前端---梳理 http 知识体系 1

最近看了http相关的知识点,觉得还是有必要整理下,这样对自己的网络知识体系也有帮助。
http 是什么
协议
http 是一个用在计算机里面的协议,使用计算机通信之间的一个规范,以及相关各种控制和错误处理方式。简单的说就是约定、规则。
传输
http 是一个在计算机世界里专门用来在计算机之间传输数据的约定和规范。
超文本
所谓“超文本”,就是“超越了普通文本的文本”,它是文字、图片、音频和视频等的混合体,最关键的是含有“超链接”,能够从一个“超文本”跳跃到另一个“超文本”,形成复杂的非线性、网状的结构关系
http 不是一个孤立的协议
http 是一个应用层协议, 通常跑在 TCP/IP 协议栈之上,依靠 IP 协议实现寻址和路由、TCP 协议实现可靠数据传输、DNS 协议实现域名查找、SSL/TLS 协议实现安全通信。此外,还有一些协议依赖于 HTTP,例如 WebSocket、HTTPDNS 等。
HTTP 优缺点
特点
灵活可扩展
语法上只规定了基本格式,空格分隔单词,换行分隔字段等。以及传输上不仅可以传输文本,还可以传输图片,视频等任意数据。
可靠传输
请求-应答模式
请求 - 应答模式是 HTTP 协议最根本的通信模型,简单的理解就是,一方发消息,一方接收消息
无状态
整个协议里没有规定任何的“状态”,客户端和服务器永远是处在一种“无知”的状态。建立连接前两者互不知情,每次收发的报文也都是互相独立的,没有任何的联系。
缺点
不安全
明文传输,其次HTTP 协议也不支持“完整性校验”,数据在传输过程中容易被窜改而无法验证真伪。为了解决 HTTP 不安全的缺点,所以就出现了 HTTPS
性能
http 是请求-应答模式,发起的请求类似一个队列,先进先出,会存在对头阻塞问题
无状态
这个无状态主要看应用场景,对于不需要上下文状态的,这个就是优点,对于需要记录状态的,这个就是缺点,当然这个可以通过其他方式来做,比如 cookie,token 等
HTTP 报文结构
HTTP 协议的请求报文和响应报文的结构基本相同,由三大部分组成:
- 起始行(start line):描述请求或响应的基本信息
- 头部字段集合(header):使用 key-value 形式更详细地说明报文
- 消息正文(entity):实际传输的数据,它不一定是纯文本,可以是图片、视频等二进制数据
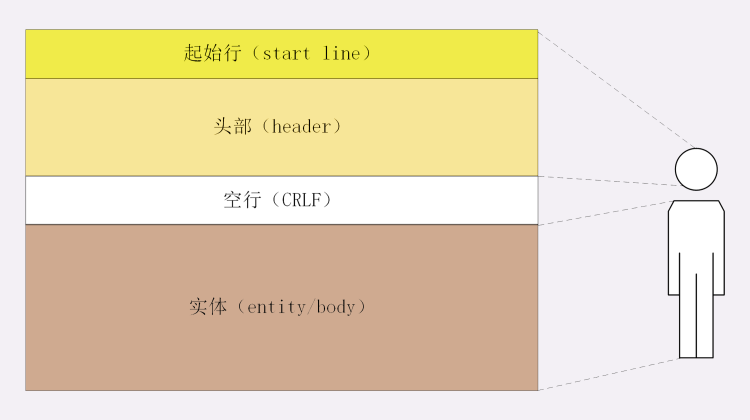
前两部分起始行和头部字段经常又合称为“请求头”或“响应头”,消息正文又称为“实体”,但与“header”对应,很多时候就直接称为“body”。
HTTP 协议规定报文必须有 header,但可以没有 body,而且在 header 之后必须要有一个“空行”(区分body 与 head 分割),也就是CRLF。
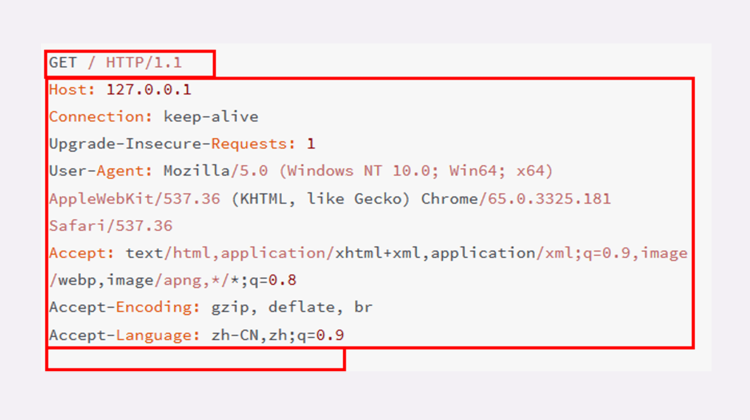
HTTP 头字段非常灵活,不仅可以使用标准里的 Host、Connection 等已有头,也可以任意添加自定义头,这就给 HTTP 协议带来了非常好的灵活、扩展性。
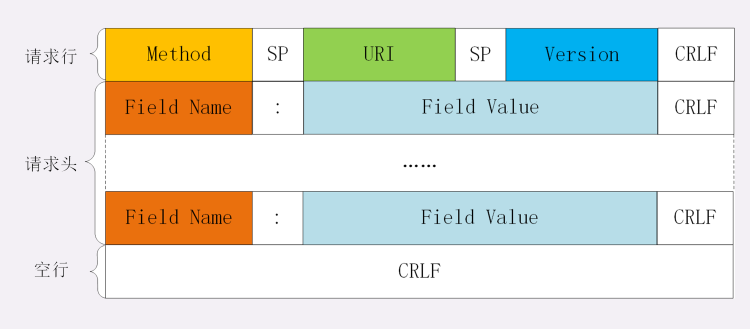
请求行
报文里的起始行也就是请求行(request line),它简要地描述了客户端想要如何操作服务器端的资源。

状态行
这里它不叫“响应行”,而是叫“状态行”(status line),意思是服务器响应的状态。

头部字段
HTTP 常见状态码
RFC 规定 HTTP 的状态码为「三位数」,第一个数字定义了响应的类别,被分为五类:
- 1xx: 代表请求已被接受,需要继续处理。
- 2xx: 表示成功状态。
- 3xx: 重定向状态。
- 4xx: 客户端错误。
- 5xx: 服务器端错误。
客户端作为请求的发起方,获取响应报文后,需要通过状态码知道请求是否被正确处理,是否要再次发送请求,如果出错了原因又是什么。这样才能进行下一步的动作,要么发送新请求,要么改正错误重发请求。
服务器端作为请求的接收方,也应该很好地运用状态码。在处理请求时,选择最恰当的状态码回复客户端,告知客户端处理的结果,指示客户端下一步应该如何行动。特别是在出错的时候,尽量不要简单地返 400、500 这样意思含糊不清的状态码。
目前 RFC 标准里总共有 41 个状态码,但状态码的定义是开放的,允许自行扩展。所以 Apache、Nginx 等 Web 服务器都定义了一些专有的状态码。如果你自己开发 Web 应用,也完全可以在不冲突的前提下定义新的代码。
1xx 信息类
接受的请求正在处理,信息类状态码。
2xx 成功
- 200 OK 表示从客户端发来的请求在服务器端被正确请求。
- 204 No content,表示请求成功,但没有资源可返回。
- 206 Partial Content,该状态码表示客户端进行了范围请求,而服务器成功执行了这部分的 GET 请求 响应报文中包含由 「Content-Range」 指定范围的实体内容。
3xx 重定向
- 301 moved permanently,永久性重定向,表示资源已被分配了新的 URL,这时应该按 Location 首部字段提示的 URI 重新保存。
- 302 found,临时性重定向,表示资源临时被分配了新的 URL。
- 304 资源未修改,拿缓存的资源
301 和 302 都会在响应头里使用字段 Location 指明后续要跳转的 URI,最终的效果很相似,浏览器都会重定向到新的 URI。两者的根本区别在于语义,一个是“永久”,一个是“临时”。
比如,你的网站升级到了 HTTPS,原来的 HTTP 不打算用了,这就是“永久”的,所以要配置 301 跳转,把所有的 HTTP 流量都切换到 HTTPS。
“304 Not Modified” 是一个比较有意思的状态码,它用于 If-Modified-Since 等条件请求,表示资源未修改,用于缓存控制。它不具有通常的跳转含义,但可以理解成“重定向已到缓存的文件”(即“缓存重定向”)。
4xx 客户端错误
- 400 bad request,通用的错误码,请求报文存在语法错误。
- 403 forbidden,表示对请求资源的访问被服务器拒绝,服务器经常访问资源。
- 404 not found,表示在服务器上没有找到请求的资源。
- 405 Method Not Allowed,服务器禁止使用该方法,客户端可以通过options方法来查看服务器允许的访问方法
5xx 服务的错误
- 500 internal sever error,表示服务器端在执行请求时发生了错误。
- 502 Bad Gateway,服务器自身是正常的,访问的时候出了问题,具体啥错误我们不知道。
- 503 service unavailable,表明服务器暂时处于超负载或正在停机维护,无法处理请求。
HTTP主要版本之间的差异
http0.9
http1.0
相比0.9版本,1.0版本增加了很多功能,例如:
- 传输的数据不再仅限于文本,图像、视频、音频都能传输
- 引入了 HTTP Header(头部)的概念,让 HTTP 处理请求和响应更加灵活
- 增加了响应状态码,标记可能的错误原因
- 增加了 HEAD、POST 等新方法
http1.1
http1.1是对 http1.0 的小幅度修改。但一个重要的区别是:它是一个“正式的标准”
- 明确了连接管理,允许持久连接,即TCP建立连接之后默认不关闭,可以被多个请求复用,不用声明Connection: keep-alive
- 增加了 PUT、DELETE 等新的方法
- 增加了缓存管理和控制,如增加了 E-tag,If-Unmodified-Since, If-Match, If-None-Match 等缓存控制标头来控制缓存失效
- 支持断点续传,通过使用请求头中的
Range来实现。 - 允许响应数据分块(chunked)传输,有利于传输大文件
- 强制要求 请求头带上Host 头,让互联网主机托管成为可能。
其中http1.1 版本是目前主流版本。
http2
随着互联网在飞速发展,目前http1.0 不符合现在的网络环境要求了,所以谷歌在1.0 的基础上提出了SPDY 协议,优化了1.0。http/2 的制定充分考虑了现今互联网的现状:宽带、移动、不安全,在高度兼容 http/1.1 的同时在性能改善方面做了很大努力,
主要的特点有:
- 二进制协议,不再是纯文本,包括头部字段、body 的实体数据都是二进制,并且统称为"帧":头信息帧和数据帧
- 可发起多个请求,废弃了 1.1 里的管道
- 增加流、二进制分帧的概念
- 多路复用TCP连接,在一个连接里,客户端和浏览器都可以同时发送多个请求或回应,且不用按顺序一一对应,这样子解决了http队头阻塞的问题。
- 使用专用算法(HPACK)压缩头部,减少数据传输量
- 允许服务器主动向客户端推送数据
http3
在http2 的基础之上又进一步优化,出现了QUIC 协议,后面更名为http/3,HTTP/3 目前正式进入了标准化制订阶段。
TCP/IP 协议栈
tcp/ip 是一个有层次的协议栈,TCP/IP 协议总共有四层,就像搭积木一样,每一层需要下层的支撑,同时又支撑着上层,任何一层被抽掉都可能会导致整个协议栈坍塌。每一层只做自己的事情,然后把结果给其他层,这样的结构责任清晰,便于扩展。
第一层:链接层(数据链路层)负责在以太网、WiFi 这样的底层网络上发送原始数据包,工作在网卡这个层次,使用 MAC 地址来标记网络上的设备,所以有时候也叫 MAC 层。
第二层:“网际层”或者“网络互连层”(internet layer)也叫网络层,IP 协议就处在这一层。因为 IP 协议定义了“IP 地址”的概念,所以就可以在“链接层”的基础上,用 IP 地址取代 MAC 地址,把许许多多的局域网、广域网连接成一个虚拟的巨大网络,在这个网络里找设备时只要把 IP 地址再“翻译”成 MAC 地址就可以了。
第三层:“传输层”(transport layer),这个层次协议的职责是保证数据在 IP 地址标记的两点之间“可靠”地传输,是 TCP 协议工作的层次,另外还有它的一个“小伙伴”UDP。
第四层叫“应用层”(application layer),由于下面的三层把基础打得非常好,所以在这一层就“百花齐放”了,有各种面向具体应用的协议。例如 Telnet、SSH、FTP、SMTP 等等,当然还有我们的 HTTP。
TCP/IP工作方式
HTTP 协议的传输过程就是通过协议栈逐层向下,每一层都添加本层的专有数据,层层打包,然后通过下层发送出去。
接收数据则是相反的操作,从下往上穿过协议栈,逐层拆包,每层去掉本层的专有头,上层就会拿到自己的数据。
简单的理解就是类似发快递的过程,快递员从你那拿到包裹,拿到地址,装到他的车子,运送到站点,在分类打包,送去各个物流中转站,到达之后,对方再依次拆包,拿到你寄送过去的物品。
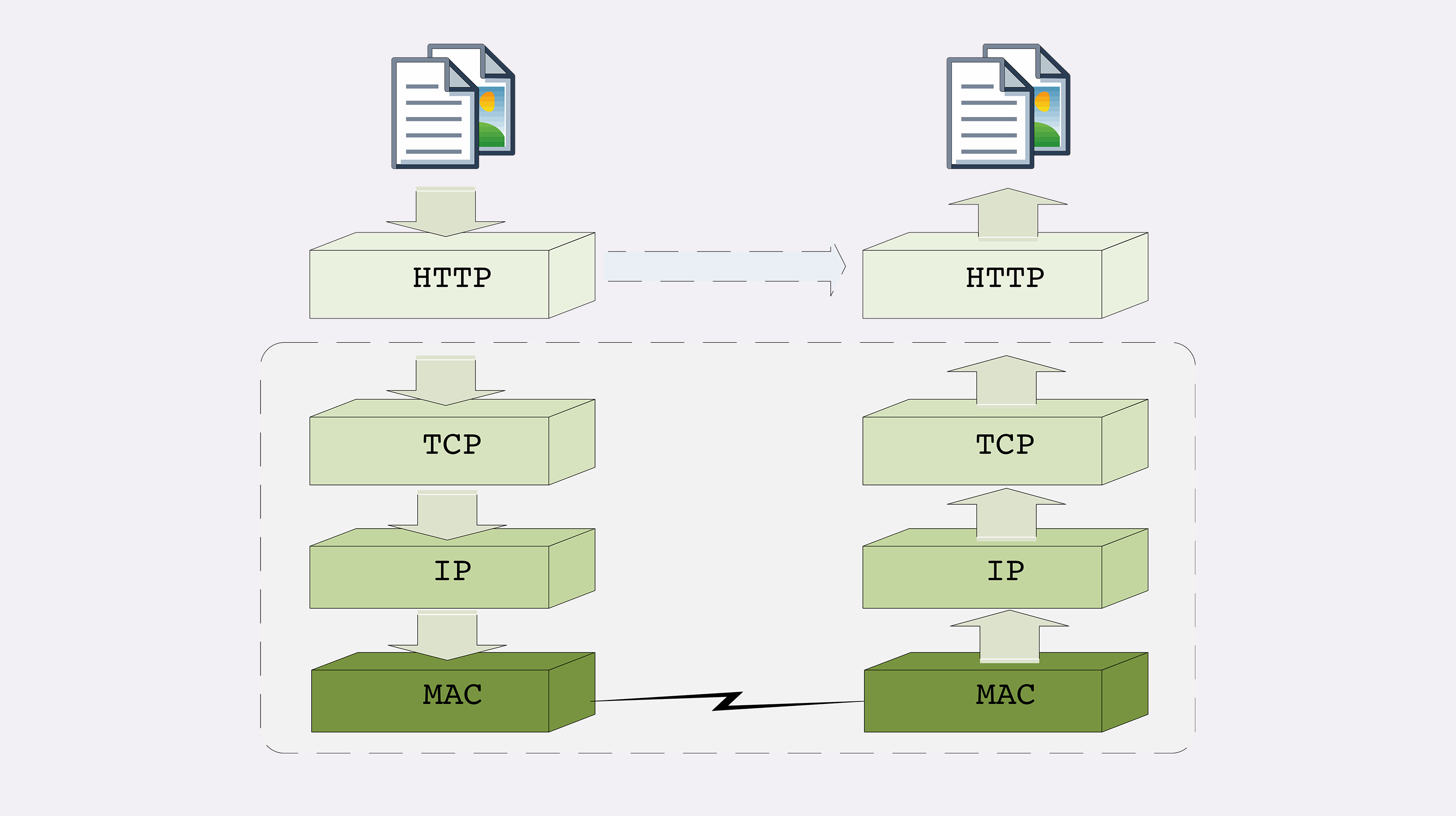
TCP/IP四层与OSI七层模型
TCP/IP 发明于 1970 年代,当时除了它还有很多其他的网络协议,整个网络世界比较混乱。
这个时候国际标准组织(ISO)注意到了这种现象,就想要来个“大一统”。于是设计出了一个新的网络分层模型,想用这个新框架来统一既存的各种网络协议。TCP/IP 等协议已经在许多网络上实际运行,再推翻重来是不可能的。
所以,OSI 分层模型在发布的时候就明确地表明是一个“参考”,不是强制标准
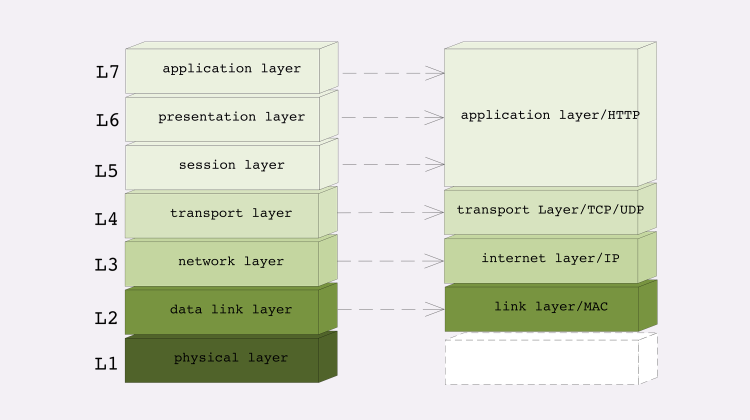
第一层:物理层,TCP/IP 里无对应;
第二层:数据链路层,对应 TCP/IP 的链接层;
第三层:网络层,对应 TCP/IP 的网际层;
第四层:传输层,对应 TCP/IP 的传输层;
第五、六、七层:统一对应到 TCP/IP 的应用层。
HTTP 连接管理
目前主流版本http1.1 中的连接管理是会存在对头阻塞的问题,所以性能是存在一点问题的,这个后面在说。
短连接
HTTP 协议最初(0.9/1.0)是个非常简单的协议,通信过程也采用了简单的“请求 - 应答”方式。
它底层的数据传输基于 TCP/IP,每次发送请求前需要先与服务器建立连接,收到响应报文后会立即关闭连接。
因为客户端与服务器的整个连接过程很短暂,不会与服务器保持长时间的连接状态,所以就被称为“短连接”(short-lived connections)。早期的 HTTP 协议也被称为是“无连接”的协议。
短连接的缺点相当严重,因为在 TCP 协议里,建立连接和关闭连接都是非常“昂贵”的操作。TCP 建立连接要有“三次握手”,发送 3 个数据包;关闭连接是“四次挥手”,4 个数据包需要 。
长连接
针对短连接暴露出的缺点,HTTP 协议就提出了“长连接”的通信方式,也叫“持久连接”。
其实解决办法也很简单,用的就是“成本均摊”的思路,既然 TCP 的连接和关闭非常耗时间,那么就把这个时间成本由原来的一个“请求 - 应答”均摊到多个“请求 - 应答”上。

连接相关的头部字段
由于长连接对性能的改善效果非常显著,所以在 HTTP/1.1 中的连接都会默认启用长连接。不需要用什么特殊的头字段指定,只要向服务器发送了第一次请求,后续的请求都会重复利用第一次打开的 TCP 连接,也就是长连接,在这个连接上收发数据。
也可以在请求头里明确地要求使用长连接机制,使用的字段是 Connection,值是“keep-alive”,如图:
长连接缺点
因为 TCP 连接长时间不关闭,服务器必须在内存里保存它的状态,这就占用了服务器的资源。如果有大量的空闲长连接只连不发,就会很快耗尽服务器的资源,导致服务器无法为真正有需要的用户提供服务。
所以,长连接也需要在恰当的时间关闭,不能永远保持与服务器的连接,这在客户端或者服务器都可以做到。
在客户端,可以在请求头里加上“Connection: close”字段,告诉服务器:“这次通信后就关闭连接”。服务器看到这个字段,就知道客户端要主动关闭连接,于是在响应报文里也加上这个字段,发送之后就调用 Socket API 关闭 TCP 连接。
服务器端通常不会主动关闭连接,但也可以使用一些策略。拿 Nginx 来举例,它有两种方式:
- 使用keepalive_timeout指令,设置长连接的超时时间,如果在一段时间内连接上没有任何数据收发就主动断开连接,避免空闲连接占用系统资源。
- 使用keepalive_requests指令,设置长连接上可发送的最大请求次数。比如设置成 1000,那么当 Nginx 在这个连接上处理了 1000 个请求后,也会主动断开连接。
HTTP 缓存控制
http 的缓存是通过Cache-Control 字段来控制
- max-age:是 HTTP 缓存控制最常用的属性,max-age=30”就是资源的有效时间,相当于告诉浏览器,“这个页面只能缓存 30 秒,之后就算是过期,不能用,这也就是经常说的强缓存。
- no-store:不允许缓存,用于某些变化非常频繁的数据,例如秒杀页面;
- no-cache:它的字面含义容易与 no-store 搞混,实际的意思并不是不允许缓存,而是可以缓存,但在使用之前必须要去服务器验证是否过期,是否有最新的版本,这也就是经常说的协商缓存;
- must-revalidate:又是一个和 no-cache 相似的词,它的意思是如果缓存不过期就可以继续使用,但过期了如果还想用就必须去服务器验证。
强缓存
强缓存两个相关的字段是Expires、Cache-Control,HTTP1.0版本使用的是Expires,HTTP1.1使用的是Cache-Control,当这两个字段同时在头部字段中出现时已Cache-Control 为准。
协商缓存
HTTP 协议定义了一系列“If”开头的“条件请求”字段,专门用来检查验证资源是否过期,把两个请求才能完成的工作合并在一个请求里做。而且,验证的责任也交给服务器,浏览器只需等待验证的结果。
我们最常用的字段时if-Modified-Since和If-None-Match这两个。
在第一次的响应报文里提供Last-modified和ETag,然后第二次请求时就可以带上缓存里的原值,验证资源是否是最新的。如果资源没有变,服务器就回应一个“304 Not Modified”,表示缓存依然有效,浏览器就可以更新一下有效期,然后放心大胆地使用缓存了。
- if-Modified-Since:上一次响应头里的Last-modified
- If-None-Match:上一次响应头里的ETag

ETag
ETag是服务器根据当前文件的内容,对文件生成唯一的标识,比如MD5算法,只要里面的内容有改动,这个值就会修改,服务器通过把响应头把该字段发送给浏览器。
浏览器接受到ETag值,会在下次请求的时候,将这个值作为If-None-Match这个字段的内容,发给服务器。
服务器接收到If-None-Match后,会跟服务器上该资源的ETag进行比对
- 如果两者一样的话,直接返回304,告诉浏览器直接使用缓存
- 如果不一样的话,说明内容更新了,返回新的资源,跟常规的HTTP请求响应的流程一样
Etag 一般由web 应用服务器生成,根据修改时间、内容大小等生成一个字符串,可以理解为通过某种算法生成 如MD5; 比如
nginx 中 etag 由响应头的 Last-Modified 与 Content-Length 表示为十六进制组合而成,不同的web 服务器采用的算法应该不一样;
etag 还分强、弱,通常都是采用弱etag,强etag 耗时间,消耗资源,具体的可以查阅相关资料;
前端---梳理 http 知识体系 1的更多相关文章
- 前端---梳理 http 知识体系 2
为什么要有HTTPS HTTP 天生具有明文的特点,整个传输过程完全透明,任何人都能够在链路中截获.修改或者伪造请求 / 响应报文,数据不具有安全性.仅凭HTTP 自身是无法解决的,需要引入新的HTT ...
- 从输入URL到页面加载的过程?如何由一道题完善自己的前端知识体系!
前言 见解有限,如有描述不当之处,请帮忙指出,如有错误,会及时修正. 为什么要梳理这篇文章? 最近恰好被问到这方面的问题,尝试整理后发现,这道题的覆盖面可以非常广,很适合作为一道承载知识体系的题目. ...
- github上最全的资源教程-前端涉及的所有知识体系
前面分享了前端入门资源汇总,今天分享下前端所有的知识体系. 个人站长对个人综合素质要求还是比较高的,要想打造多拉斯自媒体网站,不花点心血是很难成功的,学习前端是必不可少的一个环节, 当然你不一定要成为 ...
- Web前端知识体系精简
Web前端技术由html.css和javascript三大部分构成,是一个庞大而复杂的技术体系,其复杂程度不低于任何一门后端语言.而我们在学习它的时候往往是先从某一个点切入,然后不断地接触和学习新的知 ...
- Web前端知识体系
看到一篇不错的文章,拿来收藏和分享. 原文:http://mp.weixin.qq.com/s/UFTfdE7LYhHquWEzwZKLCQ Web前端技术由html.css和 javascript三 ...
- web前端知识体系总结
1. 前言 大约在几个月之前,让我看完了<webkit技术内幕>这本书的时候,突然有了一个想法.想把整个web前端开发所需要的知识都之中在一个视图中,形成一个完整的web前端知识体系,目的 ...
- 自己总结的web前端知识体系大全【欢迎补充】
1. 前言 大约在几个月之前,让我看完了<webkit技术内幕>这本书的时候,突然有了一个想法.想把整个web前端开发所需要的知识都之中在一个视图中,形成一个完整的web前端知识体系,目的 ...
- WEB前端知识体系脑图
说在开始的话: 我上大学那会,虽说主要是学Java语言,但是web前端也稍微学了一些,那时候对前端也没多在意,因为涉入的不深,可以搞一个差不多可以看的界面就可以了,其他也没过多在意. 因为稍微了解一点 ...
- 、web前端的这么知识应该是怎样的一个知识体系架构?
.web前端的这么知识应该是怎样的一个知识体系架构?之前我以为可以以W3C为纲要,把W3C的东西学会了就够了.后来发现我错了,W3C还不全面. 真正全面的覆盖了web前端知识体系的东西是——浏览器内核 ...
随机推荐
- 学习PHP中的iconv扩展相关函数
想必 iconv 这个扩展的相关函数大家多少都接触过,做为 PHP 的默认扩展它已经存在了很久,也是我们在操作字符编码时经常会使用的函数.不过除了 iconv() 这个函数外,你还知道它的其它函数吗? ...
- TP生成二维码插件
安装 composer require endroid/qrcode 使用: use Endroid\QrCode\QrCode 然后 这个类库要改一下 在路径:你的项目路径\vendor\endro ...
- windows 中cmd一些特殊命令
chcp 65001 就是换成UTF-8代码页 chcp 936 可以换回默认的GBK chcp 437 是美国英语 shutdown -s -t 60 60秒后关机 shutdown /a ...
- javascript 定时器 timer setTimeout setInterval (js for循环如何等待几秒再循环)
实现一个打点计时器,要求1.从 start 到 end(包含 start 和 end),每隔 100 毫秒 console.log 一个数字,每次数字增幅为 12.返回的对象中需要包含一个 cance ...
- 使用php函数 json_encode ,数据存入mysql
$data = json_encode($array); // 过滤 $data = addslashes($data); // 插入数据库 $db->insert($table_name,ar ...
- [转载]CentOS 7 创建本地YUM源
本文中的"本地YUM源"包括三种类型:一是直接使用CentOS光盘作为本地yum源,优点是简单便捷,缺点是光盘软件包可能不完整(centos 7 Everything 总共才6.5 ...
- kubeadm 命令简介
kubeadm 命令 kubeadm init 启动一个kubernetes主节点 kubeadm join 启动一个kubernetes工作节点并加入到集群中 kubeadm upgrade 更新一 ...
- P5056-[模板]插头dp
正题 题目链接:https://www.luogu.com.cn/problem/P5056 题目大意 \(n*m\)的网格,求有多少条回路可以铺满整个棋盘. 解题思路 插头\(dp\)的,写法是按照 ...
- Winform 空闲时间(鼠标键盘无操作)
前言 Winform 在特定情况下,需要判断软件空闲时间(鼠标键盘无操作),然后在做一下一些操作. 实现 做了一个简单的例子,新建一个窗体,然后拖两个控件(Timer控件和label控件) using ...
- 关于docker复现vulhub环境的搭建
原本想用docker复现一下vul的漏洞. 装docker过程中遇到了很多问题, 昨天熬夜到凌晨三点都没弄完. 中午又找了找原因,终于全部解决了, 小结一下. 0x01 镜像 去官方下载了centos ...