Hadoop-2.7.5完全分布式搭建
1、在虚拟机上安装Hadoop完全分布式准备工作
1)这里使用的是VMWare软件,在VMWare上安装一个CentOS6.5,并再克隆两个机器配置相关MAC地址,以及配置机器名
2)三台虚拟机配置好静态IP以及网络环境,以及SSH免密码登录(自行参考资料)
3)安装Java环境(自行参考资料)
4)Hadoop完全分布式结构及拓扑
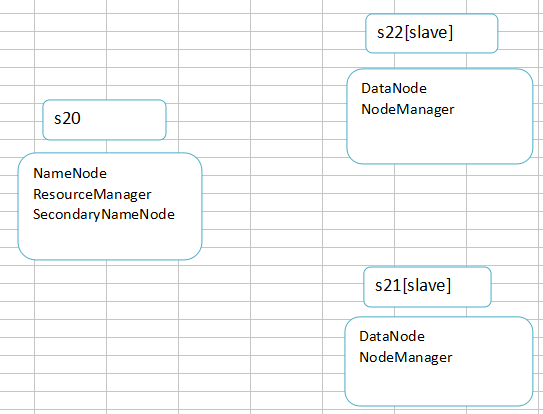
2、Hadoop相关配置
1)在apache官方网站上下载hadoop-2.7.5.tar.gz包
将下载好的gz包上传到s20机器上,解压到/opt/soft目录下
2)配置hadoop的环境变量
编辑/etc/profile文件,配置内容如下,编辑完成后使其生效 source /etc/profile
export HADOOP_HOME=/opt/soft/hadoop-2.7.5
export JAVA_HOME=/usr/local/java/jdk1.8.0_161
export CLASSPATH=.:$JAVA_HOME/jre/lib/rt.jar:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
3)Hadoop配置文件
[core-site.xml]
3、启动
1)在一个节点上执行完上述配置操作之后将hadoop-2.7.5整个文件夹复制到其他两个节点的相同目录,并配置其他两个节点Hadoop环境变量
2)上述操作都完成之后,执行格式化
hdfs namenode -format
3)执行启动脚本
start-dfs.sh:启动hdfs
start-yarn.sh:启动yarn
4)分别查看进程,是否启动的进程与拓扑图中的一致,如果不一致则可能有进程没有启动成功,需要检查配置
5)查看hdfs管理页面
http://192.168.137.120:50070

6)查看yarn管理页面
http://192.168.137.120:8088
Hadoop-2.7.5完全分布式搭建的更多相关文章
- Hadoop生态圈-hbase介绍-完全分布式搭建
Hadoop生态圈-hbase介绍-完全分布式搭建 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任.
- Hadoop单机模式和伪分布式搭建教程CentOS
1. 安装JAVA环境 2. Hadoop下载地址: http://archive.apache.org/dist/hadoop/core/ tar -zxvf hadoop-2.6.0.tar.gz ...
- Hadoop 完全分布式搭建
搭建环境 https://www.cnblogs.com/YuanWeiBlogger/p/11456623.html 修改主机名------------------- 1./etc/hostname ...
- hadoop分布式搭建
1.新建三台机器,分别为: hadoop分布式搭建至少需要三台机器: master extension1 extension2 本文利用在VMware Workstation下安装Linux cent ...
- hadoop完全分布式搭建HA(高可用)
2018年03月25日 16:25:26 D调的Stanley 阅读数:2725 标签: hadoop HAssh免密登录hdfs HA配置hadoop完全分布式搭建zookeeper 配置 更多 个 ...
- Hadoop简介与伪分布式搭建—DAY01
一. Hadoop的一些相关概念及思想 1.hadoop的核心组成: (1)hdfs分布式文件系统 (2)mapreduce 分布式批处理运算框架 (3)yarn 分布式资源调度系统 2.hadoo ...
- 超详细解说Hadoop伪分布式搭建--实战验证【转】
超详细解说Hadoop伪分布式搭建 原文http://www.tuicool.com/articles/NBvMv2原原文 http://wojiaobaoshanyinong.iteye.com/b ...
- 3.hadoop完全分布式搭建
3.Hadoop完全分布式搭建 1.完全分布式搭建 配置 #cd /soft/hadoop/etc/ #mv hadoop local #cp -r local full #ln -s full ha ...
- 2.hadoop基本配置,本地模式,伪分布式搭建
2. Hadoop三种集群方式 1. 三种集群方式 本地模式 hdfs dfs -ls / 不需要启动任何进程 伪分布式 所有进程跑在一个机器上 完全分布式 每个机器运行不同的进程 2. 服务器基本配 ...
- Hadoop的完全分布式搭建
一.准备虚拟机两台 1.将虚拟机进行克隆https://www.cnblogs.com/the-roc/p/12336745.html 2.1将克隆虚拟机的IP修改一下 vi /etc/sysconf ...
随机推荐
- shiro学习(五、springboot+shiro+mybatis+thymeleaf)
入门shiro(感觉成功了)首先感谢狂神,然后我就一本正经的复制代码了 项目结构 运行效果 数据库 <dependencies> <!-- thymeleaf-shiro整合包 -- ...
- vue-$watch属性方法
特性 https://www.cnblogs.com/widgetbox/p/8954162.html https://segmentfault.com/a/1190000012948175?utm_ ...
- 数组通常在JS中使用
数组通常在JS中使用,例如具有相同名称的多个输入.如果它们是动态生成的,则需要在提交时确定它们是否是数组.如果(文件).MyList.长度!=“未定义”)此用法不正确.正确的是如果(文件.MyList ...
- svn经典总结
大佬的svn:http://www.cnblogs.com/armyfai/p/3985660.html#!comments https://www.cnblogs.com/0zcl/p/730976 ...
- 1 sql server中添加链接服务器
1 链接到另一个sql server 的实例 exec sp_addlinkedserver @server= '服务器的地址',@srvproduct='SQL Server' go 分布式查询中 ...
- 数据集:Introduction to Econometrics by Stock&Watson
James H. Stock and Mark W. Watson, Introduction to Econometrics: data sets 詹姆斯·H·斯托克 马克·W·沃森. 计量经济学. ...
- Python之for循环与while循环
for语句格式for x in range(起始值,结束值,步幅) 执行语句输出0,100各个数字for i in range(0,101) print(i)输出0,100的偶数for i in ra ...
- 【1】Zookeeper概述
一.前言 在"网络是不可靠的"这一前提下,分布式系统开发需要解决如下四个问题: 客户端如何访问众多服务? 解决方案:服务聚合,使用API网关 服务于服务之间如何通信? 解决方案 ...
- Delphi 媒体播放器控件
樊伟胜
- Vivotek 摄像头远程栈溢出漏洞分析及利用
Vivotek 摄像头远程栈溢出漏洞分析及利用 近日,Vivotek 旗下多款摄像头被曝出远程未授权栈溢出漏洞,攻击者发送特定数据可导致摄像头进程崩溃. 漏洞作者@bashis 放出了可造成摄像头 C ...