分布式全局ID生成器原理剖析及非常齐全开源方案应用示例
为何需要分布式ID生成器
**本人博客网站 **IT小神 www.itxiaoshen.com
**拿我们系统常用Mysql数据库来说,在之前的单体架构基本是单库结构,每个业务表的ID一般从1增,通过 **AUTO_INCREMENT=1设置自增起始值,随着系统(比如互联网电商、外卖)用户数据日渐增长,单库性能无法满足业务系统,在这之后我们会使用基于主从同步的读写分离,但当用户量规模连主从模式都无法应对时,我们会采用分库分表(当然现在还有其他解决方案比如分布式关系型数据库如TiDB)的方案,这样对数据分库分表后需要有一个唯一 ID 来标识一条数据或消息,数据库的自增 ID 显然不能满足需求,在复杂分布式系统中,往往还有很多场景需要对大量的数据和消息进行唯一标识,这就迫使我们需要用到分布式系统中全局ID生成器。
我们本篇文章只是介绍一些常用实现方案,而大部分的开源分布式ID生成器基本都是基于号段模式和雪花算法为基础,可以根据不同业务场景需要选择,不做详细说明
分布式ID满足要求
- 全局唯一:需要是唯一标识,不能出现重复的 ID 号,这是最基本的要求。
- 高性能:高QPS、低延迟、否则反倒会成为系统瓶颈
- 高可用性:可用性接近 5 个 9
- 信息安全:如果 ID 是连续的那对于恶意用户爬虫采用顺序爬取指定 URL爬取信息就非常容易完成;如果是作为订单号就更危险了,可以直接知道一天的单量,所以在一些应用场景下会需要 ID 无规则、不规则的要求
- 趋势递增:在 MySQL InnoDB 引擎中使用的是聚集索引,采用B+ Tree的数据结构来存储索引数据,在主键的选择上我们应该尽量使用有序的编号保证写入性能
- 单调递增:保证下一个 ID 一定大于上一个 ID,例如事务版本号、IM 增量消息、排序等特殊需求。
常用解决方案
UUID
全局ID在Java中们可以简单使用来UUID生成,输出的41c9b76fc5ac4265939cd5b27bdacdf1这种结果的字符串数据,可以看生成的是36位长度的16进制的字符串,然后将中划线-替换为空字符串**
public static void main(String[] args) {
String uuid = UUID.randomUUID().toString().replaceAll("-","");
System.out.println(uuid);
}
优点
- 优点UUID设计上固然是可以满足全局唯一的要求
缺点
- UUID太长且无序,在互联网大部分企业中都是使用Mysql数据库,且有些业务场景需要使用到事务因此底层存储引擎采用的是Innodb,这就导致B+ Tree索引的分裂,存储和索引的性能差,并不适合在Innodb作为主键,自增ID比较适合作为Innodb主键
数据库自增ID
这样方式就是单独使用一个数据库来生成ID,业务程序通过这个数据库获取ID,表结构可以简单设计如下,--然后再通过事务通过插入等操作数据触发ID自增,这个数据库层级性能比较高,你也可以采用表级别插入返回数据的主键
CREATE DATABASE `SEQ_ID`;
CREATE TABLE SEQID.SEQUENCE_ID (
id bigint(20) unsigned NOT NULL auto_increment,
id_value char(10) NOT NULL default '',
PRIMARY KEY (id),
UNIQUE KEY id_value(id_value)
) ENGINE=MyISAM;
begin
replace into SEQUENCE_ID(id_value) values('xxx');
SELECT LAST_INSERT_ID();
commit;
end
优点
- 简单、ID自增
缺点
- DB单点故障
- Mysql并发不好,无法抗住高并发
数据库集群模式
上面单个数据库有弊端,那么可以采用数据库集群,数据库集群常用主从和主主,我们使用主主模式,每个数据库通过设置不同起始值和相同自增步长来实现,比如三台mysql主主模式,mysql1从1开始自增步长为3,序号1、4、7...,mysql2从2开始自增步长为3,序号2、5、8...,mysql3从3开始自增步长为3,序号3、6、9....,每个业务系统可以通过这三台中获取到ID
set @@auto_increment_offset = 1; -- mysql1起始值
set @@auto_increment_increment = 3; -- mysql1自增步长
set @@auto_increment_offset = 2; -- mysql2起始值
set @@auto_increment_increment = 3; -- mysql2自增步长
set @@auto_increment_offset = 3; -- mysql3起始值
set @@auto_increment_increment = 3; -- mysql3自增步长
优点
- 解决DB单点问题
缺点
- 不利于扩容,如果需要进行MySQL扩容增加节点还是比较麻烦,可能还需要停机扩容
号段模式
号段模式几乎是目前所有开源分布式ID生成器的主流实现方式之一,号段模式比如每次从数据库取出一个号段范围,例如 (1,1000] 代表1000个ID,具体的业务服务将本号段,生成1~1000的自增ID并加载到内存,不强依赖于数据库,不会频繁的访问数据库,对数据库的压力小很多。简易版本的表结构如下:
CREATE TABLE id_generator (
id int(10) NOT NULL,
max_id bigint(20) NOT NULL COMMENT '当前最大id',
step int(20) NOT NULL COMMENT '号段的步长',
biz_type int(20) NOT NULL COMMENT '业务类型',
version int(20) NOT NULL COMMENT '版本号',
PRIMARY KEY (`id`)
)
biz_type :代表不同业务类型
max_id :当前最大的可用id
step :代表号段的长度
version :是一个乐观锁,每次都更新version,保证并发时数据的正确性
每次申请一个号段,通过乐观锁的机制对 max_id字段做一次 update操作,update成功则说明新号段获取成功,新的号段范围是 (max_id ,max_id +step]
update id_generator set max_id = #{max_id+step}, version = version + 1 where version = # {version} and biz_type = XXX
Redis实现
Redis也同样可以实现,原理就是利用 redis**的 **incr命令实现ID的原子性自增,redis持久化也支持基于每条命令持久化方式,且redis自身有高可用集群模式
192.168.3.117:6379> set seq_id 1 // 初始化自增ID为1
OK
192.168.3.117:6379> incr seq_id // 增加1,并返回递增后的数值
(integer) 2
雪花算法(SnowFlake)
雪花算法(Snowflake)是twitter公司内部分布式项目采用的ID生成算法,开源后广受国内大厂的好评,在该算法影响下各大公司相继开发出各具特色的分布式生成器。SnowFlake算法用来生成64位的ID,刚好可以用long整型存储,能够用于分布式系统中生产唯一的ID, 并且生成的ID有序
Snowflake生成的是Long类型的ID,一个Long类型占8个字节,每个字节占8比特,也就是说一个Long类型占64个比特。
Snowflake ID组成结构:正数位(占1比特)+ 时间戳(占41比特)+ 机器ID(占5比特)+ 数据中心(占5比特)+ 自增值(占12比特),总共64比特组成的一个Long类型。
- 第一个bit位(1bit):Java中long的最高位是符号位代表正负,正数是0,负数是1,一般生成ID都为正数,所以默认为0。
- 时间戳部分(41bit):毫秒级的时间,不建议存当前时间戳,而是用(当前时间戳 - 固定开始时间戳)的差值,可以使产生的ID从更小的值开始;41位的时间戳可以使用69年,(1L << 41) / (1000L * 60 * 60 * 24 * 365) = 69年
- 工作机器id(10bit):也被叫做
workId,这个可以灵活配置,机房或者机器号组合都可以。 - 序列号部分(12bit),自增值支持同一毫秒内同一个节点可以生成4096个ID
雪花算法比较依赖于时间,会出现时钟回拨的问题,所以尽量保证时间同步,大部分开源分布式ID生成器大都有优化解决时钟回拨的问题
下面是基于Twitter的雪花算法SnowFlake,使用Java语言实现,封装成工具方法,各个业务应用可以直接使用该工具方法来获取分布式ID,只需保证每个业务应用有自己的工作机器id即可,而不需要单独去搭建一个获取分布式ID的应用
0 - 41位时间戳 - 5位数据中心标识 - 5位机器标识 - 12位序列号
5位数据中心标识跟5位机器标识这样的分配仅仅是当前实现中分配的,如果业务有其实的需要,可以按其它的分配比例分配,如10位机器标识,不需要数据中心标识。
/**
* twitter的snowflake算法 -- java实现
*
* @author beyond
* @date 2016/11/26
*/
public class SnowFlake {
/**
* 起始的时间戳
*/
private final static long START_STMP = 1480166465631L;
/**
* 每一部分占用的位数
*/
private final static long SEQUENCE_BIT = 12; //序列号占用的位数
private final static long MACHINE_BIT = 5; //机器标识占用的位数
private final static long DATACENTER_BIT = 5;//数据中心占用的位数
/**
* 每一部分的最大值
*/
private final static long MAX_DATACENTER_NUM = -1L ^ (-1L << DATACENTER_BIT);
private final static long MAX_MACHINE_NUM = -1L ^ (-1L << MACHINE_BIT);
private final static long MAX_SEQUENCE = -1L ^ (-1L << SEQUENCE_BIT);
/**
* 每一部分向左的位移
*/
private final static long MACHINE_LEFT = SEQUENCE_BIT;
private final static long DATACENTER_LEFT = SEQUENCE_BIT + MACHINE_BIT;
private final static long TIMESTMP_LEFT = DATACENTER_LEFT + DATACENTER_BIT;
private long datacenterId; //数据中心
private long machineId; //机器标识
private long sequence = 0L; //序列号
private long lastStmp = -1L;//上一次时间戳
public SnowFlake(long datacenterId, long machineId) {
if (datacenterId > MAX_DATACENTER_NUM || datacenterId < 0) {
throw new IllegalArgumentException("datacenterId can't be greater than MAX_DATACENTER_NUM or less than 0");
}
if (machineId > MAX_MACHINE_NUM || machineId < 0) {
throw new IllegalArgumentException("machineId can't be greater than MAX_MACHINE_NUM or less than 0");
}
this.datacenterId = datacenterId;
this.machineId = machineId;
}
/**
* 产生下一个ID
*
* @return
*/
public synchronized long nextId() {
long currStmp = getNewstmp();
if (currStmp < lastStmp) {
throw new RuntimeException("Clock moved backwards. Refusing to generate id");
}
if (currStmp == lastStmp) {
//相同毫秒内,序列号自增
sequence = (sequence + 1) & MAX_SEQUENCE;
//同一毫秒的序列数已经达到最大
if (sequence == 0L) {
currStmp = getNextMill();
}
} else {
//不同毫秒内,序列号置为0
sequence = 0L;
}
lastStmp = currStmp;
return (currStmp - START_STMP) << TIMESTMP_LEFT //时间戳部分
| datacenterId << DATACENTER_LEFT //数据中心部分
| machineId << MACHINE_LEFT //机器标识部分
| sequence; //序列号部分
}
private long getNextMill() {
long mill = getNewstmp();
while (mill <= lastStmp) {
mill = getNewstmp();
}
return mill;
}
private long getNewstmp() {
return System.currentTimeMillis();
}
public static void main(String[] args) {
SnowFlake snowFlake = new SnowFlake(2, 3);
for (int i = 0; i < (1 << 12); i++) {
System.out.println(snowFlake.nextId());
}
}
}
百度 (Uidgenerator)
概述
官方GitHub地址** **https://github.com/baidu/uid-generator
UidGenerator是Java实现的, 基于Snowflake算法的唯一ID生成器。UidGenerator以组件形式工作在应用项目中, 支持自定义workerId位数和初始化策略, 从而适用于docker等虚拟化环境下实例自动重启、漂移等场景。 在实现上, UidGenerator通过借用未来时间来解决sequence天然存在的并发限制; 采用RingBuffer来缓存已生成的UID, 并行化UID的生产和消费, 同时对CacheLine补齐,避免了由RingBuffer带来的硬件级「伪共享」问题. 最终单机QPS可达600万。
依赖版本:Java8及以上版本, MySQL(内置WorkerID分配器, 启动阶段通过DB进行分配; 如自定义实现, 则DB非必选依赖)
[](https://github.com/baidu/uid-generator/blob/master/doc/snowflake.png)
{kind=link}
Snowflake算法描述:指定机器 & 同一时刻 & 某一并发序列,是唯一的。据此可生成一个64 bits的唯一ID(long)。默认采用上图字节分配方式:
- sign(1bit)****固定1bit符号标识,即生成的UID为正数。
- delta seconds (28 bits)****当前时间,相对于时间基点"2016-05-20"的增量值,单位:秒,而不是毫秒,最多可支持约8.7年
- worker id (22 bits)****机器id,最多可支持约420w次机器启动。内置实现为在启动时由数据库分配,默认分配策略为用后即弃,后续可提供复用策略,同一应用每次重启就会消费一个workId
- sequence (13 bits)**
**每秒下的并发序列,13 bits可支持每秒8192个并发。
UidGenerator是基于 Snowflake算法实现的,与原始的 snowflake算法不同在于,UidGenerator支持自 定义时间戳、工作机器ID和 序列号 等各部分的位数,而且 UidGenerator中采用用户自定义 workId的生成策略。
UidGenerator需要与数据库配合使用,需要新增一个 WORKER_NODE表。当应用启动时会向数据库表中去插入一条数据,插入成功后返回的自增ID就是该机器的 workId数据由host,port组成。
提供了两种生成器: DefaultUidGenerator、CachedUidGenerator,如对UID生成性能有要求则使用CachedUidGenerator。
CachedUidGenerator
RingBuffer环形数组,数组每个元素成为一个slot。RingBuffer容量,默认为Snowflake算法中sequence最大值,且为2^N。可通过 boostPower配置进行扩容,以提高RingBuffer 读写吞吐量。
Tail指针、Cursor指针用于环形数组上读写slot:
- Tail指针****表示Producer生产的最大序号(此序号从0开始,持续递增)。Tail不能超过Cursor,即生产者不能覆盖未消费的slot。当Tail已赶上curosr,此时可通过
rejectedPutBufferHandler指定PutRejectPolicy - Cursor指针**
**表示Consumer消费到的最小序号(序号序列与Producer序列相同)。Cursor不能超过Tail,即不能消费未生产的slot。当Cursor已赶上tail,此时可通过rejectedTakeBufferHandler指定TakeRejectPolicy
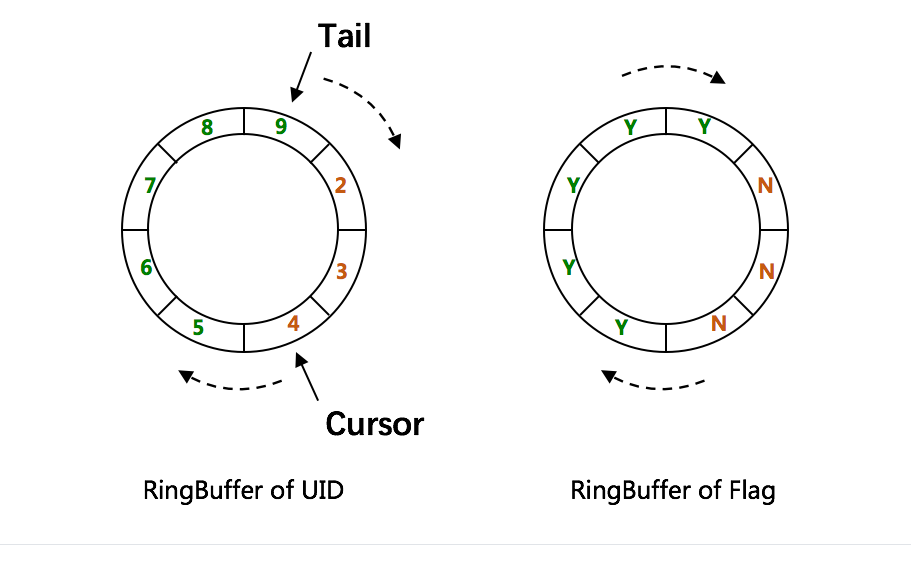
CachedUidGenerator采用了双RingBuffer,Uid-RingBuffer用于存储Uid、Flag-RingBuffer用于存储Uid状态(是否可填充、是否可消费)
由于数组元素在内存中是连续分配的,可最大程度利用CPU cache以提升性能。但同时会带来「伪共享」FalseSharing问题,为此在Tail、Cursor指针、Flag-RingBuffer中采用了CacheLine 补齐方式。
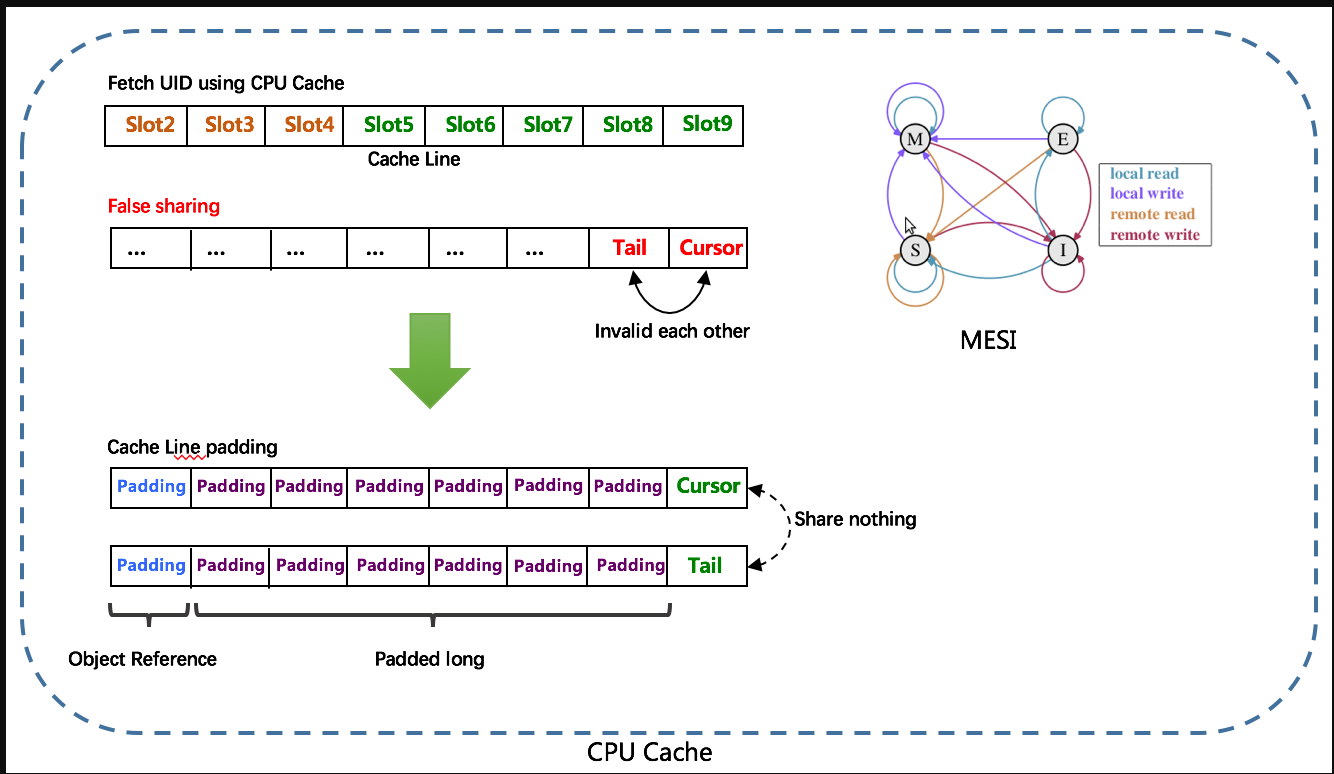
RingBuffer填充时机
- 初始化预填充****RingBuffer初始化时,预先填充满整个RingBuffer.
- 即时填充****Take消费时,即时检查剩余可用slot量(
tail** -cursor),如小于设定阈值,则补全空闲slots。阈值可通过paddingFactor来进行配置,请参考Quick Start中CachedUidGenerator配置** - 周期填充**
**通过Schedule线程,定时补全空闲slots。可通过scheduleInterval配置,以应用定时填充功能,并指定Schedule时间间隔
简单使用
官方源码导入idea
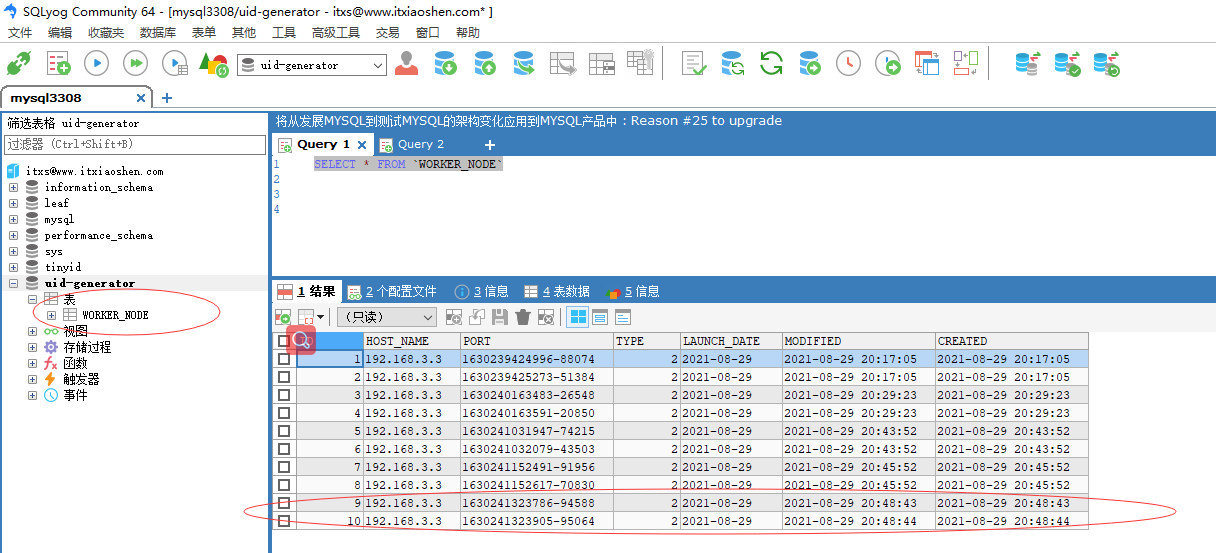
建立数据库和导入表WORKER_NODE.sql
创建一个SpringBoot启动类,在application-dev.yml文件配置数据库信息,启动类配置Mybatis扫描com.baidu.fsg.uid的mapper文件注解,创建一个UidControoler提供一个获取单个uid的接口,启动SpringBoot程序

访问提供接口地址:http://localhost:8080/uid/snowflake** ,返回uid结果,每次刷新+1**

数据库表WORKER_NODE当我们每次启动程序会重新生成新的记录
美团(Leaf)
概述
官方GitHub地址** **https://github.com/Meituan-Dianping/Leaf
There are no two identical leaves in the world. 世界上没有两片完全相同的树叶。
— 莱布尼茨
Leaf 最早期需求是各个业务线的订单ID生成需求。在美团早期,有的业务直接通过DB自增的方式生成ID,有的业务通过redis缓存来生成ID,也有的业务直接用UUID这种方式来生成ID。以上的方式各自有各自的问题,因此我们决定实现一套分布式ID生成服务来满足需求。
目前Leaf覆盖了美团点评公司内部金融、餐饮、外卖、酒店旅游、猫眼电影等众多业务线。在4C8G VM基础上,通过公司RPC方式调用,QPS压测结果近5w/s,TP999 1ms
当然,为了追求更高的性能,需要通过RPC Server来部署Leaf 服务,那仅需要引入leaf-core的包,把生成ID的API封装到指定的RPC框架中即可。
Leaf Server 是一个spring boot的程序,提供HTTP服务来获取ID。
Leaf 提供两种生成的ID的方式(号段模式和snowflake模式),你可以同时开启两种方式,也可以指定开启某种方式(默认两种方式为关闭状态)
配置
Leaf Server的配置都在leaf-server/src/main/resources/leaf.properties中
| 配置项 | 含义 | 默认值 |
|---|---|---|
| leaf.name | leaf 服务名 | |
| leaf.segment.enable | 是否开启号段模式 | false |
| leaf.jdbc.url | mysql 库地址 | |
| leaf.jdbc.username | mysql 用户名 | |
| leaf.jdbc.password | mysql 密码 | |
| leaf.snowflake.enable | 是否开启snowflake模式 | false |
| leaf.snowflake.zk.address | snowflake模式下的zk地址 | |
| leaf.snowflake.port | snowflake模式下的服务注册端口 |
- 号段模式
- 如果使用号段模式,需要建立DB表,并配置leaf.jdbc.url, leaf.jdbc.username, leaf.jdbc.password
- 如果不想使用该模式配置leaf.segment.enable=false即可。
- Snowflake模式
- 算法取自twitter开源的snowflake算法。
- 如果不想使用该模式配置leaf.snowflake.enable=false即可。
- 配置zookeeper地址
- 在leaf.properties中配置leaf.snowflake.zk.address,配置leaf 服务监听的端口leaf.snowflake.port。
简单使用
- 创建数据库,通过源码根目录下的scripts的leaf_alloc.sql导入数据库表leaf_alloc
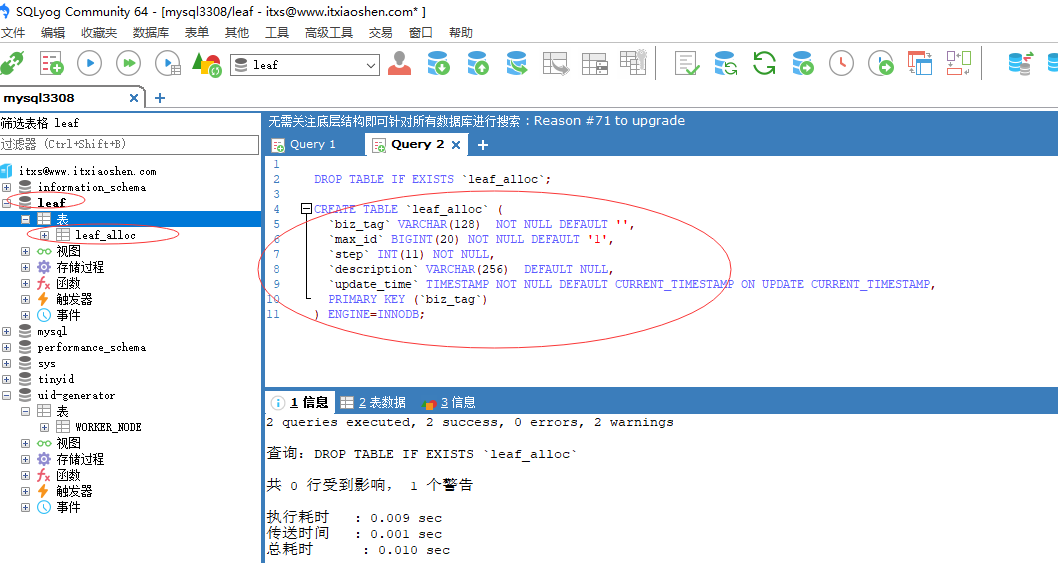
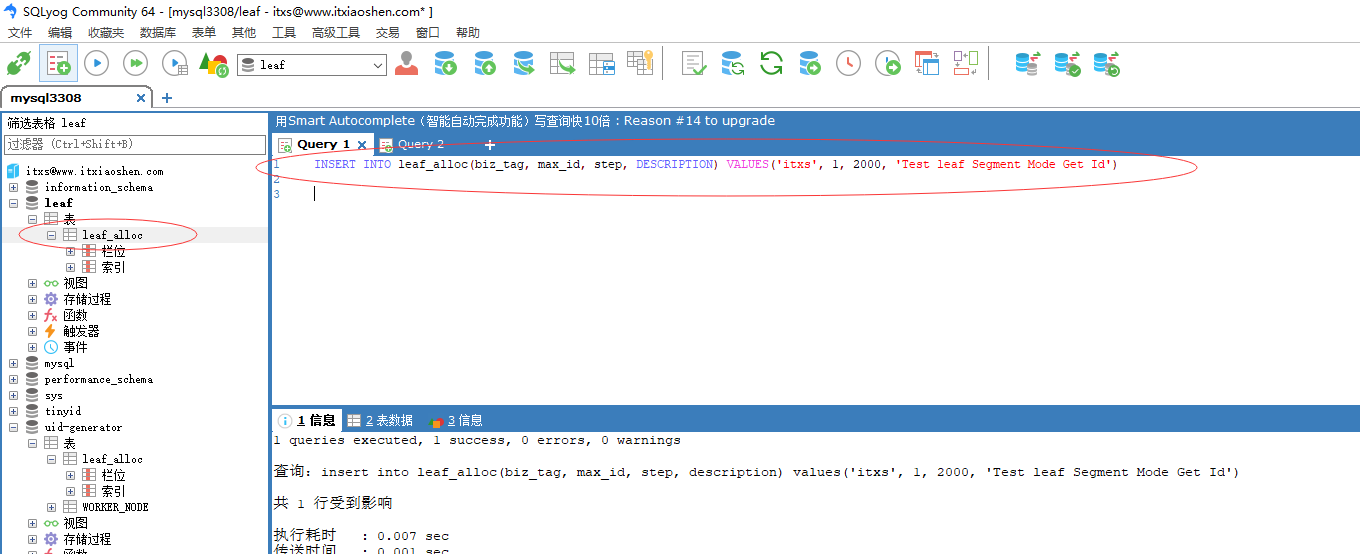
- 初始化数据,设置步长为2000,每次重启重新获取为下一个号段起始值
INSERT INTO leaf_alloc(biz_tag, max_id, step, DESCRIPTION) VALUES('itxs', 1, 2000, 'Test leaf Segment Mode Get Id')
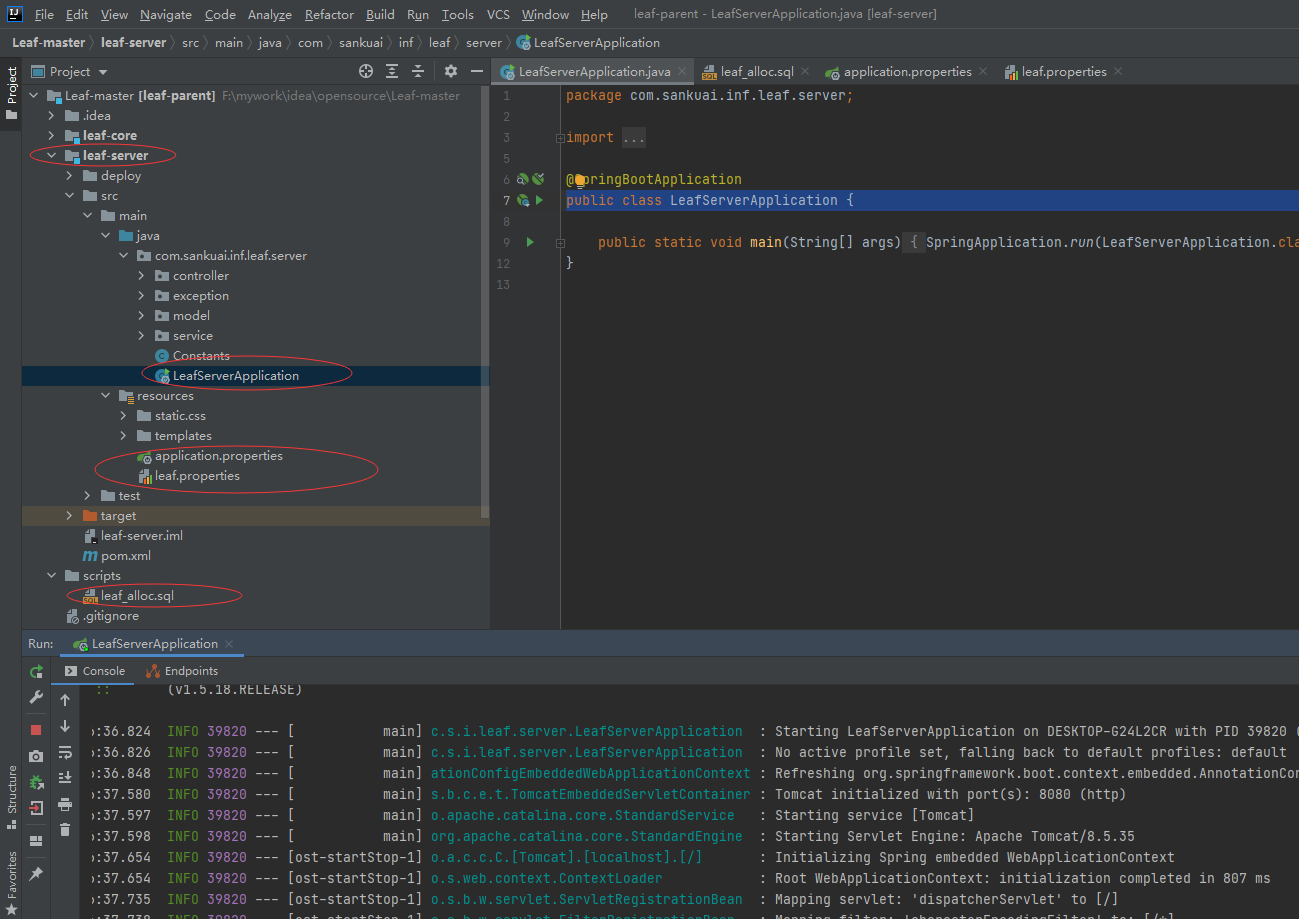
配置application.properties中的数据库信息,将leaf.segment.enable设置为true或者注释;配置zookeeper信息,leaf.snowflake.enable设置为true或者注释;启动leaf-server Spring Boot启动类
访问号段模式http接口地址:http://localhost:8080/api/segment/get/itxs

访问雪花算法的http接口地址:http://localhost:8080/api/snowflake/get/test

访问监控页面地址:http://localhost:8080/cache

我们再使用上一小节的工程项目先简单通过将leaf的core模块源码工程引入,使用号段模式,通过@Autowired SegmentIDGenImpl主动注入leaf号段模式实现类,并完成http getSegment测试接口的controller
package com.itxs.uiddemo.controller;
import javax.annotation.Resource;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.PathVariable;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import com.baidu.fsg.uid.UidGenerator;
import com.sankuai.inf.leaf.Result;
import com.sankuai.inf.leaf.segment.SegmentIDGenImpl;
@RestController
@RequestMapping(value="/uid")
public class UidController {
@Resource(name = "cachedUidGenerator")
private UidGenerator cachedUidGenerator;
@Autowired
private SegmentIDGenImpl idGen;
@GetMapping("/snowflake")
public String snowflake() {
return String.valueOf(this.cachedUidGenerator.getUID());
}
@GetMapping(value = "/segment/{key}")
public Result<Long> getSegment(@PathVariable("key") String key) throws Exception {
return this.idGen.get(key);
}
}
启动Spring Boot程序,访问http://localhost:8080/uid/segment/itxs,返回data字段就是uid值,每次刷新+1

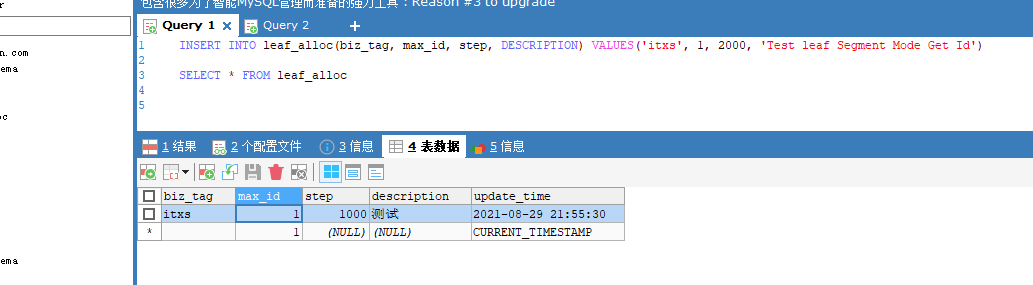
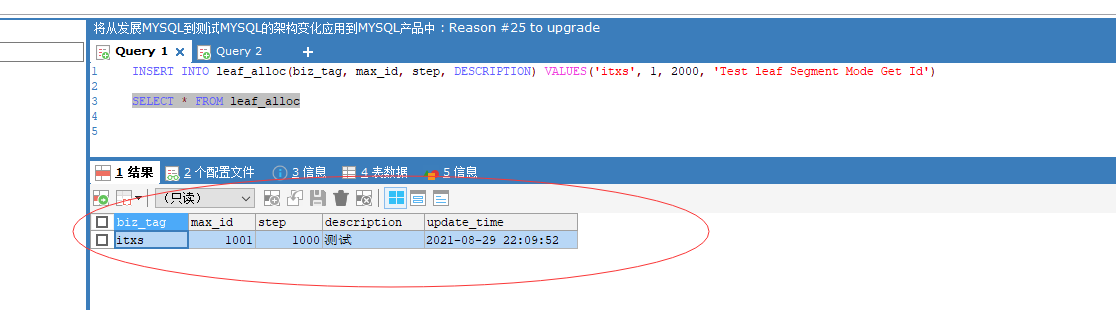
重新启动后,再次访问http://localhost:8080/uid/segment/itxs,返回data字段1001,也即是新的号段的起始值,数据库的maxid也变为1001

当然也可以采用Spring Boot Startser方式使用,官网也有相关的说明
我们自己下载leaf-starter 整合Spring Boot 制作启动器starter源码进行编译
编译好leaf-boot-starter后我们新建一个Spring Boot demo工程,由于原来封装是基于Spring Boot早期的版本,高版本不兼容,所以用早期版本,由于leaf-boot-starter里面使用zookeeper的客户端curator,我们直接运行是出现curator的某些类找不到,因此我们简单就直接在工程加入curator-framework和curator-recipes的依赖。
pom文件
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.itxs</groupId>
<artifactId>leaf-spring-boot-demo</artifactId>
<version>1.0-SNAPSHOT</version>
<parent>
<artifactId>spring-boot-starter-parent</artifactId>
<groupId>org.springframework.boot</groupId>
<version>2.0.3.RELEASE</version>
</parent>
<properties>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>com.sankuai.inf.leaf</groupId>
<artifactId>leaf-boot-starter</artifactId>
<version>1.0.1-RELEASE</version>
</dependency>
<dependency>
<groupId>org.apache.curator</groupId>
<artifactId>curator-framework</artifactId>
<version>5.2.0</version>
</dependency>
<dependency>
<groupId>org.apache.curator</groupId>
<artifactId>curator-recipes</artifactId>
<version>5.2.0</version>
</dependency>
</dependencies>
</project>
在class path也即是resource根目录下新建leaf.properties文件,同时开启号段模式和雪花算法,配置信息如下
leaf.name=com.sankuai.leaf.opensource.test
leaf.segment.enable=true
leaf.segment.url=jdbc:mysql://192.168.3.117:3306/leaf?autoReconnect=true&useUnicode=true&characterEncoding=UTF-8
leaf.segment.username=leaf
leaf.segment.password=leaf123
leaf.snowflake.enable=true
leaf.snowflake.address=192.168.3.117
leaf.snowflake.port=2181
新建一个controller用于测试,提供号段和雪花算法测试接口
package com.itxs.controller;
import com.sankuai.inf.leaf.common.Result;
import com.sankuai.inf.leaf.service.SegmentService;
import com.sankuai.inf.leaf.service.SnowflakeService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.PathVariable;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
@RestController
@RequestMapping(value="/uid")
public class LeafUidController {
@Autowired
private SegmentService segmentService;
@Autowired
private SnowflakeService snowflakeService;
@GetMapping("/snowflake")
public String snowflake() {
return String.valueOf(this.snowflakeService.getId("test"));
}
@GetMapping(value = "/segment/{key}")
public Result getSegment(@PathVariable("key") String key) throws Exception {
return this.segmentService.getId(key);
}
}
新建Spring Boot启动类,在启动类上标注@EnableLeafServer开启LeafServer的注解,启动Spring Boot程序,默认是使用8080端口
package com.itxs;
import com.sankuai.inf.leaf.plugin.annotation.EnableLeafServer;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
@SpringBootApplication
@EnableLeafServer
public class LeafApplication {
public static void main(String[] args) {
SpringApplication.run(LeafApplication.class,args);
}
}
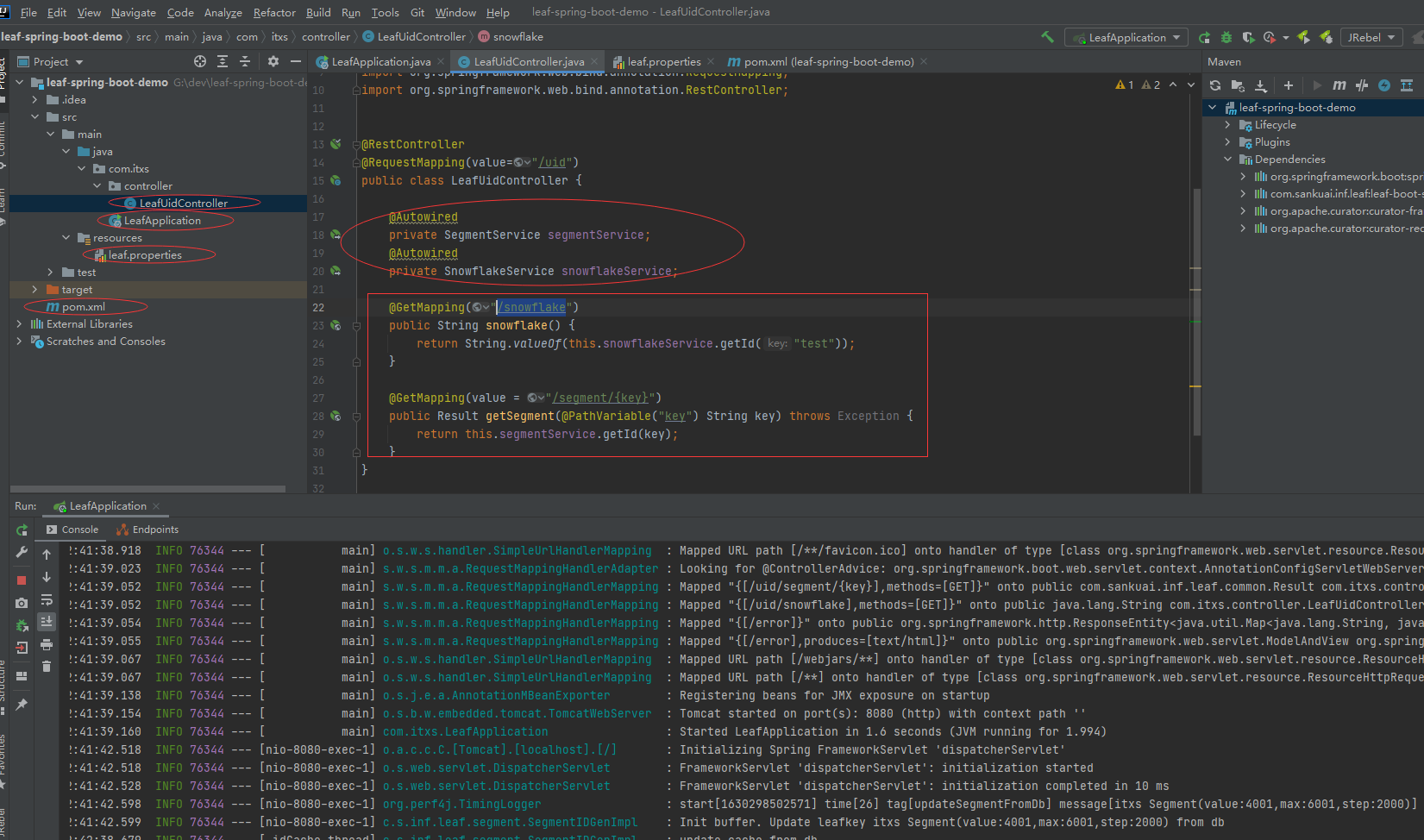
访问号段uid获取接口:http://localhost:8080/uid/segment/itxs,放回id结果如下

访问雪花算法uid获取接口:http://localhost:8080/uid/snowflake,返回id结果如下

滴滴(TinyID)
概述
官方GitHub地址** **https://github.com/didi/tinyid/
Tinyid是用Java开发的一款分布式id生成系统,基于数据库号段算法实现,关于这个算法可以参考美团leaf或者tinyid原理介绍。Tinyid扩展了leaf-segment算法,支持了多db(master),同时提供了java-client(sdk)使id生成本地化,获得了更好的性能与可用性。Tinyid在滴滴客服部门使用,均通过tinyid-client方式接入,每天生成亿级别的id。
- 性能
- http方式访问,性能取决于http server的能力,网络传输速度
- java-client方式,id为本地生成,号段长度(step)越长,qps越大,如果将号段设置足够大,则qps可达1000w+
- 可用性
- 依赖db,当db不可用时,因为server有缓存,所以还可以使用一段时间,如果配置了多个db,则只要有1个db存活,则服务可用
- 使用tiny-client,只要server有一台存活,则理论上可用,server全挂,因为client有缓存,也可以继续使用一段时间
- 特性
- 全局唯一的long型id
- 趋势递增的id,即不保证下一个id一定比上一个大
- 非连续性
- 提供http和java client方式接入
- 支持批量获取id
- 支持生成1,3,5,7,9...序列的id
- 支持多个db的配置,无单点
适用场景:只关心id是数字,趋势递增的系统,可以容忍id不连续,有浪费的场景**
**不适用场景:类似订单id的业务(因为生成的id大部分是连续的,容易被扫库、或者测算出订单量)
推荐使用方式
- tinyid-server推荐部署到多个机房的多台机器
- 多机房部署可用性更高,http方式访问需使用方考虑延迟问题
- 推荐使用tinyid-client来获取id,好处如下:
- id为本地生成(调用AtomicLong.addAndGet方法),性能大大增加
- client对server访问变的低频,减轻了server的压力
- 因为低频,即便client使用方和server不在一个机房,也无须担心延迟
- 即便所有server挂掉,因为client预加载了号段,依然可以继续使用一段时间 注:使用tinyid-client方式,如果client机器较多频繁重启,可能会浪费较多的id,这时可以考虑使用http方式
- 推荐db配置两个或更多:
- db配置多个时,只要有1个db存活,则服务可用 多db配置,如配置了两个db,则每次新增业务需在两个db中都写入相关数据
原理和架构
- tinyid是基于数据库发号算法实现的,简单来说是数据库中保存了可用的id号段,tinyid会将可用号段加载到内存中,之后生成id会直接内存中产生。
- 可用号段在第一次获取id时加载,如当前号段使用达到一定量时,会异步加载下一可用号段,保证内存中始终有可用号段。
- (如可用号段1-1000被加载到内存,则获取id时,会从1开始递增获取,当使用到一定百分比时,如20%(默认),即200时,会异步加载下一可用号段到内存,假设新加载的号段是1001-2000,则此时内存中可用号段为200-1000,1001~2000),当id递增到1000时,当前号段使用完毕,下一号段会替换为当前号段。依次类推。

- nextId和getNextSegmentId是tinyid-server对外提供的两个http接口
- nextId是获取下一个id,当调用nextId时,会传入bizType,每个bizType的id数据是隔离的,生成id会使用该bizType类型生成的IdGenerator。
- getNextSegmentId是获取下一个可用号段,tinyid-client会通过此接口来获取可用号段
- IdGenerator是id生成的接口
- IdGeneratorFactory是生产具体IdGenerator的工厂,每个biz_type生成一个IdGenerator实例。通过工厂,我们可以随时在db中新增biz_type,而不用重启服务
- IdGeneratorFactory实际上有两个子类IdGeneratorFactoryServer和IdGeneratorFactoryClient,区别在于,getNextSegmentId的不同,一个是DbGet,一个是HttpGet
- CachedIdGenerator则是具体的id生成器对象,持有currentSegmentId和nextSegmentId对象,负责nextId的核心流程。nextId最终通过AtomicLong.andAndGet(delta)方法产生。
简单使用
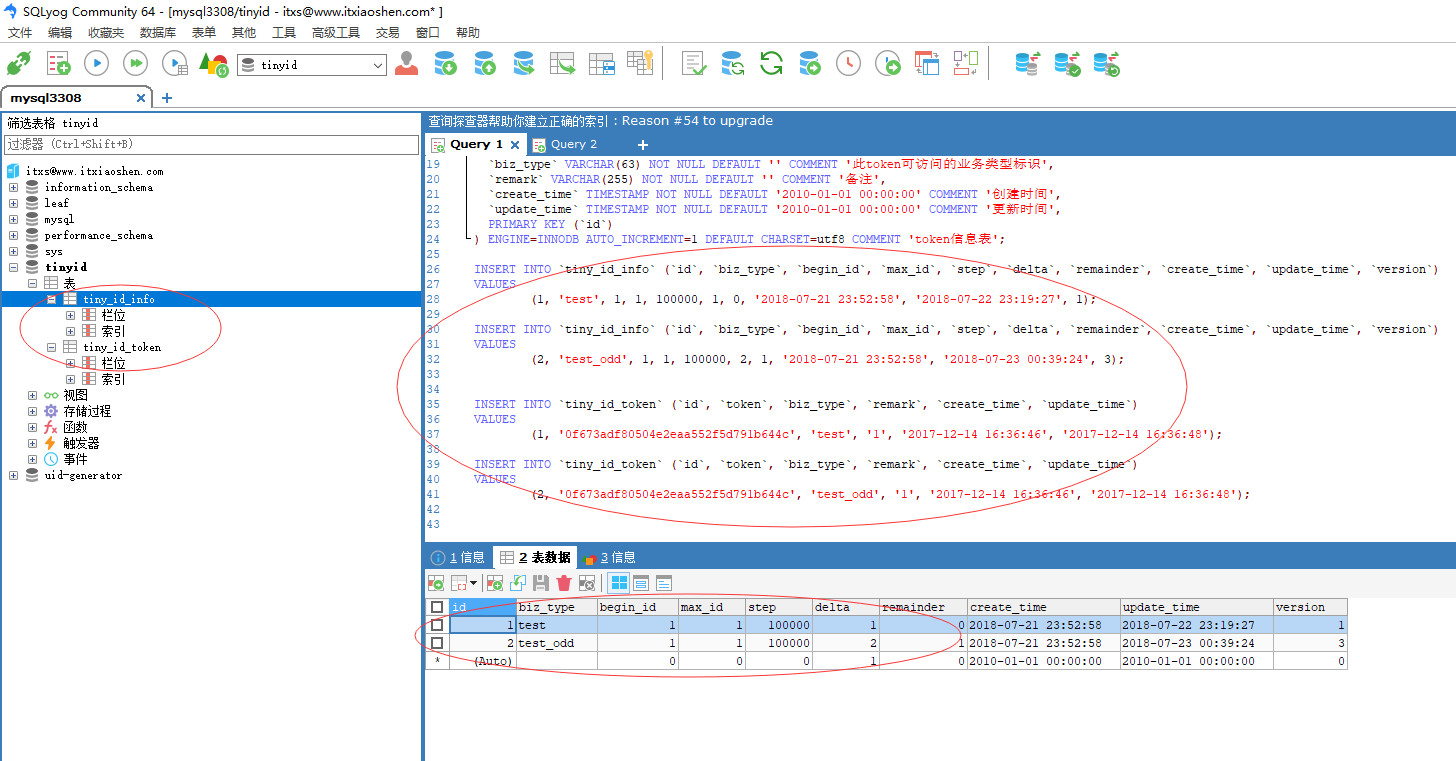
- 创建表
- 导入源码根目录下面tinyid/tinyid-server/db.sql的数据库脚本,两张表一张存储每个业务类型的token授权信息,一张存储业务类型ID的号段模式起始值和步长,通过version也即是数据库乐观锁实现原子操作。
cd tinyid/tinyid-server/ && create table with db.sql (mysql)
- 配置db
cd tinyid-server/src/main/resources/offline
vi application.properties
datasource.tinyid.names=primary
datasource.tinyid.primary.driver-class-name=com.mysql.jdbc.Driver
datasource.tinyid.primary.url=jdbc:mysql://ip:port/databaseName?autoReconnect=true&useUnicode=true&characterEncoding=UTF-8
datasource.tinyid.primary.username=root
datasource.tinyid.primary.password=123456
- 启动tinyid-server
- 将源码放在一个linux主机上,当然得有Jdk和Maven环境,在tinyid-server目录下执行脚本编译并启动编译好的jar包.并启动tinyid-server程序
cd tinyid-server/
sh build.sh offline
java -jar output/tinyid-server-xxx.jar
或者将tinyid源码导入idea中,同样配置db,然后启动tinyid-server
通过初始化sql脚本中的授权码和biz_type,访问本地的RestApi接口测试,结果如下



接下来我们使用基于java客户端的方式,这也是官方推荐的,性能最好,我们这里就直接使用客户端源码工程的测试代码
- 导入Maven dependency
<dependency>
<groupId>com.xiaoju.uemc.tinyid</groupId>
<artifactId>tinyid-client</artifactId>
<version>${tinyid.version}</version>
</dependency>
- 配置客户端信息tinyid_client.properties
tinyid.server=localhost:9999
tinyid.token=0f673adf80504e2eaa552f5d791b644c
#(tinyid.server=localhost:9999/gateway,ip2:port2/prefix,...)
- 编写代码,test为业务类型
Long id = TinyId.nextId("test");
List<Long> ids = TinyId.nextId("test", 10);

我们再看数据库表的信息,发现max_id已经变为200001,也即是每个客户端通过步长申请号段放在内存中,然后更新数据库表为下一次申请id段的起始值

看到这里,以后如果遇到需要使用分布式ID的场景,你会选择和使用了吗?
分布式全局ID生成器原理剖析及非常齐全开源方案应用示例的更多相关文章
- 分布式全局ID生成器设计
项目是分布式的架构,需要设计一款分布式全局ID,参照了多种方案,博主最后基于snowflake的算法设计了一款自用ID生成器.具有以下优势: 保证分布式场景下生成的ID是全局唯一的 生成的全局ID整体 ...
- 分布式唯一id生成器的想法
0x01 起因 前端时间遇到一个问题,怎么快速生成唯一的id,后来采用了hashid的方法.最近在网上读到了美团关于分布式唯一id生成器的解决方案, 其中提到了三种生成法:(建议看一下这篇文章,写得很 ...
- 高并发情况下分布式全局ID
1.高并发情况下,生成分布式全局id策略2.利用全球唯一UUID生成订单号优缺点3.基于数据库自增或者序列生成订单号4.数据库集群如何考虑数据库自增唯一性5.基于Redis生成生成全局id策略6.Tw ...
- 分布式的Id生成器
项目中需要一个分布式的Id生成器,twitter的Snowflake中这个既简单又高效,网上找的Java版本 package com.cqfc.id; import org.slf4j.Logger; ...
- snowflake 分布式唯一ID生成器
本文来自我的github pages博客http://galengao.github.io/ 即www.gaohuirong.cn 摘要: 原文参考运维生存和开源中国上的代码整理 我的环境是pytho ...
- Jedis使用总结【pipeline】【分布式的id生成器】【分布式锁【watch】【multi】】【redis分布式】(转)
前段时间细节的了解了Jedis的使用,Jedis是redis的java版本的客户端实现.本文做个总结,主要分享如下内容: [pipeline][分布式的id生成器][分布式锁[watch][multi ...
- python生成器原理剖析
python生成器原理剖析 函数的调用满足"后进先出"的原则,也就是说,最后被调用的函数应该第一个返回,函数的递归调用就是一个经典的例子.显然,内存中以"后进先出&quo ...
- 分布式全局ID与分布式事务
1. 概述 老话说的好:人不可貌相,海水不可斗量.以貌取人是非常不好的,我们要平等的对待每一个人. 言归正传,今天我们来聊一下分布式全局 ID 与分布式事务. 2. 分布式全局ID 2.1 分布式数据 ...
- 分布式全局ID生成方案
传统的单体架构的时候,我们基本是单库然后业务单表的结构.每个业务表的ID一般我们都是从1增,通过AUTO_INCREMENT=1设置自增起始值,但是在分布式服务架构模式下分库分表的设计,使得多个库或多 ...
随机推荐
- Unable to unwrap data, invalid status [CLOSED]-服务端webSocket报错
一.问题由来 现在的项目中在使用webSocket这门技术,主要用来在服务端和客户端进行实时的数据传输,因为需要及时的进行响应,所以才没有使用http请求的方式, 而是使用socket的方式,这样可以 ...
- [bzoj5510]唱跳rap和篮球
显然答案可以理解为有(不是仅有)0对情况-1对情况+2对情况-- 考虑这个怎么计算,先计算这t对情况的位置,有c(n-3t,t)种情况(可以理解为将这4个点缩为1个,然后再从中选t个位置),然后相当于 ...
- [loj2586]选圆圈
下面先给出比较简单的KD树的做法-- 根据圆心建一棵KD树,然后模拟题目的过程,考虑搜索一个圆 剪枝:如果当前圆[与包含该子树内所有圆的最小矩形]都不相交就退出 然而这样的理论复杂度是$o(n^2)$ ...
- Java-ASM框架学习-从零构建类的字节码
Tips: ASM使用访问者模式,学会访问者模式再看ASM更加清晰 什么是ASM ASM是一个操作Java字节码的类库 学习这个类库之前,希望大家对Java 基本IO和字节码有一定的了解. 高版本的A ...
- maven私服-配置本地私服环境之jar包下载环境搭建
我们前面已经搭建好环境了,就是maven里没有代码,如何导入jar包管理jar包 maven-public仓库组:已有 maven-central代理仓库:从直接代理maven中央仓库,修改为代理阿里 ...
- vue create is a Vue CLI 3 only command and you are using Vue CLI 2.9.6. You
这是因为你安装的是2.9的版本用了3.0的命令 解决方法:1.用2.9的命令初始化项目 vue init webpack my-project 2.卸载2.9升级到3.0
- 网络协议之:一定要大写的SOCKS
目录 简介 SOCKS的故事 SOCKS的历史 SOCKS协议的具体内容 SOCKS4 SOCKS4a SOCKS5 总结 简介 很久很久以前,人们还穿的是草鞋,草鞋虽然穿着舒服,但是不够美观.然后人 ...
- AtCoder Regular Contest 127 题解
sb atcoder 提前比赛时间/fn/fn/fn--sb atcoder 还我 rating/zk/zk/zk A 签到题,枚举位数 \(+\) 前导 \(1\) 个数然后随便算算贡献即可,时间复 ...
- 洛谷 P3676 - 小清新数据结构题(动态点分治)
洛谷题面传送门 题目名称好评(实在是太清新了呢) 首先考虑探究这个"换根操作"有什么性质.我们考虑在换根前后虽然每个点的子树会变,但整棵树的形态不会边,换句话说,割掉每条边后,得到 ...
- Codeforces 1461F - Mathematical Expression(分类讨论+找性质+dp)
现场 1 小时 44 分钟过掉此题,祭之 大力分类讨论. 如果 \(|s|=1\),那么显然所有位置都只能填上这个字符,因为你只能这么填. scanf("%d",&n);m ...