【机器学习】EM算法详细推导和讲解
今天不太想学习,炒个冷饭,讲讲机器学习十大算法里有名的EM算法,文章里面有些个人理解,如有错漏,还请读者不吝赐教。
众所周知,极大似然估计是一种应用很广泛的参数估计方法。例如我手头有一些东北人的身高的数据,又知道身高的概率模型是高斯分布,那么利用极大化似然函数的方法可以估计出高斯分布的两个参数,均值和方差。这个方法基本上所有概率课本上都会讲,我这就不多说了,不清楚的请百度。
然而现在我面临的是这种情况,我手上的数据是四川人和东北人的身高合集,然而对于其中具体的每一个数据,并没有标定出它来自“东北人”还是“四川人”,我想如果把这个数据集的概率密度画出来,大约是这个样子:

好了不要吐槽了,能画成这个样子我已经很用心了= =
其实这个双峰的概率密度函数是有模型的,称作高斯混合模型(GMM),写作:

话说往博客上加公式真是费劲= =这模型很好理解,就是k个高斯模型加权组成,α是各高斯分布的权重,Θ是参数。对GMM模型的参数估计,就要用EM算法。更一般的讲,EM算法适用于带有隐变量的概率模型的估计,什么是隐变量呢?就是观测不到的变量,对于上面四川人和东北人的例子,对每一个身高而言,它来自四川还是东北,就是一个隐变量。
为什么要用EM,我们来具体考虑一下上面这个问题。如果使用极大似然估计——这是我们最开始最单纯的想法,那么我们需要极大化的似然函数应该是这个:

然而我们并不知道p(x;θ)的表达式,有同学说我知道啊,不就是上面那个混个高斯模型?不就是参数多一点麽。
仔细想想,GMM里的θ可是由四川人和东北人两部分组成哟,假如你要估计四川人的身高均值,直接用GMM做似然函数,会把四川人和东北人全考虑进去,显然不合适。
另一个想法是考虑隐变量,如果我们已经知道哪些样本来自四川,哪些样本来自东北,那就好了。用Z=0或Z=1标记样本来自哪个总体,则Z就是隐变量,需要最大化的似然函数就变为:
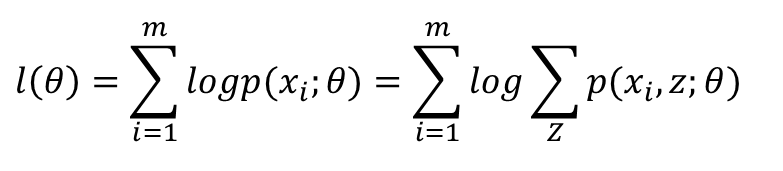
然而并没有卵用,因为隐变量确实不知道。要估计一个样本是来自四川还是东北,我们就要有模型参数,要估计模型参数,我们首先要知道一个样本是来自四川或东北的可能性...
到底是鸡生蛋,还是蛋生鸡?
不闹了,我们的方法是假设。首先假设一个模型参数θ,然后每个样本来自四川/东北的概率p(zi)就能算出来了,p(xi,zi)=p(xi|zi)p(zi),而x|z=0服从四川人分布,x|z=1服从东北人分布,所以似然函数可以写成含有θ的函数,极大化它我们可以得到一个新的θ。新的θ因为考虑了样本来自哪个分布,会比原来的更能反应数据规律。有了这个更好的θ我们再对每个样本重新计算它来自四川和东北的概率,用更好的θ算出来的概率会更准确,有了更准确的信息,我们可以继续像上面一样估计θ,自然而然这次得到的θ会比上一次更棒,如此蒸蒸日上,直到收敛(参数变动不明显了),理论上,EM算法就说完了。
然而事情并没有这么简单,上面的思想理论上可行,实践起来不成。主要是因为似然函数有“和的log”这一项,log里面是一个和的形式,一求导这画面不要太美,直接强来你要面对 “两个正态分布的概率密度函数相加”做分母,“两个正态分布分别求导再相加”做分子的分数形式。m个这玩意加起来令它等于0,要求出关于θ的解析解,你对自己的数学水平想的不要太高。
怎么办?先介绍一个不等式,叫Jensen不等式,是这样说的:
X是一个随机变量,f(X)是一个凸函数(二阶导数大或等于0),那么有:

当且仅当X是常数的时候等号成立
如果f(X)是凹函数,不等号反向
关于这个不等式,我既不打算证明,也不打算说明,希望你承认它正确就好。
半路杀出一个Jensen不等式,要用它解决上面的困境也是应有之义,不然说它做什么。直接最大化似然函数做不到,那么如果我们能找到似然函数的一个紧的下界一直优化它,并保证每次迭代能够使总的似然函数一直增大,其实也是一样的。怎么说?画个图你就明白了:
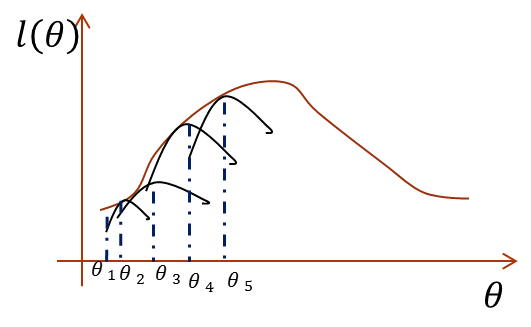
图画的不好,多见谅。横坐标是参数,纵坐标是似然函数,首先我们初始化一个θ1,根据它求似然函数一个紧的下界,也就是图中第一条黑短线,黑短线上的值虽然都小于似然函数的值,但至少有一点可以满足等号(所以称为紧下界),最大化小黑短线我们就hit到至少与似然函数刚好相等的位置,对应的横坐标就是我们的新的θ2,如此进行,只要保证随着θ的更新,每次最大化的小黑短线值都比上次的更大,那么算法收敛,最后就能最大化到似然函数的极大值处。
构造这个小黑短线,就要靠Jensen不等式。注意我们这里的log函数是个凹函数,所以我们使用的Jensen不等式的凹函数版本。根据Jensen函数,需要把log里面的东西写成一个数学期望的形式,注意到log里的和是关于隐变量Z的和,于是自然而然,这个数学期望一定是和Z有关,如果设Q(z)是Z的分布函数,那么可以这样构造:
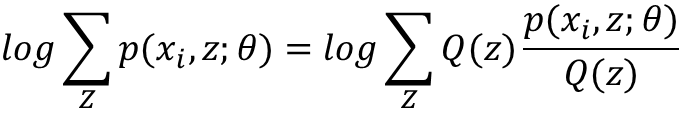
这几句公式比较多,我不一一敲了,直接把我PPT里的内容截图过来:
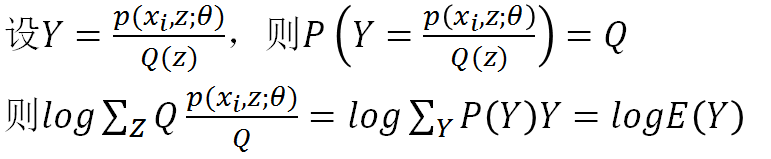
所以log里其实构造了一个随机变量Y,Y是Z的函数,Y取p/Q的值的概率是Q,这点说的很清楚了。
构造好数学期望,下一步根据Jensen不等式进行放缩:

有了这一步,我们看一下整个式子:

也就是说我们找到了似然函数的一个下界,那么优化它是否就可以呢?不是的,上面说了必须保证这个下界是紧的,也就是至少有点能使等号成立。由Jensen不等式,等式成立的条件是随机变量是常数,具体到这里,就是:

又因为Q(z)是z的分布函数,所以:
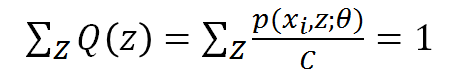
把C乘过去,可得C就是p(xi,z)对z求和,所以我们终于知道了:
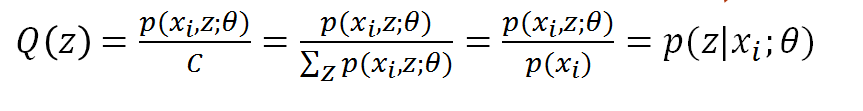
得到Q(z),大功告成,Q(z)就是p(zi|xi),或者写成p(zi),都是一回事,代表第i个数据是来自zi的概率。
于是EM算法出炉,它是这样做的:
首先,初始化参数θ
(1)E-Step:根据参数θ计算每个样本属于zi的概率,即这个身高来自四川或东北的概率,这个概率就是Q
(2)M-Step:根据计算得到的Q,求出含有θ的似然函数的下界并最大化它,得到新的参数θ
重复(1)和(2)直到收敛,可以看到,从思想上来说,和最开始没什么两样,只不过直接最大化似然函数不好做,曲线救国而已。
至于为什么这样的迭代会保证似然函数单调不减,即EM算法的收敛性证明,我就先不写了,以后有时间再考虑补。需要额外说明的是,EM算法在一般情况是收敛的,但是不保证收敛到全局最优,即有可能进入局部的最优。EM算法在混合高斯模型,隐马尔科夫模型中都有应用,是著名的数据挖掘十大算法之一。
就酱~有什么错漏和不同见解欢迎留言评论,我的推导和思路整理和网上的其他并不是完全相同,见仁见智吧~
【机器学习】EM算法详细推导和讲解的更多相关文章
- 机器学习-EM算法笔记
EM算法也称期望最大化(Expectation-Maximum,简称EM)算法,它是一个基础算法,是很多机器学习领域算法的基础,比如隐式马尔科夫算法(HMM), LDA主题模型的变分推断,混合高斯模型 ...
- EM算法简易推导
EM算法推导 网上和书上有关于EM算法的推导,都比较复杂,不便于记忆,这里给出一个更加简短的推导,用于备忘. 在不包含隐变量的情况下,我们求最大似然的时候只需要进行求导使导函数等于0,求出参数即可.但 ...
- 转载:EM算法的最精辟讲解
机器学习十大算法之一:EM算法.能评得上十大之一,让人听起来觉得挺NB的.什么是NB啊,我们一般说某个人很NB,是因为他能解决一些别人解决不了的问题.神为什么是神,因为神能做很多人做不了的事.那么EM ...
- 机器学习-EM算法-pLSA模型笔记
pLSA模型--基于概率统计的pLSA模型(probabilistic Latent Semantic Analysis,概率隐语义分析),增加了主题模型,形成简单的贝叶斯网络,可以使用EM算法学习模 ...
- 机器学习——EM算法与GMM算法
目录 最大似然估计 K-means算法 EM算法 GMM算法(实际是高斯混合聚类) 中心思想:①极大似然估计 ②θ=f(θold) 此算法非常老,几乎不会问到,但思想很重要. EM的原理推导还是蛮复杂 ...
- 机器学习——EM算法
1 数学基础 在实际中,最小化的函数有几个极值,所以最优化算法得出的极值不确实是否为全局的极值,对于一些特殊的函数,凸函数与凹函数,任何局部极值也是全局极致,因此如果目标函数是凸的或凹的,那么优化算法 ...
- EM算法以及推导
EM算法 Jensen不等式 其实Jensen不等式正是我们熟知的convex函数和concave函数性质,对于convex函数,有 \[ \lambda f(x) + (1-\lambda)f(y) ...
- EM算法-完整推导
前篇已经对EM过程,举了扔硬币和高斯分布等案例来直观认识了, 目标是参数估计, 分为 E-step 和 M-step, 不断循环, 直到收敛则求出了近似的估计参数, 不多说了, 本篇不说栗子, 直接来 ...
- 机器学习-EM算法
最大期望算法 EM算法的正式提出来自美国数学家Arthur Dempster.Nan Laird和Donald Rubin,其在1977年发表的研究对先前出现的作为特例的EM算法进行了总结并给出了标准 ...
随机推荐
- npm 包 升降版本
今天用vue-awesome-swiper最新版本遇到些问题,需要调整到2.6.7版本.记录以下. 查看vue-awesome-swiper版本 npm list vue-awesome-swiper ...
- underscore.js源码研究(4)
概述 很早就想研究underscore源码了,虽然underscore.js这个库有些过时了,但是我还是想学习一下库的架构,函数式编程以及常用方法的编写这些方面的内容,又恰好没什么其它要研究的了,所以 ...
- 安卓Dialog对话框多次显示而闪退的解决办法
事情是这样子的,我在一个活动中自定义了一个AlertDialog,通过一个按钮点击即可弹出,而后来出现的情况是,第一次点击就没问题, 正常跳出,而第二次就直接程序闪退,然后报The specified ...
- [原创]Base32加密解密工具
工具: Base32_Decode编译: VS2012 C# (.NET Framework v2.0)组织: K8搞基大队[K8team]作者: K8拉登哥哥博客: http://qqhack8. ...
- 06-01 Java 二维数组格式、二维数组内存图解、二维数组操作
二维数组格式1 /* 二维数组:就是元素为一维数组的一个数组. 格式1: 数据类型[][] 数组名 = new 数据类型[m][n]; m:表示这个二维数组有多少个一维数组. n:表示每一个一维数组的 ...
- odoo开发笔记--工作流
虽然odoo10里边取消了工作流 Odoo Workflow http://www.jeffzhang.cn/Odoo-Workflow-Notes/
- (转)【学习笔记】通过netstat+rmsock查找AIX端口对应进程
原文:http://www.oracleplus.net/arch/888.html https://www.ibm.com/support/knowledgecenter/zh/ssw_aix_72 ...
- ElasticSearch 6.x 父子文档[join]分析
ES6.0以后,索引的type只能有一个,使得父子结构变的不那么清晰,毕竟对于java开发者来说,index->db,type->table的结构比较容易理解. 按照官方的说明,之前一个索 ...
- 记一次TCP重发接口调用的问题
问题描述:基于微软RDP协议,使用开源rdp库与微软skpye软件进行基于tcp的p2p通讯,由于rdp协议传输原始图片数据较大,调用公司内部ice p2p通讯接口处会导致失败. 错误思路:一开始是怀 ...
- COM+时代的自动事务
最近看公司的遗留项目代码,调试的时候发现经常报分布式事务错误,可是整个代码里没有看见开启过事务,于是开始研究,发现了这个.Net Framework1.1时代的产物. namespace Busine ...