜在的误区
我们首先需要澄清一点:MySQL 跟 B+ 树其实没有直接的关系,真正与 B+ 树有关系的是 MySQL 的「默认存储引擎 InnoDB」。存储引擎的主要作用是负责数据的存储和提取(简单来说就是读写),MySQL 的一个简单架构如下图所示:
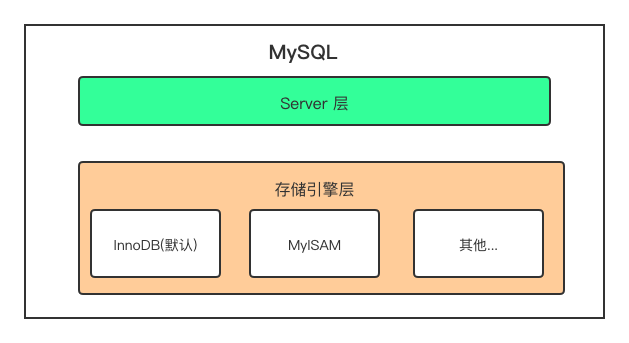
我们在创建表时就可以为当前表指定使用的存储引擎,你可以在 MySQL 的文档 Alternative Storage Engines 中找到它支持的全部存储引擎,例如:MyISAM、CSV、MEMORY 等,默认情况下,使用如下所示的 SQL 语句来创建表就会得到 InnoDB 存储引擎支撑的表:
CREATE TABLE table1 (
a INT,
b CHAR (20),
PRIMARY KEY (a))
ENGINE=InnoDB;
说完这个可能存在的误区,接下来我们进入正题,聊聊为什么 MySQL 默认的存储引擎 InnoDB 会使用 B+ 树来存储数据?
前置知识
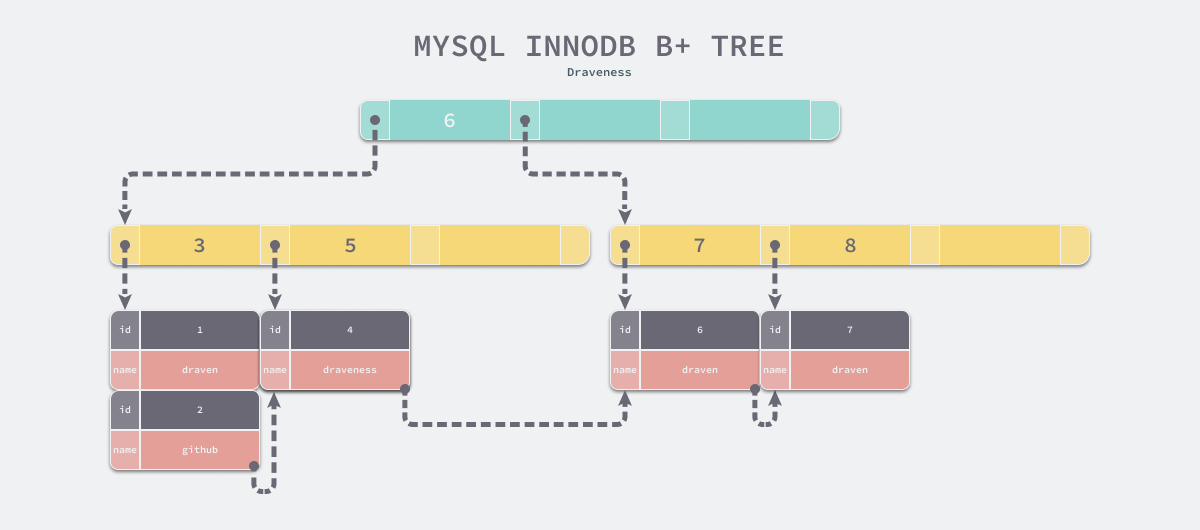
相信对 MySQL 有些了解的人都知道,无论是表中的数据(主键索引)还是辅助索引最终都会使用 B+ 树来存储数据,其中前者在表中会以 <id, row> 的方式存储,而后者会以 <index, id> 的方式进行存储,这里简单解释一下:
在主键索引中,
id是主键,我们可以通过id找到该行的全部列;在辅助索引中,索引中的几个列构成了键,我们能够通过索引中的列找到
id,如果有需要的话,可以再通过id找到当前数据行的全部内容;这里再扩展一点,如果仅需要辅助索引中的列,建议开发者在 sql 直接指定目标列,避免「回表」查询,从而提升性能。
解释一下
<index, id>:其中 index 就是指定列构建的索引,id 就是数据表的主键。
对于 InnoDB 来说,所有的数据都是以键值对的方式存储的,主键索引和辅助索引在存储数据时会将 id 和 index 作为键,将所有列和 id 作为键对应的值。
在具体分析 InnoDB 使用 B+ 树背后的原因之前,我们需要为 B+ 树找几个假想敌,因为如果我们只有一个选择,那么选择 B+ 树也并不值得讨论,找到的两个假想敌就是 B 树和哈希,这也是很多人会在面试中真实遇到的问题。我们就以这两种数据结构为例,分析比较 B+ 树的优点。
[idea]学习一门技术或者原理,多想想优缺点还有横向对比,从而加深对某项技术的理解深度。
接下来,我们将通过以下的两个方面介绍 InnoDB 这样选择的原因。
- InnoDB 需要支持的场景和功能需要在特定查询上拥有较强的性能;
- CPU 将数据从磁盘加载到内存中需要花费大量的时间,这使得 B+ 树成为了非常好的选择;
数据的持久化以及持久化数据的查询是一个非常常见的需求,而数据的持久化就需要与磁盘、内存和 CPU 打交道;MySQL 作为 OLTP 的数据库不仅需要具备事务的处理能力,而且要保证数据的持久化并且能够有一定的实时数据查询能力,这些需求决定了 B+ 树的选择,接下来我们会详细分析上述两个原因背后的逻辑。
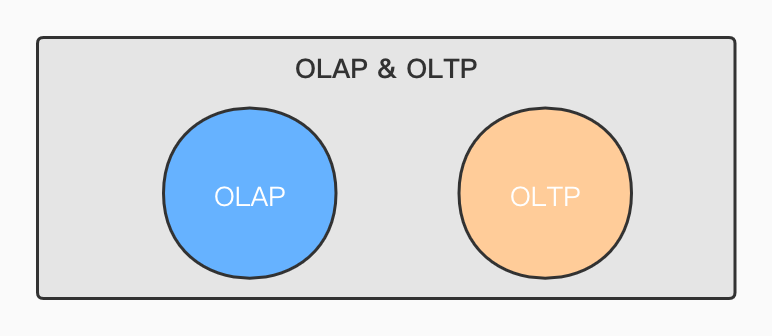
OLTP & OLAP
为了方便理解两个常见概念,我画了一张表格如下:
| 名称 | 全称 | 作用 |
|---|---|---|
| OLTP | Online Transaction Processing(在线事务处理) | 传统关系型数据库,主要用于处理基本的、日常的事务处理 |
| OLAP | Online Analytical Processing(在线分析处理) | 主要在数据仓库中使用,用于支持一些复杂的分析和决策 |
作为支撑 OLTP 数据库的存储引擎,我们经常会使用 InnoDB 完成以下的一些工作:
- 通过
INSERT、UPDATE和DELETE语句对表中的数据进行增加、修改和删除;- 通过
UPDATE和DELETE语句对符合条件的数据进行批量的删除;- 通过
SELECT语句和主键查询某条记录的全部列;- 通过
SELECT语句在表中查询符合某些条件的记录并根据某些字段排序;- 通过
SELECT语句查询表中数据的行数;- 通过唯一索引保证表中某个字段或者某几个字段的唯一性;
B Tree 结构(多叉树)
- 叶节点具有相同的深度,叶节点的指针为空(这是为什么不选 B Tree 重要原因)
- 所有索引的元素不重复
- 节点中的数据索引从左到右递增排序
为了方便理解,可以查看下图:
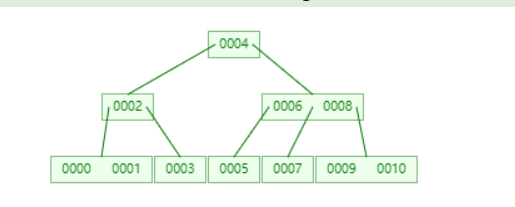
接下来,我们通过一个更加详细的例子来看一下。

每个节点维护两个数据,并指向最多 3 个子节点。如图 3 个子节点的数据分别为:小于 17, 17 ~ 35 ,大于 35。
假设,从上图中查找 10 这个数,步骤如下:
- 找到根节点,对比 10 与 17 和 35 的大小,发现 10 < 17 在左子节点,也就是第 2 层节点;
- 从根节点的指针,找到左子节点,对比 10 与 8 和 12 的大小,发现
8 < 10 < 12,数据在当前节点的中间子节点,也就是第 3 层节点;- 通过上步节点的指针,找到中间子节点(第 3 层节点),对比 10 与 9 和 10 的大小,发现
9 < 10 == 10,因此找到当前节点的第二数即为结果。
加上忽略的 12 个数据,从 26 个数据中查找一个数字 10,仅仅用了 log3(26)≈ 3次,而如果用平衡二叉树,则需要log2(26)≈ 5 次,事实证明,多叉树确实可以再次提高查找性能(因为树的高度更矮了)。
多叉树是在二分查找树的基础上,增加单个节点的数据存储数量,同时增加了树的子节点数,一次计算可以把查找范围缩小更多。
优点:在二叉平衡树的基础上,使加载一次节点,可以加载更多路径数据,同时把查询范围缩减到更小。

缺点:业务数据的大小可能远远超过了索引数据的大小,每次为了查找对比计算,需要把数据加载到内存以及 CPU 高速缓存中时,都要把索引数据和无关的业务数据全部查出来。本来一次就可以把所有索引数据加载进来,现在却要多次才能加载完。如果所对比的节点不是所查的数据,那么这些加载进内存的业务数据就毫无用处,全部抛弃。
B+ Tree 结构
- 非叶子节点不存储数据,只存储索引(冗余的),可以放更多的索引
- 叶子节点包含索引所有字段
- 叶子节点用指针链接,提高区间访问性能(可以极大减少随机I/O,进而提高性能)
为了方便理解,可以查看下图:
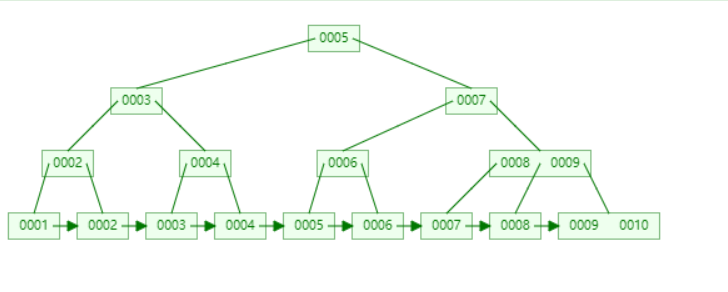
考虑到磁盘 I/O 的性能问题,以及每次 I/O 获取数据量上限的限制,提高索引本身 I/O 的方法最好是,减少 I/O 次数和每次获取有用的数据。
B-tree 大大改进了树家族的性能,它把多个数据集中存储在一个节点中,本身就可能减少了 I/O 次数或者寻道次数。
但它仍然有一个致命的缺陷,那就是它的索引数据与业务绑定在一块,而业务数据的大小很有可能远远超过了索引数据,这会大大减小一次 I/O 有用数据的获取,间接的增加 I/O 次数去获取有用的索引数据,简单来说,就是增加了随机 I/O 的性能开销。
因为业务数据才是我们查询最终的目的,但是它又是在二分查找中途过程的无用数据,因此,如果只把业务数据存储在最终查询到的那个节点是不是就可以了?
B+tree 横空出世,B+ 树就是为了拆分索引数据与业务数据的平衡多叉树。

B+ 树中,非叶子节点只保存索引数据,叶子节点保存索引数据与业务数据。这样即保证了叶子节点的简约干净,数据量大大减小,又保证了最终能查到对应的业务数。既提高了单次 I/O 数据的有效性,又减少了 I/O 次数,还实现了业务。
但是,在数据中索引与数据是分离的,不像示例那样的?
如图:我们只需要把真实的业务数据,换成数据所在地址就可以了,此时,业务数据所在的地址在 B+ 树中充当业务数据。

为什么不选择哈希表?
先说结论:哈希表对于范围查找和排序效率低,需要全表扫描,但对于单行数据查询效率高。
如果我们使用 B+ 树作为底层的数据结构,那么所有只会访问或者修改一条数据的 SQL 的时间复杂度都是 O(log n),即树的高度,但是使用哈希却有可能达到 O(1) 的时间复杂度,看起来是不是特别的美好?
但是当我们使用如下所示的 SQL 时,哈希索引的表现就不会这么好了:
SELECT * FROM user WHERE username = 'alan' ORDER BY created_at DESC
SELECT * FROM user WHERE comments_count > 100
UPDATE user SET address = 'hz' WHERE username = 'alan'
DELETE FROM user WHERE username = 'draven'
[idea]特别是针对 OLTP 这种场景,用户查询的条件可能是多种多样的,我们无法在大多数场景下使用哈希。
如果我们使用哈希作为底层的数据结构,遇到上述的场景时,使用哈希构成的主键索引或者辅助索引可能就没有办法快速处理了,它对于处理范围查询或者排序性能会非常差,只能进行全表扫描并依次判断是否满足条件。全表扫描对于数据库来说是一个非常糟糕的结果,这就意味着我们使用的数据结构对于这些查询没有其他任何效果,最终的性能可能都不如从日志中顺序进行匹配。
简言之,哈希不适用于「范围查询」和「排序」的场景。
使用 B+ 树能够保证数据按照键的顺序进行存储,也就是相邻的所有数据都是按照自然顺序排列的。使用哈希却无法达到这样的效果,因为哈希函数的目的就是让数据尽可能被分散到不同的桶中进行存储,所以在遇到可能存在相同键 username = 'alan' 或者排序以及范围查询 comments_count > 100 时,使用哈希作为底层数据结构的表可能就会面对数据库查询的噩梦 —— 「全表扫描」。
B 树和 B+ 树在数据结构上其实有一些类似,它们都可以按照某些顺序对索引中的内容进行遍历,对于排序和范围查询等操作,B 树和 B+ 树相比于哈希会带来更好的性能,当然如果索引建立不够好或者 SQL 查询非常复杂,依然会导致全表扫描。
与 B 树和 B+ 树相比:
- 哈希作为底层的数据结构的表能够以
O(1)的速度处理单行数据的增删改查,但是面对范围查询或者排序时就会导致全表扫描, - 而 B 树和 B+ 树虽然在单行数据的增删查改上需要
O(log n)的时间,但是它会将索引列相近的数据按顺序存储,所以能够避免全表扫描。
为什么不选择 B 树?
既然使用哈希无法应对我们常见的 SQL 中排序和范围查询等操作,而 B 树和 B 树和 B+ 树都可以相对高效地执行这些查询,那么为什么我们不选择 B 树呢?
这个原因其实非常简单 —— 计算机在读写文件时会以页为单位将数据加载到内存中。页的大小可能会根据操作系统的不同而发生变化,不过在大多数的操作系统中,页的大小都是 4KB,你可以通过如下的命令获取操作系统上的页大小:
$ getconf PAGE_SIZE
4096
笔者这里使用 macOS 系统,页大小为
4KB,在不同的计算机上得到不同的结果是有可能的。
当我们需要在数据库中查询数据时,CPU 会发现当前数据位于磁盘而不是内存中,这时就会触发 I/O 操作将数据加载到内存中进行访问,数据的加载都是以页的维度进行加载的,然而将数据从磁盘读取到内存中所需要的成本是非常大的,普通磁盘(非 SSD)加载数据需要经过队列、寻道、旋转以及传输的这些过程,大概要花费 10ms 左右的时间。
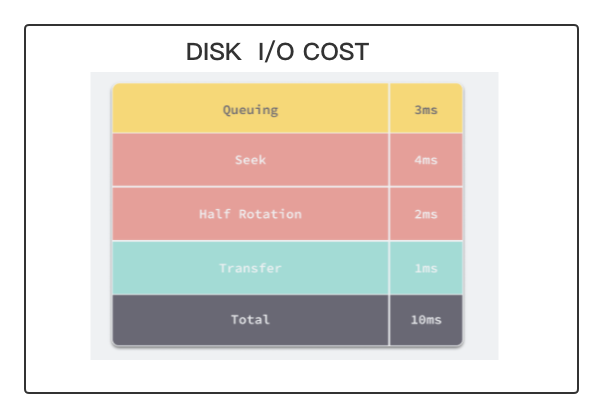
我们在估算 MySQL 的查询时就可以使用 10ms 这个数量级对随机 I/O 占用的时间进行估算。这里想要说明一下:是随机 I/O 对于 MySQL 的查询性能影响会非常大,而顺序读取磁盘中的数据时速度可以达到 40MB/s,这两者的性能差距有几个数量级,由此我们也应该尽量减少随机 I/O 的次数,这样才能提高性能。
B 树与 B+ 树的最大区别就是:B 树可以在非叶结点中存储数据,但是 B+ 树的所有数据都存储在叶子节点中。
假设当一个表底层的数据结构是 B 树时,假设我们需要访问所有大于 4,并且小于 9 的数据:
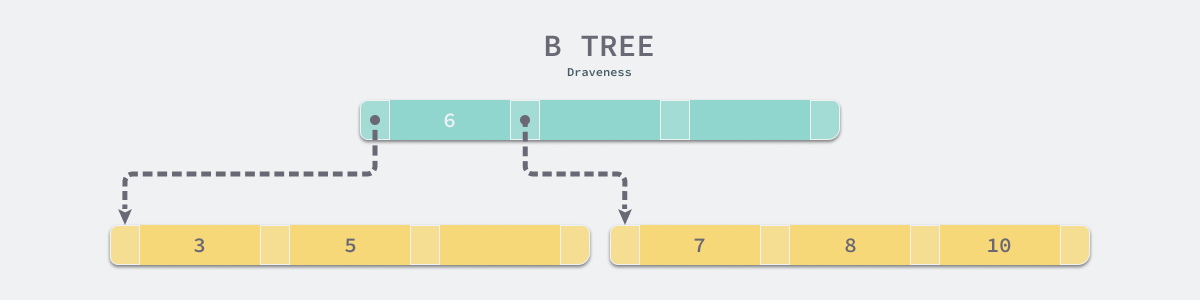
如果不考虑任何优化,在上面的简单 B 树中我们需要进行 4 次磁盘的随机 I/O 才能找到所有满足条件的数据行:
- 加载根节点所在的页,发现根节点的第一个元素是 6,大于 4;
- 通过根节点的指针加载左子节点所在的页,遍历页面中的数据,找到 5;
- 重新加载根节点所在的页,发现根节点不包含第二个元素;
- 通过根节点的指针加载右子节点所在的页,遍历页面中的数据,找到 7 和 8;
当然我们可以通过各种方式来对上述的过程进行优化,不过 B 树能做的优化 B+ 树基本都可以,所以我们不需要考虑优化 B 树而带来的收益,直接来看看什么样的优化 B+ 树可以做,而 B 树不行。
由于所有的节点都可能包含目标数据,我们总是要从根节点向下遍历子树查找满足条件的数据行,这个特点带来了大量的随机 I/O,也是 B 树最大的性能问题。
B+ 树中就不存在这个问题了,因为所有的数据行都存储在叶节点中,而这些叶节点可以通过指针依次按顺序连接,当我们在如下所示的 B+ 树遍历数据时可以直接在多个子节点之间进行跳转,这样能够节省大量的磁盘 I/O 时间,也不需要在不同层级的节点之间对数据进行拼接和排序;通过一个 B+ 树最左侧的叶子节点,我们可以像链表一样遍历整个树中的全部数据,我们也可以引入双向链表保证倒序遍历时的性能。
有些读者可能会认为使用 B+ 树这种数据结构会增加树的高度从而增加整体的耗时,然而高度为 3 的 B+ 树就能够存储千万级别的数据,实践中 B+ 树的高度最多也就 4 或者 5,所以这并不是影响性能的根本问题。
[idea]因此一个 B+ 树的高度不建议太深,否则性能将大大降低,所以一般到达一定数据量后(如上千万),我们就可以进行分库分表。
为什么不选择二叉树?
因为当插入数据时,如果是数据排好序的,二叉树会退化为链表,查询时间复杂度为 O(n)。这样就失去了索引的价值。
特别是自增主键(如常用的自增 id),默认会构建主键索引。
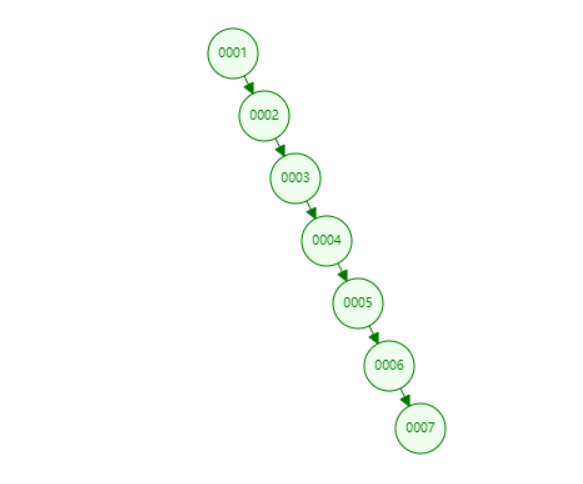
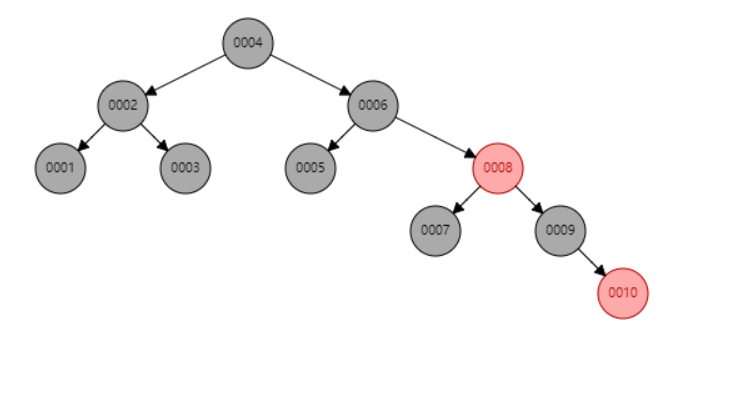
为什么不选择红黑树?
因为红黑树是弱平衡树,如果插入的数据是排好序的,则只会单边增长,查询效率不高。特别是自增数据量大时,高度非常大,增加 IO 消耗。
为什么选择 B+ Tree?
- 由于 mysql 通常将数据存储在磁盘中,读取数据就会产生磁盘 IO 消耗。而B+树的非叶子节点中不保存数据,B树中非叶子节点会保存数据,通常一个节点大小会设置为磁盘页大小,这样B+树每个节点可放更多的key,B树的key则更少。这样就造成了,B树的高度会比B+树更高,从而会产生更多的磁盘IO消耗。
- B+ 树叶子节点构成链表,更有利于范围查找和排序。而B树进行范围查找和排序则要对树进行递归遍历。
B+ Tree Vs B Tree
- B+树层级更少,查找更快
- B+树查询速度稳定:由于B+树所有数据都存储在叶子节点,所以查询任意数据的次数都是树的高度h
- B+树有利于范围查找和排序
- B+树全节点遍历更快:所有叶子节点构成链表,全节点扫描,只需遍历这个链表即可
- B 树优点:如果在B树中查找的数据离根节点近,由于B树节点中保存有数据,那么这时查询速度比B+树快[少数优点之一]
小结
任何不考虑应用场景的设计都不是最好的设计,当我们明确的定义了使用 MySQL 时的常见查询需求并理解场景之后,再对不同的数据结构进行选择就成了理所当然的事情,当然 B+ 树可能无法对所有 OLTP 场景下的查询都有着较好的性能,但是它能够解决大多数的问题。
因此 MySQL 默认的存储引擎选择 B+ 树而不是哈希或者 B 树的原因如下:
- 哈希虽然能够提供
O(1)的单行数据操作性能,但是对于范围查询和排序却无法很好地支持,最终导致全表扫描; - B 树能够在非叶节点中存储数据,但是这也导致在查询连续数据时可能会带来更多的随机 I/O,而 B+ 树的所有叶节点可以通过指针相互连接,能够减少顺序遍历时产生的额外随机 I/O;
如果想要追求各方面的极致性能也不是没有可能,只是会带来更高的复杂度,我们可以为一张表同时建 B+ 树和哈希构成的存储结构,这样不同类型的查询就可以选择相对更快的数据结构,但是会导致更新和删除时需要操作多份数据(这又会带来空间消耗变大,数据一致等问题)。
其实从今天的角度来看,B+ 树可能不是 InnoDB 的最优选择,但是它一定是能够满足当时设计场景的需要,从 B+ 树作为数据库底层的存储结构到今天已经过了几十年的时间,我们不得不说优秀的工程设计确实有足够的生命力。而我们作为工程师,在选择数据库时也应该非常清楚地知道不同数据库适合的场景,因为软件工程中没有银弹。
到最后,我们还是来看一些比较开放的相关问题,有兴趣的读者可以思考一下下面的问题:
- 常用于分析的 OLAP 数据库一般会使用什么样的数据结构存储数据?为什么?(提示:列式存储)
- Redis 是如何对数据进行持久化存储的?常见的数据结构都有什么?
Reference
- B+ tree · Wikipedia
- What is the difference between Mysql InnoDB B+ tree index and hash index? Why does MongoDB use B-tree?
- B+Trees and why I love them, part I
- What are the main differences between INNODB and MYISAM
- B+ Tree File Organization
- Database Index: A Re-visit to B+ Tree
- Fundamentals of database systems
- 为什么 MySQL 使用 B+ 树
- MySQL 为什么使用 B+ 树来作索引
- https://mp.weixin.qq.com/s/DK8zIueMiSsnkz9C77E10Q
MySQL 为什么使用 B+ 树来作索引?的更多相关文章
- 为什么MySQL要用B+树?聊聊B+树与硬盘的前世今生【宇哥带你玩转MySQL 索引篇(二)】
为什么MySQL要用B+树?聊聊B+树与硬盘的前世今生 在上一节,我们聊到数据库为了让我们的查询加速,通过索引方式对数据进行冗余并排序,这样我们在使用时就可以在排好序的数据里进行快速的二分查找,使得查 ...
- MySQL索引的原理,B+树、聚集索引和二级索引
MySQL索引的原理,B+树.聚集索引和二级索引的结构分析 一.索引类型 1.1 B树 1.2 B+树 1.3 哈希索引 1.4 聚集索引(clusterd index) 1.5 二级索引(secon ...
- mysql为什么用b+树做索引
关键字就是key的意思 一.B-Tree的性质 1.定义任意非叶子结点最多只有M个儿子,且M>2: 2.根结点的儿子数为[2, M]: 3.除根结点以外的非叶子结点的儿子数为[M/2, M]: ...
- B树在数据库索引中的应用剖析
引言 关于数据库索引,google一个oracle index,mysql index总 有大量的结果,其中很多的使用方法推荐,**索引之n条经典建议云云.笔者认为,较之借鉴,在搞清楚了自己的需求的基 ...
- 一步步分析为什么B+树适合作为索引的结构
在MySQL中,主要有四种类型的索引,分别为:B-Tree索引,Hash索引,Fulltext索引和R-Tree索引,本文讲的是B-Tree索引. 什么是索引 索引(Index)是帮助数据库高效获取数 ...
- 【Explain】mysql之explain详解(分析索引的最佳使用)
在日常工作中,我们会有时会开慢查询去记录一些执行时间比较久的SQL语句,找出这些SQL语句并不意味着完事了,些时我们常常用到explain 这个命令来查看一个这些SQL语句的执行计划,查看该SQL语句 ...
- MySQL实战 | 05 如何设计高性能的索引?
原文链接:MySQL | 05 如何设计高性能的索引? 上回我们主要研究了为什么使用索引,以及索引的数据结构.今天带你了解如何设计高性能的索引. 其中,有这么一个点,说的是 InnoDB 引擎中使用的 ...
- MySQL存储引擎MyISAM和InnoDB,索引结构优缺点
MySQL存储引擎MyISAM和InnoDB底层索引结构 深入理解MySQL索引底层数据结构与算法 (各种索引结构优缺点) Myisam和Innodb索引实现的不同(存储结构) 存储引擎作用于什么对象 ...
- 浅析MySQL中的Index Condition Pushdown (ICP 索引条件下推)和Multi-Range Read(MRR 索引多范围查找)查询优化
本文出处:http://www.cnblogs.com/wy123/p/7374078.html(保留出处并非什么原创作品权利,本人拙作还远远达不到,仅仅是为了链接到原文,因为后续对可能存在的一些错误 ...
随机推荐
- 从零搭建springboot服务02-内嵌持久层框架Mybatis
愿历尽千帆,归来仍是少年 内嵌持久层框架Mybatis 1.所需依赖 <!-- Mysql驱动包 --> <dependency> <groupId>mysql&l ...
- [Java] Spring 使用
背景 JavaEE 应用框架 基于IOC和AOP的结构J2EE系统的框架 IOC(反转控制):即创建对象由以前的程序员自己new 构造方法来调用,变成了交由Spring创建对象,是Spring的基础 ...
- fedora21 桌面用户自动登录lightdm.conf -20190520 方法
修改 /etc/lightdm/lightdm.conf 步骤:1解除注释#autologin-user=root 2等号 =后面是root或者普通用户的用户名 例如:root用户自动登录 autol ...
- 有没有一种组合字体,中文是宋体,英文是times new roman?
有没有一种组合字体,中文是宋体,英文是times new roman? 由于日常科研工作书写需要,想问问各位大神有没有一种字体,中文是宋体,西文是times new roman,这样写论文好方便啊有没 ...
- shell基础之变量及表达式
本节内容 1. shell变量简介 2. 定义变量 3. 使用变量 4. 修改变量的值 5. 单引号和双引号的区别 6. 将命令的结果赋值给变量 7. 删除变量 8. 变量类型 9. 特殊变量列表 1 ...
- 进程-信号相关 函数-(转自wblyuyang)
Linux 中的进程: 程序时一个预定义的指令序列,用来完成一个特定的任务. C 编译器可以把每个源文件翻译成一个目标文件,链接器将所有的目标文件与一些必要的库链接在一起,产生一个可执行文件.当程序被 ...
- 安装beanstalkd队列问题——No package beanstalkd available
CentOS7.4安装beanstalkd 时无可用源 No package beanstalkd availableError:Nothing to do 可从以下获取:wget /etc/yum. ...
- 大数据学习之路——环境配置(2)——mysql 在linux 系统上安装配置
1.安装参考网址: https://blog.csdn.net/IronWring_Fly/article/details/103637801 设置新秘密: mysqladmin -u root ...
- mysql数据库-运维合集
目录 RDBMS 术语 整删改查操作 库操作 表操作 账号与授权 匹配符(条件查询) MySQL三大类数据类型 函数 其他操作 查看数据库的占用空间大小 开启慢查询 状态查询 字符集设置 忘记密码重置 ...
- [leetcode] 38. 报数(Java)(字符串处理)
38. 报数 水题 class Solution { public String next(String num) { String ans = ""; int i = 0; wh ...