神经网络优化算法:梯度下降法、Momentum、RMSprop和Adam
最近回顾神经网络的知识,简单做一些整理,归档一下神经网络优化算法的知识。关于神经网络的优化,吴恩达的深度学习课程讲解得非常通俗易懂,有需要的可以去学习一下,本人只是对课程知识点做一个总结。吴恩达的深度学习课程放在了网易云课堂上,链接如下(免费):
https://mooc.study.163.com/smartSpec/detail/1001319001.htm
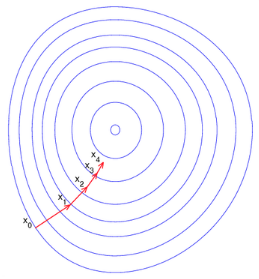
神经网络最基本的优化算法是反向传播算法加上梯度下降法。通过梯度下降法,使得网络参数不断收敛到全局(或者局部)最小值,但是由于神经网络层数太多,需要通过反向传播算法,把误差一层一层地从输出传播到输入,逐层地更新网络参数。由于梯度方向是函数值变大的最快的方向,因此负梯度方向则是函数值变小的最快的方向。沿着负梯度方向一步一步迭代,便能快速地收敛到函数最小值。这就是梯度下降法的基本思想,从下图可以很直观地理解其含义。
梯度下降法的迭代公式如下:
\[w=w-\alpha* dw\]
其中w是待训练的网络参数,\(\alpha\)是学习率,是一个常数,dw是梯度。以上是梯度下降法的最基本形式,在此基础上,研究人员提出了其他多种变种,使得梯度下降法收敛更加迅速和稳定,其中最优秀的代表便是Mommentum, RMSprop和Adam等。
Momentum算法
Momentum算法又叫做冲量算法,其迭代更新公式如下:
\[\begin{cases} v=\beta v+(1-\beta)dw \\ w=w-\alpha v \end{cases}\]
光看上面的公式有些抽象,我们先介绍一下指数加权平均,再回过头来看这个公式,会容易理解得多。
指数加权平均
假设我们有一年365天的气温数据\(\theta_1,\theta_2,...,\theta_{365}\),把他们化成散点图,如下图所示:
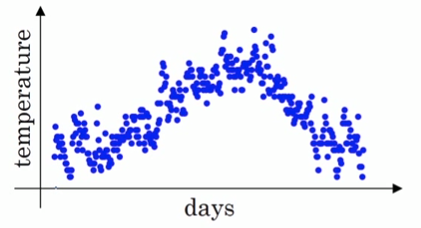
这些数据有些杂乱,我们想画一条曲线,用来表征这一年气温的变化趋势,那么我们需要把数据做一次平滑处理。最常见的方法是用一个华东窗口滑过各个数据点,计算窗口的平均值,从而得到数据的滑动平均值。但除此之外,我们还可以使用指数加权平均来对数据做平滑。其公式如下:
\[\begin{cases} v_0=0 \\ v_k=\beta v_{k-1}+(1-\beta)\theta_k, \quad k=1,2,...,365 \end{cases}\]
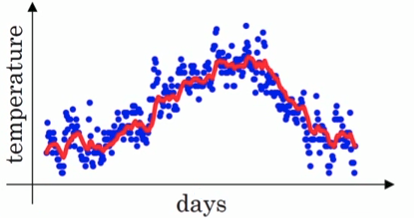
v就是指数加权平均值,也就是平滑后的气温。\(\beta\)的典型值是0.9,平滑后的曲线如下图所示:
对于\(v_k=\beta v_{k-1}+(1-\beta)\theta_k\),我们把它展开,可以得到如下形式:
\[\begin{split} v_k&=\beta v_{k-1}+(1-\beta)\theta_k \\ &=\beta^kv_0+\beta^{k-1}(1-\beta)\theta_1+\beta^{k-2}(1-\beta)\theta_2+\dots+\beta(1-\beta)\theta_{k-1}+(1-\beta)\theta_k \\ &=\beta^{k-1}(1-\beta)\theta_1+\beta^{k-2}(1-\beta)\theta_2+\dots+\beta(1-\beta)\theta_{k-1}+(1-\beta)\theta_k \end{split}\]
可见,平滑后的气温,是以往每一天原始气温的加权平均值,只是这个权值是随时间的远近而变化的,离今天越远,权值越小,且呈指数衰减。从今天往前数k天,它的权值为\(\beta^k(1-\beta)\)。当\(\beta=\frac{1}{1-\beta}\)时,由于\(\underset{\beta \rightarrow 1}{lim}\beta^k(1-\beta)=e^{-1}\),权重已经非常小,更久远一些的气温数据权重更小,可以认为对今天的气温没有影响。因此,可以认为指数加权平均计算的是最近\(\frac{1}{1-\beta}\)个数据的加权平均值。通常\(\beta\)取值为0.9,相当于计算10个数的加权平均值。但是按照原始的指数加权平均公式,还有一个问题,就是当k比较小时,其最近的数据太少,导致估计误差比较大。例如\(v_1=0.9 v_0 + (1-0.9)\theta_1=0.1\theta_1\)。为了减小最初几个数据的误差,通常对于k比较小时,需要做如下修正:
\[v_k=\frac{\beta v_{k-1}+(1-\beta)\theta_k}{1-\beta^k}\]
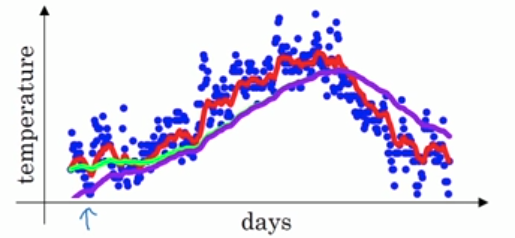
\(1-\beta^k\)是所有权重的和,这相当于对权重做了一个归一化处理。下面的图中,紫色的线就是没有做修正的结果,修正之后就是绿色曲线。二者在前面几个数据点之间相差较大,后面则基本重合了。
回看Momentum算法
现在再回过头来看Momentum算法的迭代更新公式:
\[\begin{cases} v=\beta v+(1-\beta)dw \\ w=w-\alpha v \end{cases}\]
\(dw\)是我们计算出来的原始梯度,\(v\)则是用指数加权平均计算出来的梯度。这相当于对原始梯度做了一个平滑,然后再用来做梯度下降。实验表明,相比于标准梯度下降算法,Momentum算法具有更快的收敛速度。为什么呢?看下面的图,蓝线是标准梯度下降法,可以看到收敛过程中产生了一些震荡。这些震荡在纵轴方向上是均匀的,几乎可以相互抵消,也就是说如果直接沿着横轴方向迭代,收敛速度可以加快。Momentum通过对原始梯度做了一个平滑,正好将纵轴方向的梯度抹平了(红线部分),使得参数更新方向更多地沿着横轴进行,因此速度更快。
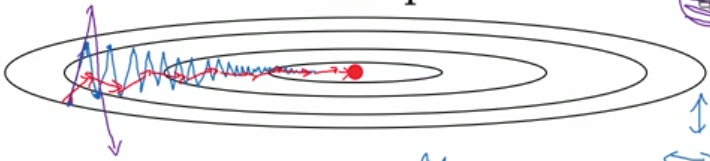
RMSprop算法
对于上面的这个椭圆形的抛物面(图中的椭圆代表等高线),沿着横轴收敛速度是最快的,所以我们希望在横轴(假设记为w1)方向步长大一些,在纵轴(假设记为w2)方向步长小一些。这时候可以通过RMSprop实现,迭代更新公式如下:
\[\begin{cases} s_1=\beta_1 s_1+(1-\beta_1)dw_1^2 \\ s_2=\beta_2 s_2+(1-\beta_2)dw_2^2 \end{cases}\]
\[\begin{cases} w_1=w_1-\alpha \frac{dw_1}{\sqrt{s_1+\epsilon}} \\ w_2=w_2-\alpha \frac{dw_2}{\sqrt{s_2+\epsilon}} \end{cases}\]
观察上面的公式可以看到,s是对梯度的平方做了一次平滑。在更新w时,先用梯度除以\(\sqrt{s_1+\epsilon}\),相当于对梯度做了一次归一化。如果某个方向上梯度震荡很大,应该减小其步长;而震荡大,则这个方向的s也较大,除完之后,归一化的梯度就小了;如果某个方向上梯度震荡很小,应该增大其步长;而震荡小,则这个方向的s也较小,归一化的梯度就大了。因此,通过RMSprop,我们可以调整不同维度上的步长,加快收敛速度。把上式合并后,RMSprop迭代更新公式如下:
\[\begin{cases} s=\beta s+(1-\beta)dw^2 \\ w=w-\alpha\frac{dw}{\sqrt{s+\epsilon}} \end{cases}\]
\(\beta\)的典型值是0.999。公式中还有一个\(\epsilon\),这是一个很小的数,典型值是\(10^{-8}\)。
Adam算法
Adam算法则是以上二者的结合。先看迭代更新公式:
\[\begin{cases} v=\beta_1 v+(1-\beta_1)dw \\ s=\beta_2 s+(1-\beta_2)dw^2 \\ w=w-\alpha\frac{v}{\sqrt{s+\epsilon}} \end{cases}\]
典型值:\(\beta_1=0.9, \quad \beta_2=0.999, \quad \epsilon=10^{-8}\)。Adam算法相当于先把原始梯度做一个指数加权平均,再做一次归一化处理,然后再更新梯度值。
神经网络优化算法:梯度下降法、Momentum、RMSprop和Adam的更多相关文章
- 改善深层神经网络_优化算法_mini-batch梯度下降、指数加权平均、动量梯度下降、RMSprop、Adam优化、学习率衰减
1.mini-batch梯度下降 在前面学习向量化时,知道了可以将训练样本横向堆叠,形成一个输入矩阵和对应的输出矩阵: 当数据量不是太大时,这样做当然会充分利用向量化的优点,一次训练中就可以将所有训练 ...
- 机器学习入门-BP神经网络模型及梯度下降法-2017年9月5日14:58:16
BP(Back Propagation)网络是1985年由Rumelhart和McCelland为首的科学家小组提出,是一种按误差逆传播算法训练的多层前馈网络,是目前应用最广泛的神经网络模型之一. B ...
- BP神经网络模型及梯度下降法
BP(Back Propagation)网络是1985年由Rumelhart和McCelland为首的科学家小组提出,是一种按误差逆传播算法训练的多层前馈网络,是目前应用最广泛的神经网络模型之一. B ...
- 神经网络优化算法如何选择Adam,SGD
之前在tensorflow上和caffe上都折腾过CNN用来做视频处理,在学习tensorflow例子的时候代码里面给的优化方案默认很多情况下都是直接用的AdamOptimizer优化算法,如下: o ...
- 机器学习之路: 深度学习 tensorflow 神经网络优化算法 学习率的设置
在神经网络中,广泛的使用反向传播和梯度下降算法调整神经网络中参数的取值. 梯度下降和学习率: 假设用 θ 来表示神经网络中的参数, J(θ) 表示在给定参数下训练数据集上损失函数的大小. 那么整个优化 ...
- 神经网络优化算法:Dropout、梯度消失/爆炸、Adam优化算法,一篇就够了!
1. 训练误差和泛化误差 机器学习模型在训练数据集和测试数据集上的表现.如果你改变过实验中的模型结构或者超参数,你也许发现了:当模型在训练数据集上更准确时,它在测试数据集上却不⼀定更准确.这是为什么呢 ...
- AI-Tensorflow-神经网络优化算法-梯度下降算法-学习率
记录内容来自<Tensorflow实战Google一书>及MOOC人工智能实践 http://www.icourse163.org/learn/PKU-1002536002?tid=100 ...
- 各种梯度下降 bgd sgd mbgd adam
转载 https://blog.csdn.net/itchosen/article/details/77200322 各种神经网络优化算法:从梯度下降到Adam方法 在调整模型更新权重和偏差 ...
- 优化深度神经网络(二)优化算法 SGD Momentum RMSprop Adam
Coursera吴恩达<优化深度神经网络>课程笔记(2)-- 优化算法 深度机器学习中的batch的大小 深度机器学习中的batch的大小对学习效果有何影响? 1. Mini-batch ...
随机推荐
- Steps 步骤条
引导用户按照流程完成任务的分步导航条,可根据实际应用场景设定步骤,步骤不得少于 2 步. 基础用法 简单的步骤条. 设置active属性,接受一个Number,表明步骤的 index,从 0 开始.需 ...
- 阶段3 3.SpringMVC·_07.SSM整合案例_02.ssm整合之搭建环境
创建数据库ssm并创建表account create database ssm; use ssm; create table account( id int primary key auto_incr ...
- JavaScript(2):函数
<!DOCTYPE html> <html> <body> <p>JavaScript 函数</p> <script> // 函 ...
- Bat:IP切换,内外网切换,路由设置内外网同时连接
1.IP切换: @echo off ::双冒号表示注释,注释只能单独一行写,@表示不让执行的命令又显示在屏幕上 cls ::清屏 color c ::设置显示字体颜色 set IP=10.10.17. ...
- Django路由系统-URL命名&URL反向解析
命名URL和URL反向解析 前言 起始样式,HTML中的href是写死的,不能更改,如下示例代码: # urls中 urlpatterns = [ url(r'^admin/', admin.site ...
- centos 6.5安装erlang和RabbitMQ
一.安装erlang 1.下载erlang源码 git clone https://github.com/erlang/otp.git 2.编译并安装erlang cd otp ./otp_build ...
- 【神经网络与深度学习】【C/C++】ZLIB学习2
Zlib文件压缩和解压 开源代码:http://www.zlib.net/ zlib使用手册:http://www.zlib.net/manual.html zlib wince版:http://ww ...
- appium环境搭建(一)----安装appium
一.安装appium Appium官方网站:http://appium.io/,官方首页给出了appium的安装步骤. > brew install node # get node.js > ...
- C++多线程基础学习笔记(七)
一.std::async和std::future的用法 std::async是一个函数模板,std::future是一个类模板 #include <iostream> #include & ...
- liunx 安装rsync
新建一个rsync.s文件,把下面的代码写入文件里: #!/usr/bin/env bash mkdir -p /data/app/rsync/etc/ mkdir -p /data/logs/rsy ...