MySQL实战45讲(21--25)-笔记
21 | 为什么我只改一行的语句,锁这么多?
加锁规则里面:包含了两个“原则”、两个“优化”和一个“bug”。
- 原则 1:加锁的基本单位是 next-key lock。希望你还记得,next-key lock 是前开后闭区
间。 - 原则 2:查找过程中访问到的对象才会加锁。
- 优化 1:索引上的等值查询,给唯一索引加锁的时候,next-key lock 退化为行锁。
- 优化 2:索引上的等值查询,向右遍历时且最后一个值不满足等值条件的时候,next-key lock 退化为间隙锁。
- 一个 bug:唯一索引上的范围查询会访问到不满足条件的第一个值为止。
22 | MySQL有哪些“饮鸩止渴”提高性能的方法?
业务高峰期,生产环境的 MySQL 压力太大,没法正常响应,需要短期内、临时性地提升一些性能。
短连接风暴
正常的短连接模式就是连接到数据库后,执行很少的 SQL 语句就断开,下次需要的时候再重连。
如果使用的是短连接,在业务高峰期的时候,就可能出现连接数突然暴涨的情况。
除了正常的网络连接三次握手外,还需要做登录权限判断和获得这个连接的数据读写权限。
max_connections 参数,用来控制一个 MySQL 实例同时存在的连接数的上限,超过这个值,系统就会拒绝接下来的连接请求,并报错提示“Too many connections”。
第一种方法:先处理掉那些占着连接但是不工作的线程
max_connections 的计算,不是看谁在 running,是只要连着就占用一个计数位置。
对于那些不需要保持的连接,我们可以通过 kill connection 主动踢掉。
这个行为跟事先设置wait_timeout 的效果是一样的。
wait_timeout 参数表示的是,一个线程空闲wait_timeout 这么多秒之后,就会被 MySQL 直接断开连接。
第二种方法:减少连接过程的消耗
有的业务代码会在短时间内先大量申请数据库连接做备用,如果现在数据库确认是被连接行为打挂了,那么一种可能的做法,是让数据库跳过权限验证阶段。
跳过权限验证的方法是:重启数据库,并使用–skip-grant-tables 参数启动。
这样,整个MySQL 会跳过所有的权限验证阶段,包括连接过程和语句执行过程在内。
但是,这种方法特别符合我们标题里说的“饮鸩止渴”,风险极高,是我特别不建议使用的方案。
尤其你的库外网可访问的话,就更不能这么做了。
在 MySQL 8.0 版本里,如果你启用 –skip-grant-tables 参数,
MySQL 会默认把 --skip-networking 参数打开,表示这时候数据库只能被本地的客户端连接。
可见,MySQL 官方对skip-grant-tables 这个参数的安全问题也很重视。
慢查询性能问题
MySQL慢查询就是在日志中记录运行比较慢的SQL语句,这个功能需要开启才能用。
在 MySQL 中,会引发性能问题的慢查询,大体有以下三种可能:
索引没有设计好;
SQL 语句没写好;
MySQL 选错了索引。
索引没有设计好
这种场景一般就是通过紧急创建索引来解决。
MySQL 5.6 版本以后,创建索引都支持 Online DDL 了,
对于那种高峰期数据库已经被这个语句打挂了的情况,最高效的做法就是直接执行alter table 语句。
比较理想的是能够在备库先执行。假设你现在的服务是一主一备,主库 A、备库 B,这个方案的
大致流程是这样的:
- 在备库 B 上执行 set sql_log_bin=off,也就是不写 binlog,然后执行 alter table 语句加+索引;
- 执行主备切换;
- 这时候主库是 B,备库是 A。在 A 上执行 set sql_log_bin=off,然后执行 alter table 语句
加上索引。
这是一个“古老”的 DDL 方案。
平时在做变更的时候,你应该考虑类似 gh-ost 这样的方案,更加稳妥。
但是在需要紧急处理时,上面这个方案的效率是最高的。
语句没有写好
我们可以通过改写 SQL 语句来处理。MySQL 5.7 提供了 query_rewrite 功能,
可以把输入的一种语句改写成另外一种模式。
MySQL 选错了索引
应急方案就是给这个语句加上 force index。
QPS 突增问题
Queries Per Second,意思是“每秒查询率”
一类情况,是由一个新功能的 bug 导致的。
当然,最理想的情况是让业务把这个功能下掉,服务自然就会恢复。
一种是由全新业务的 bug 导致的。
假设你的 DB 运维是比较规范的,也就是说白名单是一个个加的。
这种情况下,如果你能够确定业务方会下掉这个功能,只是时间上没那么快,那么就可以从数据库端直接把白名单去掉。
如果这个新功能使用的是单独的数据库用户,可以用管理员账号把这个用户删掉,
然后断开现有连接。这样,这个新功能的连接不成功,由它引发的 QPS 就会变成 0。
如果这个新增的功能跟主体功能是部署在一起的,那么我们只能通过处理语句来限制。
这时,我们可以使用上面提到的查询重写功能,把压力最大的 SQL 语句直接重写成"select 1"。
当然,这个操作的风险很高,需要你特别细致。
它可能存在两个副作用:
如果别的功能里面也用到了这个 SQL 语句模板,会有误伤;
很多业务并不是靠这一个语句就能完成逻辑的,所以如果单独把这一个语句以 select 1 的结果返回的话,可能会导致后面的业务逻辑一起失败。
所以,方案 3 是用于止血的,跟前面提到的去掉权限验证一样,应该是你所有选项里优先级最低的一个方案。
23 | MySQL是怎么保证数据不丢的?
只要 redo log 和 binlog 保证持久化到磁盘,就能确保 MySQL 异常重启后,数据可以恢复。
探究 MySQL 写入 binlog 和 redo log 的流程。
binlog写入机制
binlog 的写入机制binlog 的写入逻辑比较简单:
事务执行过程中,先把日志写到 binlog cache,事务提交的时候,再把 binlog cache 写到 binlog 文件中。
问题来了:一个事务的 binlog 是不能被拆开的,因此不论这个事务多大,也要确保一次性写入。这就涉及
到了 binlog cache 的保存问题。
系统给 binlog cache 分配了一片内存,每个线程一个,
参数 binlog_cache_size 用于控制单个线程内 binlog cache 所占内存的大小。
如果超过了这个参数规定的大小,就要暂存到磁盘。
事务提交的时候,执行器把 binlog cache 里的完整事务写入到 binlog 中,并清空 binlog cache。
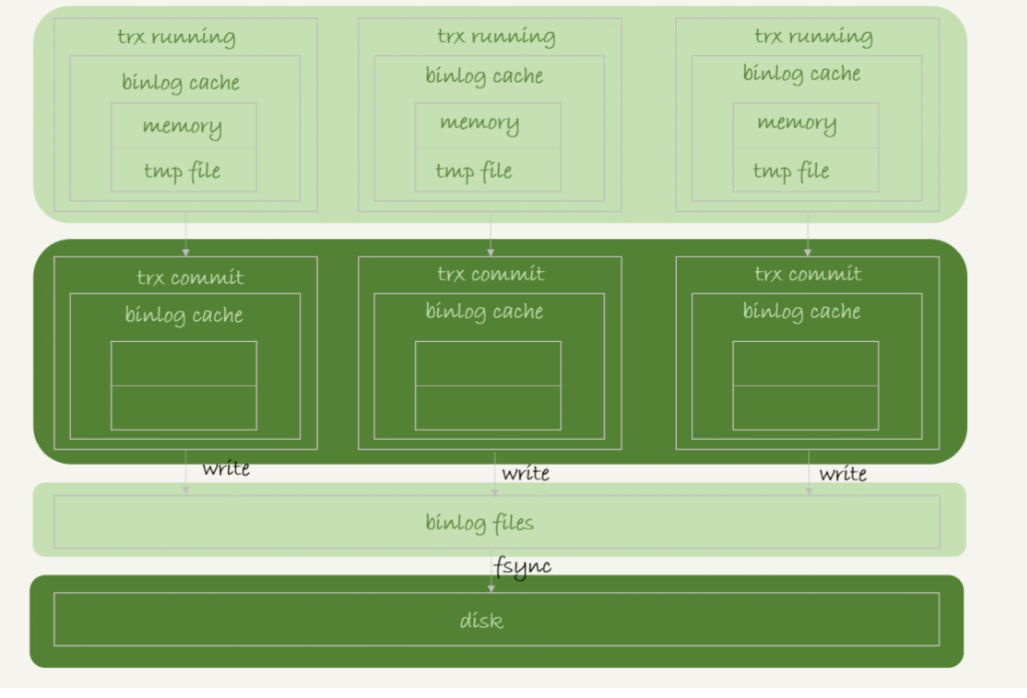
可以看到,每个线程有自己 binlog cache,但是共用同一份 binlog 文件。
图中的 write,指的就是指把日志写入到文件系统的 page cache,并没有把数据持久化到磁盘,所以速度比较快。
图中的 fsync,才是将数据持久化到磁盘的操作。一般情况下,我们认为 fsync 才占磁盘的IOPS。
write 和 fsync 的时机,是由参数 sync_binlog 控制的:
sync_binlog=0 的时候,表示每次提交事务都只 write,不 fsync;
sync_binlog=1 的时候,表示每次提交事务都会执行 fsync;
sync_binlog=N(N>1) 的时候,表示每次提交事务都 write,但累积 N 个事务后才 fsync。
因此,在出现 IO 瓶颈的场景里,将 sync_binlog 设置成一个比较大的值,可以提升性能。
在实际的业务场景中,考虑到丢失日志量的可控性,一般不建议将这个参数设成 0,比较常见的是将其设置为 100~1000 中的某个数值。
但是,将 sync_binlog 设置为 N,对应的风险是:如果主机发生异常重启,会丢失最近 N 个事务的 binlog 日志。
redo log 的写入机制
事务在执行过程中,生成的redo log 是要先写到 redo log buffer 的。
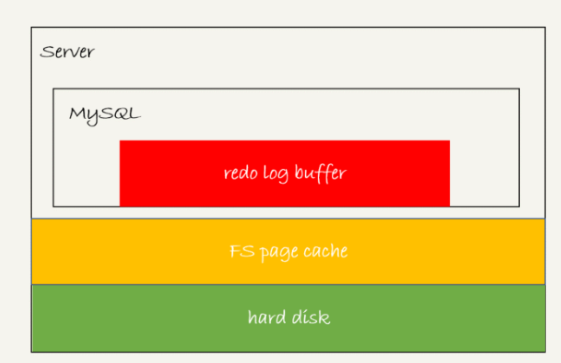
这三种状态分别是:
- 存在 redo log buffer 中,物理上是在 MySQL 进程内存中,就是图中的红色部分;
- 写到磁盘 (write),但是没有持久化(fsync),物理上是在文件系统的 page cache 里面,也就是图中的黄色部分;
- 持久化到磁盘,对应的是 hard disk,也就是图中的绿色部分。
日志写到 redo log buffer 是很快的,wirte 到 page cache 也差不多,但是持久化到磁盘的速度就慢多了。
为了控制 redo log 的写入策略,InnoDB 提供了 innodb_flush_log_at_trx_commit 参数,
它有三种可能取值:
- 设置为 0 的时候,表示每次事务提交时都只是把 redo log 留在 redo log buffer 中 ;
- 设置为 1 的时候,表示每次事务提交时都将 redo log 直接持久化到磁盘;
- 设置为 2 的时候,表示每次事务提交时都只是把 redo log 写到 page cache。
InnoDB 有一个后台线程,每隔 1 秒,就会把 redo log buffer 中的日志,调用 write 写到文件系统的 page cache,然后调用 fsync 持久化到磁盘。
注意,事务执行中间过程的 redo log 也是直接写在 redo log buffer 中的,
这些 redo log 也会被后台线程一起持久化到磁盘。也就是说,一个没有提交的事务的 redo log,也是可能已经
持久化到磁盘的。
实际上,除了后台线程每秒一次的轮询操作外,还有两种场景会让一个没有提交的事务的 redolog 写入到磁盘中。
- 一种是,redo log buffer 占用的空间即将达到 innodb_log_buffer_size 一半的时候,后台线程会主动写盘。
注意,由于这个事务并没有提交,所以这个写盘动作只是 write,而没有调用 fsync,也就是只留在了文件系统的 page cache。
- 另一种是,并行的事务提交的时候,顺带将这个事务的 redo log buffer 持久化到磁盘。
两阶段提交,时序上 redo log 先 prepare, 再写binlog,最后再把 redo log commit。
更新中…………(这里有地方没有理解)
24 | MySQL是怎么保证主备一致的?
MySQL 主备的基本原理
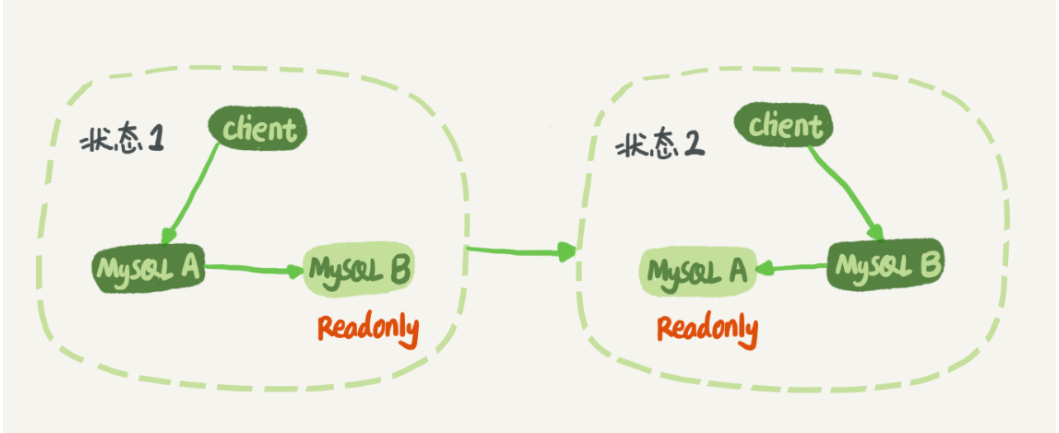
在状态 1 中,虽然节点 B 没有被直接访问,但是我依然建议你把节点 B(也就是备库)设置成只读(readonly)模式,
防止一些误操作
与主库保持同步更新,readonly 设置对超级 (super) 权限用户是无效的,而用于同步更新的线程,就拥有超级权限。
备库 B 跟主库 A 之间维持了一个长连接。主库 A 内部有一个线程,专门用于服务备库 B 的这个长连接。
binlog 的三种格式对比
更新中…………
循环复制问题
binlog 的特性确保了在备库执行相同的 binlog,可以得到与主库相同的状态。
因此,我们可以认为正常情况下主备的数据是一致的。
上面俩个圈的图我们称作“双M结构”
双 M 结构还有一个问题需要解决。
如果节点 A 同时是节点 B 的备库,
相当于又把节点 B 新生成的 binlog 拿过来执行了一次,
然后节点 A 和 B 间,会不断地循环执行这个更新语句,也就是循环复制了。
这个要怎么解决呢?
我们可以用下面的逻辑,来解决两个节点间的循环复制的问题:
1. 规定两个库的 server id 必须不同,如果相同,则它们之间不能设定为主备关系;
2. 一个备库接到 binlog 并在重放的过程中,生成与原 binlog 的 server id 相同的新的binlog;
3. 每个库在收到从自己的主库发过来的日志后,先判断 server id,如果跟自己的相同,
表示这个日志是自己生成的,就直接丢弃这个日志。
25 | MySQL是怎么保证高可用的?
主备延迟
主备延迟最直接的表现是,备库消费中转日志(relay log)的速度,比主库生产binlog 的速度要慢。
来源
- 备库所在机器的性能要比主库所在的机器性能差。
主好从弱,更新请求对 IOPS 的压力,在主库和备库上是无差别的,所以不好。
这种部署现在比较少了。因为主备可能发生切换,备库随时可能变成主库,所以主备库选用相同规格的机器,并且做对称部署。
- 备库的压力大
主库直接影响业务,大家使用起来会比较克制,反而忽视了备库的压力控制。
这种情况,我们一般可以这么处理:
1. 一主多从。除了备库外,可以多接几个从库,让这些从库来分担读的压力。
2. 通过 binlog 输出到外部系统,比如 Hadoop 这类系统,让外部系统提供统计类查询的能力。
- 大事务
主库上必须等事务执行完成才会写入 binlog,再传给备库,如果主库的的执行时间太长,延迟就有了。
可靠性优先策略
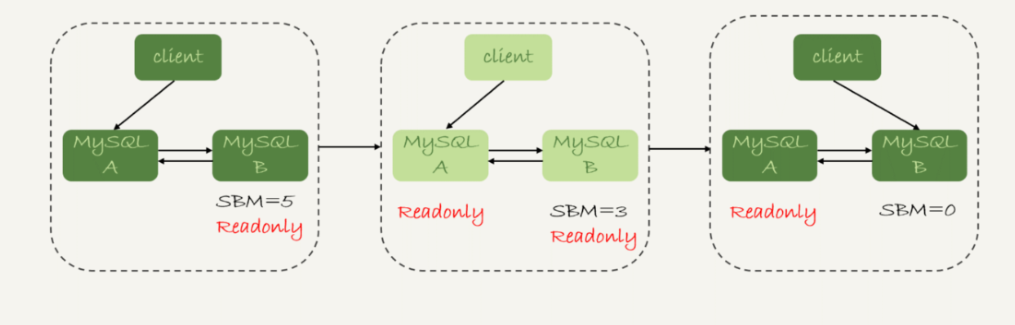
备注:图中的 SBM,是 seconds_behind_master 参数的简写。
可用性优先策略
- 使用 row 格式的 binlog 时,数据不一致的问题更容易被发现。
而使用 mixed 或者statement 格式的 binlog 时,数据很可能悄悄地就不一致了。
如果你过了很久才发现数据不一致的问题,很可能这时的数据不一致已经不可查,或者连带造成了更多的数据逻辑不一致。
- 主备切换的可用性优先策略会导致数据不一致。
因此,大多数情况下,我都建议你使用可靠性优先策略。
毕竟对数据服务来说的话,数据的可靠性一般还是要优于可用性的
MySQL实战45讲(21--25)-笔记的更多相关文章
- 《MySQL实战45讲》(1-7)笔记
<MySQL实战45讲>笔记 目录 <MySQL实战45讲>笔记 第一节: 基础架构:一条SQL查询语句是如何执行的? 连接器 查询缓存 分析器 优化器 执行器 第二节:日志系 ...
- 《MySQL实战45讲》(8-15)笔记
MySQL实战45讲 目录 MySQL实战45讲 第八节: 事务到底是隔离的还是不隔离的? 在MySQL里,有两个"视图"的概念: "快照"在MVCC里是怎么工 ...
- 《MySQL实战45讲》学习笔记1——MySQL的基础架构
在<极客时间>订阅了<MySQL实战45讲>专栏,总觉得看完和没看一样
- 《MySQL实战45讲》个人笔记-基础篇
拜读了林晓斌大佬的<MySQL实战45讲>,特意做个知识点总结,以便后期回忆. 01.基础架构:一条SQL查询语句是如何执行的? Server 层包括连接器.查询缓存.分析器.优化器.执行 ...
- 《MySQL实战45讲》学习笔记2——MySQL的日志系统
一.日志类型 逻辑日志:存储了逻辑SQL修改语句 物理日志:存储了数据被修改的值 二.binlog 1.定义 binlog 是 MySQL 的逻辑日志,也叫二进制日志.归档日志,由 MySQL Ser ...
- 《MySQL实战45讲》学习笔记4——MySQL中InnoDB的索引
索引是在存储引擎层实现的,且在 MySQL 不同存储引擎中的实现也不同,本篇文章介绍的是 MySQL 的 InnoDB 的索引. 下文将以这张表为例开展. # 创建一个主键为 id 的表,表中有字段 ...
- 《MySQL实战45讲》学习笔记3——InnoDB为什么采用B+树结构实现索引
索引的作用是提高查询效率,其实现方式有很多种,常见的索引模型有哈希表.有序列表.搜索树等. 哈希表 一种以key-value键值对的方式存储数据的结构,通过指定的key可以找到对应的value. 哈希 ...
- 深挖计算机基础:MySQL实战45讲学习笔记
参考极客时间专栏<MySQL实战45讲>学习笔记 一.基础篇(8讲) MySQL实战45讲学习笔记:第一讲 MySQL实战45讲学习笔记:第二讲 MySQL实战45讲学习笔记:第三讲 My ...
- 极客时间 Mysql实战45讲 07讲行锁功过:怎么减少行锁对性能的影响笔记 极客时间
极客时间 Mysql实战45讲 07讲行锁功过:怎么减少行锁对性能的影响笔记 极客时间极客时间 Mysql实战45讲 07讲行锁功过:怎么减少行锁对性能的影响笔记 极客时间 笔记体会: 方案一,事务相 ...
- Mysql实战45讲 06讲全局锁和表锁:给表加个字段怎么有这么多阻碍 极客时间 读书笔记
Mysql实战45讲 极客时间 读书笔记 Mysql实战45讲 极客时间 读书笔记 笔记体会: 根据加锁范围:MySQL里面的锁可以分为:全局锁.表级锁.行级锁 一.全局锁:对整个数据库实例加锁.My ...
随机推荐
- 从门外汉到腾讯Android高级研发——一个半路出家菜鸟的艰难逆袭之路
我是在去年3月份加入腾讯公司,目前是腾讯公司某技术部门里面的一个小负责人,年薪月薪大税后概30K,谈不上多么厉害,但在回想自己半路出家学习编程,从一个销售到现在终于进入中国互联网顶尖公司,还是有些许感 ...
- TestNG注释@BeforeGroups与@AfterGroups不执行的处理
在学习TestNG框架注解时发现在执行以下的代码 package com.groups; import org.testng.annotations.AfterGroups; import org.t ...
- SpringBoot报错:Error starting ApplicationContext. To display the conditions report re-run your application with 'debug' enabled.
Spring Boot报错:Error starting ApplicationContext. To display the conditions report re-run your applic ...
- 线程的常用知识(包括 Thread/Executor/Lock-free/阻塞/并发/锁等)
本次内容列表: 1.使用线程的经验:设置名称.响应中断.使用ThreadLocal 2.Executor:ExecutorService和Future 3.阻塞队列:put和take.offer和po ...
- 成为编程大牛很简单,把这些书看个八成就OK
原文链接:http://lucida.me/blog/developer-reading-list/ 本文把程序员所需掌握的关键知识总结为三大类19个关键概念,然后给出了掌握每个关键概念所需的入门书籍 ...
- sqli-labs lesson 7-10 (文件导出,布尔盲注,延时注入)
写在前面: 首先需要更改一下数据库用户的权限用于我们之后的操作. 首先在mysql命令行中用show variables like '%secure%';查看 secure-file-priv 当前的 ...
- springCloud-Hystrix服务监控Dashboard
1.Hystrix服务监控Dashboard 介绍 Hystrix服务监控Dashboard仪表盘 在实际生产中,成千上万的服务,我们怎么知道提供服务的高可用情况,即服务的成功失败超时等相关情况; H ...
- Vue2.0 axios 读取本地json文件
参考:https://www.cnblogs.com/wdxue/p/8868982.html 1.下载插件 npm install axios --save 2.在main.js下引用axios i ...
- C# 利用反射进行深拷贝
- c++本地动态连接库代码
c++本地动态连接库代码 1 #pragma once 2 #include "stdafx.h" 3 4 #ifdef PERSON_EXPORTS 5 #define PERS ...