Python——决策树实战:california房价预测
Python——决策树实战:california房价预测
编译环境:Anaconda、Jupyter Notebook
首先,导入模块:
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
接下来导入数据集:
from sklearn.datasets.california_housing import fetch_california_housing
housing = fetch_california_housing()
print(housing.DESCR) #description
使用sklearn自带的数据集california_housing,详情见:Python——sklearn提供的自带的数据集
运行结果:
California housing dataset.
The original database is available from StatLib
http://lib.stat.cmu.edu/datasets/
The data contains 20,640 observations on 9 variables.
This dataset contains the average house value as target variable
and the following input variables (features): average income,
housing average age, average rooms, average bedrooms, population,
average occupation, latitude, and longitude in that order.
References
----------
Pace, R. Kelley and Ronald Barry, Sparse Spatial Autoregressions,
Statistics and Probability Letters, 33 (1997) 291-297.
查看一下数据:
housing.data.shape
(20640, 8)
housing.data[0]
array([ 8.3252 , 41. , 6.98412698, 1.02380952,
322. , 2.55555556, 37.88 , -122.23 ])
树模型参数:
1.criterion gini or entropy
2.splitter best or random 前者是在所有特征中找最好的切分点 后者是在部分特征中(数据量大的时候)
3.max_features None(所有),log2,sqrt,N 特征小于50的时候一般使用所有的
4.max_depth 数据少或者特征少的时候可以不管这个值,如果模型样本量多,特征也多的情况下,可以尝试限制下
5.min_samples_split 如果某节点的样本数少于min_samples_split,则不会继续再尝试选择最优特征来进行划分如果样本量不大,不需要管这个值。如果样本量数量级非常大,则推荐增大这个值。
6.min_samples_leaf 这个值限制了叶子节点最少的样本数,如果某叶子节点数目小于样本数,则会和兄弟节点一起被剪枝,如果样本量不大,不需要管这个值,大些如10W可是尝试下5
7.min_weight_fraction_leaf 这个值限制了叶子节点所有样本权重和的最小值,如果小于这个值,则会和兄弟节点一起被剪枝默认是0,就是不考虑权重问题。一般来说,如果我们有较多样本有缺失值,或者分类树样本的分布类别偏差很大,就会引入样本权重,这时我们就要注意这个值了。
8.max_leaf_nodes 通过限制最大叶子节点数,可以防止过拟合,默认是"None”,即不限制最大的叶子节点数。如果加了限制,算法会建立在最大叶子节点数内最优的决策树。如果特征不多,可以不考虑这个值,但是如果特征分成多的话,可以加以限制具体的值可以通过交叉验证得到。
9.class_weight 指定样本各类别的的权重,主要是为了防止训练集某些类别的样本过多导致训练的决策树过于偏向这些类别。这里可以自己指定各个样本的权重如果使用“balanced”,则算法会自己计算权重,样本量少的类别所对应的样本权重会高。
10.min_impurity_split 这个值限制了决策树的增长,如果某节点的不纯度(基尼系数,信息增益,均方差,绝对差)小于这个阈值则该节点不再生成子节点。即为叶子节点 。
- n_estimators:要建立树的个数
接下来首先把算法实例化出来,然后传参进行训练。
from sklearn import tree
dtr = tree.DecisionTreeRegressor(max_depth = 2)
# 使用两列的特征进行训练 即传两个参数x, y
dtr.fit(housing.data[:, [6, 7]], housing.target)
输出:
DecisionTreeRegressor(criterion='mse', max_depth=2, max_features=None,
max_leaf_nodes=None, min_impurity_split=1e-07,
min_samples_leaf=1, min_samples_split=2,
min_weight_fraction_leaf=0.0, presort=False, random_state=None,
splitter='best')
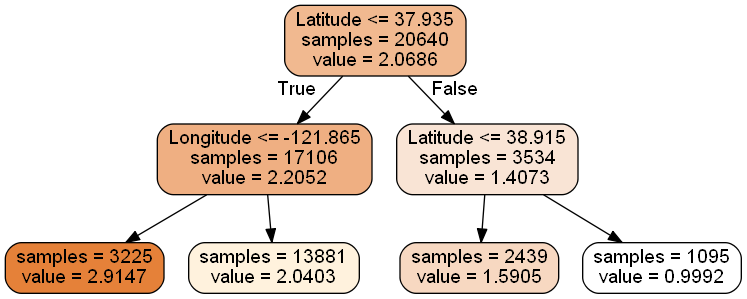
为了将决策树可视化,首先安装graphviz。export_graphviz出口也支持多种美学选项,包括可以通过类着色节点(或值回归)和如果需要的话使用显式的变量和类名称。IPython笔记本还可以使用Image()函数内联渲染这些图:
#要可视化显示 首先需要安装 graphviz http://www.graphviz.org/Download..php
dot_data = \
tree.export_graphviz(
dtr,
out_file = None,
feature_names = housing.feature_names[6:8],
filled = True,
impurity = False,
rounded = True
)
graphviz及pydotplus安装步骤 :Python——graphviz及pydotplus安装步骤
安装了Python模块pydotplus后,可以直接在Python中生成PNG文件(或任何其他支持的文件类型):
#pip install pydotplus
import pydotplus
graph = pydotplus.graph_from_dot_data(dot_data)
graph.get_nodes()[7].set_fillcolor("#FFF2DD")
graph.write_png("graph.png")
from IPython.display import Image
Image(graph.create_png())
sklearn——train_test_split 随机划分训练集和测试集
将数据集进行划分,划分为训练集和测试集,并进行训练、验证
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = \
train_test_split(housing.data, housing.target, test_size = 0.1, random_state = 42)
dtr = tree.DecisionTreeRegressor(random_state=42)
dtr.fit(x_train, y_train) dtr.score(x_test, y_test)
结果:
0.637318351331017
使用随机森林:
from sklearn.ensemble import RandomForestRegressor
rfr = RandomForestRegressor( random_state = 42)
rfr.fit(x_train, y_train)
rfr.score(x_test, y_test)
结果:
0.79086492280964926
用交叉验证选取参数:
from sklearn.grid_search import GridSearchCV # 一般把参数写成字典的格式:
tree_param_grid = { 'min_samples_split': list((3, 6, 9)),'n_estimators': list((10,50,100))} # 第一个参数是模型,第二个参数是待选的参数,cv:进行几次交叉验证
grid = GridSearchCV(RandomForestRegressor(), param_grid = tree_param_grid, cv = 5)
grid.fit(x_train, y_train)
grid.grid_scores_, grid.best_params_, grid.best_score_
结果为:
([mean: 0.78795, std: 0.00337, params: {'min_samples_split': 3, 'n_estimators': 10},
mean: 0.80463, std: 0.00308, params: {'min_samples_split': 3, 'n_estimators': 50},
mean: 0.80732, std: 0.00448, params: {'min_samples_split': 3, 'n_estimators': 100},
mean: 0.78535, std: 0.00506, params: {'min_samples_split': 6, 'n_estimators': 10},
mean: 0.80446, std: 0.00399, params: {'min_samples_split': 6, 'n_estimators': 50},
mean: 0.80688, std: 0.00424, params: {'min_samples_split': 6, 'n_estimators': 100},
mean: 0.78754, std: 0.00552, params: {'min_samples_split': 9, 'n_estimators': 10},
mean: 0.80321, std: 0.00487, params: {'min_samples_split': 9, 'n_estimators': 50},
mean: 0.80553, std: 0.00389, params: {'min_samples_split': 9, 'n_estimators': 100}],
{'min_samples_split': 3, 'n_estimators': 100},
0.8073224957136084)
使用得到的参数重新训练随机森林:
rfr = RandomForestRegressor( min_samples_split=3,n_estimators = 100,random_state = 42)
rfr.fit(x_train, y_train)
rfr.score(x_test, y_test)
结果为:
0.80908290496531576
pd.Series(rfr.feature_importances_, index = housing.feature_names).sort_values(ascending = False)
结果为:
MedInc 0.524257
AveOccup 0.137947
Latitude 0.090622
Longitude 0.089414
HouseAge 0.053970
AveRooms 0.044443
Population 0.030263
AveBedrms 0.029084
dtype: float64
Python——决策树实战:california房价预测的更多相关文章
- 科学经得起实践检验-python3.6通过决策树实战精准准确预测今日大盘走势(含代码)
科学经得起实践检验-python3.6通过决策树实战精准准确预测今日大盘走势(含代码) 春有百花秋有月,夏有凉风冬有雪: 若无闲事挂心头,便是人间好时节. --宋.无门慧开 不废话了,以下训练模型数据 ...
- Python之机器学习-波斯顿房价预测
目录 波士顿房价预测 导入模块 获取数据 打印数据 特征选择 散点图矩阵 关联矩阵 训练模型 可视化 波士顿房价预测 导入模块 import pandas as pd import numpy as ...
- 机器学习实战二:波士顿房价预测 Boston Housing
波士顿房价预测 Boston housing 这是一个波士顿房价预测的一个实战,上一次的Titantic是生存预测,其实本质上是一个分类问题,就是根据数据分为1或为0,这次的波士顿房价预测更像是预测一 ...
- 【Machine Learning】决策树案例:基于python的商品购买能力预测系统
决策树在商品购买能力预测案例中的算法实现 作者:白宁超 2016年12月24日22:05:42 摘要:随着机器学习和深度学习的热潮,各种图书层出不穷.然而多数是基础理论知识介绍,缺乏实现的深入理解.本 ...
- 【Python机器学习实战】决策树和集成学习(一)
摘要:本部分对决策树几种算法的原理及算法过程进行简要介绍,然后编写程序实现决策树算法,再根据Python自带机器学习包实现决策树算法,最后从决策树引申至集成学习相关内容. 1.决策树 决策树作为一种常 ...
- python机器学习实战(二)
python机器学习实战(二) 版权声明:本文为博主原创文章,转载请指明转载地址 http://www.cnblogs.com/fydeblog/p/7159775.html 前言 这篇noteboo ...
- 使用sklearn进行数据挖掘-房价预测(6)—模型调优
通过上一节的探索,我们会得到几个相对比较满意的模型,本节我们就对模型进行调优 网格搜索 列举出参数组合,直到找到比较满意的参数组合,这是一种调优方法,当然如果手动选择并一一进行实验这是一个十分繁琐的工 ...
- 波士顿房价预测 - 最简单入门机器学习 - Jupyter
机器学习入门项目分享 - 波士顿房价预测 该分享源于Udacity机器学习进阶中的一个mini作业项目,用于入门非常合适,刨除了繁琐的部分,保留了最关键.基本的步骤,能够对机器学习基本流程有一个最清晰 ...
- 基于股票大数据分析的Python入门实战(视频教学版)的精彩插图汇总
在我写的这本书,<基于股票大数据分析的Python入门实战(视频教学版)>里,用能吸引人的股票案例,带领大家入门Python的语法,数据分析和机器学习. 京东链接是这个:https://i ...
随机推荐
- JS 发送弹幕
JS实现弹幕的发送 <div class="box1"> <div class="box2" style="width: 600px ...
- Java后端开发常用工具
Java后端开发常用工具推荐: 俗话说,工欲善其事,必先利其器.不过初学时候不大建议过度依赖IDE等过多工具,这会让自己的编程基础功变得很差,比如各种语法的不熟悉,各种关键字比如synchronize ...
- oracle索引查询
/*<br>* *查看目标表中已添加的索引 * */ --在数据库中查找表名 select * from user_tables where table_name like 'table ...
- SQL学习——SELECT INTO和INSERT INTO SELECT
原文链接 SELECT INTO 作用 SELECT INTO 语句从一个表中复制数据,然后将数据插入到另一个新表中. SELECT INTO 语法 我们可以把所有的列都复制到新表中: SELECT ...
- Django + mysql 在创建数据库出错
错误:django.db.utils.OperationalError: (1366, "Incorrect string value: '\\xE6\\x96\\x87\\xE7\\xAB ...
- 13.SpringMVC核心技术-异常处理
常用的SpringMVC异常处理方式主要是三种: 1.使用系统定义好的异常处理器 SimpleMappingExceptionResolver 2.使用自定义异常处理器 3.使用异常处理注解 Si ...
- 使用python2与python3创建一个简单的http服务(基于SimpleHTTPServer)
python2与python3基于SimpleHTTPServer创建一个http服务的方法是不同的: 一.在linux服务器上面检查一下自己的python版本:如: [root@zabbix ~]# ...
- pyltp安装
第一步:下载wheel文件 第二步:进入该文件的文件夹 第三步:pip install wheel文件名 注意:python的安装版本必须和pyltp的版本相同,我这版本都是pyhton3.6.之前p ...
- oppo面经-java开发
Oppo一面(1)自我简介(2)介绍一个自己做过的最得意的项目,项目的细节,难点,怎么解决的,还存在的问题,有什么优化的想法吗(这个我说了很长时间,面试官说非计算机专业的,有这种实习经验确实能加分)( ...
- use redir to make port redirecting
Step 1: install redir apt-get update apt-get install redir -y Step2 : add port mapping redir --lport ...