pyspider爬取数据存入es--2.测试数据库连通性
写一个简单案例测试能否将数据写入es
#!/usr/bin/env python
# -*- encoding: utf-8 -*-
# Created on 2017-10-27 08:35:57
# Project: es_test from pyspider.libs.base_handler import *
from elasticsearch import Elasticsearch class Handler(BaseHandler):
crawl_config = {
} def __init__(self):
self.index = 1 @every(minutes=24 * 60)
def on_start(self):
es = Elasticsearch("ip")
for num in range(1,5):
es.index(index="my-index", doc_type="test-type",id=self.index,
body={
"any": "data01"
})
self.index += 1
es = Elasticsearch() 方法默认连接本地9200端口,需要本地安装es并启动;如果需要连接远程es数据库,可以这样
es = Elasticsearch("ip")
查看一下es中是否已有数据:
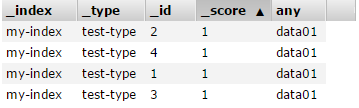
pyspider爬取数据存入es--2.测试数据库连通性的更多相关文章
- pyspider爬取数据存入mysql--2.测试数据库能否连通
做一个简单的测试,看数据能否存入mysql 1 #!/usr/bin/env python 2 # -*- encoding: utf-8 -*- 3 # Created on 2017-10-26 ...
- pyspider爬取数据存入redis--2.测试数据库连通性
直接上代码 #!/usr/bin/env python # -*- encoding: utf-8 -*- # Created on 2017-10-27 09:56:50 # Project: re ...
- pyspider爬取数据存入es--1.安装驱动
跟使用mysql一样,不安装es驱动的话,也会触发模块找不到的错误 ImportError: No module named elasticsearch 通过pip安装 pip install ela ...
- pyspider爬取数据存入redis--1.安装驱动
首先安装pyredis的驱动 wget https://pypi.python.org/packages/source/r/redis/redis-2.9.1.tar.gz 解压并cd python ...
- Python使用Scrapy框架爬取数据存入CSV文件(Python爬虫实战4)
1. Scrapy框架 Scrapy是python下实现爬虫功能的框架,能够将数据解析.数据处理.数据存储合为一体功能的爬虫框架. 2. Scrapy安装 1. 安装依赖包 yum install g ...
- pyspider爬取数据导入mysql--1.安装驱动
接上篇,刚装好的pyspider,我们打算大显身手,抓一批数据到mysql中. 然而,出师未捷,提示我们:ImportError: No module named MySQLdb 这是因为还没有安装M ...
- 关于js渲染网页时爬取数据的思路和全过程(附源码)
于js渲染网页时爬取数据的思路 首先可以先去用requests库访问url来测试一下能不能拿到数据,如果能拿到那么就是一个普通的网页,如果出现403类的错误代码可以在requests.get()方法里 ...
- scrapy爬取数据的基本流程及url地址拼接
说明:初学者,整理后方便能及时完善,冗余之处请多提建议,感谢! 了解内容: Scrapy :抓取数据的爬虫框架 异步与非阻塞的区别 异步:指的是整个过程,中间如果是非阻塞的,那就是异步 ...
- 借助Chrome和插件爬取数据
工具 Chrome浏览器 TamperMonkey ReRes Chrome浏览器 chrome浏览器是目前最受欢迎的浏览器,没有之一,它兼容大部分的w3c标准和ecma标准,对于前端工程师在开发过程 ...
随机推荐
- 撩课-Web大前端每天5道面试题-Day33
1.CommonJS 中的 require/exports 和 ES6 中的 import/export 区别? CommonJS 模块的重要特性是加载时执行, 即脚本代码在 require 的时候, ...
- 在mysql中RIGHT JOIN与group by一起使用引起的一个大bug
本来按理说这个小问题不值得写一个博客的,不过正是这个小问题造成了一个大bug. 本来每月对数据都好好的,但是这一两天突然发现许多数据明显不对,这一块的代码和sql有些不是我写的,不过出现了bug,还是 ...
- Go 语言相关的优秀框架,库及软件列表
If you see a package or project here that is no longer maintained or is not a good fit, please submi ...
- CentOS7部署Django项目
1. 云服务器 这里使用的是腾讯云选择系统:CentOS7.3 记住云服务器登录密码 2. 配置Python3环境 默认Python环境为python2.7,yum安装是需要python2的环境的 安 ...
- HTTPS的安全性
一.Https介绍 1. 什么是Https HTTPS(全称:Hypertext Transfer Protocol over Secure Socket Layer),是以安全为目标的HTTP通道, ...
- 基于react的标准form+table页面的请求流程图
componentDidMount直接走handleSearch而不走loadData,是为了当form有默认初始值的时候也能适用! --------------------2018.2.7新增--- ...
- 编译64位cu文件的设置
作者:朱金灿 来源:http://blog.csdn.net/clever101 CUDA(ComputeUnified Device Architecture),是显卡厂商NVIDIA推出的运 ...
- ActiveReports 报表应用教程 (12)---交互式报表之贯穿钻取
在葡萄城ActiveReports报表中提供强大的数据分析能力,您可以通过图表.表格.图片.列表.波形图等控件来实现数据的贯穿钻取,在一级报表中可以通过鼠标点击来钻取更为详细的数据. 本文展示的是20 ...
- hadoop中实现java网络爬虫
这一篇网络爬虫的实现就要联系上大数据了.在前两篇java实现网络爬虫和heritrix实现网络爬虫的基础上,这一次是要完整的做一次数据的收集.数据上传.数据分析.数据结果读取.数据可视化. 需要用到 ...
- 分享今天在客户那里遇到的SQLSERVER连接超时以及我的解决办法
分享今天在客户那里遇到的SQLSERVER连接超时以及我的解决办法 客户的环境:SQLSERVER2005,WINDOWS2003 SP2 32位 这次发生连接超时的时间是2013-8-5 21: ...