SVM支持向量机实例
波士顿房价回归分析
1.导入波士顿房价数据集
############################# svm实例--波士顿房价回归分析 #######################################
#导入numpy
import numpy as np
#导入画图工具
import matplotlib.pyplot as plt
#导入波士顿房价数据集
from sklearn.datasets import load_boston
boston = load_boston()
#打印数据集中的键
print(boston.keys()) #打印数据集中的短描述
#print(boston['DESCR'])
dict_keys(['data', 'target', 'feature_names', 'DESCR', 'filename'])
2.使用SVR进行建模
#导入数据集拆分工具
from sklearn.model_selection import train_test_split
#建立训练数据集和测试数据集
X,y = boston.data,boston.target
X_train,X_test,y_train,y_test = train_test_split(X,y,random_state=8)
print('\n\n\n')
print('代码运行结果')
print('====================================\n')
#打印训练集和测试集的形态
print(X_train.shape)
print(X_test.shape)
print('\n====================================')
print('\n\n\n')
代码运行结果
====================================
(379, 13)
(127, 13)
====================================
#导入支持向量机回归模型
from sklearn.svm import SVR
#分别测试linear核函数和rbf核函数
for kernel in ['linear','rbf']:
svr = SVR(kernel = kernel,gamma = 'auto')
svr.fit(X_train,y_train)
print(kernel,'核函数的模型训练集得分: {:.3f}'.format(svr.score(X_train,y_train)))
print(kernel,'核函数的模型测试集得分: {:.3f}'.format(svr.score(X_test,y_test)))
linear 核函数的模型训练集得分: 0.709
linear 核函数的模型测试集得分: 0.696
rbf 核函数的模型训练集得分: 0.145
rbf 核函数的模型测试集得分: 0.001
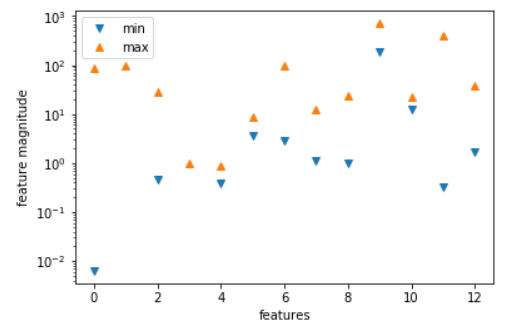
#将特征数值中的最小值和最大值用散点画出来
plt.plot(X.min(axis=0),'v',label='min')
plt.plot(X.max(axis=0),'^',label='max')
#设定纵坐标为对数形式
plt.yscale('log')
#设置图注位置为最佳
plt.legend(loc='best')
#设定横纵轴标题
plt.xlabel('features')
plt.ylabel('feature magnitude')
#显示图形
plt.show()
3.用StandardScaler进行数据预处理
#导入数据预处理工具
from sklearn.preprocessing import StandardScaler
#对训练集和测试集进行数据预处理
scaler = StandardScaler()
scaler.fit(X_train)
X_train_scaled = scaler.transform(X_train)
X_test_scaled = scaler.transform(X_test) #将预处理后的数据特征最大值和最小值用散点图表示出来 plt.plot(X_train_scaled.min(axis=0),'v',label='train set min')
plt.plot(X_train_scaled.max(axis=0),'^',label='train set max')
plt.plot(X_test_scaled.min(axis=0),'v',label='test set min')
plt.plot(X_test_scaled.max(axis=0),'^',label='test set max') #设置图注位置为最佳
plt.legend(loc='best')
#设定横纵轴标题
plt.xlabel('scaled features')
plt.ylabel('scaled feature magnitude')
#显示图形
plt.show()

4.数据预处理后重新训练模型
#用预处理后的数据重新训练模型
for kernel in ['linear','rbf']:
svr = SVR(kernel = kernel)
svr.fit(X_train_scaled,y_train)
print('数据预处理后',kernel,'核函数的模型训练集得分: {:.3f}'.format(svr.score(X_train_scaled,y_train)))
print('数据预处理后',kernel,'核函数的模型测试集得分: {:.3f}'.format(svr.score(X_test_scaled,y_test)))
数据预处理后 linear 核函数的模型训练集得分: 0.706
数据预处理后 linear 核函数的模型测试集得分: 0.698
数据预处理后 rbf 核函数的模型训练集得分: 0.665
数据预处理后 rbf 核函数的模型测试集得分: 0.695
#设置"rbf"内核的SVR模型的C参数和gamma参数
svr = SVR(C=100,gamma=0.1)
svr.fit(X_train_scaled,y_train)
print('调节参数后的"rbf"内核的SVR模型在训练集得分:{:.3f}'.format(svr.score(X_train_scaled,y_train)))
print('调节参数后的"rbf"内核的SVR模型在测试集得分:{:.3f}'.format(svr.score(X_test_scaled,y_test)))
调节参数后的"rbf"内核的SVR模型在训练集得分:0.966
调节参数后的"rbf"内核的SVR模型在测试集得分:0.894
总结:
我们通过对数据预处理和参数的调节,使"rbf"内核的SVR模型在测试集中的得分从0.001升到0.894,
于是我们可以知道SVM算法对数据预处理和调参的要求非常高.
文章引自 : 《深入浅出python机器学习》
SVM支持向量机实例的更多相关文章
- 机器学习进阶-svm支持向量机
支持向量机需要解决的问题:找出一条最好的决策边界将两种类型的点进行分开 这个时候我们需要考虑一个问题,在找到一条直线将两种点分开时,是否具有其他的约束条件,这里我们在满足找到一条决策边界时,同时使得距 ...
- 机器学习实战 - 读书笔记(06) – SVM支持向量机
前言 最近在看Peter Harrington写的"机器学习实战",这是我的学习笔记,这次是第6章:SVM 支持向量机. 支持向量机不是很好被理解,主要是因为里面涉及到了许多数学知 ...
- Python实现SVM(支持向量机)
Python实现SVM(支持向量机) 运行环境 Pyhton3 numpy(科学计算包) matplotlib(画图所需,不画图可不必) 计算过程 st=>start: 开始 e=>end ...
- SVM支持向量机的基本原理
SVM支持向量机的基本原理 对于很多分类问题,例如最简单的,一个平面上的两类不同的点,如何将它用一条直线分开?在平面上我们可能无法实现,但是如果通过某种映射,将这些点映射到其它空间(比如说球面上等), ...
- 6-11 SVM支持向量机2
SVM支持向量机的核:线性核.进行预测的时候我们需要把正负样本的数据装载在一起,同时我们label标签也要把正负样本的数据全部打上一个label. 第四步,开始训练和预测.ml(machine lea ...
- 6-10 SVM支持向量机1
都是特征加上分类器.还将为大家介绍如何对这个数据进行训练.如何训练得到这样一组数据. 其实SVM支持向量机,它的本质仍然是一个分类器.既然是一个分类器,它就具有分类的功能.我们可以使用一条直线来完成分 ...
- SVM 支持向量机算法-实战篇
公号:码农充电站pro 主页:https://codeshellme.github.io 上一篇介绍了 SVM 的原理和一些基本概念,本篇来介绍如何用 SVM 处理实际问题. 1,SVM 的实现 SV ...
- SVM 支持向量机
学习策略:间隔最大化(解凸二次规划的问题) 对于上图,如果采用感知机,可以找到无数条分界线区分正负类,SVM目的就是找到一个margin 最大的 classifier,因此这个分界线(超平 ...
- SVM(支持向量机)算法
第一步.初步了解SVM 1.0.什么是支持向量机SVM 要明白什么是SVM,便得从分类说起. 分类作为数据挖掘领域中一项非常重要的任务,它的目的是学会一个分类函数或分类模型(或者叫做分类器),而支持向 ...
随机推荐
- PHP实现执行定时任务
首先用命令检查服务是否在运行 systemctl status crond.service 如果服务器上没有装有crontab ,则可以执行 yum install vixie-cron yum in ...
- 002 centos7中遇到的问题
在关机的时候,发现输入密码之后竟然报错了,然后确认普通用户的密码没有问题.下面是处理方式. 一:问题 1.问题 当在终端执行sudo命令时,系统提示“caojun is not in the sudo ...
- Tomcat7/8/8.5三种版本的redis-session-manager的jar和xml配置均不同
chexagon/redis-session-manager: A tomcat8 session manager providing session replication via persiste ...
- flutter Checkbox 复选框组件
import 'package:flutter/material.dart'; class CheckboxDemo extends StatefulWidget { @override _Check ...
- 【转】Python读取PDF文档,输出内容
Python3读取pdf文档,输出内容(txt) from urllib.request import urlopen from pdfminer.pdfinterp import PDFResour ...
- dtypes.py", line 499 _np_qint8 = np.dtype([("qint8", np.int8, (1,)])
Traceback (most recent call last): File "<stdin>", line 1, in <module> File &q ...
- linux下配置face_recognition
1.如linux下已有python2.7,但需要更新一下python 2.7至python2.x sudo add-apt-repository ppa:fkrull/deadsnakes-pytho ...
- Apache Flink 开发环境搭建和应用的配置、部署及运行
https://mp.weixin.qq.com/s/noD2Jv6m-somEMtjWTJh3w 本文是根据 Apache Flink 系列直播课程整理而成,由阿里巴巴高级开发工程师沙晟阳分享,主要 ...
- window下安装docker
下载docker toolbox https://mirrors.aliyun.com/docker-toolbox/windows/docker-toolbox/ 1,.双击安装DockerTool ...
- 带你进入异步Django+Vue的世界 - Didi打车实战
https://www.jianshu.com/p/7e5f2090555d#!/xh?tdsourcetag=s_pcqq_aiomsg