Hadoop hadoop(2.9.0)---uber模式(小作业“ubertask”优化)
前言:
在有些情况下,运行于Hadoop集群上的一些mapreduce作业本身的数据量并不是很大,如果此时的任务分片很多,那么为每个map任务或者reduce任务频繁创建Container,势必会增加Hadoop集群的资源消耗,并且因为创建分配Container本身的开销,还会增加这些任务的运行时延。如果能将这些小任务都放入少量的Container中执行,将会解决这些问题。好在Hadoop本身已经提供了这种功能,只需要我们理解其原理,并应用它。
Uber运行模式就是解决此类问题的现成解决方案。
uber运行模式:
Uber运行模式对小作业进行优化,不会给每个任务分别申请分配Container资源,这些小任务将统一在一个Container中按照先执行map任务后执行reduce任务的顺序串行执行。那么什么样的任务,mapreduce框架会认为它是小任务呢?
- map任务的数量不大于mapreduce.job.ubertask.maxmaps参数(默认值是9)的值;
- reduce任务的数量不大于mapreduce.job.ubertask.maxreduces参数(默认值是1)的值;
- 输入文件大小不大于mapreduce.job.ubertask.maxbytes参数(默认为1个Block的字节大小)的值;
- map任务和reduce任务需要的资源量不能大于MRAppMaster(mapreduce作业的ApplicationMaster)可用的资源总量;也就是说yarn.app.mapreduce.am.resource.mb必须大于mapreduce.map.memory.mb和mapreduce.reduce.memory.mb以及yarn.app .mapreduce.am.resource.cpu-vcores必须大于mapreduce.map.cpu.vcores和mapreduce.reduce.cpu.vcores以启用ubertask。
参数mapreduce.job.ubertask.enable用来控制是否开启Uber运行模式,默认为false。
优化:该优化在单个JVM中按顺序运行“足够小”的作业。
以WordCount例
(1)限制任务的划分数量:
hadoop自带的Wordcount程序里面,MapReduce数量已经通过Job.setNumReduceTasks(int)方法已经设置为1,因此满足mapreduce.job.ubertask.maxreduces参数的限制。所以我们首先控制下map任务的数量,我们通过设置mapreduce.input.fileinputformat.split.maxsize参数来限制。看看在满足小任务前提,但是不开启Uber运行模式时的执行情况。执行命令如下:
[hadoop@master hadoop-2.9.0]$ hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.9.0.jar wordcount -D mapreduce.input.fileinputformat.split.maxsize=6 /wc.input /wc.output_2
file wc.intput为25K 参数 mapreduce.input.fileinputformat.split.maxsize=6 是以k为单位,我这里在分片的时候指定的6K,所以,最终分的片为5个,从下图可以明显的看出来,处理的总文件为1,分片数量为5,uber模式为false;还可以看到一共6个map任务,一个reduce任务。
结果如下:

web界面查看:

(2)开启uber模式
[hadoop@master hadoop-2.9.0]$ hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.9.0.jar wordcount -D mapreduce.input.fileinputformat.split.maxsize=6 -D mapreduce.job.ubertask.enable=true /wc.input /wc.output_5
wc.input 35k
结果如下:

这里是是6个map任务和1个reduce任务,但是之前的数据本地map任务= 5一行信息已经变为当地的其他maptasks=6。此外还增加了TOTAL_LAUNCHED_UBERTASKS、NUM_UBER_SUBMAPS、NUM_UBER_SUBREDUCES等信息,如下图所示:
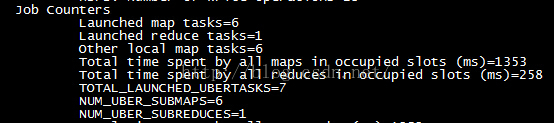
以下列出这几个信息的含义:
| 输出字段 | 描述 |
| TOTAL_LAUNCHED_UBERTASKS | 启动的Uber任务数 |
| NUM_UBER_SUBMAPS | Uber任务中的map任务数 |
| NUM_UBER_SUBREDUCES | Uber中reduce任务数 |
其他测试
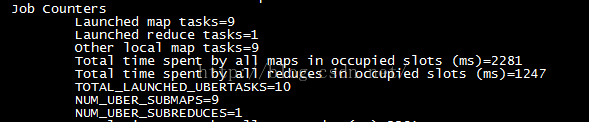
由于我主动控制了分片大小,导致分片数量是6,这小于mapreduce.job.ubertask.maxmaps参数的默认值9。按照之前的介绍,当map任务数量大于9时,那么这个作业就不会被认为小任务。所以我们先将分片大小调整为20字节,使得map任务的数量刚好等于9,然后执行以下命令:
[hadoop@master hadoop-2.9.0]hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.9.0.jar wordcount -D mapreduce.input.fileinputformat.split.maxsize=20 -D mapreduce.job.ubertask.enable=true /wc.input /wc.output_6
file:wc.input 为172k

我们看到的确将输入数据划分为9份了其它信息如下
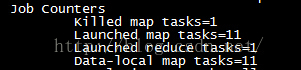
[hadoop@master hadoop-2.9.0]hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.9.0.jar wordcount -D mapreduce.input.fileinputformat.split.maxsize=19 -D mapreduce.job.ubertask.enable=true /wc.input /wc.output_7

我们看到的确将输入数据划分为10份了其它信息如下:
- 设置当map任务全部运行结束后才开始reduce任务(参数mapreduce.job.reduce.slowstart.completedmaps设置为1.0,默认0.05)。
- 将当前Job的最大map任务尝试执行次数(参数mapreduce.map.maxattempts)和最大reduce任务尝试次数(参数mapreduce.reduce.maxattempts)都设置为1,默认为4。
- 取消当前Job的map任务的推断执行(参数mapreduce.map.speculative设置为false)和reduce任务的推断执行(参数mapreduce.reduce.speculative设置为false),默认为。
Hadoop hadoop(2.9.0)---uber模式(小作业“ubertask”优化)的更多相关文章
- Hadoop上路-01_Hadoop2.3.0的分布式集群搭建
一.配置虚拟机软件 下载地址:https://www.virtualbox.org/wiki/downloads 1.虚拟机软件设定 1)进入全集设定 2)常规设定 2.Linux安装配置 1)名称类 ...
- 从Hadoop骨架MapReduce在海量数据处理模式(包括淘宝技术架构)
从hadoop框架与MapReduce模式中谈海量数据处理 前言 几周前,当我最初听到,以致后来初次接触Hadoop与MapReduce这两个东西,我便稍显兴奋,认为它们非常是神奇.而神奇的东西常能勾 ...
- hadoop环境搭建之关于NAT模式静态IP的设置 ---VMware12+CentOs7
很久没有更新了,主要是没有时间,今天挤出时间验证了一下,果然还是有些问题的,不过已经解决了,就发上来吧. PS:小豆腐看仔细了哦~ 关于hadoop环境搭建,从单机模式,到伪分布式,再到完全分布式,我 ...
- Hadoop之搭建完全分布式运行模式
一.过程分析 1.准备3台客户机(关闭防火墙.修改静态ip.主机名称) 2.安装JDK 3.配置环境变量 4.安装Hadoop 5.配置集群 6.单点启动 7.配置ssh免密登录 8.群起并测试集群 ...
- Hadoop 2.x 版本的单机模式安装
Hadoop 2.x 版本比起之前的版本在Hadoop和MapReduce上做了许多变化,主要的变化之一,是JobTracker被ResourceManager和ApplicationManager所 ...
- 【hadoop】hadoop3.2.0的安装并测试
前言:前段时间将hadoop01的虚拟机弄的崩溃掉了,也没有备份,重新从hadoop02虚拟上克隆过来的,结果hadoop-eclipse插件一样的编译,居然用不起了,找了3天的原因,最后还是没有解决 ...
- 简单说明hadoop集群运行三种模式和配置文件
Hadoop的运行模式分为3种:本地运行模式,伪分布运行模式,集群运行模式,相应概念如下: 1.独立模式即本地运行模式(standalone或local mode)无需运行任何守护进程(daemon) ...
- [hadoop] hadoop 运行 wordcount
讲准备好的文本文件放到hdfs中 执行 hadoop 安装包中的例子 [root@hadoop01 mapreduce]# hadoop jar hadoop-mapreduce-examples-2 ...
- hadoop hadoop install (1)
vmuser@vmuser-VirtualBox:~$ sudo useradd -m hadoop -s /bin/bash[sudo] vmuser 的密码: vmuser@vmuser-Virt ...
随机推荐
- C# 字符串补位方法
string i=9; 方法1:Console.WriteLine(i.ToString("D5")); 方法2:Console.WriteLine(i.ToString().Pa ...
- 测试人员必须掌握的linu常用命令
有些公司需要测试人员部署程序包,通过工具xshell. 现在我将总结下工作需要用到的最多的命令 ls 显示文件或目录 pwd ...
- sublime text3上设置 python 环境
1. 打开Sublime text 3 安装package control 2. 安装 SublimeREPL Preferences -> package control 或者Ctrl+shi ...
- solr的post.jar
http://iamyida.iteye.com/blog/2207920 跟益达学Solr5之玩转post.jar
- 安卓开发之生成cache目录和files目录
package com.lidaochen.test; import android.os.Bundle; import android.support.v7.app.AppCompatActivit ...
- git命令——git commit
功能 将暂存区中的更改记录到仓库. 加到staging area里面的文件,是表示已经准备好commit的.所以在commit修改之前,务必确定所有修改文件都是staged的.对于unstaged的文 ...
- 温控PID自测验程序
#pragma once #ifndef _PID_H_ #define _PID_H_ #include <vector> #include <map> using name ...
- WIN10试用
技巧 Win10技巧3.智能化窗口排列 排列窗口时后面的内容被挡住无疑让人倍感郁闷,Win10很好地解决了这个问题.当我们通过拖拽法将一个窗口分屏显示时(目前仅限1/2比例),操作系统就会利用屏幕剩余 ...
- HDU - 5706 - Girlcat - 简单搜索 - 新手都可以看懂的详解
原题链接: 大致题意:给你一个二维字符串,可以看成图:再给两个子串“girl”和“cat”,求图中任意起点开始的不间断连接起来的字母构成的两个子串的分别的个数:连接的方向只有不间断的上下左右. 搜索函 ...
- attr方法笔记(反射)
attr方法笔记 attr中用到了四个内置面向对象方法(__getattr__,__setattr__,__hasattr__,__delattr__),这称为反射,由于python中一切皆对象,反射 ...