属性 每秒10万吞吐 并发 架构 设计 58最核心的帖子中心服务IMC 类目服务 入口层是Java研发的,聚合层与检索层都是C语言研发的 电商系统里的SKU扩展服务
小结:
1、
海量异构数据的存储问题
如何将不同品类,异构的数据统一存储起来呢?
(1)全品类通用属性统一存储;
(2)单品类特有属性,品类类型与通用属性json来进行存储;
2、
入口层是Java研发的,聚合层与检索层都是C语言研发的
3、
(1)数据库提供“帖子id”的正排查询需求;
(2)所有非“帖子id”的个性化检索需求,统一走外置索引;
4、
定期全量重建索引
5、
为应对100亿级别数据量、几十万级别的吞吐量,业务线各种复杂的复杂检索查询,扩展性是设计重点:
(1)统一的代理层,作为入口,其无状态性能够保证增加机器就能扩充系统性能;
(2)统一的结果聚合层,其无状态性也能够保证增加机器就能扩充系统性能;
(3)搜索内核检索层,服务和索引数据部署在同一台机器上,服务启动时可以加载索引数据到内存,请求访问时从内存中load数据,访问速度很快:
为了满足数据容量的扩展性,索引数据进行了水平切分,增加切分份数,就能够无限扩展性能
为了满足一份数据的性能扩展性,同一份数据进行了冗余,理论上做到增加机器就无限扩展性能
系统时延,100亿级别帖子检索,包含请求分合,拉链求交集,从聚合层均可以做到10ms返回。
https://mp.weixin.qq.com/s/msinJA9T3TR1uWrYx6M1iQ
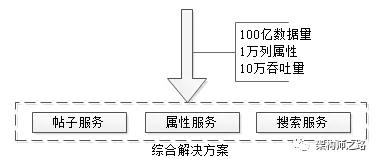
1万属性,100亿数据,每秒10万吞吐,架构如何设计?
有一类业务场景,没有固定的schema存储,却有着海量的数据行数,架构上如何来实现这类业务的存储与检索呢?58最核心的数据“帖子”的架构实现技术细节,今天和大家聊一聊。
一、背景描述及业务介绍
什么是58最核心的数据?
58是一个信息平台,有很多垂直品类:招聘、房产、二手物品、二手车、黄页等等,每个品类又有很多子品类,不管哪个品类,最核心的数据都是“帖子信息”。
画外音:像不像一个大论坛?
各分类帖子的信息有什么特点?
逛过58的朋友很容易了解到,这里的帖子信息:
(1)各品类的属性千差万别,招聘帖子和二手帖子属性完全不同,二手手机和二手家电的属性又完全不同,目前恐怕有近万个属性;
(2)数据量巨大,100亿级别;
(3)每个属性上都有查询需求,各组合属性上都可能有组合查询需求,招聘要查职位/经验/薪酬范围,二手手机要查颜色/价格/型号,二手要查冰箱/洗衣机/空调;
(4)吞吐量很大,每秒几10万吞吐;
如何解决100亿数据量,1万属性,多属性组合查询,10万并发查询的技术难题呢?一步步来。
二、最容易想到的方案
每个公司的发展都是一个从小到大的过程,撇开并发量和数据量不谈,先看看
(1)如何实现属性扩展性需求;
(2)多属性组合查询需求;
画外音:公司初期并发量和数据量都不大,必须先解决业务问题。
如何满足业务的存储需求呢?
最开始,业务只有一个招聘品类,那帖子表可能是这么设计的:
tiezi(tid, uid, c1, c2, c3);
那如何满足各属性之间的组合查询需求呢?
最容易想到的是通过组合索引满足查询需求:
index_1(c1, c2)
index_2(c2, c3)
index_3(c1, c3)
随着业务的发展,又新增了一个房产类别,存储问题又该如何解决呢?
可以新增若干属性满足存储需求,于是帖子表变成了:
tiezi(tid, uid, c1, c2, c3, c10, c11, c12, c13);
其中:
c1,c2,c3是招聘类别属性
c10,c11,c12,c13是房产类别属性
通过扩展属性,可以解决存储的问题。
查询需求,又该如何满足呢?
首先,跨业务属性一般没有组合查询需求。只能建立了若干组合索引,满足房产类别的查询需求。
画外音:不敢想有多少个索引能覆盖所有两属性查询,三属性查询。
当业务越来越多时,是不是发现玩不下去了?
三、垂直拆分是一个思路
新增属性是一种扩展方式,新增表也是一种方式,垂直拆分也是常见的存储扩展方案。
如何按照业务进行垂直拆分?
可以这么玩:
tiezi_zhaopin(tid, uid, c1, c2, c3);
tiezi_fangchan(tid, uid, c10, c11, c12, c13);
在业务各异,数据量和吞吐量都巨大的情况下,垂直拆分会遇到什么问题呢?
这些表,以及对应的服务维护在不同的部门,看上去各业务灵活性强,研发闭环,这恰恰是悲剧的开始:
(1)tid如何规范?
(2)属性如何规范?
(3)按照uid来查询怎么办(查询自己发布的所有帖子)?
(4)按照时间来查询怎么办(最新发布的帖子)?
(5)跨品类查询怎么办(例如首页搜索框)?
(6)技术范围的扩散,有的用mongo存储,有的用mysql存储,有的自研存储;
(7)重复开发了不少组件;
(8)维护成本过高;
(9)…
画外音:想想看,电商的商品表,不可能一个类目一个表的。
四、58的玩法:三大中心服务
第一:统一帖子中心服务
平台型创业型公司,可能有多个品类,各品类有很多异构数据的存储需求,到底是分还是合,无需纠结:基础数据基础服务的统一,是一个很好的实践。
画外音:这里说的是平台型业务。
如何将不同品类,异构的数据统一存储起来呢?
(1)全品类通用属性统一存储;
(2)单品类特有属性,品类类型与通用属性json来进行存储;
更具体的:
tiezi(tid, uid, time, title, cate, subcate, xxid, ext);
(1)一些通用的字段抽取出来单独存储;
(2)通过cate, subcate, xxid等来定义ext是何种含义;

(3)通过ext来存储不同业务线的个性化需求
例如:
招聘的帖子,ext为:
{“job”:”driver”,”salary”:8000,”location”:”bj”}
而二手的帖子,ext为:
{”type”:”iphone”,”money”:3500}
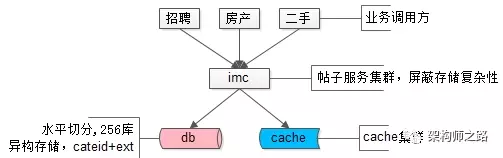
帖子数据,100亿的数据量,分256库,通过ext存储异构业务数据,使用mysql存储,上层架了一个帖子中心服务,使用memcache做缓存,就是这样一个并不复杂的架构,解决了业务的大问题。这是58最核心的帖子中心服务IMC(Info Management Center)。
画外音:该服务的底层存储在16年全面切换为了自研存储引擎,替换了mysql,但架构理念仍未变。
解决了海量异构数据的存储问题,遇到的新问题是:
(1)每条记录ext内key都需要重复存储,占据了大量的空间,能否压缩存储;
(2)cateid已经不足以描述ext内的内容,品类有层级,深度不确定,ext能否具备自描述性;
(3)随时可以增加属性,保证扩展性;
解决完海量异构数据的存储问题,接下来,要解决的是类目的扩展性问题。
第二:统一类目属性服务
每个业务有多少属性,这些属性是什么含义,值的约束等,耦合到帖子服务里显然是不合理的,那怎么办呢?
抽象出一个统一的类目、属性服务,单独来管理这些信息,而帖子库ext字段里json的key,统一由数字来表示,减少存储空间。

画外音:帖子表只存元信息,不管业务含义。
如上图所示,json里的key不再是”salary” ”location” ”money” 这样的长字符串了,取而代之的是数字1,2,3,4,这些数字是什么含义,属于哪个子分类,值的校验约束,统一都存储在类目、属性服务里。

画外音:类目表存业务信息,以及约束信息,与帖子表解耦。
这个表里对帖子中心服务里ext字段里的数字key进行了解释:
(1)1代表job,属于招聘品类下100子品类,其value必须是一个小于32的[a-z]字符;
(2)4代表type,属于二手品类下200子品类,其value必须是一个short;
这样就对原来帖子表ext扩展属性:
{“1”:”driver”,”2”:8000,”3”:”bj”}
{”4”:”iphone”,”5”:3500}
key和value都做了统一约束。
除此之外,如果ext里某个key的value不是正则校验的值,而是枚举值时,需要有一个对值进行限定的枚举表来进行校验:

这个枚举校验,说明key=4的属性(对应属性表里二手,手机类型字段),其值不只是要进行“short类型”校验,而是value必须是固定的枚举值。
{”4”:”iphone”,”5”:3500}
这个ext就是不合法的,key=4的value=iphone不合法,而应该是枚举属性,合法的应该为:
{”4”:”5”,”5”:3500}
此外,类目属性服务还能记录类目之间的层级关系:
(1)一级类目是招聘、房产、二手…
(2)二手下有二级类目二手家具、二手手机…
(3)二手手机下有三级类目二手iphone,二手小米,二手三星…
(4)…
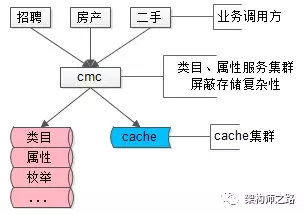
类目服务解释了帖子数据,描述品类层级关系,保证各类目属性扩展性,保证各属性值合理性校验,就是58另一个统一的核心服务CMC(Category Management Center)。
画外音:类目、属性服务像不像电商系统里的SKU扩展服务?
(1)品类层级关系,对应电商里的类别层级体系;
(2)属性扩展,对应电商里各类别商品SKU的属性;
(3)枚举值校验,对应属性的枚举值,例如颜色:红,黄,蓝;
通过品类服务,解决了key压缩,key描述,key扩展,value校验,品类层级的问题,还有这样的一个问题没有解决:每个品类下帖子的属性各不相同,查询需求各不相同,如何解决100亿数据量,1万属性的检索与联合检索需求呢?
第三:统一检索服务
数据量很大的时候,不同属性上的查询需求,不可能通过组合索引来满足所有查询需求,“外置索引,统一检索服务”是一个很常用的实践:
(1)数据库提供“帖子id”的正排查询需求;
(2)所有非“帖子id”的个性化检索需求,统一走外置索引;
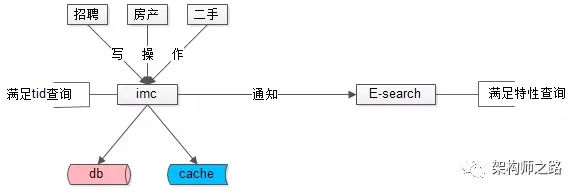
元数据与索引数据的操作遵循:
(1)对帖子进行tid正排查询,直接访问帖子服务;
(2)对帖子进行修改,帖子服务通知检索服务,同时对索引进行修改;
(3)对帖子进行复杂查询,通过检索服务满足需求;
画外音:这个检索服务,扛起了58同城80%的请求(不管来自PC还是APP,不管是主页、城市页、分类页、列表页、详情页,最终都会转化为一个检索请求),它就是58另一个统一的核心服务E-search,这个搜索引擎,是完全自研的。
对于这个内核自研服务的搜索引擎架构,简单说明一下:
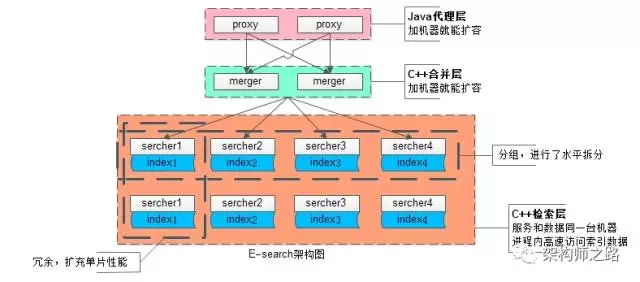
为应对100亿级别数据量、几十万级别的吞吐量,业务线各种复杂的复杂检索查询,扩展性是设计重点:
(1)统一的代理层,作为入口,其无状态性能够保证增加机器就能扩充系统性能;
(2)统一的结果聚合层,其无状态性也能够保证增加机器就能扩充系统性能;
(3)搜索内核检索层,服务和索引数据部署在同一台机器上,服务启动时可以加载索引数据到内存,请求访问时从内存中load数据,访问速度很快:
为了满足数据容量的扩展性,索引数据进行了水平切分,增加切分份数,就能够无限扩展性能
为了满足一份数据的性能扩展性,同一份数据进行了冗余,理论上做到增加机器就无限扩展性能
系统时延,100亿级别帖子检索,包含请求分合,拉链求交集,从聚合层均可以做到10ms返回。
画外音:入口层是Java研发的,聚合层与检索层都是C语言研发的。
帖子业务,一致性不是主要矛盾,E-search会定期全量重建索引,以保证即使数据不一致,也不会持续很长的时间。
五、总结
文章写了很长,最后做一个简单总结,面对100亿数据量,1万列属性,10万吞吐量的业务需求,可以采用了元数据服务、属性服务、搜索服务来解决:
一个解决存储问题
一个解决品类解耦问题
一个解决检索问题
任何复杂问题的解决,都是循序渐进的。
思路比结论重要,希望大家有收获。
属性 每秒10万吞吐 并发 架构 设计 58最核心的帖子中心服务IMC 类目服务 入口层是Java研发的,聚合层与检索层都是C语言研发的 电商系统里的SKU扩展服务的更多相关文章
- SpringCloud Alibaba实战(2:电商系统业务分析)
选用了很常见的电商业务来进行SpringCloud Alibaba的实战. 当然,因为仅仅是为了学习SpringCloud Alibaba,所以对业务进行了大幅度简化,这里只取一个精简版的用户下单业务 ...
- 案例实战:每日上亿请求量的电商系统,JVM年轻代垃圾回收参数如何优化?
出自:http://1t.click/7TJ 目录: 案例背景引入 特殊的电商大促场景 抗住大促的瞬时压力需要几台机器? 大促高峰期订单系统的内存使用模型估算 内存到底该如何分配? 新生代垃圾回收优化 ...
- 每日上亿请求量的电商系统,JVM年轻代垃圾回收参数如何优化? ----实战教会你如何配置
目录: 案例背景引入 特殊的电商大促场景 抗住大促的瞬时压力需要几台机器? 大促高峰期订单系统的内存使用模型估算 内存到底该如何分配? 新生代垃圾回收优化之一:Survivor空间够不够 新生代对象躲 ...
- 免费领CRMEB移动社交电商系统源码与授权
移动电商风起云涌,直播带货重塑销售模式,传统商业更是举步维艰,各行各业转型移动电商迫在眉睫,拥有一款好的移动社群社交电商系统成为众多企业与商家的心病! 你曾是否被那些劣质的移动电商系统搞得心力憔悴? ...
- 12. 亿级流量电商系统JVM模型参数二次优化
亿级流量电商系统JVM模型参数预估方案,在原来的基础上采用ParNew+CMS垃圾收集器 一.亿级流量分析及jvm参数设置 1. 需求分析 大促在即,拥有亿级流量的电商平台开发了一个订单系统,我们应该 ...
- Java进阶专题(十三) 从电商系统角度研究多线程(上)
前言 本章节主要分享下,多线程并发在电商系统下的应用.主要从以下几个方面深入:线程相关的基础理论和工具.多线程程序下的性能调优和电商场景下多线程的使用. 多线程J·U·C 线程池 概念 回顾线程创 ...
- Java进阶专题(十五) 从电商系统角度研究多线程(下)
前言 本章节继上章节继续梳理:线程相关的基础理论和工具.多线程程序下的性能调优和电商场景下多线程的使用. 多线程J·U·C ThreadLocal 概念 ThreadLocal类并不是用来解决 ...
- 通过Dapr实现一个简单的基于.net的微服务电商系统(六)——一步一步教你如何撸Dapr之Actor服务
我个人认为Actor应该是Dapr里比较重头的部分也是Dapr一直在讲的所谓"stateful applications"真正具体的一个实现(个人认为),上一章讲到有状态服务可能很 ...
- 通过Dapr实现一个简单的基于.net的微服务电商系统(七)——一步一步教你如何撸Dapr之服务限流
在一般的互联网应用中限流是一个比较常见的场景,也有很多常见的方式可以实现对应用的限流比如通过令牌桶通过滑动窗口等等方式都可以实现,也可以在整个请求流程中进行限流比如客户端限流就是在客户端通过随机数直接 ...
随机推荐
- redis数据结构分析 (redisObject、SDS)
redis是一个key-value储存系统.和Memcached类似,它支持存储的value类型相对更多,包括string(字符串).list(链表).set(集合).zset(sorted set ...
- eclipse导入项目后出现红色叉号的解决方案
对于一名程序员来说,我导入的项目在项目的名称上无端加了一个红色的叉号,虽然这个不友好的符号,对于我整个的项目运行没有任何影响,但是总让我觉得不舒服,大大的叉号写在我的项目的脑袋上,我心里能舒服吗?于是 ...
- storedownloadd占用cpu高
禁用App Store的自动更新
- NLP传统基础(3)---潜在语义分析LSA主题模型---SVD得到降维矩阵
https://www.jianshu.com/p/9fe0a7004560 一.简单介绍 LSA和传统向量空间模型(vector space model)一样使用向量来表示词(terms)和文档(d ...
- HTTP通过Get请求传递参数时特殊字符被转码的处理方式
有些符号在URL中是不能直接传递的,如果要在URL中传递这些特殊符号,那么就要使用他们的编码了. 编码的格式为:%加字符的ASCII码,即一个百分号%,后面跟对应字符的ASCII(16进制)码值.例如 ...
- virtualBox+centOS的一些报错
step1: 安装系统后进入命令行模式 安装virtualBox:https://www.virtualbox.org/wiki/Downloads 下载centOS7镜像:https://www.c ...
- 24、自动装配-@Profile环境搭建
24.自动装配-@Profile环境搭建 Spring为我们提供的可以根据当前环境,动态的激活和切换一系列组件的功能. 开发环境.测试环境.正式环境 数据源切换 24.1 添加 数据源和jdbc驱动 ...
- js.map文件意义(转)
什么是source map文件 source map文件是js文件压缩后,文件的变量名替换对应.变量所在位置等元信息数据文件,一般这种文件和min.js主文件放在同一个目录下. 比如压缩后原变量是ma ...
- paramiko的使用
import paramiko import sys user = "root" pwd = " # 上传文件 def sftp_upload_file(server_p ...
- Appium自动化测试教程-自学网-SDK
SDK:软件开发工具包,被软件开发工程师用于特定的软件包.软件框架.硬件平台.操作系统等建立应用软件的开发工具的集合. 因此,Android SDK指的是Android专属的软件开发工具包. 1,安装 ...