Elasticsearch Java Rest Client API 整理总结 (三)——Building Queries
上篇回顾
子曰,温故而知新,可以为师也。学习的过程就是不断的回顾,总结,总结,再总结。首先,一起来回顾下上篇 search API中的内容。
为了能够更透彻的理解 rest client search API 的使用,我专门整理了相关对象之间的关系图,一起来看下。
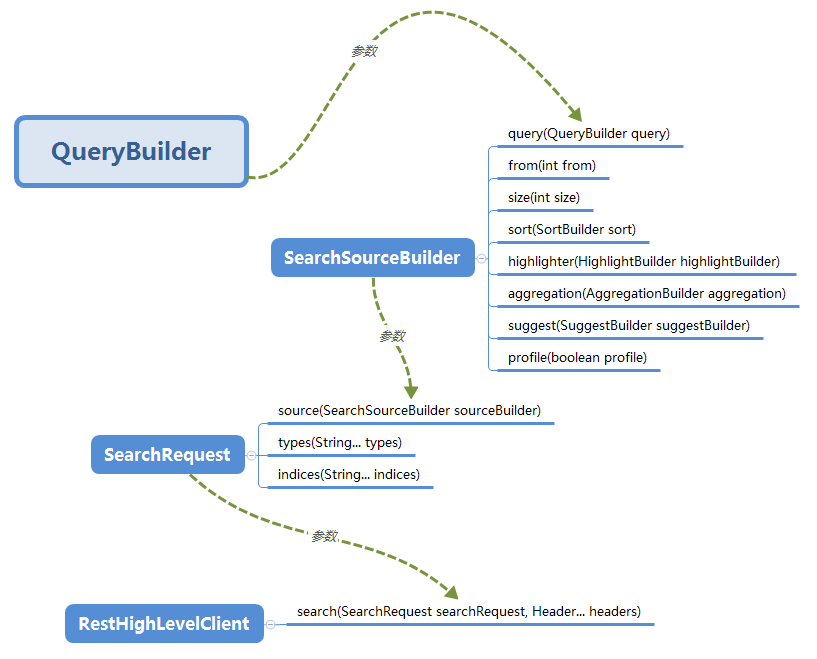
由上图看出, QueryBuilder 是整个查询操作的核心,决定了查询什么样的数据和期望得到什么结果这些核心的问题。
QueryBuilder 只是一个接口,需要具体的实体类才可以。那么如何创建 QueryBuilder 的实例呢?有两种方式
- 通过
QueryBuilder实现类的构造函数 - 使用
QueryBuilders工具类创建
Building Queries
下面就来看下常用的查询及其 API 有哪些
匹配所有的查询
查询语句如下
GET /_search
{
"query": {
"match_all": {}
}
}
对应的 QueryBuilder Class 为 MatchAllQueryBuilder
具体方法为 QueryBuilders.matchAllQuery()
全文查询 Full Text Queries
什么是全文查询?
像使用 match 或者 query_string 这样的高层查询都属于全文查询,
- 查询 日期(
date) 或整数(integer) 字段,会将查询字符串分别作为日期或整数对待。 - 查询一个(
not_analyzed)未分析的精确值字符串字段,会将整个查询字符串作为单个词项对待。 - 查询一个(
analyzed)已分析的全文字段,会先将查询字符串传递到一个合适的分析器,然后生成一个供查询的词项列表
组成了词项列表,后面就会对每个词项逐一执行底层查询,将查询结果合并,并且为每个文档生成最终的相关度评分。
Match
match 查询的单个词的步骤是什么?
- 检查字段类型,查看字段是
analyzed,not_analyzed - 分析查询字符串,如果只有一个单词项,
match查询在执行时就会是单个底层的term查询 - 查找匹配的文档,会在倒排索引中查找匹配文档,然后获取一组包含该项的文档
- 为每个文档评分
构建 Match 查询
match 查询可以接受 text/numeric/dates 格式的参数,分析,并构建一个查询。
GET /_search
{
"query": {
"match" : {
"message" : "this is a test"
}
}
}
上面的实例中 message 是一个字段名。
对应的 QueryBuilder class : MatchQueryBuilder
具体方法 : QueryBuilders.matchQuery()
全文查询 API 列表
全部的 API 列表如下(链接均指向 elasticsearch 官网)
基于词项的查询
这种类型的查询不需要分析,它们是对单个词项操作,只是在倒排索引中查找准确的词项(精确匹配)并且使用 TF/IDF 算法为每个包含词项的文档计算相关度评分 _score。
Term
term 查询可用作精确值匹配,精确值的类型则可以是数字,时间,布尔类型,或者是那些 not_analyzed 的字符串。
对应的 QueryBuilder class 是TermQueryBuilder
具体方法是 QueryBuilders.termQuery()
Terms
terms 查询允许指定多个值进行匹配。如果这个字段包含了指定值中的任何一个值,就表示该文档满足条件。
对应的 QueryBuilder class 是 TermsQueryBuilder
具体方法是 QueryBuilders.termsQuery()
Wildcard
wildcard 通配符查询是一种底层基于词的查询,它允许指定匹配的正则表达式。而且它使用的是标准的 shell 通配符查询:
?匹配任意字符*匹配 0 个或多个字符
wildcard 需要扫描倒排索引中的词列表才能找到所有匹配的词,然后依次获取每个词相关的文档 ID。
由于通配符和正则表达式只能在查询时才能完成,因此查询效率会比较低,在需要高性能的场合,应当谨慎使用。
对应的 QueryBuilder class 是 WildcardQueryBuilder
具体方法是 QueryBuilders.wildcardQuery()
基于词项 API 列表
复合查询
什么是复合查询?
复合查询会将其他的复合查询或者叶查询包裹起来,以嵌套的形式展示和执行,得到的结果也是对各个子查询结果和分数的合并。可以分为下面几种:
-
经常用在使用 filter 的场合,所有匹配的文档分数都是一个不变的常量
-
可以将多个叶查询和组合查询再组合起来,可接受的参数如下
- must : 文档必须匹配这些条件才能被包含进来
must_not文档必须不匹配才能被包含进来should如果满足其中的任何语句,都会增加分数;即使不满足,也没有影响filter以过滤模式进行,不评分,但是必须匹配
-
叫做分离最大化查询,它会将任何与查询匹配的文档都作为结果返回,但是只是将其中最佳匹配的评分作为最终的评分返回。
-
允许为每个与主查询匹配的文档应用一个函数,可用来改变甚至替换原始的评分
-
用来控制(提高或降低)复合查询中子查询的权重。
复合查询列表
特殊查询
Wrapper Query
这里比较重要的一个是 Wrapper Query,是说可以接受任何其他 base64 编码的字符串作为子查询。
主要应用场合就是在 Rest High-Level REST client 中接受 json 字符串作为参数。比如使用 gson 等 json 库将要查询的语句拼接好,直接塞到 Wrapper Query 中查询就可以了,非常方便。
Wrapper Query 对应的 QueryBuilder class 是WrapperQueryBuilder
具体方法是 QueryBuilders.wrapperQuery()
小结
本文对 elasticsearch rest high client 中的查询构建进行了总结和整理,对常用的 API 做了简要的介绍。读者如果要查看完整的构建查询的 API 列表,可参考此处
参考文档
系列文章列表
- Elasticsearch Java Rest Client API 整理总结 (一)——Document API
- Elasticsearch Java Rest Client API 整理总结 (二) —— SearchAPI
- Elasticsearch Java Rest Client API 整理总结 (三)——Building Queries
Elasticsearch Java Rest Client API 整理总结 (三)——Building Queries的更多相关文章
- Elasticsearch Java Rest Client API 整理总结 (二) —— SearchAPI
目录 引言 Search APIs Search API Search Request 可选参数 使用 SearchSourceBuilder 构建查询条件 指定排序 高亮请求 聚合请求 建议请求 R ...
- Elasticsearch Java Rest Client API 整理总结 (一)——Document API
目录 引言 概述 High REST Client 起步 兼容性 Java Doc 地址 Maven 配置 依赖 初始化 文档 API Index API GET API Exists API Del ...
- Elasticsearch Java Rest Client API 整理总结 (一)
http://www.likecs.com/default/index/show?id=39549
- Elasticsearch Java Rest Client简述
ESJavaClient的历史 JavaAPI Client 优势:基于transport进行数据访问,能够使用ES集群内部的性能特性,性能相对好 劣势:client版本需要和es集群版本一致,数据序 ...
- Java REST Client API
https://www.elastic.co/guide/en/elasticsearch/client/java-rest/7.3/java-rest-high-supported-apis.htm ...
- Java基础知识➣集合整理(三)
概述 集合框架是一个用来代表和操纵集合的统一架构.所有的集合框架都包含如下内容: 接口:是代表集合的抽象数据类型.接口允许集合独立操纵其代表的细节.在面向对象的语言,接口通常形成一个层次. 实现(类) ...
- Docker Client (another java docker client api)
前一篇提到了docker-java,这里介绍另一个docker client 库,Docker Client 版本兼容 兼容17.03.1~ce - 17.12.1~ce (点 [here][1]查看 ...
- elasticSearch Java Spring Data Api
1. BoolQueryBuilder qb=QueryBuilders. boolQuery(); qb.should(QueryBuilders.matchQuery("keyWord& ...
- Elasticsearch Java API 很全的整理
Elasticsearch 的API 分为 REST Client API(http请求形式)以及 transportClient API两种.相比来说transportClient API效率更高, ...
随机推荐
- 最近用到的 sql 统计操作
统计操作 1.分组统计group by select id,name,count(*) as '总数' from test1 group by id,name --group by 分组 ...
- 【gp数据库】你一定会用到的运维语句宝典
-- 查询未空闲的进程信息 select * from pg_stat_activity where current_query<>'<IDLE>'; 结果可查看数据库名,进程 ...
- MySQL应用架构优化-实时数据处理
1.1. 场景 在和开发人员做优化的时候,讨论最多的应该是结合应用场景编写出合适的SQL.并培训开发应该如何编写SQL让MySQL的性能尽量好.但是有一些的场景对于SQL的优化是行不通的. 打个比方, ...
- 第五次作业 hql查询
hql查询是基于对象的查询,不是基于表的查询. 1.hql的简单查询 @Test public void queryUsers() { //简单查询 SessionFactory sf = null; ...
- IE 8 下sharepoint 2013 难看的字体的解决方案
将 corev15.css 中的有关"Segoe UI","Segoe",Tahoma,移除即可. 一共二处 C:\Program Files\Common F ...
- cJSON 使用详解
由于c语言中,没有直接的字典,字符串数组等数据结构,所以要借助结构体定义,处理json.如果有对应的数据结构就方便一些, 如python中用json.loads(json)就把json字符串转变为内建 ...
- 抓取js动态生成的数据分析案例
需求:爬取https://www.xuexi.cn/f997e76a890b0e5a053c57b19f468436/018d244441062d8916dd472a4c6a0a0b.html页面中的 ...
- 8、Django的模型层(2)
第3节:多表操作 3.1 创建模型 实例:我们来假定下面这些概念,字段和关系 作者模型:一个作者有姓名和年龄. 作者详细模型:把作者的详情放到详情表,包含生日,手机号,家庭住址等信息.作者详情模型和作 ...
- BZOJ3673/3674:可持久化并查集
Description n个集合 m个操作 操作: 1 a b 合并a,b所在集合 2 k 回到第k次操作之后的状态(查询算作操作) 3 a b 询问a,b是否属于同一集合,是则输出1否则输出0 0& ...
- 为什么重写equals必须重写hashcode?
示例代码: class User { private String name; public User(String name) { this.name = name; } @Override pub ...