Spark Streaming实时数据分析


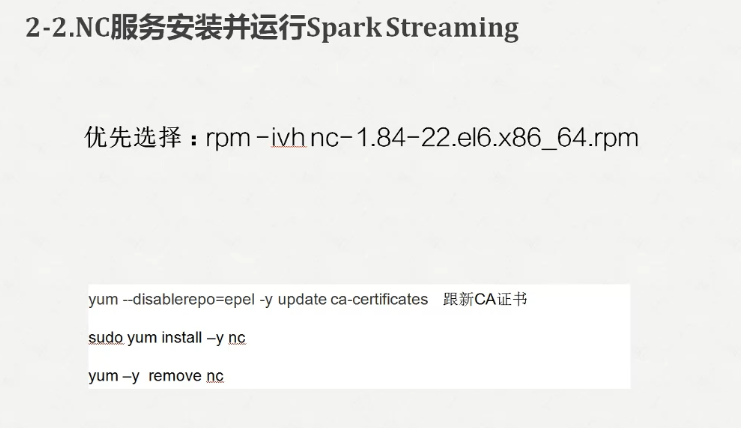

[kfk@bigdata-pro01 softwares]$ sudo rpm -ivh nc-1.84-.el6.x86_64.rpm
Preparing... ########################################### [%]
:nc ########################################### [%]
[kfk@bigdata-pro01 softwares]$

重新启用一个远程连接窗口
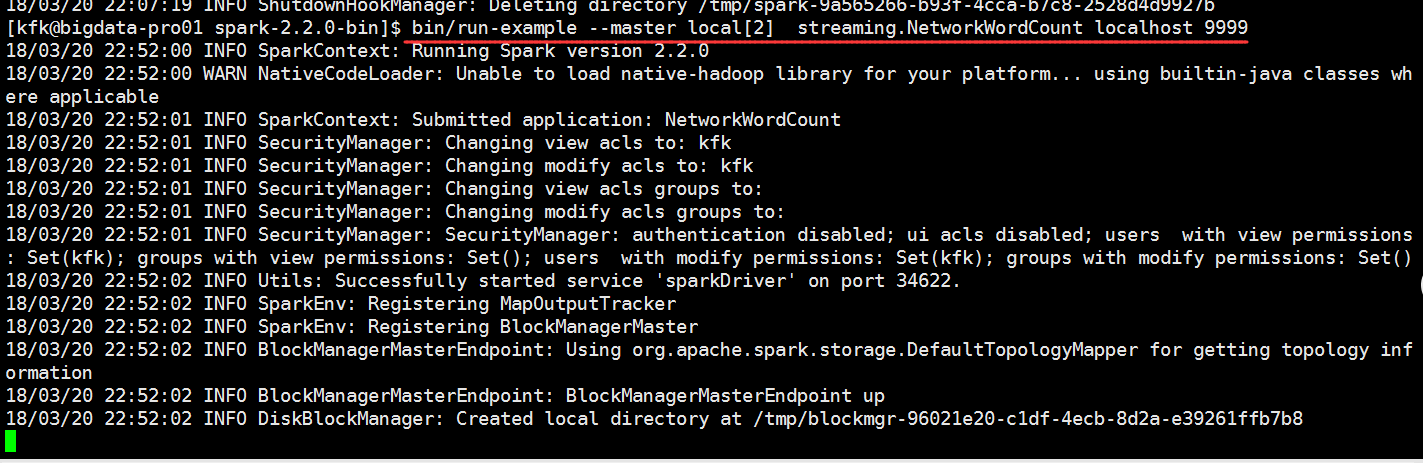
bin/run-example streaming.NetworkWordCount localhost

回到这边输入一些信息
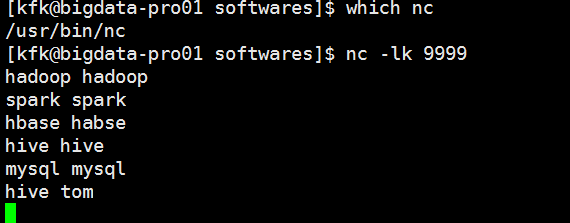
看到这边就有数据接收到了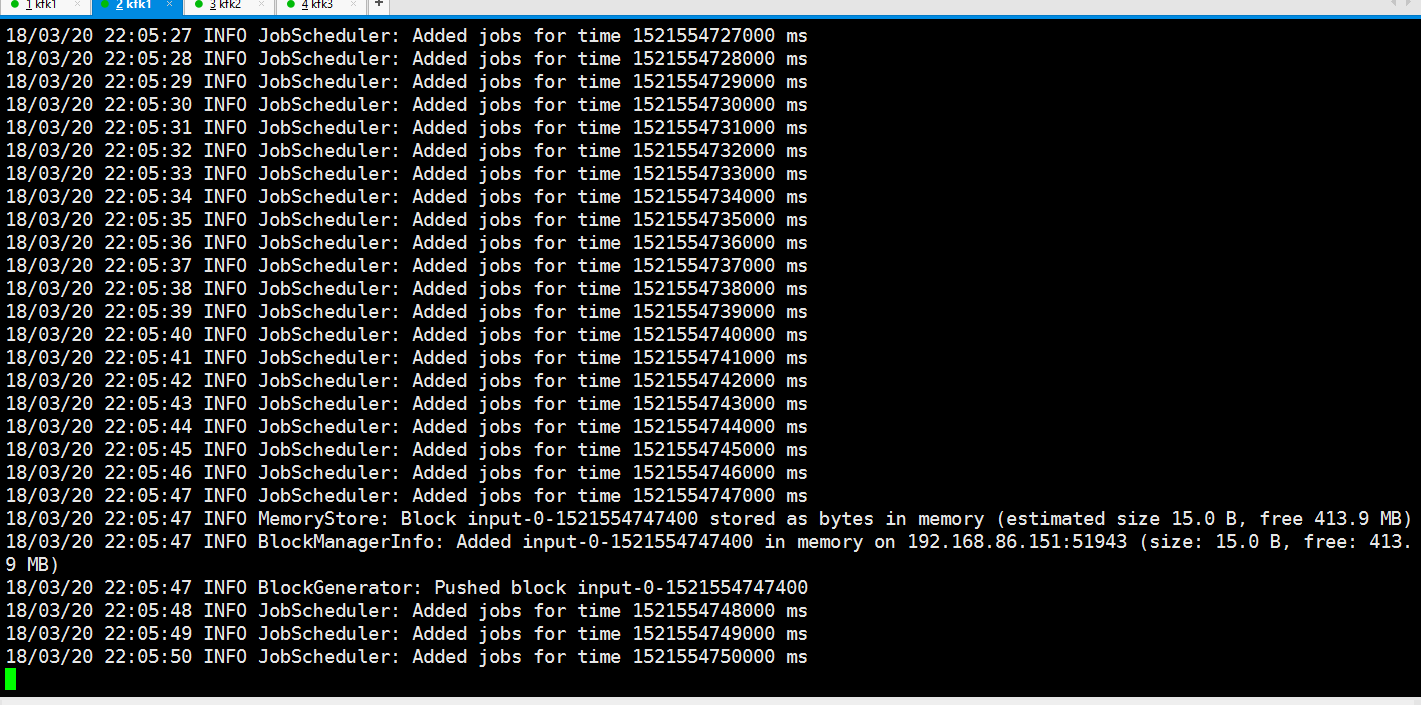
我们退出,换个方式启动
我们在这边再输入一些数据

这边处理得非常快

因为打印的日志信息太多了,我修改一下配置文件(3个节点都修改吧,保守一点了)
我们在来跑一下

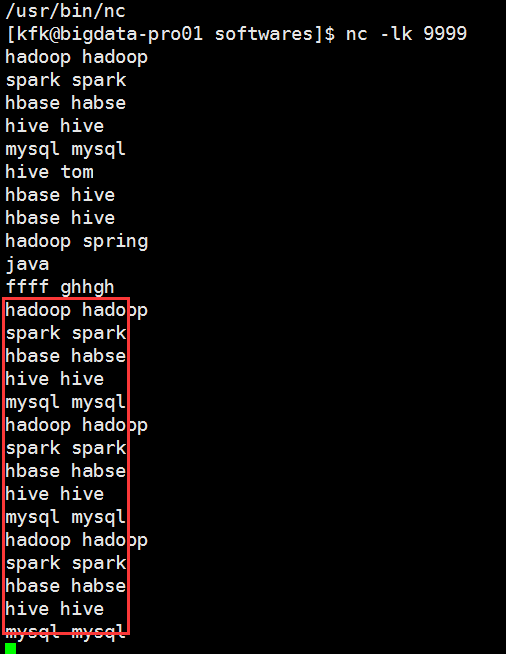
再回到这边我们敲几个字母进去

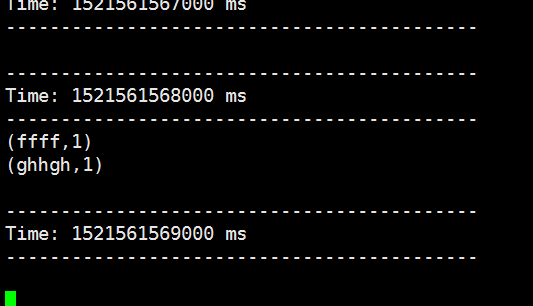
把同样的单词多次输入我们看看是什么结果
可以看到他会统计
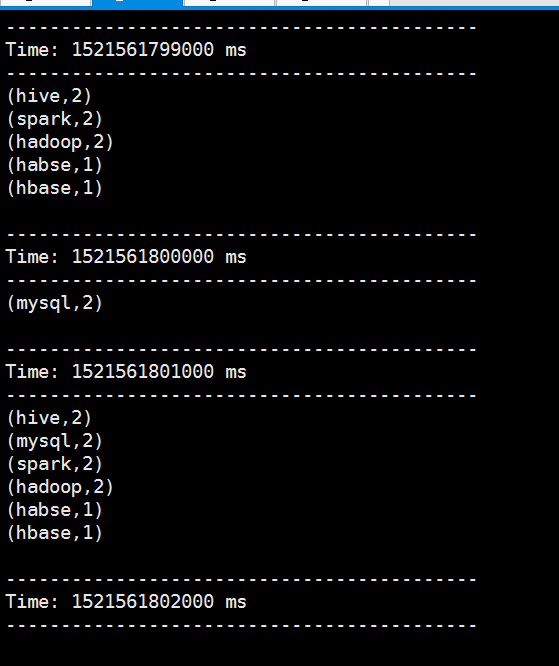
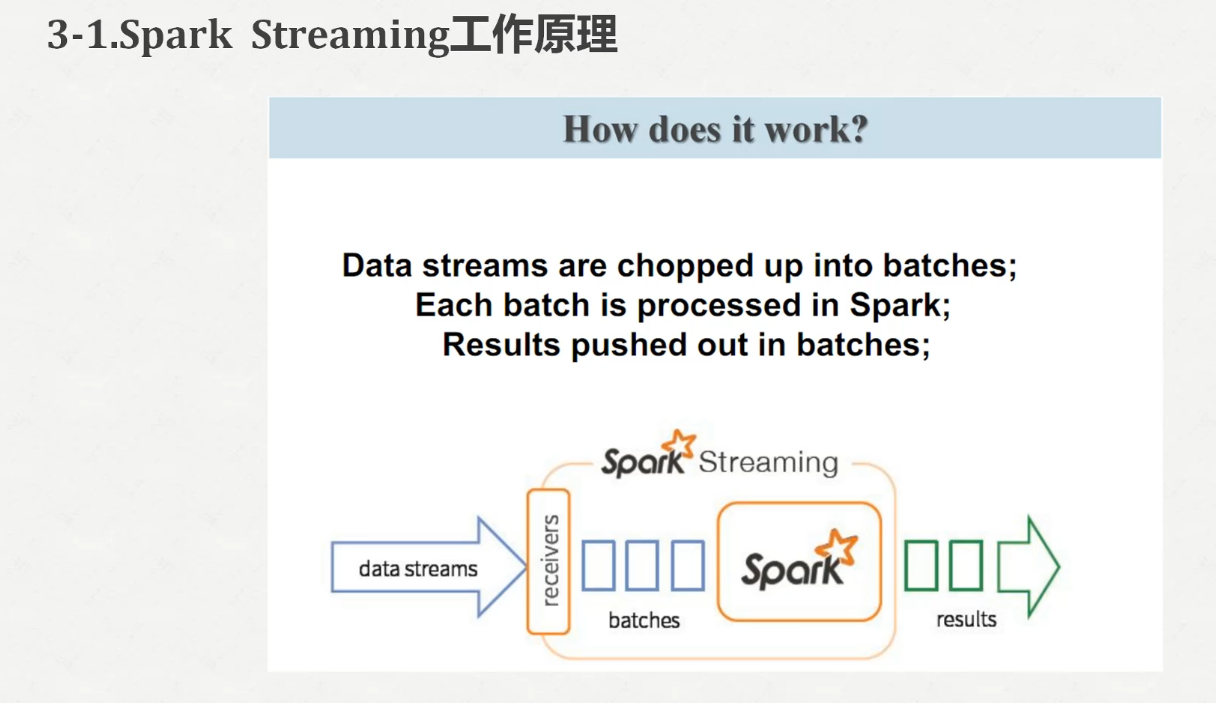
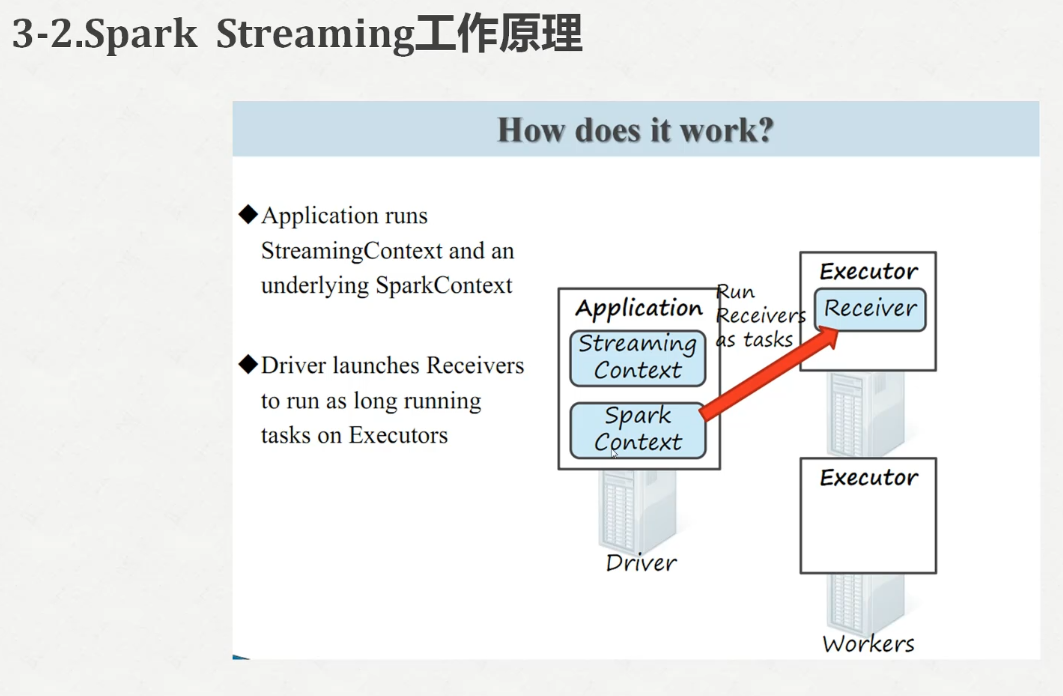
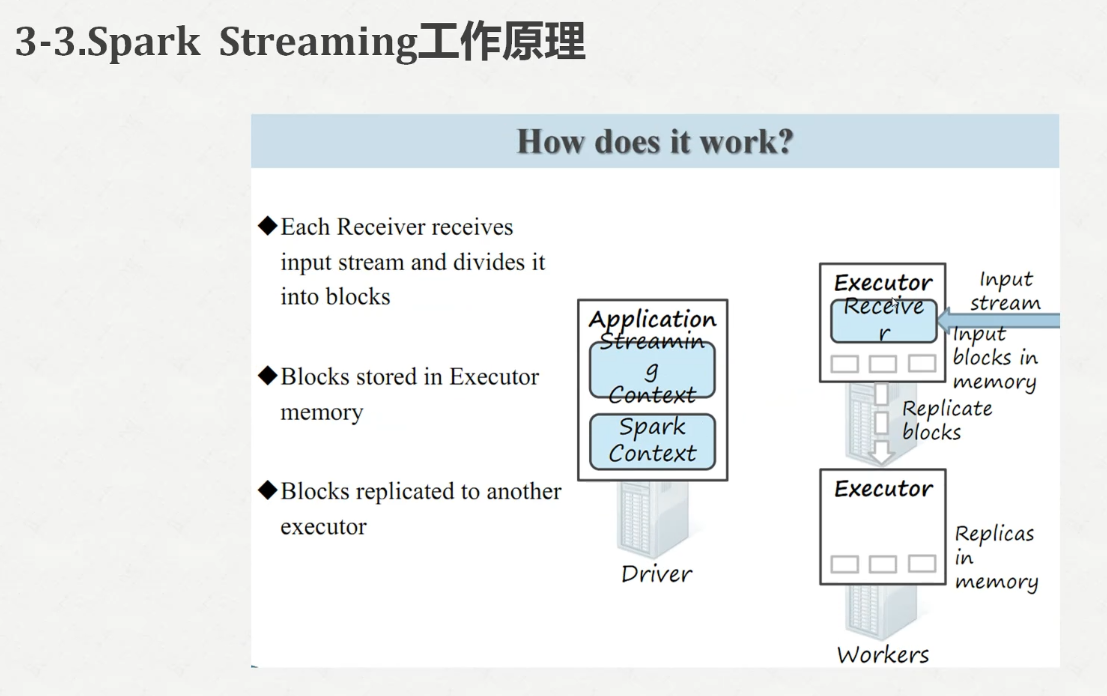





我们启动一下spark-shell,发现报错了

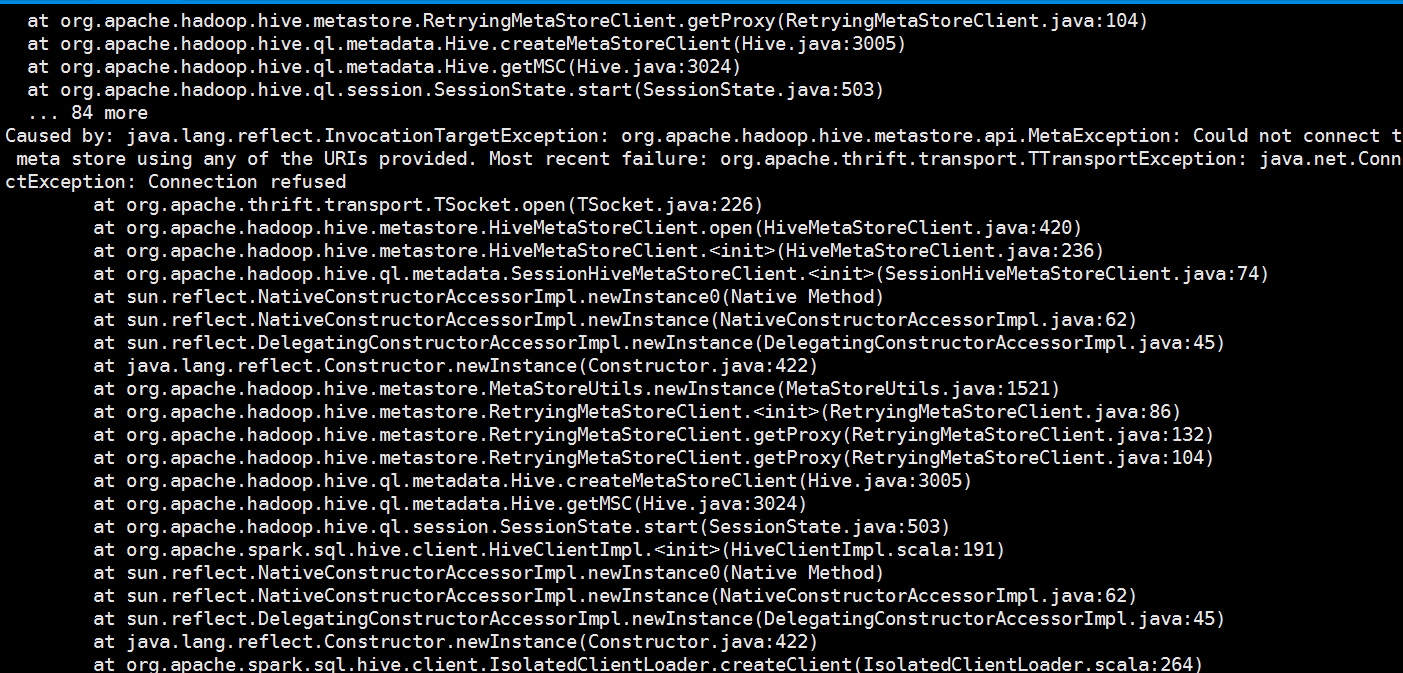
是因为我们前面配置了hive到spark sql 里面,我们先配回来(3个节点都修改)


再启动一下

我们输入代码

scala> import org.apache.spark.streaming._
import org.apache.spark.streaming._ scala> import org.apache.spark.streaming.StreamingContext._
import org.apache.spark.streaming.StreamingContext._ scala> val ssc = new StreamingContext(sc, Seconds())
ssc: org.apache.spark.streaming.StreamingContext = org.apache.spark.streaming.StreamingContext@431f8830 scala> val lines = ssc.socketTextStream("localhost", )
lines: org.apache.spark.streaming.dstream.ReceiverInputDStream[String] = org.apache.spark.streaming.dstream.SocketInputDStream@23f27434 scala> val words = lines.flatMap(_.split(" "))
words: org.apache.spark.streaming.dstream.DStream[String] = org.apache.spark.streaming.dstream.FlatMappedDStream@2c3df478 scala> val pairs = words.map(word => (word, ))
pairs: org.apache.spark.streaming.dstream.DStream[(String, Int)] = org.apache.spark.streaming.dstream.MappedDStream@6d3dc0c5 scala> val wordCounts = pairs.reduceByKey(_ + _)
wordCounts: org.apache.spark.streaming.dstream.DStream[(String, Int)] = org.apache.spark.streaming.dstream.ShuffledDStream@8fa4647 scala> wordCounts.print() scala>
最后启动一下服务发现报错了
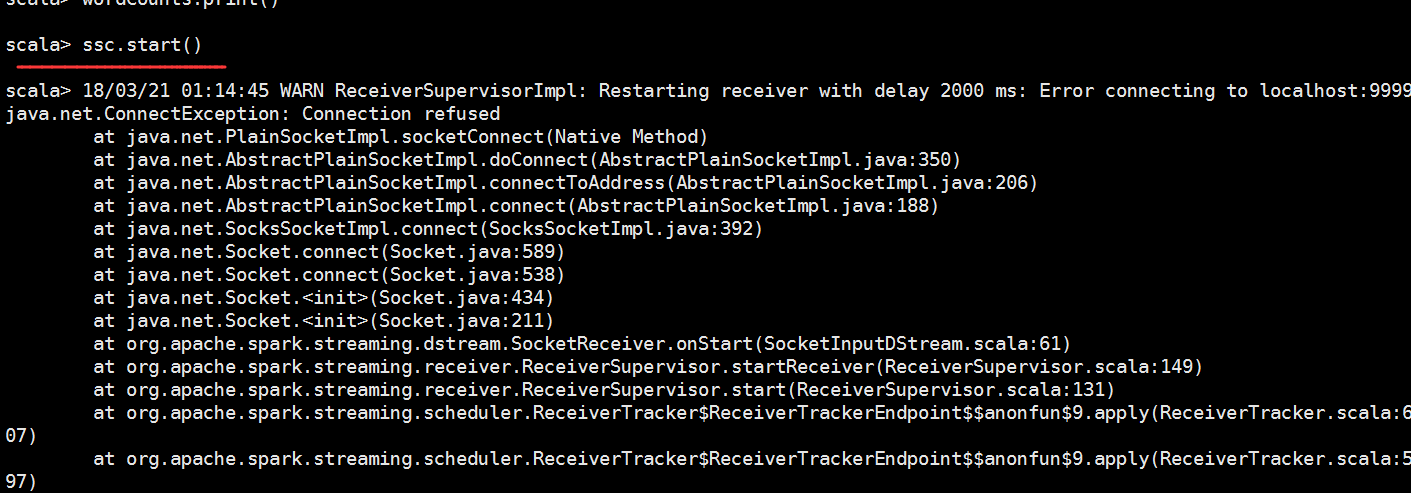
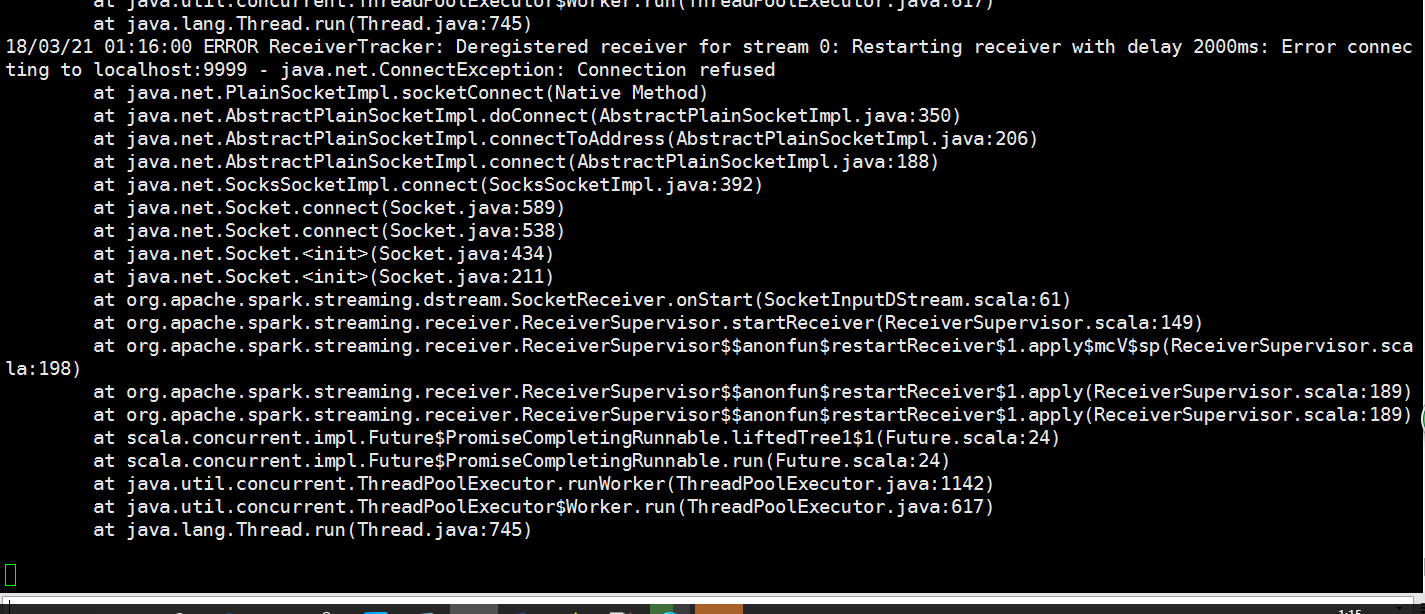
是因为没有启动nc
现在把他启动

我们敲进去一些数据


退出再启动一次

再次把代码放进来


我们在nc那边输入数据

回到这边看看结果

打开我们的idea



package com.spark.test import org.apache.spark.sql.SparkSession
import org.apache.spark.streaming._
import org.apache.spark.streaming.StreamingContext._
import org.apache.spark.{SparkConf, SparkContext}
object Test { def main(args: Array[String]): Unit = {
val spark= SparkSession
.builder
.master("local[2]")
.appName("HdfsTest")
.getOrCreate() val ssc = new StreamingContext(spark.sparkContext, Seconds());
val lines = ssc.socketTextStream("localhost", )
val words = lines.flatMap(_.split(" "))
}
}






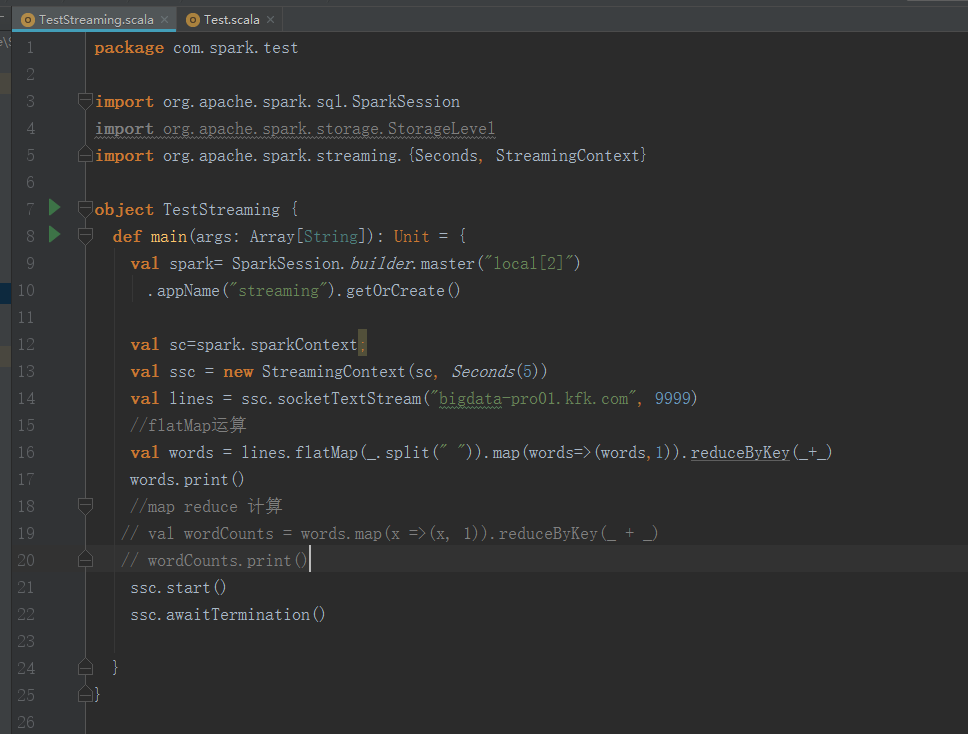
package com.spark.test import org.apache.spark.sql.SparkSession
import org.apache.spark.storage.StorageLevel
import org.apache.spark.streaming.{Seconds, StreamingContext} object TestStreaming {
def main(args: Array[String]): Unit = {
val spark= SparkSession.builder.master("local[2]")
.appName("streaming").getOrCreate() val sc=spark.sparkContext;
val ssc = new StreamingContext(sc, Seconds())
val lines = ssc.socketTextStream("bigdata-pro01.kfk.com", )
//flatMap运算
val words = lines.flatMap(_.split(" ")).map(words=>(words,)).reduceByKey(_+_)
words.print()
//map reduce 计算
// val wordCounts = words.map(x =>(x, 1)).reduceByKey(_ + _)
// wordCounts.print()
ssc.start()
ssc.awaitTermination() }
}



这个过程呢要这样操作,先把程序运行,再启动nc,再到nc界面输入单词

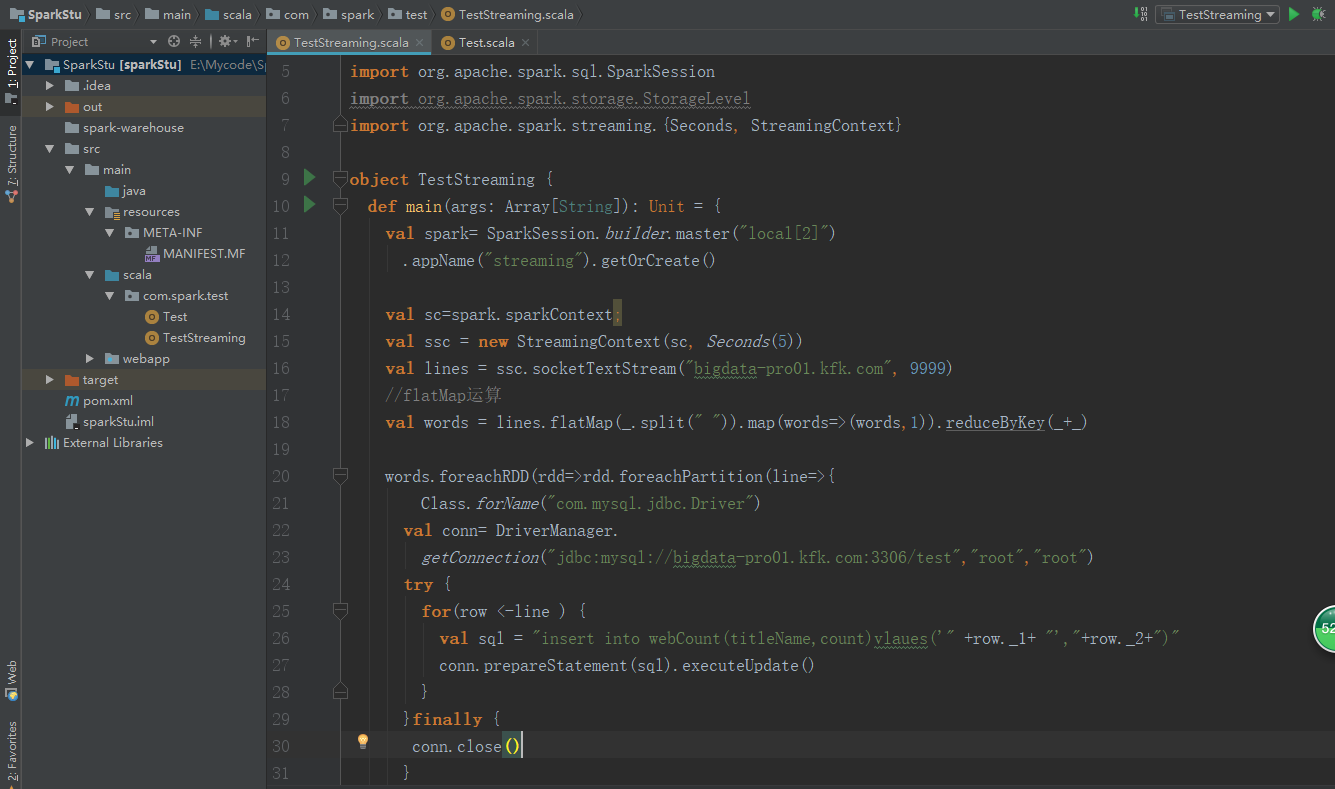
package com.spark.test import java.sql.DriverManager import org.apache.spark.sql.SparkSession
import org.apache.spark.storage.StorageLevel
import org.apache.spark.streaming.{Seconds, StreamingContext} object TestStreaming {
def main(args: Array[String]): Unit = {
val spark= SparkSession.builder.master("local[2]")
.appName("streaming").getOrCreate() val sc=spark.sparkContext;
val ssc = new StreamingContext(sc, Seconds())
val lines = ssc.socketTextStream("bigdata-pro01.kfk.com", )
//flatMap运算
val words = lines.flatMap(_.split(" ")).map(words=>(words,)).reduceByKey(_+_) words.foreachRDD(rdd=>rdd.foreachPartition(line=>{
Class.forName("com.mysql.jdbc.Driver")
val conn= DriverManager.
getConnection("jdbc:mysql://bigdata-pro01.kfk.com:3306/test","root","root")
try {
for(row <-line ) {
val sql = "insert into webCount(titleName,count)values('" +row._1+ "',"+row._2+")"
conn.prepareStatement(sql).executeUpdate()
}
}finally {
conn.close()
} })) words.print()
//map reduce 计算
// val wordCounts = words.map(x =>(x, 1)).reduceByKey(_ + _)
// wordCounts.print()
ssc.start()
ssc.awaitTermination() }
}

我们把代码拷进来

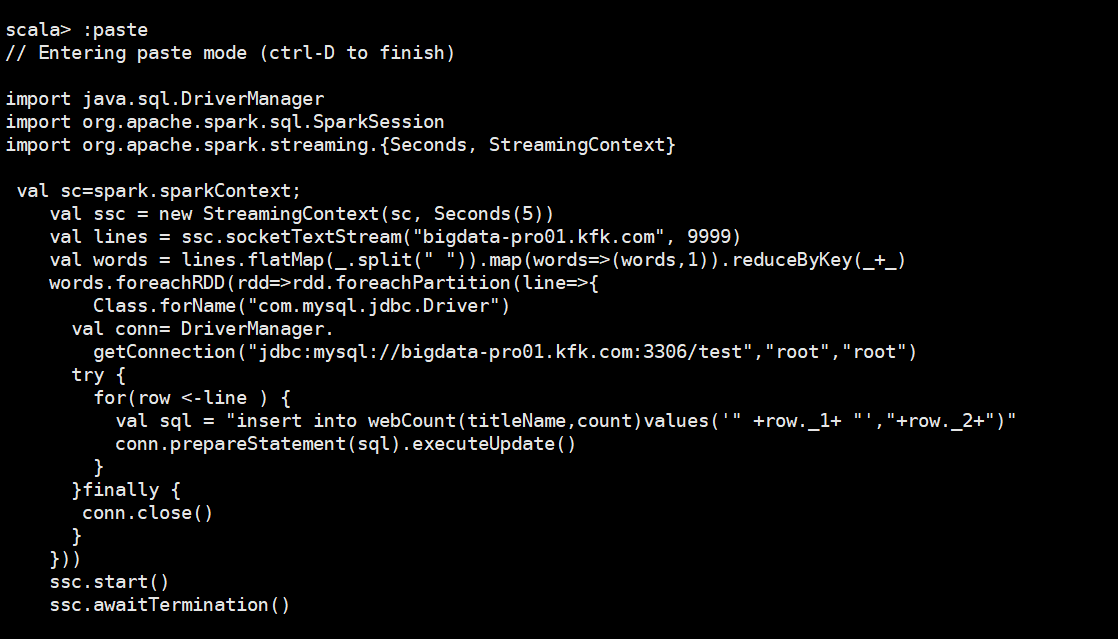
import java.sql.DriverManager
import org.apache.spark.sql.SparkSession
import org.apache.spark.streaming.{Seconds, StreamingContext} val sc=spark.sparkContext;
val ssc = new StreamingContext(sc, Seconds())
val lines = ssc.socketTextStream("bigdata-pro01.kfk.com", )
val words = lines.flatMap(_.split(" ")).map(words=>(words,)).reduceByKey(_+_)
words.foreachRDD(rdd=>rdd.foreachPartition(line=>{
Class.forName("com.mysql.jdbc.Driver")
val conn= DriverManager.
getConnection("jdbc:mysql://bigdata-pro01.kfk.com:3306/test","root","root")
try {
for(row <-line ) {
val sql = "insert into webCount(titleName,count)values('" +row._1+ "',"+row._2+")"
conn.prepareStatement(sql).executeUpdate()
}
}finally {
conn.close()
}
}))
ssc.start()
ssc.awaitTermination()
我们输入数据

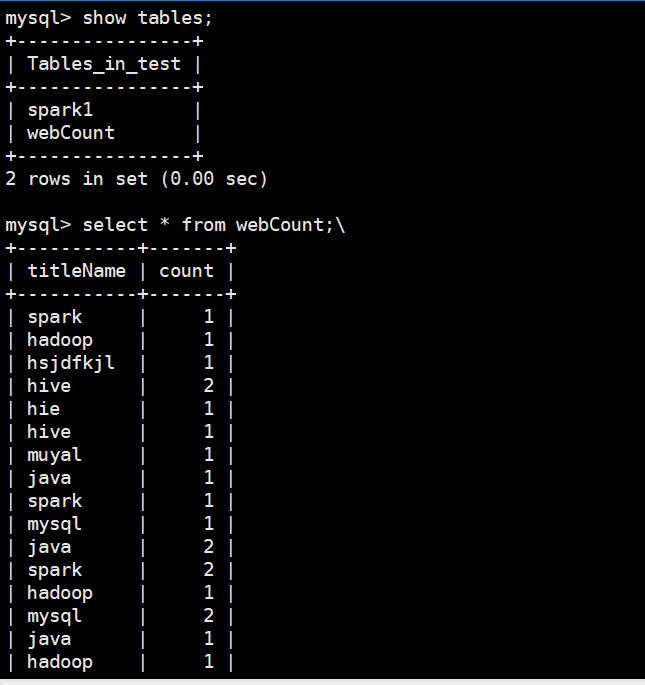
我们通过mysql查看一下表里面的数据
Spark Streaming实时数据分析的更多相关文章
- 新闻实时分析系统 Spark Streaming实时数据分析
1.Spark Streaming功能介绍1)定义Spark Streaming is an extension of the core Spark API that enables scalable ...
- 新闻网大数据实时分析可视化系统项目——19、Spark Streaming实时数据分析
1.Spark Streaming功能介绍 1)定义 Spark Streaming is an extension of the core Spark API that enables scalab ...
- Spark Streaming实时计算框架介绍
随着大数据的发展,人们对大数据的处理要求也越来越高,原有的批处理框架MapReduce适合离线计算,却无法满足实时性要求较高的业务,如实时推荐.用户行为分析等. Spark Streaming是建立在 ...
- 【Streaming】30分钟概览Spark Streaming 实时计算
本文主要介绍四个问题: 什么是Spark Streaming实时计算? Spark实时计算原理流程是什么? Spark 2.X下一代实时计算框架Structured Streaming Spark S ...
- 【转】Spark Streaming 实时计算在甜橙金融监控系统中的应用及优化
系统架构介绍 整个实时监控系统的架构是先由 Flume 收集服务器产生的日志 Log 和前端埋点数据, 然后实时把这些信息发送到 Kafka 分布式发布订阅消息系统,接着由 Spark Streami ...
- Spark练习之通过Spark Streaming实时计算wordcount程序
Spark练习之通过Spark Streaming实时计算wordcount程序 Java版本 Scala版本 pom.xml Java版本 import org.apache.spark.Spark ...
- 大数据Spark+Kafka实时数据分析案例
本案例利用Spark+Kafka实时分析男女生每秒购物人数,利用Spark Streaming实时处理用户购物日志,然后利用websocket将数据实时推送给浏览器,最后浏览器将接收到的数据实时展现, ...
- 【慕课网实战】Spark Streaming实时流处理项目实战笔记十六之铭文升级版
铭文一级: linux crontab 网站:http://tool.lu/crontab 每一分钟执行一次的crontab表达式: */1 * * * * crontab -e */1 * * * ...
- 【慕课网实战】Spark Streaming实时流处理项目实战笔记十五之铭文升级版
铭文一级:[木有笔记] 铭文二级: 第12章 Spark Streaming项目实战 行为日志分析: 1.访问量的统计 2.网站黏性 3.推荐 Python实时产生数据 访问URL->IP信息- ...
随机推荐
- pri 知识点
pri github:https://github.com/prijs/pri 添加路由后动态导入,使用的是 react-loadable:https://github.com/jamiebuilds ...
- dojo:如何显示ListBox风格的选择框
常见的选择框控件:Selelct.FilteringSelect和ComboBox都是下拉框风格,而不是ListBox风格. dojo还提供了一个dijit.form.MultiSelect控件可以解 ...
- apache的MultipartEntityBuilder文件上传
本文讲解多文件上传方法,不比较上传有几种方法和效率,而是定向分析apache的httpmime包的MultipartEntityBuilder类,源码包:httpmime-4.5.2.jar 一.常用 ...
- Go 并发控制--WaitGroup的使用
开发过程中,经常task之间的同步问题.例如,多个子task并发完成一部分任务,主task等待他们最后结束. 在Go语言,实现同步的一种方式就是WaitGroup. Example package m ...
- jsonp跨域设置cookie
html: <!DOCTYPE html> <html> <head> <meta charset="UTF-8"> <tit ...
- 使用Tesseract-OCR 进行文字识别
关于中文的识别,效果比较好而且开源的应该就是Tesseract-OCR了,所以自己亲身试用一下,分享到博客让有同样兴趣的人少走弯路. 文中所用到的身份证图片资源是百度找的,如有侵权可联系我删除. 一. ...
- jQuery位置操作
position();获取当前标签相对于最近一个父标签中有positon:relative属性的位置. height();标签纯高度 innerHeight();标签内边距padding加上纯高度 o ...
- WPF DataGrid 导出Excel
#region Excel导出 private void btnExportExcel_Click(object sender, RoutedEventArgs e) { Export(this.dg ...
- CEF中弹出窗口的处理
CEF开发如果不想在弹出窗口中打开网页,即想要在当前窗体加载目标Url, 就需要重写OnBeforePopup,它是属于CefLifeSpanHandler类中的. /*--cef(optional_ ...
- SQLServer数据库自增长标识列的更新修改操作
SQLServer数据库自增长标识列的更新修改操作方法在日常的sql server开发中,经常会用到Identity类型的标识列作为一个表结构的自增长编号.比如文章编号.记录序号等等.自增长的标识列的 ...