Python学习路程day16
Python之路,Day14 - It's time for Django
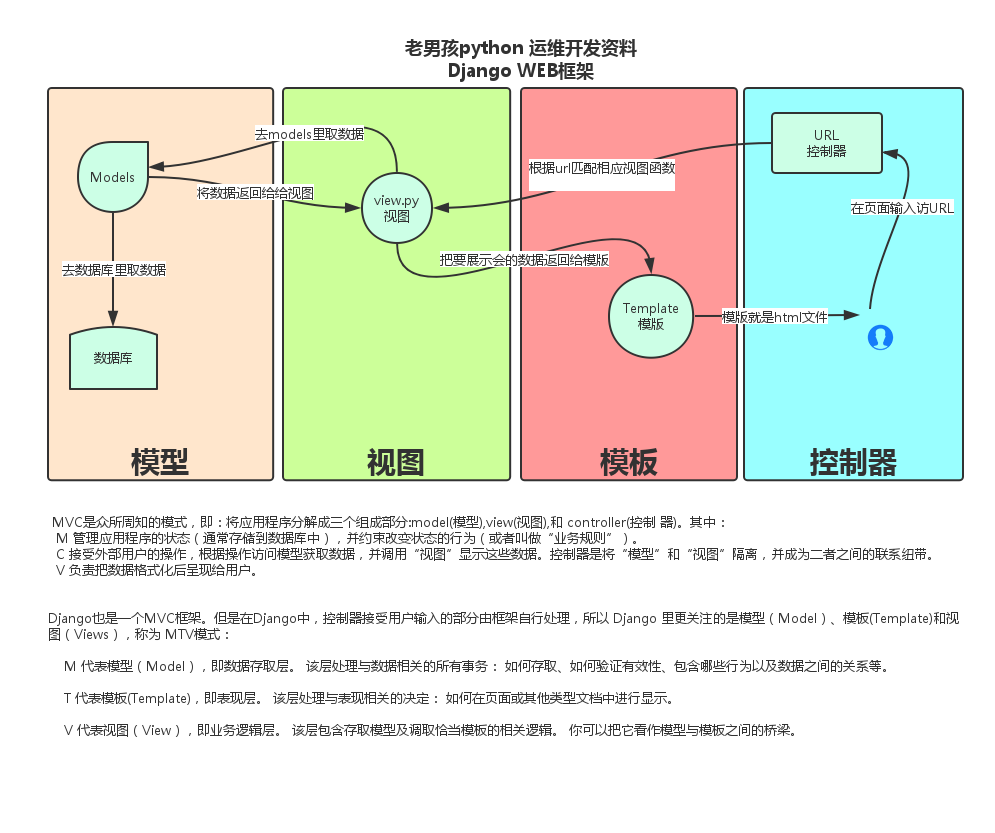
本节内容
Django流程介绍
Django url
Django view
Django models
Django template
Django form
Django admin
Django流程介绍
Django URL
Example
Here’s a sample URLconf:
from django.conf.urls import url from . import views urlpatterns = [
url(r'^articles/2003/$', views.special_case_2003),
url(r'^articles/([0-9]{4})/$', views.year_archive),
url(r'^articles/([0-9]{4})/([0-9]{2})/$', views.month_archive),
url(r'^articles/([0-9]{4})/([0-9]{2})/([0-9]+)/$', views.article_detail),
]
Notes:
- To capture a value from the URL, just put parenthesis around it.
- There’s no need to add a leading slash, because every URL has that. For example, it’s
^articles, not^/articles. - The
'r'in front of each regular expression string is optional but recommended. It tells Python that a string is “raw” – that nothing in the string should be escaped. See Dive Into Python’s explanation.
Example requests:
- A request to
/articles/2005/03/would match the third entry in the list. Django would call the functionviews.month_archive(request, '2005', '03'). /articles/2005/3/would not match any URL patterns, because the third entry in the list requires two digits for the month./articles/2003/would match the first pattern in the list, not the second one, because the patterns are tested in order, and the first one is the first test to pass. Feel free to exploit the ordering to insert special cases like this. Here, Django would call the functionviews.special_case_2003(request)/articles/2003would not match any of these patterns, because each pattern requires that the URL end with a slash./articles/2003/03/03/would match the final pattern. Django would call the functionviews.article_detail(request, '2003', '03', '03').
Named groups
The above example used simple, non-named regular-expression groups (via parenthesis) to capture bits of the URL and pass them as positional arguments to a view. In more advanced usage, it’s possible to use named regular-expression groups to capture URL bits and pass them as keyword arguments to a view.
In Python regular expressions, the syntax for named regular-expression groups is (?P<name>pattern), where name is the name of the group and pattern is some pattern to match.
Here’s the above example URLconf, rewritten to use named groups:
from django.conf.urls import url from . import views urlpatterns = [
url(r'^articles/2003/$', views.special_case_2003),
url(r'^articles/(?P<year>[0-9]{4})/$', views.year_archive),
url(r'^articles/(?P<year>[0-9]{4})/(?P<month>[0-9]{2})/$', views.month_archive),
url(r'^articles/(?P<year>[0-9]{4})/(?P<month>[0-9]{2})/(?P<day>[0-9]{2})/$', views.article_detail),
]
This accomplishes exactly the same thing as the previous example, with one subtle difference: The captured values are passed to view functions as keyword arguments rather than positional arguments. For example:
- A request to
/articles/2005/03/would call the functionviews.month_archive(request, year='2005',month='03'), instead ofviews.month_archive(request, '2005', '03'). - A request to
/articles/2003/03/03/would call the functionviews.article_detail(request, year='2003',month='03', day='03').
In practice, this means your URLconfs are slightly more explicit and less prone to argument-order bugs – and you can reorder the arguments in your views’ function definitions. Of course, these benefits come at the cost of brevity; some developers find the named-group syntax ugly and too verbose.
What the URLconf searches against¶
The URLconf searches against the requested URL, as a normal Python string. This does not include GET or POST parameters, or the domain name.
For example, in a request to https://www.example.com/myapp/, the URLconf will look for myapp/.
In a request to https://www.example.com/myapp/?page=3, the URLconf will look for myapp/.
The URLconf doesn’t look at the request method. In other words, all request methods – POST, GET, HEAD, etc. – will be routed to the same function for the same URL.
Captured arguments are always strings¶
Each captured argument is sent to the view as a plain Python string, regardless of what sort of match the regular expression makes. For example, in this URLconf line:
url(r'^articles/(?P<year>[0-9]{4})/$', views.year_archive),
...the year argument passed to views.year_archive() will be a string,not an integer, even though the [0-9]{4} will only match integer strings.
Including other URLconfs¶
At any point, your urlpatterns can “include” other URLconf modules. This essentially “roots” a set of URLs below other ones.
For example, here’s an excerpt of the URLconf for the Django website itself. It includes a number of other URLconfs:
from django.conf.urls import include, url urlpatterns = [
# ... snip ...
url(r'^community/', include('django_website.aggregator.urls')),
url(r'^contact/', include('django_website.contact.urls')),
# ... snip ...
]
Note that the regular expressions in this example don’t have a $ (end-of-string match character) but do include a trailing slash. Whenever Django encounters include() (django.conf.urls.include()), it chops off whatever part of the URL matched up to that point and sends the remaining string to the included URLconf for further processing.
Another possibility is to include additional URL patterns by using a list of url() instances. For example, consider this URLconf:
from django.conf.urls import include, url from apps.main import views as main_views
from credit import views as credit_views extra_patterns = [
url(r'^reports/$', credit_views.report),
url(r'^reports/(?P<id>[0-9]+)/$', credit_views.report),
url(r'^charge/$', credit_views.charge),
] urlpatterns = [
url(r'^$', main_views.homepage),
url(r'^help/', include('apps.help.urls')),
url(r'^credit/', include(extra_patterns)),
]
In this example, the /credit/reports/ URL will be handled by the credit_views.report() Django view.
This can be used to remove redundancy from URLconfs where a single pattern prefix is used repeatedly. For example, consider this URLconf:
from django.conf.urls import url
from . import views urlpatterns = [
url(r'^(?P<page_slug>[\w-]+)-(?P<page_id>\w+)/history/$', views.history),
url(r'^(?P<page_slug>[\w-]+)-(?P<page_id>\w+)/edit/$', views.edit),
url(r'^(?P<page_slug>[\w-]+)-(?P<page_id>\w+)/discuss/$', views.discuss),
url(r'^(?P<page_slug>[\w-]+)-(?P<page_id>\w+)/permissions/$', views.permissions),
]
We can improve this by stating the common path prefix only once and grouping the suffixes that differ:
from django.conf.urls import include, url
from . import views urlpatterns = [
url(r'^(?P<page_slug>[\w-]+)-(?P<page_id>\w+)/', include([
url(r'^history/$', views.history),
url(r'^edit/$', views.edit),
url(r'^discuss/$', views.discuss),
url(r'^permissions/$', views.permissions),
])),
]
Passing extra options to view functions
URLconfs have a hook that lets you pass extra arguments to your view functions, as a Python dictionary.
The django.conf.urls.url() function can take an optional third argument which should be a dictionary of extra keyword arguments to pass to the view function.
For example:
from django.conf.urls import url
from . import views urlpatterns = [
url(r'^blog/(?P<year>[0-9]{4})/$', views.year_archive, {'foo': 'bar'}),
]
In this example, for a request to /blog/2005/, Django will call views.year_archive(request, year='2005',foo='bar').
This technique is used in the syndication framework to pass metadata and options to views.
Dealing with conflicts
It’s possible to have a URL pattern which captures named keyword arguments, and also passes arguments with the same names in its dictionary of extra arguments. When this happens, the arguments in the dictionary will be used instead of the arguments captured in the URL.
Passing extra options to include()¶
Similarly, you can pass extra options to include(). When you pass extra options to include(), each line in the included URLconf will be passed the extra options.
For example, these two URLconf sets are functionally identical:
Set one:
# main.py
from django.conf.urls import include, url urlpatterns = [
url(r'^blog/', include('inner'), {'blogid': 3}),
] # inner.py
from django.conf.urls import url
from mysite import views urlpatterns = [
url(r'^archive/$', views.archive),
url(r'^about/$', views.about),
]
Set two:
# main.py
from django.conf.urls import include, url
from mysite import views urlpatterns = [
url(r'^blog/', include('inner')),
] # inner.py
from django.conf.urls import url urlpatterns = [
url(r'^archive/$', views.archive, {'blogid': 3}),
url(r'^about/$', views.about, {'blogid': 3}),
]
Note that extra options will always be passed to every line in the included URLconf, regardless of whether the line’s view actually accepts those options as valid. For this reason, this technique is only useful if you’re certain that every view in the included URLconf accepts the extra options you’re passing.
Django Views
最简单的返回一个字符串形式的view
from django.http import HttpResponse def my_view(request):
if request.method == 'GET':
# <view logic>
return HttpResponse('result')
如果想直接返回一个html文档
from django.shortcuts import render,HttpResponse # Create your views here. def test_view(request):
return render(request,'index.html')
Django Models
django 本身提供了非常强大易使用的ORM组件,并且支持多种数据库,如sqllite,mysql,progressSql,Oracle等,当然最常用的搭配还是mysql,要启用orm,先要配置好连接数据 的信息
在你创建的project目录下编辑settings.py
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.mysql',
'NAME': 'OldboyWebsite', #确保此数据库已存在
'HOST':'',
'PORT':'',
'USER':'root',
'PASSWORD':''
}
}
下面要开始学习Django ORM语法了,为了更好的理解,我们来做一个基本的 书籍/作者/出版商 数据库结构。 我们这样做是因为 这是一个众所周知的例子,很多SQL有关的书籍也常用这个举例。
我们来假定下面的这些概念、字段和关系:
一个作者有姓,有名及email地址。
出版商有名称,地址,所在城市、省,国家,网站。
书籍有书名和出版日期。 它有一个或多个作者(和作者是多对多的关联关系[many-to-many]), 只有一个出版商(和出版商是一对多的关联关系[one-to-many],也被称作外键[foreign key])
from django.db import models class Publisher(models.Model):
name = models.CharField(max_length=30)
address = models.CharField(max_length=50)
city = models.CharField(max_length=60)
state_province = models.CharField(max_length=30)
country = models.CharField(max_length=50)
website = models.URLField() class Author(models.Model):
first_name = models.CharField(max_length=30)
last_name = models.CharField(max_length=40)
email = models.EmailField() class Book(models.Model):
title = models.CharField(max_length=100)
authors = models.ManyToManyField(Author)
publisher = models.ForeignKey(Publisher)
publication_date = models.DateField()
更多models field 字段:https://docs.djangoproject.com/en/1.9/ref/models/fields/
每个模型相当于单个数据库表,每个属性也是这个表中的一个字段。 属性名就是字段名,它的类型(例如CharField )相当于数据库的字段类型 (例如 varchar )。例如, Publisher 模块等同于下面这张表(用PostgreSQL的 CREATE TABLE 语法描述):
CREATE TABLE "books_publisher" (
"id" serial NOT NULL PRIMARY KEY,
"name" varchar(30) NOT NULL,
"address" varchar(50) NOT NULL,
"city" varchar(60) NOT NULL,
"state_province" varchar(30) NOT NULL,
"country" varchar(50) NOT NULL,
"website" varchar(200) NOT NULL
);
模型安装
完成这些代码之后,现在让我们来在数据库中创建这些表。 要完成该项工作,第一步是在 Django 项目中 激活这些模型。 将上面的模型所在的app (此例子app是books) 添加到配置文件的已安装应用列表中即可完成此步骤。
再次编辑 settings.py 文件, 找到 INSTALLED_APPS 设置。 INSTALLED_APPS 告诉 Django 项目哪些 app 处于激活状态。 缺省情况下如下所示:
INSTALLED_APPS = (
'django.contrib.auth',
'django.contrib.contenttypes',
'django.contrib.sessions',
'django.contrib.sites',
'books',
)
使数据库按照模型的配置生成表结构
Jies-MacBook-Air:s12django jieli$ python manage.py makemigrations #生成同步纪录
Migrations for 'app01':
0001_initial.py:
- Create model Author
- Create model Book
- Create model Publisher
- Add field publisher to book
Jies-MacBook-Air:s12django jieli$ python manage.py migrate #开始同步
Operations to perform:
Apply all migrations: admin, contenttypes, app01, auth, sessions
Running migrations:
Rendering model states... DONE
Applying app01.0001_initial... OK
基本数据访问
一旦你创建了模型,Django自动为这些模型提供了高级的Python API。 运行 python manage.py shell 并输入下面的内容试试看:
>>> from books.models import Publisher
>>> p1 = Publisher(name='Apress', address='2855 Telegraph Avenue',
... city='Berkeley', state_province='CA', country='U.S.A.',
... website='http://www.apress.com/')
>>> p1.save()
>>> p2 = Publisher(name="O'Reilly", address='10 Fawcett St.',
... city='Cambridge', state_province='MA', country='U.S.A.',
... website='http://www.oreilly.com/')
>>> p2.save()
>>> publisher_list = Publisher.objects.all()
>>> publisher_list
[<Publisher: Publisher object>, <Publisher: Publisher object>]
这里有一个值得注意的地方,在这个例子可能并未清晰地展示。 当你使用Django modle API创建对象时Django并未将对象保存至数据库内,除非你调用`` save()`` 方法:
p1 = Publisher(...)
# At this point, p1 is not saved to the database yet!
p1.save()
# Now it is.
如果需要一步完成对象的创建与存储至数据库,就使用`` objects.create()`` 方法。 下面的例子与之前的例子等价:
>>> p1 = Publisher.objects.create(name='Apress',
... address='2855 Telegraph Avenue',
... city='Berkeley', state_province='CA', country='U.S.A.',
... website='http://www.apress.com/')
>>> p2 = Publisher.objects.create(name="O'Reilly",
... address='10 Fawcett St.', city='Cambridge',
... state_province='MA', country='U.S.A.',
... website='http://www.oreilly.com/')
>>> publisher_list = Publisher.objects.all()
>>> publisher_list
__unicode__()方法是个什么鬼?
当我们打印整个publisher列表时,我们没有得到想要的有用信息,无法把````对象区分开来:
[<Publisher: Publisher object>, <Publisher: Publisher object>]
我们可以简单解决这个问题,只需要为Publisher 对象添加一个方法 __unicode__() 。 __unicode__() 方法告诉Python如何将对象以unicode的方式显示出来。 为以上三个模型添加__unicode__()方法后,就可以看到效果了。
def __unicode__(self):
return self.name
对__unicode__()的唯一要求就是它要返回一个unicode对象 如果`` __unicode__()`` 方法未返回一个Unicode对象,而返回比如说一个整型数字,那么Python将抛出一个`` TypeError`` 错误,并提示:”coercing to Unicode: need string or buffer, int found” 。
插入和更新数据
你已经知道怎么做了: 先使用一些关键参数创建对象实例,如下:
>>> p = Publisher(name='Apress',
... address='2855 Telegraph Ave.',
... city='Berkeley',
... state_province='CA',
... country='U.S.A.',
... website='http://www.apress.com/')
这个对象实例并 没有 对数据库做修改。 在调用`` save()`` 方法之前,记录并没有保存至数据库,像这样:
>>> p.save()
在SQL里,这大致可以转换成这样:
INSERT INTO books_publisher
(name, address, city, state_province, country, website)
VALUES
('Apress', '2855 Telegraph Ave.', 'Berkeley', 'CA',
'U.S.A.', 'http://www.apress.com/');
因为 Publisher 模型有一个自动增加的主键 id ,所以第一次调用 save() 还多做了一件事: 计算这个主键的值并把它赋值给这个对象实例:
>>> p.id
52 # this will differ based on your own data
接下来再调用 save() 将不会创建新的记录,而只是修改记录内容(也就是 执行 UPDATE SQL语句,而不是 INSERT语句):
>>> p.name = 'Apress Publishing'
>>> p.save()
前面执行的 save() 相当于下面的SQL语句:
UPDATE books_publisher SET
name = 'Apress Publishing',
address = '2855 Telegraph Ave.',
city = 'Berkeley',
state_province = 'CA',
country = 'U.S.A.',
website = 'http://www.apress.com'
WHERE id = 52;
注意,并不是只更新修改过的那个字段,所有的字段都会被更新。
查找对象
当然,创建新的数据库,并更新之中的数据是必要的,但是,对于 Web 应用程序来说,更多的时候是在检索查询数据库。 我们已经知道如何从一个给定的模型中取出所有记录:
>>> Publisher.objects.all()
[<Publisher: Apress>, <Publisher: O'Reilly>]
这相当于这个SQL语句:
SELECT id, name, address, city, state_province, country, website
FROM books_publisher;
注意
注意到Django在选择所有数据时并没有使用 SELECT* ,而是显式列出了所有字段。 设计的时候就是这样:SELECT* 会更慢,而且最重要的是列出所有字段遵循了Python 界的一个信条: 明言胜于暗示。
数据过滤
我们很少会一次性从数据库中取出所有的数据;通常都只针对一部分数据进行操作。 在Django API中,我们可以使用`` filter()`` 方法对数据进行过滤:
>>> Publisher.objects.filter(name='Apress')
[<Publisher: Apress>]
filter() 根据关键字参数来转换成 WHERE SQL语句。 前面这个例子 相当于这样:
SELECT id, name, address, city, state_province, country, website
FROM books_publisher
WHERE name = 'Apress';
你可以传递多个参数到 filter() 来缩小选取范围:
>>> Publisher.objects.filter(country="U.S.A.", state_province="CA")
[<Publisher: Apress>]
多个参数会被转换成 AND SQL从句, 因此上面的代码可以转化成这样:
SELECT id, name, address, city, state_province, country, website
FROM books_publisher
WHERE country = 'U.S.A.'
AND state_province = 'CA';
注意,SQL缺省的 = 操作符是精确匹配的, 其他类型的查找也可以使用:
>>> Publisher.objects.filter(name__contains="press")
[<Publisher: Apress>]
在 name 和 contains 之间有双下划线。和Python一样,Django也使用双下划线来表明会进行一些魔术般的操作。这里,contains部分会被Django翻译成LIKE语句:
SELECT id, name, address, city, state_province, country, website
FROM books_publisher
WHERE name LIKE '%press%';
其他的一些查找类型有:icontains(大小写不敏感的LIKE),startswith和endswith, 还有range
获取单个对象
上面的例子中`` filter()`` 函数返回一个记录集,这个记录集是一个列表。 相对列表来说,有些时候我们更需要获取单个的对象, `` get()`` 方法就是在此时使用的:
>>> Publisher.objects.get(name="Apress")
<Publisher: Apress>
这样,就返回了单个对象,而不是列表(更准确的说,QuerySet)。 所以,如果结果是多个对象,会导致抛出异常:
>>> Publisher.objects.get(country="U.S.A.")
Traceback (most recent call last):
...
MultipleObjectsReturned: get() returned more than one Publisher --
it returned 2! Lookup parameters were {'country': 'U.S.A.'}
如果查询没有返回结果也会抛出异常:
>>> Publisher.objects.get(name="Penguin")
Traceback (most recent call last):
...
DoesNotExist: Publisher matching query does not exist.
这个 DoesNotExist 异常 是 Publisher 这个 model 类的一个属性,即 Publisher.DoesNotExist。在你的应用中,你可以捕获并处理这个异常,像这样:
try:
p = Publisher.objects.get(name='Apress')
except Publisher.DoesNotExist:
print "Apress isn't in the database yet."
else:
print "Apress is in the database."
数据排序
在运行前面的例子中,你可能已经注意到返回的结果是无序的。 我们还没有告诉数据库 怎样对结果进行排序,所以我们返回的结果是无序的。
在你的 Django 应用中,你或许希望根据某字段的值对检索结果排序,比如说,按字母顺序。 那么,使用order_by() 这个方法就可以搞定了。
>>> Publisher.objects.order_by("name")
[<Publisher: Apress>, <Publisher: O'Reilly>]
跟以前的 all() 例子差不多,SQL语句里多了指定排序的部分:
SELECT id, name, address, city, state_province, country, website
FROM books_publisher
ORDER BY name;
我们可以对任意字段进行排序:
>>> Publisher.objects.order_by("address")
[<Publisher: O'Reilly>, <Publisher: Apress>]
>>> Publisher.objects.order_by("state_province")
[<Publisher: Apress>, <Publisher: O'Reilly>]
如果需要以多个字段为标准进行排序(第二个字段会在第一个字段的值相同的情况下被使用到),使用多个参数就可以了,如下:
>>> Publisher.objects.order_by("state_province", "address")
[<Publisher: Apress>, <Publisher: O'Reilly>]
我们还可以指定逆向排序,在前面加一个减号 - 前缀:
>>> Publisher.objects.order_by("-name")
[<Publisher: O'Reilly>, <Publisher: Apress>]
尽管很灵活,但是每次都要用 order_by() 显得有点啰嗦。 大多数时间你通常只会对某些 字段进行排序。 在这种情况下,Django让你可以指定模型的缺省排序方式:
class Publisher(models.Model):
name = models.CharField(max_length=30)
address = models.CharField(max_length=50)
city = models.CharField(max_length=60)
state_province = models.CharField(max_length=30)
country = models.CharField(max_length=50)
website = models.URLField() def __unicode__(self):
return self.name class Meta:
ordering = ['name']
现在,让我们来接触一个新的概念。 class Meta,内嵌于 Publisher 这个类的定义中(如果 class Publisher 是顶格的,那么 class Meta 在它之下要缩进4个空格--按 Python 的传统 )。你可以在任意一个 模型 类中使用Meta 类,来设置一些与特定模型相关的选项。Meta 还可设置很多其它选项,现在,我们关注ordering 这个选项就够了。 如果你设置了这个选项,那么除非你检索时特意额外地使用了 order_by(),否则,当你使用 Django 的数据库 API 去检索时,Publisher对象的相关返回值默认地都会按 name 字段排序。
连锁查询
我们已经知道如何对数据进行过滤和排序。 当然,通常我们需要同时进行过滤和排序查询的操作。 因此,你可以简单地写成这种“链式”的形式:
>>> Publisher.objects.filter(country="U.S.A.").order_by("-name")
[<Publisher: O'Reilly>, <Publisher: Apress>]
你应该没猜错,转换成SQL查询就是 WHERE 和 ORDER BY 的组合:
SELECT id, name, address, city, state_province, country, website
FROM books_publisher
WHERE country = 'U.S.A'
ORDER BY name DESC;
限制返回的数据
另一个常用的需求就是取出固定数目的记录。 想象一下你有成千上万的出版商在你的数据库里, 但是你只想显示第一个。 你可以使用标准的Python列表裁剪语句:
>>> Publisher.objects.order_by('name')[0]
<Publisher: Apress>
这相当于:
SELECT id, name, address, city, state_province, country, website
FROM books_publisher
ORDER BY name
LIMIT 1;
类似的,你可以用Python的range-slicing语法来取出数据的特定子集:
>>> Publisher.objects.order_by('name')[0:2]
这个例子返回两个对象,等同于以下的SQL语句:
SELECT id, name, address, city, state_province, country, website
FROM books_publisher
ORDER BY name
OFFSET 0 LIMIT 2;
注意,不支持Python的负索引(negative slicing):
>>> Publisher.objects.order_by('name')[-1]
Traceback (most recent call last):
...
AssertionError: Negative indexing is not supported.
虽然不支持负索引,但是我们可以使用其他的方法。 比如,稍微修改 order_by() 语句来实现:
>>> Publisher.objects.order_by('-name')[0]
更新多个对象
在“插入和更新数据”小节中,我们有提到模型的save()方法,这个方法会更新一行里的所有列。 而某些情况下,我们只需要更新行里的某几列。
例如说我们现在想要将Apress Publisher的名称由原来的”Apress”更改为”Apress Publishing”。若使用save()方法,如:
>>> p = Publisher.objects.get(name='Apress')
>>> p.name = 'Apress Publishing'
>>> p.save()
这等同于如下SQL语句:
SELECT id, name, address, city, state_province, country, website
FROM books_publisher
WHERE name = 'Apress'; UPDATE books_publisher SET
name = 'Apress Publishing',
address = '2855 Telegraph Ave.',
city = 'Berkeley',
state_province = 'CA',
country = 'U.S.A.',
website = 'http://www.apress.com'
WHERE id = 52;
(注意在这里我们假设Apress的ID为52)
在这个例子里我们可以看到Django的save()方法更新了不仅仅是name列的值,还有更新了所有的列。 若name以外的列有可能会被其他的进程所改动的情况下,只更改name列显然是更加明智的。 更改某一指定的列,我们可以调用结果集(QuerySet)对象的update()方法: 示例如下:
>>> Publisher.objects.filter(id=52).update(name='Apress Publishing')
与之等同的SQL语句变得更高效,并且不会引起竞态条件。
UPDATE books_publisher
SET name = 'Apress Publishing'
WHERE id = 52;
update()方法对于任何结果集(QuerySet)均有效,这意味着你可以同时更新多条记录。 以下示例演示如何将所有Publisher的country字段值由’U.S.A’更改为’USA’:
>>> Publisher.objects.all().update(country='USA')
2
update()方法会返回一个整型数值,表示受影响的记录条数。 在上面的例子中,这个值是2。
删除对象
删除数据库中的对象只需调用该对象的delete()方法即可:
>>> p = Publisher.objects.get(name="O'Reilly")
>>> p.delete()
>>> Publisher.objects.all()
[<Publisher: Apress Publishing>]
同样我们可以在结果集上调用delete()方法同时删除多条记录。这一点与我们上一小节提到的update()方法相似:
>>> Publisher.objects.filter(country='USA').delete()
>>> Publisher.objects.all().delete()
>>> Publisher.objects.all()
[]
删除数据时要谨慎! 为了预防误删除掉某一个表内的所有数据,Django要求在删除表内所有数据时显示使用all()。 比如,下面的操作将会出错:
>>> Publisher.objects.delete()
Traceback (most recent call last):
File "<console>", line 1, in <module>
AttributeError: 'Manager' object has no attribute 'delete'
而一旦使用all()方法,所有数据将会被删除:
>>> Publisher.objects.all().delete()
如果只需要删除部分的数据,就不需要调用all()方法。再看一下之前的例子:
>>> Publisher.objects.filter(country='USA').delete()
Django Template
你可能已经注意到我们在例子视图中返回文本的方式有点特别。 也就是说,HTML被直接硬编码在 Python 代码之中。
def current_datetime(request):
now = datetime.datetime.now()
html = "<html><body>It is now %s.</body></html>" % now
return HttpResponse(html)
尽管这种技术便于解释视图是如何工作的,但直接将HTML硬编码到你的视图里却并不是一个好主意。 让我们来看一下为什么:
对页面设计进行的任何改变都必须对 Python 代码进行相应的修改。 站点设计的修改往往比底层 Python 代码的修改要频繁得多,因此如果可以在不进行 Python 代码修改的情况下变更设计,那将会方便得多。
Python 代码编写和 HTML 设计是两项不同的工作,大多数专业的网站开发环境都将他们分配给不同的人员(甚至不同部门)来完成。 设计者和HTML/CSS的编码人员不应该被要求去编辑Python的代码来完成他们的工作。
程序员编写 Python代码和设计人员制作模板两项工作同时进行的效率是最高的,远胜于让一个人等待另一个人完成对某个既包含 Python又包含 HTML 的文件的编辑工作。
基于这些原因,将页面的设计和Python的代码分离开会更干净简洁更容易维护。 我们可以使用 Django的 模板系统 (Template System)来实现这种模式,这就是本章要具体讨论的问题。
Django 模版基本语法
>>> from django.template import Context, Template
>>> t = Template('My name is {{ name }}.')
>>> c = Context({'name': 'Stephane'})
>>> t.render(c)
u'My name is Stephane.'
同一模板,多个上下文
一旦有了 模板 对象,你就可以通过它渲染多个context, 例如:
>>> from django.template import Template, Context
>>> t = Template('Hello, {{ name }}')
>>> print t.render(Context({'name': 'John'}))
Hello, John
>>> print t.render(Context({'name': 'Julie'}))
Hello, Julie
>>> print t.render(Context({'name': 'Pat'}))
Hello, Pat
无论何时我们都可以像这样使用同一模板源渲染多个context,只进行 一次模板创建然后多次调用render()方法渲染会更为高效:
# Bad
for name in ('John', 'Julie', 'Pat'):
t = Template('Hello, {{ name }}')
print t.render(Context({'name': name})) # Good
t = Template('Hello, {{ name }}')
for name in ('John', 'Julie', 'Pat'):
print t.render(Context({'name': name}))
Django 模板解析非常快捷。 大部分的解析工作都是在后台通过对简短正则表达式一次性调用来完成。 这和基于 XML 的模板引擎形成鲜明对比,那些引擎承担了 XML 解析器的开销,且往往比 Django 模板渲染引擎要慢上几个数量级。
深度变量的查找
在到目前为止的例子中,我们通过 context 传递的简单参数值主要是字符串,然而,模板系统能够非常简洁地处理更加复杂的数据结构,例如list、dictionary和自定义的对象。
在 Django 模板中遍历复杂数据结构的关键是句点字符 (.)。
最好是用几个例子来说明一下。 比如,假设你要向模板传递一个 Python 字典。 要通过字典键访问该字典的值,可使用一个句点:
>>> from django.template import Template, Context
>>> person = {'name': 'Sally', 'age': ''}
>>> t = Template('{{ person.name }} is {{ person.age }} years old.')
>>> c = Context({'person': person})
>>> t.render(c)
u'Sally is 43 years old.'
同样,也可以通过句点来访问对象的属性。 比方说, Python 的 datetime.date 对象有 year 、 month 和 day 几个属性,你同样可以在模板中使用句点来访问这些属性:
>>> from django.template import Template, Context
>>> import datetime
>>> d = datetime.date(1993, 5, 2)
>>> d.year
1993
>>> d.month
5
>>> d.day
2
>>> t = Template('The month is {{ date.month }} and the year is {{ date.year }}.')
>>> c = Context({'date': d})
>>> t.render(c)
u'The month is 5 and the year is 1993.'
这个例子使用了一个自定义的类,演示了通过实例变量加一点(dots)来访问它的属性,这个方法适用于任意的对象。
>>> from django.template import Template, Context
>>> class Person(object):
... def __init__(self, first_name, last_name):
... self.first_name, self.last_name = first_name, last_name
>>> t = Template('Hello, {{ person.first_name }} {{ person.last_name }}.')
>>> c = Context({'person': Person('John', 'Smith')})
>>> t.render(c)
u'Hello, John Smith.'
点语法也可以用来引用对象的* 方法*。 例如,每个 Python 字符串都有 upper() 和 isdigit() 方法,你在模板中可以使用同样的句点语法来调用它们:
>>> from django.template import Template, Context
>>> t = Template('{{ var }} -- {{ var.upper }} -- {{ var.isdigit }}')
>>> t.render(Context({'var': 'hello'}))
u'hello -- HELLO -- False'
>>> t.render(Context({'var': ''}))
u'123 -- 123 -- True'
注意这里调用方法时并* 没有* 使用圆括号 而且也无法给该方法传递参数;你只能调用不需参数的方法。 (我们将在本章稍后部分解释该设计观。)
最后,句点也可用于访问列表索引,例如:
>>> from django.template import Template, Context
>>> t = Template('Item 2 is {{ items.2 }}.')
>>> c = Context({'items': ['apples', 'bananas', 'carrots']})
>>> t.render(c)
u'Item 2 is carrots.'
include 模板标签
在讲解了模板加载机制之后,我们再介绍一个利用该机制的内建模板标签: {% include %} 。该标签允许在(模板中)包含其它的模板的内容。 标签的参数是所要包含的模板名称,可以是一个变量,也可以是用单/双引号硬编码的字符串。 每当在多个模板中出现相同的代码时,就应该考虑是否要使用 {% include %} 来减少重复。
下面这两个例子都包含了 nav.html 模板。这两个例子是等价的,它们证明单/双引号都是允许的。
{% include 'nav.html' %}
{% include "nav.html" %}
下面的例子包含了 includes/nav.html 模板的内容:
{% include 'includes/nav.html' %}
模板继承
到目前为止,我们的模板范例都只是些零星的 HTML 片段,但在实际应用中,你将用 Django 模板系统来创建整个 HTML 页面。 这就带来一个常见的 Web 开发问题: 在整个网站中,如何减少共用页面区域(比如站点导航)所引起的重复和冗余代码?
解决该问题的传统做法是使用 服务器端的 includes ,你可以在 HTML 页面中使用该指令将一个网页嵌入到另一个中。 事实上, Django 通过刚才讲述的 {% include %} 支持了这种方法。 但是用 Django 解决此类问题的首选方法是使用更加优雅的策略—— 模板继承 。
本质上来说,模板继承就是先构造一个基础框架模板,而后在其子模板中对它所包含站点公用部分和定义块进行重载。
让我们通过修改 current_datetime.html 文件,为 current_datetime 创建一个更加完整的模板来体会一下这种做法:
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01//EN">
<html lang="en">
<head>
<title>The current time</title>
</head>
<body>
<h1>My helpful timestamp site</h1>
<p>It is now {{ current_date }}.</p> <hr>
<p>Thanks for visiting my site.</p>
</body>
</html>
这看起来很棒,但如果我们要为第三章的 hours_ahead 视图创建另一个模板会发生什么事情呢?
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01//EN">
<html lang="en">
<head>
<title>Future time</title>
</head>
<body>
<h1>My helpful timestamp site</h1>
<p>In {{ hour_offset }} hour(s), it will be {{ next_time }}.</p> <hr>
<p>Thanks for visiting my site.</p>
</body>
</html>
很明显,我们刚才重复了大量的 HTML 代码。 想象一下,如果有一个更典型的网站,它有导航条、样式表,可能还有一些 JavaScript 代码,事情必将以向每个模板填充各种冗余的 HTML 而告终。
解决这个问题的服务器端 include 方案是找出两个模板中的共同部分,将其保存为不同的模板片段,然后在每个模板中进行 include。 也许你会把模板头部的一些代码保存为 header.html 文件:
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01//EN">
<html lang="en">
<head>
你可能会把底部保存到文件 footer.html :
<hr>
<p>Thanks for visiting my site.</p>
</body>
</html>
对基于 include 的策略,头部和底部的包含很简单。 麻烦的是中间部分。 在此范例中,每个页面都有一个<h1>My helpful timestamp site</h1> 标题,但是这个标题不能放在 header.html 中,因为每个页面的 <title> 是不同的。 如果我们将 <h1> 包含在头部,我们就不得不包含 <title> ,但这样又不允许在每个页面对它进行定制。 何去何从呢?
Django 的模板继承系统解决了这些问题。 你可以将其视为服务器端 include 的逆向思维版本。 你可以对那些不同 的代码段进行定义,而不是 共同 代码段。
第一步是定义 基础模板 , 该框架之后将由 子模板 所继承。 以下是我们目前所讲述范例的基础模板:
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01//EN">
<html lang="en">
<head>
<title>{% block title %}{% endblock %}</title>
</head>
<body>
<h1>My helpful timestamp site</h1>
{% block content %}{% endblock %}
{% block footer %}
<hr>
<p>Thanks for visiting my site.</p>
{% endblock %}
</body>
</html>
这个叫做 base.html 的模板定义了一个简单的 HTML 框架文档,我们将在本站点的所有页面中使用。 子模板的作用就是重载、添加或保留那些块的内容。 (如果你一直按顺序学习到这里,保存这个文件到你的template目录下,命名为 base.html .)
我们使用一个以前已经见过的模板标签: {% block %} 。 所有的 {% block %} 标签告诉模板引擎,子模板可以重载这些部分。 每个{% block %}标签所要做的是告诉模板引擎,该模板下的这一块内容将有可能被子模板覆盖。
现在我们已经有了一个基本模板,我们可以修改 current_datetime.html 模板来 使用它:
{% extends "base.html" %}
{% block title %}The current time{% endblock %}
{% block content %}
<p>It is now {{ current_date }}.</p>
{% endblock %}
再为 hours_ahead 视图创建一个模板,看起来是这样的:
{% extends "base.html" %}
{% block title %}Future time{% endblock %}
{% block content %}
<p>In {{ hour_offset }} hour(s), it will be {{ next_time }}.</p>
{% endblock %}
看起来很漂亮是不是? 每个模板只包含对自己而言 独一无二 的代码。 无需多余的部分。 如果想进行站点级的设计修改,仅需修改 base.html ,所有其它模板会立即反映出所作修改。
以下是其工作方式。 在加载 current_datetime.html 模板时,模板引擎发现了 {% extends %} 标签, 注意到该模板是一个子模板。 模板引擎立即装载其父模板,即本例中的 base.html 。
此时,模板引擎注意到 base.html 中的三个 {% block %} 标签,并用子模板的内容替换这些 block 。因此,引擎将会使用我们在 { block title %} 中定义的标题,对 {% block content %} 也是如此。 所以,网页标题一块将由{% block title %}替换,同样地,网页的内容一块将由 {% block content %}替换。
注意由于子模板并没有定义 footer 块,模板系统将使用在父模板中定义的值。 父模板 {% block %} 标签中的内容总是被当作一条退路。
继承并不会影响到模板的上下文。 换句话说,任何处在继承树上的模板都可以访问到你传到模板中的每一个模板变量。
你可以根据需要使用任意多的继承次数。 使用继承的一种常见方式是下面的三层法:
创建 base.html 模板,在其中定义站点的主要外观感受。 这些都是不常修改甚至从不修改的部分。
为网站的每个区域创建 base_SECTION.html 模板(例如, base_photos.html 和 base_forum.html )。这些模板对base.html 进行拓展,并包含区域特定的风格与设计。
为每种类型的页面创建独立的模板,例如论坛页面或者图片库。 这些模板拓展相应的区域模板。
这个方法可最大限度地重用代码,并使得向公共区域(如区域级的导航)添加内容成为一件轻松的工作。
以下是使用模板继承的一些诀窍:
如果在模板中使用 {% extends %} ,必须保证其为模板中的第一个模板标记。 否则,模板继承将不起作用。
一般来说,基础模板中的 {% block %} 标签越多越好。 记住,子模板不必定义父模板中所有的代码块,因此你可以用合理的缺省值对一些代码块进行填充,然后只对子模板所需的代码块进行(重)定义。 俗话说,钩子越多越好。
如果发觉自己在多个模板之间拷贝代码,你应该考虑将该代码段放置到父模板的某个 {% block %} 中。
如果你需要访问父模板中的块的内容,使用 {{ block.super }}这个标签吧,这一个魔法变量将会表现出父模板中的内容。 如果只想在上级代码块基础上添加内容,而不是全部重载,该变量就显得非常有用了。
不允许在同一个模板中定义多个同名的 {% block %} 。 存在这样的限制是因为block 标签的工作方式是双向的。 也就是说,block 标签不仅挖了一个要填的坑,也定义了在父模板中这个坑所填充的内容。如果模板中出现了两个相同名称的 {% block %} 标签,父模板将无从得知要使用哪个块的内容。
Django Form表单
django中的Form一般有两种功能:
- 输入html
- 验证用户输入
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import re
from django import forms
from django.core.exceptions import ValidationError def mobile_validate(value):
mobile_re = re.compile(r'^(13[0-9]|15[012356789]|17[678]|18[0-9]|14[57])[0-9]{8}$')
if not mobile_re.match(value):
raise ValidationError('手机号码格式错误') class PublishForm(forms.Form): user_type_choice = (
(0, u'普通用户'),
(1, u'高级用户'),
) user_type = forms.IntegerField(widget=forms.widgets.Select(choices=user_type_choice,
attrs={'class': "form-control"})) title = forms.CharField(max_length=20,
min_length=5,
error_messages={'required': u'标题不能为空',
'min_length': u'标题最少为5个字符',
'max_length': u'标题最多为20个字符'},
widget=forms.TextInput(attrs={'class': "form-control",
'placeholder': u'标题5-20个字符'})) memo = forms.CharField(required=False,
max_length=256,
widget=forms.widgets.Textarea(attrs={'class': "form-control no-radius", 'placeholder': u'详细描述', 'rows': 3})) phone = forms.CharField(validators=[mobile_validate, ],
error_messages={'required': u'手机不能为空'},
widget=forms.TextInput(attrs={'class': "form-control",
'placeholder': u'手机号码'})) email = forms.EmailField(required=False,
error_messages={'required': u'邮箱不能为空','invalid': u'邮箱格式错误'},
widget=forms.TextInput(attrs={'class': "form-control", 'placeholder': u'邮箱'})) '''
def __init__(self, *args, **kwargs):
super(SampleImportForm, self).__init__(*args, **kwargs) self.fields['idc'].widget.choices = models.IDC.objects.all().order_by('id').values_list('id','display')
self.fields['business_unit'].widget.choices = models.BusinessUnit.objects.all().order_by('id').values_list('id','name') Forms
'''
先写好一个Form
def test_form_view(request):
if request.method == 'POST':
request_form = PublishForm(request.POST)
if request_form.is_valid():
request_dict = request_form.clean()
print(request_dict)
return render(request,'test.html', {'pub_form':request_form})
else:
pub_form = PublishForm()
return render(request,'test.html',{'pub_form':pub_form}) 写好视图
写好视图
<div>
<form method="post" action="{% url 'test_form' %}">{% csrf_token %} <div>{{ pub_form.user_type }} {{ pub_form.errors.title }}</div>
<div>{{ pub_form.title }}</div>
<div>{{ pub_form.email }}</div>
<div>{{ pub_form.phone }}</div>
<div>{{ pub_form.memo }}</div> {% if pub_form.errors %}
{{ pub_form.errors }}
{% endif %}
<input type="submit" value="提交">
</form> </div>
模板文件
扩展:ModelForm
在使用Model和Form时,都需要对字段进行定义并指定类型,通过ModelForm则可以省去From中字段的定义
class AdminModelForm(forms.ModelForm):
class Meta:
model = models.Admin
#fields = '__all__'
fields = ('username', 'email')
widgets = {
'email' : forms.PasswordInput(attrs={'class':"alex"}),
}
Django Admin
django amdin是django提供的一个后台管理页面,改管理页面提供完善的html和css,使得你在通过Model创建完数据库表之后,就可以对数据进行增删改查,而使用django admin 则需要以下步骤:
- 创建后台管理员
- 配置url
- 注册和配置django admin后台管理页面
1、创建后台管理员
python manage.py createsuperuser
2、配置后台管理url
url(r'^admin/', include(admin.site.urls))
3、注册和配置django admin 后台管理页面
a、在admin中执行如下配置
from django.contrib import admin from app01 import models admin.site.register(models.UserType)
admin.site.register(models.UserInfo)
admin.site.register(models.UserGroup)
admin.site.register(models.Asset)
b、设置数据表名称
class UserType(models.Model):
name = models.CharField(max_length=50) class Meta:
verbose_name = '用户类型'
verbose_name_plural = '用户类型'
c、自定义页面展示
class UserInfoAdmin(admin.ModelAdmin):
list_display = ('username', 'password', 'email') admin.site.register(models.UserType)
admin.site.register(models.UserInfo,UserInfoAdmin)
admin.site.register(models.UserGroup)
d、添加页面搜索过滤等功能
from django.contrib import admin from app01 import models class UserInfoAdmin(admin.ModelAdmin):
list_display = ('username', 'password', 'email')
search_fields = ('username', 'email')
list_filter = ('username', 'email') admin.site.register(models.UserType)
admin.site.register(models.UserInfo,UserInfoAdmin)
admin.site.register(models.UserGroup)
admin.site.register(models.Asset)
-
12345678
>>>fromdjango.templateimportTemplate, Context>>> t=Template('Hello, {{ name }}')>>>printt.render(Context({'name':'John'}))Hello, John>>>printt.render(Context({'name':'Julie'}))Hello, Julie>>>printt.render(Context({'name':'Pat'}))Hello, Pat无论何时我们都可以像这样使用同一模板源渲染多个context,只进行 一次模板创建然后多次调用render()方法渲染会更为高效:
123456789# Badfornamein('John','Julie','Pat'):t=Template('Hello, {{ name }}')printt.render(Context({'name': name}))# Goodt=Template('Hello, {{ name }}')fornamein('John','Julie','Pat'):printt.render(Context({'name': name}))Django 模板解析非常快捷。 大部分的解析工作都是在后台通过对简短正则表达式一次性调用来完成。 这和基于 XML 的模板引擎形成鲜明对比,那些引擎承担了 XML 解析器的开销,且往往比 Django 模板渲染引擎要慢上几个数量级。
深度变量的查找
在到目前为止的例子中,我们通过 context 传递的简单参数值主要是字符串,然而,模板系统能够非常简洁地处理更加复杂的数据结构,例如list、dictionary和自定义的对象。
在 Django 模板中遍历复杂数据结构的关键是句点字符 (.)。
最好是用几个例子来说明一下。 比如,假设你要向模板传递一个 Python 字典。 要通过字典键访问该字典的值,可使用一个句点:
123456>>>fromdjango.templateimportTemplate, Context>>> person={'name':'Sally','age':'43'}>>> t=Template('{{ person.name }} is {{ person.age }} years old.')>>> c=Context({'person': person})>>> t.render(c)u'Sally is 43 years old.'同样,也可以通过句点来访问对象的属性。 比方说, Python 的 datetime.date 对象有 year 、 month 和 day 几个属性,你同样可以在模板中使用句点来访问这些属性:
12345678910111213>>>fromdjango.templateimportTemplate, Context>>>importdatetime>>> d=datetime.date(1993,5,2)>>> d.year1993>>> d.month5>>> d.day2>>> t=Template('The month is {{ date.month }} and the year is {{ date.year }}.')>>> c=Context({'date': d})>>> t.render(c)u'The month is 5 and the year is 1993.'这个例子使用了一个自定义的类,演示了通过实例变量加一点(dots)来访问它的属性,这个方法适用于任意的对象。
12345678>>>fromdjango.templateimportTemplate, Context>>>classPerson(object):...def__init__(self, first_name, last_name):...self.first_name,self.last_name=first_name, last_name>>> t=Template('Hello, {{ person.first_name }} {{ person.last_name }}.')>>> c=Context({'person': Person('John','Smith')})>>> t.render(c)u'Hello, John Smith.'点语法也可以用来引用对象的* 方法*。 例如,每个 Python 字符串都有 upper() 和 isdigit() 方法,你在模板中可以使用同样的句点语法来调用它们:
123456>>>fromdjango.templateimportTemplate, Context>>> t=Template('{{ var }} -- {{ var.upper }} -- {{ var.isdigit }}')>>> t.render(Context({'var':'hello'}))u'hello -- HELLO -- False'>>> t.render(Context({'var':'123'}))u'123 -- 123 -- True'注意这里调用方法时并* 没有* 使用圆括号 而且也无法给该方法传递参数;你只能调用不需参数的方法。 (我们将在本章稍后部分解释该设计观。)
最后,句点也可用于访问列表索引,例如:
12345>>>fromdjango.templateimportTemplate, Context>>> t=Template('Item 2 is {{ items.2 }}.')>>> c=Context({'items': ['apples','bananas','carrots']})>>> t.render(c)u'Item 2 is carrots.'include 模板标签
在讲解了模板加载机制之后,我们再介绍一个利用该机制的内建模板标签: {% include %} 。该标签允许在(模板中)包含其它的模板的内容。 标签的参数是所要包含的模板名称,可以是一个变量,也可以是用单/双引号硬编码的字符串。 每当在多个模板中出现相同的代码时,就应该考虑是否要使用 {% include %} 来减少重复。
下面这两个例子都包含了 nav.html 模板。这两个例子是等价的,它们证明单/双引号都是允许的。
{% include 'nav.html' %}
{% include "nav.html" %}下面的例子包含了 includes/nav.html 模板的内容:
{% include 'includes/nav.html' %}模板继承
到目前为止,我们的模板范例都只是些零星的 HTML 片段,但在实际应用中,你将用 Django 模板系统来创建整个 HTML 页面。 这就带来一个常见的 Web 开发问题: 在整个网站中,如何减少共用页面区域(比如站点导航)所引起的重复和冗余代码?
解决该问题的传统做法是使用 服务器端的 includes ,你可以在 HTML 页面中使用该指令将一个网页嵌入到另一个中。 事实上, Django 通过刚才讲述的 {% include %} 支持了这种方法。 但是用 Django 解决此类问题的首选方法是使用更加优雅的策略—— 模板继承 。
本质上来说,模板继承就是先构造一个基础框架模板,而后在其子模板中对它所包含站点公用部分和定义块进行重载。
让我们通过修改 current_datetime.html 文件,为 current_datetime 创建一个更加完整的模板来体会一下这种做法:
12345678910111213<!DOCTYPE HTML PUBLIC"-//W3C//DTD HTML 4.01//EN"><html lang="en"><head><title>The current time</title></head><body><h1>My helpful timestamp site</h1><p>Itisnow {{ current_date }}.</p><hr><p>Thanksforvisiting my site.</p></body></html>这看起来很棒,但如果我们要为第三章的 hours_ahead 视图创建另一个模板会发生什么事情呢?
12345678910111213<!DOCTYPE HTML PUBLIC"-//W3C//DTD HTML 4.01//EN"><html lang="en"><head><title>Future time</title></head><body><h1>My helpful timestamp site</h1><p>In {{ hour_offset }} hour(s), it will be {{ next_time }}.</p><hr><p>Thanksforvisiting my site.</p></body></html>很明显,我们刚才重复了大量的 HTML 代码。 想象一下,如果有一个更典型的网站,它有导航条、样式表,可能还有一些 JavaScript 代码,事情必将以向每个模板填充各种冗余的 HTML 而告终。
解决这个问题的服务器端 include 方案是找出两个模板中的共同部分,将其保存为不同的模板片段,然后在每个模板中进行 include。 也许你会把模板头部的一些代码保存为 header.html 文件:
123<!DOCTYPE HTML PUBLIC"-//W3C//DTD HTML 4.01//EN"><html lang="en"><head>你可能会把底部保存到文件 footer.html :
1234<hr><p>Thanksforvisiting my site.</p></body></html>对基于 include 的策略,头部和底部的包含很简单。 麻烦的是中间部分。 在此范例中,每个页面都有一个<h1>My helpful timestamp site</h1> 标题,但是这个标题不能放在 header.html 中,因为每个页面的 <title> 是不同的。 如果我们将 <h1> 包含在头部,我们就不得不包含 <title> ,但这样又不允许在每个页面对它进行定制。 何去何从呢?
Django 的模板继承系统解决了这些问题。 你可以将其视为服务器端 include 的逆向思维版本。 你可以对那些不同 的代码段进行定义,而不是 共同 代码段。
第一步是定义 基础模板 , 该框架之后将由 子模板 所继承。 以下是我们目前所讲述范例的基础模板:
1234567891011121314<!DOCTYPE HTML PUBLIC"-//W3C//DTD HTML 4.01//EN"><html lang="en"><head><title>{%block title%}{%endblock%}</title></head><body><h1>My helpful timestamp site</h1>{%block content%}{%endblock%}{%block footer%}<hr><p>Thanksforvisiting my site.</p>{%endblock%}</body></html>这个叫做 base.html 的模板定义了一个简单的 HTML 框架文档,我们将在本站点的所有页面中使用。 子模板的作用就是重载、添加或保留那些块的内容。 (如果你一直按顺序学习到这里,保存这个文件到你的template目录下,命名为 base.html .)
我们使用一个以前已经见过的模板标签: {% block %} 。 所有的 {% block %} 标签告诉模板引擎,子模板可以重载这些部分。 每个{% block %}标签所要做的是告诉模板引擎,该模板下的这一块内容将有可能被子模板覆盖。
现在我们已经有了一个基本模板,我们可以修改 current_datetime.html 模板来 使用它:
1234567{%extends"base.html"%}{%block title%}The current time{%endblock%}{%block content%}<p>Itisnow {{ current_date }}.</p>{%endblock%}再为 hours_ahead 视图创建一个模板,看起来是这样的:
1234567{%extends"base.html"%}{%block title%}Future time{%endblock%}{%block content%}<p>In {{ hour_offset }} hour(s), it will be {{ next_time }}.</p>{%endblock%}看起来很漂亮是不是? 每个模板只包含对自己而言 独一无二 的代码。 无需多余的部分。 如果想进行站点级的设计修改,仅需修改 base.html ,所有其它模板会立即反映出所作修改。
以下是其工作方式。 在加载 current_datetime.html 模板时,模板引擎发现了 {% extends %} 标签, 注意到该模板是一个子模板。 模板引擎立即装载其父模板,即本例中的 base.html 。
此时,模板引擎注意到 base.html 中的三个 {% block %} 标签,并用子模板的内容替换这些 block 。因此,引擎将会使用我们在 { block title %} 中定义的标题,对 {% block content %} 也是如此。 所以,网页标题一块将由{% block title %}替换,同样地,网页的内容一块将由 {% block content %}替换。
注意由于子模板并没有定义 footer 块,模板系统将使用在父模板中定义的值。 父模板 {% block %} 标签中的内容总是被当作一条退路。
继承并不会影响到模板的上下文。 换句话说,任何处在继承树上的模板都可以访问到你传到模板中的每一个模板变量。
你可以根据需要使用任意多的继承次数。 使用继承的一种常见方式是下面的三层法:
创建 base.html 模板,在其中定义站点的主要外观感受。 这些都是不常修改甚至从不修改的部分。
为网站的每个区域创建 base_SECTION.html 模板(例如, base_photos.html 和 base_forum.html )。这些模板对base.html 进行拓展,并包含区域特定的风格与设计。
为每种类型的页面创建独立的模板,例如论坛页面或者图片库。 这些模板拓展相应的区域模板。
这个方法可最大限度地重用代码,并使得向公共区域(如区域级的导航)添加内容成为一件轻松的工作。
以下是使用模板继承的一些诀窍:
如果在模板中使用 {% extends %} ,必须保证其为模板中的第一个模板标记。 否则,模板继承将不起作用。
一般来说,基础模板中的 {% block %} 标签越多越好。 记住,子模板不必定义父模板中所有的代码块,因此你可以用合理的缺省值对一些代码块进行填充,然后只对子模板所需的代码块进行(重)定义。 俗话说,钩子越多越好。
如果发觉自己在多个模板之间拷贝代码,你应该考虑将该代码段放置到父模板的某个 {% block %} 中。
如果你需要访问父模板中的块的内容,使用 {{ block.super }}这个标签吧,这一个魔法变量将会表现出父模板中的内容。 如果只想在上级代码块基础上添加内容,而不是全部重载,该变量就显得非常有用了。
不允许在同一个模板中定义多个同名的 {% block %} 。 存在这样的限制是因为block 标签的工作方式是双向的。 也就是说,block 标签不仅挖了一个要填的坑,也定义了在父模板中这个坑所填充的内容。如果模板中出现了两个相同名称的 {% block %} 标签,父模板将无从得知要使用哪个块的内容。
Django Form表单
django中的Form一般有两种功能:
- 输入html
- 验证用户输入
先写好一个form写好视图模版文件扩展:ModelForm
在使用Model和Form时,都需要对字段进行定义并指定类型,通过ModelForm则可以省去From中字段的定义
12345678910classAdminModelForm(forms.ModelForm):classMeta:model=models.Admin#fields = '__all__'fields=('username','email')widgets={'email': forms.PasswordInput(attrs={'class':"alex"}),}Django Admin
django amdin是django提供的一个后台管理页面,改管理页面提供完善的html和css,使得你在通过Model创建完数据库表之后,就可以对数据进行增删改查,而使用django admin 则需要以下步骤:
- 创建后台管理员
- 配置url
- 注册和配置django admin后台管理页面
1、创建后台管理员
1python manage.py createsuperuser2、配置后台管理url
1url(r'^admin/', include(admin.site.urls))3、注册和配置django admin 后台管理页面
a、在admin中执行如下配置
12345678fromdjango.contribimportadminfromapp01importmodelsadmin.site.register(models.UserType)admin.site.register(models.UserInfo)admin.site.register(models.UserGroup)admin.site.register(models.Asset)b、设置数据表名称
123456classUserType(models.Model):name=models.CharField(max_length=50)classMeta:verbose_name='用户类型'verbose_name_plural='用户类型'c、自定义页面展示
1234567classUserInfoAdmin(admin.ModelAdmin):list_display=('username','password','email')admin.site.register(models.UserType)admin.site.register(models.UserInfo,UserInfoAdmin)admin.site.register(models.UserGroup)d、添加页面搜索过滤等功能
123456789101112131415fromdjango.contribimportadminfromapp01importmodelsclassUserInfoAdmin(admin.ModelAdmin):list_display=('username','password','email')search_fields=('username','email')list_filter=('username','email')admin.site.register(models.UserType)admin.site.register(models.UserInfo,UserInfoAdmin)admin.site.register(models.UserGroup)admin.site.register(models.Asset)


Python学习路程day16的更多相关文章
- Python学习路程day18
Python之路,Day18 - Django适当进阶篇 本节内容 学员管理系统练习 Django ORM操作进阶 用户认证 Django练习小项目:学员管理系统设计开发 带着项目需求学习是最有趣和效 ...
- Python学习路程day8
Socket语法及相关 socket概念 A network socket is an endpoint of a connection across a computer network. Toda ...
- Python学习路程day6
shelve 模块 shelve模块是一个简单的k,v将内存数据通过文件持久化的模块,可以持久化任何pickle可支持的python数据格式 import shelve d = shelve.open ...
- python 学习路程(一)
好早之前就一直想学python,可是一直没有系统的学习过,给自己立个flag,从今天开始一步步掌握python的用法: python是一种脚本形式的语言,据说是面向废程序员学习开发使用的,我觉得很适合 ...
- Python学习路程-常用设计模式学习
本节内容 设计模式介绍 设计模式分类 设计模式6大原则 1.设计模式介绍 设计模式(Design Patterns) ——可复用面向对象软件的基础 设计模式(Design pattern)是一套被反复 ...
- Python学习路程day19
Python之路,Day19 - Django 进阶 本节内容 自定义template tags 中间件 CRSF 权限管理 分页 Django分页 https://docs.djangoproj ...
- Python学习路程day15
Python之路[第十五篇]:Web框架 Web框架本质 众所周知,对于所有的Web应用,本质上其实就是一个socket服务端,用户的浏览器其实就是一个socket客户端. #!/usr/bin/en ...
- Python学习路程day17
常用算法与设计模式 选择排序 时间复杂度 二.计算方法 1.一个算法执行所耗费的时间,从理论上是不能算出来的,必须上机运行测试才能知道.但我们不可能也没有必要对每个算法都上机测试,只需知道哪个算法花费 ...
- Python学习路程day12
前端内容学习:HTML和CSS <!DOCTYPE html> <html lang="en"> <head> <meta http-eq ...
随机推荐
- this
JavaScript 中的 this ! 2016-12-28 vvv阿城 JavaScript 转自 https://qiutc.me/post/this-this-this-in-javascr ...
- 正则表达式入门(六)匹配unicode和其他字符
匹配unicode字符有时候我们需要匹配ASCII范围之外的字符. "Qu'est-ce que la tolérance? c'est l'apanage de l'humanité. N ...
- cin, cin.getline等函数
char s[100]; cin>>s; // 输入一个字符串,遇“空格”.“TAB”.“回车”都结束 cin.getline(s, 20); // cin.get( ...
- 前端优化之图片延迟加载(lazyload.js)
要想缩短首屏加载时间,思路一般是减少http请求次数和降低每次的请求量.本文中使用现成的lazyload.js插件,文末会放出下载地址. lazyload.js可以实现图片分批次加载,不是一次性加载完 ...
- 并发编程 20—— AbstractQueuedSynchronizer 深入分析
Java并发编程实践 目录 并发编程 01—— ThreadLocal 并发编程 02—— ConcurrentHashMap 并发编程 03—— 阻塞队列和生产者-消费者模式 并发编程 04—— 闭 ...
- Asp.net MVC过滤器的使用
当我们网站开发到这里的时候,我们虽然已经实现了用户登录信息,用户不经过登录信息,比如:http://localhost:6941/UserInfo/Index如果我这样访问的话,他是可以进行操作的,所 ...
- .Net Globalization and Localization
随着互联网的发展日益壮大和活跃,网上购物交易越来越频繁,一个网站支持多种语言在所难免,所以国际化和本地化在现在的网站中的作用越来越大,一个网站的使用量和搜索量有可能受国际化的影响一点.所以在当今做一个 ...
- Rigid motion segmentation
In computer vision, rigid motion segmentation is the process of separating regions, features, or tra ...
- Html.DropDownList
//获取直属父级列表 var parents = _MemberEditDTOService.GetParents(); var parentsItems = parents.Result.Selec ...
- IOS Core Animation Advanced Techniques的学习笔记(三)
第四章:Visual Effects Rounded Corners 例子4.1 cornerRadius 源码在这里下载:http://www.informit.com/title/978013 ...