openstack的Host Aggregates和Availability Zones
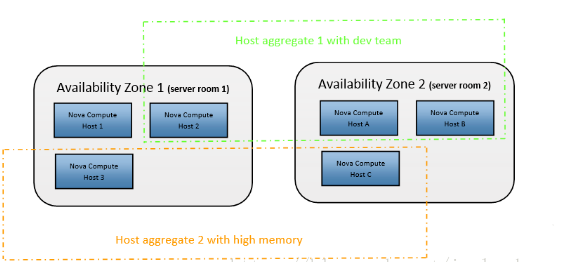
1、关系
/etc/nova/nova.conf
scheduler_default_filters=AggregateInstanceExtraSpecsFilter,其他filter
2、例子
此示例配置Compute服务以使用户能够请求具有固态驱动器(SSD)的节点。 您可以在nova可用域中创建fast-io主机集群,并将ssd = true键值对添加到该集群中。 然后,将node1和node2计算节点添加到该集群中。
$ nova aggregate-create fast-io nova
+----+---------+-------------------+-------+----------+
| Id | Name | Availability Zone | Hosts | Metadata |
+----+---------+-------------------+-------+----------+
| | fast-io | nova | | |
+----+---------+-------------------+-------+----------+
$ nova aggregate-set-metadata ssd=true
+----+---------+-------------------+-------+-------------------+
| Id | Name | Availability Zone | Hosts | Metadata |
+----+---------+-------------------+-------+-------------------+
| | fast-io | nova | [] | {u'ssd': u'true'} |
+----+---------+-------------------+-------+-------------------+
$ nova aggregate-add-host node1
+----+---------+-------------------+------------+-------------------+
| Id | Name | Availability Zone | Hosts | Metadata |
+----+---------+-------------------+------------+-------------------+
| | fast-io | nova | [u'node1'] | {u'ssd': u'true'} |
+----+---------+-------------------+------------+-------------------+
$ nova aggregate-add-host node2
+----+---------+-------------------+----------------------+-------------------+
| Id | Name | Availability Zone | Hosts | Metadata |
+----+---------+-------------------+----------------------+-------------------+
| | fast-io | nova | [u'node1', u'node2'] | {u'ssd': u'true'} |
+----+---------+-------------------+----------------------+-------------------+
使用nova flavor-create命令创建使用ID为6,8 GB的RAM,80GB的disk和4个vCPU的一个规格,名称为:ssd.large。
$ nova flavor-create ssd.large
+----+-----------+-----------+------+-----------+------+-------+-------------+-----------+
| ID | Name | Memory_MB | Disk | Ephemeral | Swap | VCPUs | RXTX_Factor | Is_Public |
+----+-----------+-----------+------+-----------+------+-------+-------------+-----------+
| | ssd.large | | | | | | 1.0 | True |
+----+-----------+-----------+------+-----------+------+-------+-------------+-----------+
创建flavor后,指定一个或多个键值对,让这些键值对与主机集群上的键值对匹配,范围为aggregate_instance_extra_specs。 在这种情况下,设置格式为:aggregate_instance_extra_specs:ssd = true键值对。
可以使用nova flavor-key命令在flavor上设置键值对。
nova flavor-key ssd.large set aggregate_instance_extra_specs:ssd=true
设置后,您应该看到ssd.large的extra_specs属性填充了ssd的键和相应的值true。
nova flavor-show ssd.large
+----------------------------+--------------------------------------------------+
| Property | Value |
+----------------------------+--------------------------------------------------+
| OS-FLV-DISABLED:disabled | False |
| OS-FLV-EXT-DATA:ephemeral | |
| disk | |
| extra_specs | {u'aggregate_instance_extra_specs:ssd': u'true'} |
| id | |
| name | ssd.large |
| os-flavor-access:is_public | True |
| ram | |
| rxtx_factor | 1.0 |
| swap | |
| vcpus | |
+----------------------------+--------------------------------------------------+
现在,当用户请求具有ssd.large规格的实例时,调度程序仅考虑具有ssd = true键值对的主机。 在此示例中,这些是node1和node2。因为node1和node2所的集群fast-io设置了属性{u'ssd': u'true'},使得与规格ssd.large里面的extra_specs的对应。
openstack的Host Aggregates和Availability Zones的更多相关文章
- Openstack关于Regions和Availability Zones
在AWS中有Region和Availability Zones的概念,并且在openstack中也实现了两者,只是不太容易看出来. 此文主要介绍他们的概念和关系,以及在openstack中的实现. 如 ...
- OpenStack G版以后的Availability Zone与Aggregate Hosts
关于Availability Zone与Aggregate Hosts的概念解析,可以参考这篇文章:http://blog.chinaunix.net/uid-20940095-id-3875022. ...
- [REP]AWS Regions and Availability Zones: the simplest explanation you will ever find around
When it comes to Amazon Web Services, there are two concepts that are extremely important and spanni ...
- openstack Icehouse发布
OpenStack 2014.1 (Icehouse) Release Notes General Upgrade Notes Windows packagers should use pbr 0.8 ...
- OpenStack 2014.1(Icehouse) 更新说明
OpenStack 2014.1(Icehouse) 更新说明 1.综合升级说明 Windows安装包应使用PBR 0.8版本,以避免发生bug1294246 log-config选项 ...
- Complex Instance Placement
转自: https://specs.openstack.org/openstack/openstack-user-stories/user-stories/proposed/complex-insta ...
- [转]Openstack Havana Dashboard测试和使用
转贴一篇陈沙克老师的文章:http://www.chenshake.com/openstack-havana-dashboard-to-test-and-use/ Openstack Havana D ...
- nova availability zone
find a bug: at first there is only one zone. create aggregate host1 in zone1 create aggregate host1 ...
- 转-4年!我对OpenStack运维架构的总结
4年!我对OpenStack运维架构的总结 原创: 徐超 云技术之家 今天 前言 应“云技术社区”北极熊之邀,写点东西.思来想去云计算范畴实在广泛,自然就聊点最近话题异常火热,让广大云计算从业者爱之深 ...
随机推荐
- 项目总结02:百度地图js 基本用法介绍
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN" "http://www.w3.org/ ...
- SpringBoot08 请求方式、参数获取注解、参数验证、前后台属性名不一致问题、自定义参数验证注解、BeanUtils的使用
1 请求方式 在定义一个Rest接口时通常会利用GET.POST.PUT.DELETE来实现数据的增删改查:这几种方式有的需要传递参数,后台开发人员必须对接收到的参数进行参数验证来确保程序的健壮性 1 ...
- 本地DNS解析
企业搭配本地域名,进行解析 2018年07月23日 09:31:46 阅读数:2 搭建dns服务器,可以进行域名解析,这样方便企业项目本地测试. 可以实现,输入域名访问本地服务器 一.安装软件 1.下 ...
- mysql中left join设置条件在on与where时的区别
一.首先我们准备两张表来进行测试. CREATE TABLE `a` ( `id` int(11) unsigned NOT NULL AUTO_INCREMENT COMMENT 'ID', `na ...
- 8P - 钱币兑换问题
在一个国家仅有1分,2分,3分硬币,将钱N兑换成硬币有很多种兑法.请你编程序计算出共有多少种兑法. Input 每行只有一个正整数N,N小于32768. Output 对应每个输入,输出兑换方法数. ...
- PAT 1089 狼人杀-简单版(20 分)(代码+测试点分析)
1089 狼人杀-简单版(20 分) 以下文字摘自<灵机一动·好玩的数学>:"狼人杀"游戏分为狼人.好人两大阵营.在一局"狼人杀"游戏中,1 号玩家 ...
- BZOJ1084或洛谷2331 [SCOI2005]最大子矩阵
BZOJ原题链接 洛谷原题链接 注意该题的子矩阵可以是空矩阵,即可以不选,答案的下界为\(0\). 设\(f[i][j][k]\)表示前\(i\)行选择了\(j\)个子矩阵,选择的方式为\(k\)时的 ...
- Spring 中的类加载机制 - ClassLoader
Spring 中的类加载机制 - ClassLoader Spring 系列目录(https://www.cnblogs.com/binarylei/p/10198698.html) ClassLoa ...
- [Spark]Spark章1 Spark架构浅析
Spark架构 Spark架构采用了分布式计算中的Master-Slave模型.集群中运行Master进程的节点称为Master,同样,集群中含有Worker进程的节点为Slave.Master负责控 ...
- HTML 学习杂记
代码范例 <?php function testFunc1 () { echo 'testFunc1'; } $b = ; ?> <!DOCTYPE html PUBLIC &quo ...