Spark中的CombineKey()详解
CombineKey()是最常用的基于键进行聚合的函数,大多数基于键聚合的函数都是用它实现的。和aggregate()一样,CombineKey()可以让用户返回与输入数据的类型不同的返回值。要理解CombineKey()需要先理解它在数据处理时是如何处理每个元素的。由于CombineKey()会遍历分区中的所有元素,因此每个元素的键要么还没有遇到,要么就是和之前的额某个元素的键相同。
如果遇到的是一个新元素,CombineKey()会使用一个叫做createCombiner()的函数来创建那个键对应的累加器的初始值,需要注意的是,这一过程会在每个分区中第一次出现各个键时发生,而不是在整个RDD中第一次出现时发生。
如果这是一个在处理当前分区之前已经遇到的键,它会使用mergeValue()方法将该键的累加器对应的值与这个新的值进行合并。
由于每个分区都是独立处理的,因此对于同一个键可以有多个累加器。如果有两个或者更多的分区都有对应同一个键的累加器,就需要使用用户提供的mergeCombiners()方法将各个分区的结果进行合并。
如果已知数据在进行combineByKey() 时无法从map 端聚合中获益的话,可以禁用它。例如,由于聚合函数(追加到一个队列)无法在map 端聚合时节约任何空间,groupByKey() 就把它禁用了。如果希望禁用map 端组合,就需要指定分区方式。就目前而言,你可以通过传递rdd.partitioner 来直接使用源RDD 的分区方式。
combineByKey() 有多个参数分别对应聚合操作的各个阶段,因而非常适合用来解释聚合操作各个阶段的功划分。为了更好地演示combineByKey() 是如何工作的,下面来看看如何计算各键对应的平均值:
在Python 中使用combineByKey() 求每个键对应的平均值
sumCount = nums.combineByKey((lambda x: (x,1)),
(lambda x, y: (x[0] + y, x[1] + 1)),
(lambda x, y: (x[0] + y[0], x[1] + y[1])))
sumCount.map(lambda key, xy: (key, xy[0]/xy[1])).collectAsMap()
在Scala 中使用combineByKey() 求每个键对应的平均值
val result = input.combineByKey(
(v) => (v, 1),
(acc: (Int, Int), v) => (acc._1 + v, acc._2 + 1),
(acc1: (Int, Int), acc2: (Int, Int)) => (acc1._1 + acc2._1, acc1._2 + acc2._2)
).map{ case (key, value) => (key, value._1 / value._2.toFloat) }
result.collectAsMap().map(println(_))
在Java 中使用combineByKey() 求每个键对应的平均值
public static class AvgCount implements Serializable {
public AvgCount(int total, int num) { total_ = total; num_ = num; }
public int total_;
public int num_;
public float avg() { returntotal_/(float)num_; }
}
Function<Integer, AvgCount> createAcc = new Function<Integer, AvgCount>() {
public AvgCount call(Integer x) {
return new AvgCount(x, 1);
}
};
Function2<AvgCount, Integer, AvgCount> addAndCount =
new Function2<AvgCount, Integer, AvgCount>() {
public AvgCount call(AvgCount a, Integer x) {
a.total_ += x;
a.num_ += 1;
return a;
}
};
Function2<AvgCount, AvgCount, AvgCount> combine =
new Function2<AvgCount, AvgCount, AvgCount>() {
public AvgCount call(AvgCount a, AvgCount b) {
a.total_ += b.total_;
a.num_ += b.num_;
return a;
}
};
AvgCount initial = new AvgCount(0,0);
JavaPairRDD<String, AvgCount> avgCounts =
nums.combineByKey(createAcc, addAndCount, combine);
Map<String, AvgCount> countMap = avgCounts.collectAsMap();
for (Entry<String, AvgCount> entry : countMap.entrySet()) {
System.out.println(entry.getKey() + ":" + entry.getValue().avg());
}
combineByKey() 数据流示意图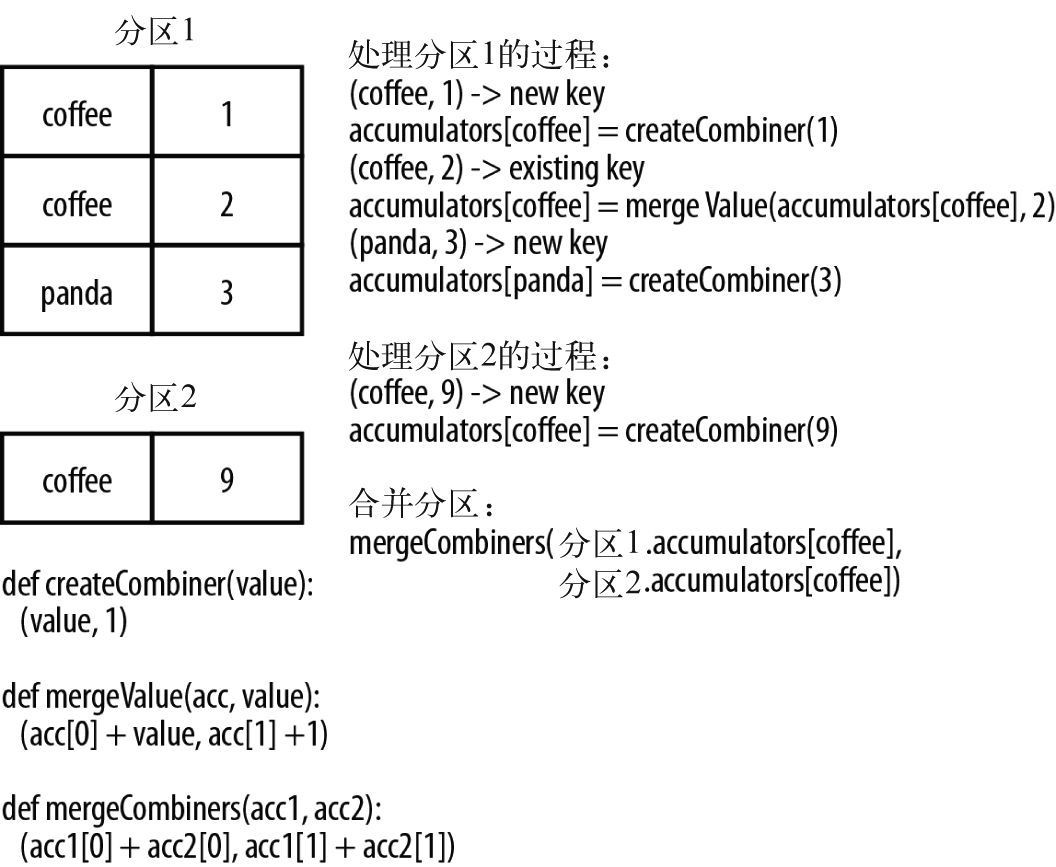
有很多函数可以进行基于键的数据合并。它们中的大多数都是在combineByKey() 的基础上实现的,为用户提供了更简单的接口。不管怎样,在Spark 中使用这些专用的聚合函数,始终要比手动将数据分组再归约快很多。
Spark中的CombineKey()详解的更多相关文章
- Spark中的分区方法详解
转自:https://blog.csdn.net/dmy1115143060/article/details/82620715 一.Spark数据分区方式简要 在Spark中,RDD(Resilien ...
- [Spark内核] 第36课:TaskScheduler内幕天机解密:Spark shell案例运行日志详解、TaskScheduler和SchedulerBackend、FIFO与FAIR、Task运行时本地性算法详解等
本課主題 通过 Spark-shell 窥探程序运行时的状况 TaskScheduler 与 SchedulerBackend 之间的关系 FIFO 与 FAIR 两种调度模式彻底解密 Task 数据 ...
- Spark log4j日志配置详解(转载)
一.spark job日志介绍 spark中提供了log4j的方式记录日志.可以在$SPARK_HOME/conf/下,将 log4j.properties.template 文件copy为 l ...
- php中关于引用(&)详解
php中关于引用(&)详解 php的引用(就是在变量或者函数.对象等前面加上&符号) 在PHP 中引用的意思是:不同的变量名访问同一个变量内容. 与C语言中的指针是有差别的.C语言中的 ...
- JavaScript正则表达式详解(二)JavaScript中正则表达式函数详解
二.JavaScript中正则表达式函数详解(exec, test, match, replace, search, split) 1.使用正则表达式的方法去匹配查找字符串 1.1. exec方法详解 ...
- AngularJS select中ngOptions用法详解
AngularJS select中ngOptions用法详解 一.用法 ngOption针对不同类型的数据源有不同的用法,主要体现在数组和对象上. 数组: label for value in a ...
- 【转载】C/C++中extern关键字详解
1 基本解释:extern可以置于变量或者函数前,以标示变量或者函数的定义在别的文件中,提示编译器遇到此变量和函数时在其他模块中寻找其定义.此外extern也可用来进行链接指定. 也就是说extern ...
- oracle中imp命令详解 .
转自http://www.cnblogs.com/songdavid/articles/2435439.html oracle中imp命令详解 Oracle的导入实用程序(Import utility ...
- Android中Service(服务)详解
http://blog.csdn.net/ryantang03/article/details/7770939 Android中Service(服务)详解 标签: serviceandroidappl ...
随机推荐
- zabbix low-level discovery 监控mysql
当一台服务器上MySQL有多个实例的时候,MySQL占用多个不同端口.利用zabbix的low-level discovery可以轻松监控. 思路参考:http://dl528888.blog.51c ...
- (13)input输入函数
(1)input 等待用户动态输入一个值,注意得到的值是一个字符串类型 提示用户输入用户名和密码: 如果用户名是admin , 并且密码是000 , 提示用户恭喜你,登陆成功 否则提示用户名或密码错误 ...
- win10激活密钥
专业版:W269N-WFGWX-YVC9B-4J6C9-T83GX 企业版:NPPR9-FWDCX-D2C8J-H872K-2YT43 家庭版:TX9XD-98N7V-6WMQ6-BX7FG-H8Q9 ...
- 洛谷P5002 专心OI - 找祖先
题目概括 题目描述 这个游戏会给出你一棵树,这棵树有\(N\)个节点,根结点是\(R\),系统会选中\(M\)个点\(P_1,P_2...P_M\). 要Imakf回答有多少组点对\((u_i,v_i ...
- java中的io流总结(一)
知识点:基于抽象基类字节流(InputStream和OutputStream).字符流(Reader和Writer)的特性,处理纯文本文件,优先考虑使用字符流BufferedReader/Buffer ...
- Vulkan 02
https://www.imgtec.com/blog/vulkan-high-efficiency-on-mobile/ vulkan性能上的优势 降低CPU开销 drawcall上限数量增加 Ho ...
- stm32焊接心得
早上焊接了一块朋友给的stm32f103zet6的开发板,起初,烙铁怎么都焊补上去,原来是烙铁头已经氧化,只能作罢! 那里一个新的焊接,温度打到450,基本上,焊接就非常顺利,当然温度不要太高,以免弄 ...
- C#分隔字符串时遭遇空值
在C#中分隔字符串时,按特定字符进行分隔的时候可能会遇到空值,如何我现在传入的是Id的字符串,如:"1501,1502,1503,,1505",以逗号分隔,由于各种原因,导致传入的 ...
- JQuery 实践--让页面动起来
获取和设置元素特性特性属性:是指DOM元素中能够和HTML元素中某个特性对应得上的属性.通常JS特性属性的名称与对应的特性一一匹配,但class <=>className操作特性还是操作属 ...
- HTML基础要点归纳
一.开发环境 常用的HTML编辑器有Sublime Text.Hbuild.Dreamweare.以及vs code.pycharm等都可以.我目前在用的就是Sublime text3和Hbuild两 ...