4个优化方法,让你能了解join计算过程更透彻
摘要:现如今, 跨源计算的场景越来越多, 数据计算不再单纯局限于单方,而可能来自不同的数据合作方进行联合计算。
本文分享自华为云社区《如何高可靠、高性能地优化join计算过程?4个优化让你掌握其中的精髓》,作者: breakDraw 。
现如今, 跨源计算的场景越来越多, 数据计算不再单纯局限于单方,而可能来自不同的数据合作方进行联合计算。
联合计算时,最关键的就是标识对齐,即需要将两方的角色将同一个标识(例如身份证、注册号等)用join操作关联起来, 提取出两边的交集部分, 后面再进行计算,得到需要的结果。
而这种join过程看似简单,其实有非常多的门道,这里让我从最简单的join方法开始, 一步步演示join的优化过程。
首先假设以下场景:
- 有tb1, tb2两张表的数据,存放在不同位置
- 各有相同的id列。
- tb1有1亿行数据,而tb2表只有10w行数据。
1.简单全集2次循环碰撞
拿到2张表的全量数据, 直接2个for循环进行遍历
如果id匹配,则合并2个行记录作为join结果
for (row r1 : tb1) {
for(row r2 : tb2) {
if(idMatch(r1, r2) {
// 获取r1和r2拼接后的r3
r3 = join(r1,r2)
result.add(r3)
}
}
}
图示如下:
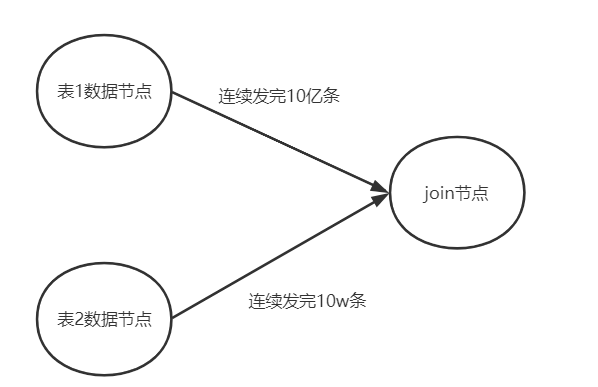
上面这种join有2个问题:
- 性能很差,两次for循环相当于O(mn)的复杂度
- 为了收集全量数据, 可能导致内存溢出,例如大表有10亿行数据,无法一次性存放。
2. 使用哈希表优化性能
首先解决刚才提到的第一个问题
实际上join过程就很像一种命中过程, 因此可以联想到哈希表。
- 我们使用一个 hashMap存储较小的tb2表(只有10w行)。
使用id列当作哈希表的key。 - 只对大表做for循环,如果id列在哈希表中能匹配中,则取出对用数据做拼接
for (row r1 : tb1) {
if(idMap.containKey(r1.getId())) {
row r2 = idMap.get(r1.getId());
r3 = join(r1,r2)
result.add(r3)
}
}
这样复杂度就优化到了O(m)了
3. 大表数据分批传输
还有一个问题没解决: ”为了收集全量数据, 可能导致内存溢出“。
那我们可以将大表按照特定数量进行拆分,分成多批数据
例如每次以1000条的数量,和小表进行上面的哈希表碰撞过程。这样空间复杂度就是O (K + n)。
当每碰撞完一次,才接着接收下一批数据。如下面所示
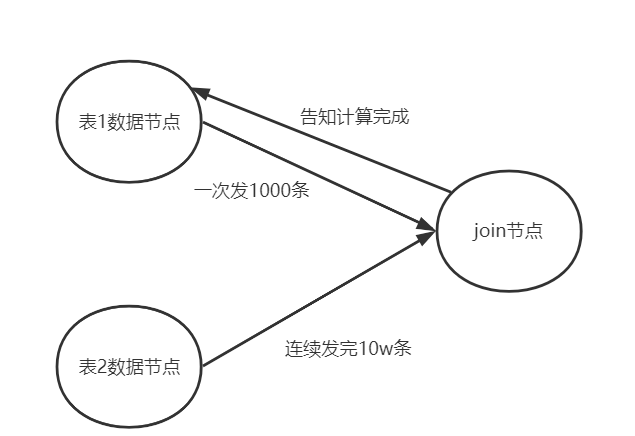
注意, ”告知计算完成这种响应机制“也可以优化成阻塞的缓冲队列。
但是还有个问题, 如果小表本身也很大, 例如1亿条, 计算节点连小表的哈希表都存不下,怎么办?
另外单节点计算的CPU有限,如何能在短时间内快速提升性能?
4. 分布式计算
当计算节点存不下小表构成的哈希表时, 这时候可以扩容2个join计算节点, 引入分布式计算来分担内存压力。
例如我们可以对id列进行shuffle分片
- id%3==0 分到计算节点A
- id%3==1 分到计算节点B
- id%3 ==2 分到计算阶段C
如果id是均匀的, 则小表的数据就被拆成了3份,也许就能正好存下了。
大表数据按同样的方式分片, 分到相同的节点, 对计算结果是没有影响的, 只要你的分片算法确保id匹配的行一定在同一个节点即可。
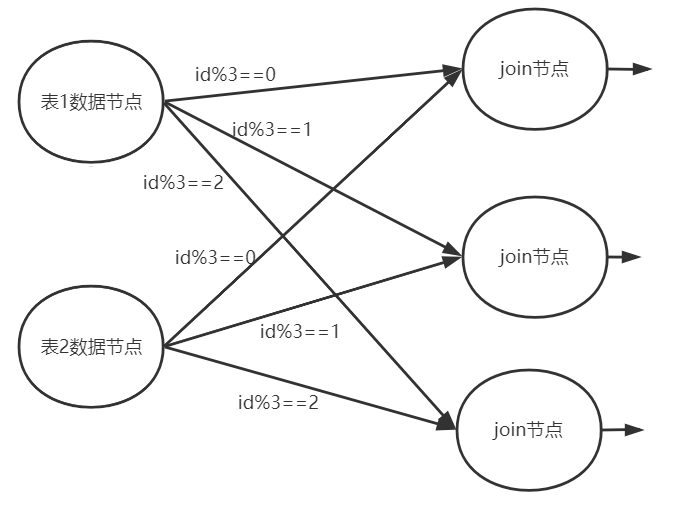
另外性能上, 分布式计算理论上按照节点数量也能够提升N倍的join速度。
这种分布式计算的方式已经能解决大部分join作业了,但是还有个问题:
- 假设网络带宽压力比较大(比如买的带宽比较便宜,发送数据的成本比较大)
- 部分涉及安全的计算场景中可能需要对数据做加密
这2种情况都会造成数据在输出时会耗费很多时间,甚至超过join的过程。那么该如何优化?
5. 本地join计算
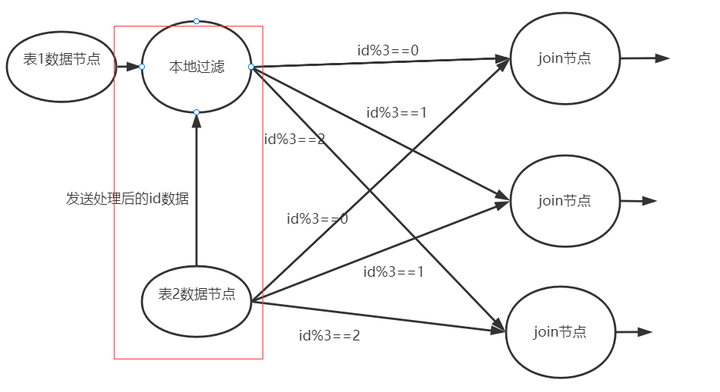
本地计算,指的就是在通过网络输出数据前,先提前做一些预处理。这种操作在各种计算引擎中都有体现
- 在spark中有一个叫boardCast广播数据的机制
- presto中有一种叫runtimeFilter的方式。
对于join过程, 我们可以:
- 将小表的id进行一定的压缩处理(例如哈希之后取前x位)
这样可以减少传输的数据量。 - 然后将这块数据传输给大表所在的节点, 进行提前的简单join筛选, 这样就可以提前过滤掉很多的没必要通过网络输出的数据。
以上仅仅只是最基础的join优化过程, 而在海量数据、高性能、高安全、跨网络的复杂场景中, 关于join计算还会有更多的挑战。
因此可以关注华为可信智能计算TICS服务,专注高性能高安全的联邦计算和联邦学习,推动跨机构数据的可信融合和协同,安全释放数据价值。
4个优化方法,让你能了解join计算过程更透彻的更多相关文章
- 提升网速的路由器优化方法(UPnP、QoS、MTU、交换机模式、无线中继)
在上一篇<为什么房间的 Wi-Fi 信号这么差>中,猫哥从微波炉.相对论.人存原理出发,介绍了影响 Wi-Fi 信号强弱的几大因素,接下来猫哥再给大家介绍几种不用升级带宽套餐也能提升网速的 ...
- php-fpm优化方法详解
php-fpm优化方法 php-fpm存在两种方式,一种是直接开启指定数量的php-fpm进程,不再增加或者减少:另一种则是开始时开启一定数量的php-fpm进程,当请求量变大时,动态的增加php-f ...
- 30多条mysql数据库优化方法,千万级数据库记录查询轻松解决(转载)
1.对查询进行优化,应尽量避免全表扫描,首先应考虑在 where 及 order by 涉及的列上建立索引. 2.应尽量避免在 where 子句中对字段进行 null 值判断,否则将导致引擎放弃使用索 ...
- Android中ListView的几种常见的优化方法
Android中的ListView应该算是布局中几种最常用的组件之一了,使用也十分方便,下面将介绍ListView几种比较常见的优化方法: 首先我们给出一个没有任何优化的Listview的Adapte ...
- php-fpm进程数优化方法
原文地址:https://www.douban.com/note/315222037/ 背景最近将Wordpress迁移至阿里云.由于自己的服务器是云服务器,硬盘和内存都比较小,所以内存经常不够使,通 ...
- DevExpress ChartControl大数据加载时有哪些性能优化方法
DevExpress ChartControl加载大数据量数据时的性能优化方法有哪些? 关于图表优化,可从以下几个方面解决: 1.关闭不需要的可视化的元素(如LineMarkers, Labels等) ...
- Tomcat从内存、并发、缓存方面优化方法
Tomcat有很多方面,从内存.并发.缓存四个方面介绍优化方法. 一.Tomcat内存优化 Tomcat内存优化主要是对 tomcat 启动参数优化,我们可以在 tomcat 的启动脚本 cata ...
- 股票投资组合-前进优化方法(Walk forward optimization)
code{white-space: pre;} pre:not([class]) { background-color: white; }if (window.hljs && docu ...
- Caffe学习系列(8):solver优化方法
上文提到,到目前为止,caffe总共提供了六种优化方法: Stochastic Gradient Descent (type: "SGD"), AdaDelta (type: &q ...
随机推荐
- c++学习笔记6(结构化程序设计的不足)
结构化程序设计 c语言使用结构化程序设计: 程序=数据结构+算法 程序有全局变量以及众多相互调用的函数组成 算法以函数的形式实现,用于对数据结构进行操作 结构化程序设计不足 软件业的目标是更快,更正确 ...
- SpringCloud升级之路2020.0.x版-34.验证重试配置正确性(3)
本系列代码地址:https://github.com/JoJoTec/spring-cloud-parent 我们继续上一节针对我们的重试进行测试 验证针对可重试的方法响应超时异常重试正确 我们可以通 ...
- 如何将rabbitmq集群中的某个节点移除.
首先将要移除的节点停机. root@rabbitmq-03:~# rabbitmqctl stop Stopping and halting node 'rabbit@rabbitmq-03' ... ...
- Protocol Buffer序列化Java框架-Protostuff
了解Protocol Buffer 首先要知道什么是Protocol Buffer,在编程过程中,当涉及数据交换时,我们往往需要将对象进行序列化然后再传输.常见的序列化的格式有JSON,XML等,这些 ...
- java 单例模式实现代码
目录 1.使用静态内部类实现 2.使用枚举实现 3.序列化与反序列化 1.使用静态内部类实现 使用静态内部类实现单例模式,线程安全 class SingletonStaticInner { priva ...
- Haywire
还是模拟退火乱搞. 不过考虑记录一下在整个退火过程中的最优答案. 而不是只看最后剩下的解. 退火是一个随机算法,他有很大的几率能跳到最优解,但也很有可能从最优解跳出去. 所以要记录答案. Haywir ...
- P3438 [POI2006]ZAB-Frogs
P3438 [POI2006]ZAB-Frogs 给出一个不一样的解法.不需要用到斜率优化等高级算法. 下文记 \(n=w_x,m=w_y\). 首先,答案显然满足可二分性,因此二分答案 \(d\in ...
- curl实现SFTP上传下载文件
摘自:https://blog.csdn.net/swj9099/article/details/85292444 #include <stdio.h> #include <stdl ...
- word2010在左侧显示目录结构
- requests+bs4爬取豌豆荚排行榜及下载排行榜app
爬取排行榜应用信息 爬取豌豆荚排行榜app信息 - app_detail_url - 应用详情页url - app_image_url - 应用图片url - app_name - 应用名称 - ap ...