C#编程总结(九)字符编码
C#编程总结(九)字符编码
相信大家一定遇到过乱码的问题,为什么会乱码呢?输出的数据怎么就跟输入的不一样呢?
最近在总结加密问题,也遇到了同样的困扰。所以今天来集中解决这个问题。
什么是字符?
字符是指计算机中使用的字母、数字、字和符号,包括:1、2、3、A、B、C、~!·#¥%……—*()——+等等。
字符集(Charset)
字符集(Charset)是一个系统支持的所有抽象字符的集合。
字符是各种文字和符号的总称,包括各国家文字、标点符号、图形符号、数字等。
什么是字符编码?
字符编码(Character Encoding):简单的说就是建立自然语言与机器语言之间的对应关系。是一套法则,使用该法则能够对自然语言的字符的一个集合(如字母表或音节表),与其他东西的一个集合(如号码或电脉冲)进行配对。即在符号集合与数字系统之间建立对应关系,它是信息处理的一项基本技术。通常人们用符号集合(一般情况下就是文字)来表达信息。而以计算机为基础的信息处理系统则是利用元件(硬件)不同状态的组合来存储和处理信息的。元件不同状态的组合能代表数字系统的数字,因此字符编码就是将符号转换为计算机可以接受的数字系统的数,称为数字代码。
计算机中的信息包括数据信息和控制信息,数据信息又可分为数值和非数值信息。非数值信息和控制信息包括了字母、各种控制符号、图形符号等,它们都以二进制编码方式存入计算机并得以处理,这种对字母和符号进行编码的二进制代码称为字符代码(Character Code)。计算机中常用的字符编码有ASCII码(美国标准信息交换码)和EBCDIC码(扩展的BCD交换码)。
在 ASCII 编码中,一个英文字母字符存储需要1个字节。在 GB 2312 编码或 GBK 编码中,一个汉字字符存储需要2个字节。在UTF-8编码中,一个英文字母字符存储需要1个字节,一个汉字字符储存需要3到4个字节。在UTF-16编码中,一个英文字母字符或一个汉字字符存储都需要2个字节(Unicode扩展区的一些汉字存储需要4个字节)。在UTF-32编码中,世界上任何字符的存储都需要4个字节。
困扰与疑惑?
1、为什么会有字符编码?
含义介绍中已经给出了解释,字符编码就是让计算机识别自然语言。
2、为什么会有这么多的字符集?
计算机发展分不同阶段,最开始只是美国通用,建立了ASCII码,但是一些欧洲国家字符无法使用ASCII码,然后就对ASCII进行了扩展补充,后来中国要使用计算机,为了标记汉语,定义了GB2312、GBK、BIG5等,还有其他一些字符集。
3、就没有一种统一的字符集吗?
有,Unicode
4、UTF8与Unicode是什么关系?
UTF8是Unicode的一种实现方式。
常用的几种编码
1. ASCII码
ASCII(American Standard Code for Information Interchange,美国信息交换标准代码)是基于拉丁字母的一套电脑编码系统。
ASCII字符集:主要包括控制字符(回车键、退格、换行键等);可显示字符(英文大小写字符、阿拉伯数字和西文符号)。
特点:单字节编码,只包含大小写英文字母、标点符号及其他符号。
ASCII编码:将ASCII字符集转换为计算机可以接受的数字系统的数的规则。使用7位(bits)表示一个字符,共128字符;但是7位编码的字符集只能支持128个字符,为了表示更多的欧洲常用字符对ASCII进行了扩展,ASCII扩展字符集使用8位(bits)表示一个字符,共256字符。
计算机为美国人发明,开始的时候也只能满足自己,所以说此编码很有局限性。在其他的国家、其他语种无法使用此编码集。
根据ASCII码的编码规则,最多只能标识256个字符,但是世界上有那么多语言,汉字就多达10万左右,那么多字符,显然很有局限性。
以下是ASCII代码表,表二为其扩展表。


2、中文编码
2.1 GB2312
特点:简体中文字符集,采用双字节编码。
GB2312或GB2312-80是中国国家标准简体中文字符集,全称《信息交换用汉字编码字符集·基本集》,又称GB0,由中国国家标准总局发布,1981年5月1日实施。GB2312编码通行于中国大陆;新加坡等地也采用此编码。中国大陆几乎所有的中文系统和国际化的软件都支持GB2312。GB2312的出现,基本满足了汉字的计算机处理需要,它所收录的汉字已经覆盖中国大陆99.75%的使用频率。对于人名、古汉语等方面出现的罕用字,GB2312不能处理,这导致了后来GBK及GB 18030汉字字符集的出现。
2.2 GBK
特点:扩展了GB2312,包括非常用简体汉字、繁体字、日语及朝鲜汉字等。
由于GB 2312只收录6763个汉字,有不少汉字,如部分在GB 2312-80推出以后才简化的汉字(如"啰"),部分人名用字(如中国前总理朱镕基的"镕"字),台湾及香港使用的繁体字,日语及朝鲜语汉字等,并未有收录在内。于是厂商微软利用GB 2312-80未使用的编码空间,收录GB 13000.1-93全部字符制定了GBK编码。
2.3 BIG编码
特点:繁体中文,流行于台湾、香港与澳门,采用双字节编码。
Big5,又称为大五码或五大码,是使用繁体中文(正体中文)社区中最常用的电脑汉字字符集标准,共收录13,060个汉字。中文码分为内码及交换码两类,Big5属中文内码,知名的中文交换码有CCCII、CNS11643。Big5虽普及于台湾、香港与澳门等繁体中文通行区,但长期以来并非当地的国家标准,而只是业界标准。Big5码是一套双字节字符集,使用了双八码存储方法,以两个字节来安放一个字。第一个字节称为"高位字节",第二个字节称为"低位字节"。"高位字节"使用了0x81-0xFE,"低位字节"使用了0x40-0x7E,及0xA1-0xFE。
2.4 GB18030
GB 18030,全称:国家标准GB 18030-2005《信息技术 中文编码字符集》,是中华人民共和国现时最新的内码字集,是GB 18030-2000《信息技术 信息交换用汉字编码字符集 基本集的扩充》的修订版。与GB 2312-1980完全兼容,与GBK基本兼容,支持GB 13000及Unicode的全部统一汉字,共收录汉字70244个。
3.Unicode
特点:涵盖所有的文字、符号,每个符号都有独一无二的编码,全世界通用,四字节存储。
Unicode(统一码、万国码、单一码)是一种在计算机上使用的字符编码。Unicode 是为了解决传统的字符编码方案的局限而产生的,它为每种语言中的每个字符设定了统一并且唯一的二进制编码,以满足跨语言、跨平台进行文本转换、处理的要求。1990年开始研发,1994年正式公布。随着计算机工作能力的增强,Unicode也在面世以来的十多年里得到普及。
具体的符号对应表,可以查询unicode.org,或者专门的汉字对应表。
全部编码采用4字节存储,如果是ASCII码,本来是单字节存储的,也要用四字节来存储,前三个字节都是0,很浪费空间。
4.UTF-8
特点:Unicode的一种实现方式,变长的编码方式,可以使用1~4个字节表示一个符号,根据不同的符号而变化字节长度。
互联网的普及,强烈要求出现一种统一的编码方式。UTF-8就是在互联网上使用最广的一种Unicode的实现方式。其他实现方式还包括UTF-16(字符用两个字节或四个字节表示)和UTF-32(字符用四个字节表示),不过在互联网上基本不用。
UTF-8最大的一个特点,就是它是一种变长的编码方式。它可以使用1~4个字节表示一个符号,根据不同的符号而变化字节长度。
UTF-8的编码规则很简单,只有二条:
1)对于单字节的符号,字节的第一位设为0,后面7位为这个符号的unicode码。因此对于英语字母,UTF-8编码和ASCII码是相同的。
2)对于n字节的符号(n>1),第一个字节的前n位都设为1,第n+1位设为0,后面字节的前两位一律设为10。剩下的没有提及的二进制位,全部为这个符号的unicode码。
下表总结了编码规则,字母x表示可用编码的位。
Unicode符号范围 | UTF-8编码方式
(十六进制) | (二进制)
--------------------+---------------------------------------------
0000 0000-0000 007F | 0xxxxxxx
0000 0080-0000 07FF | 110xxxxx 10xxxxxx
0000 0800-0000 FFFF | 1110xxxx 10xxxxxx 10xxxxxx
0001 0000-0010 FFFF | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
跟据上表,解读UTF-8编码非常简单。如果一个字节的第一位是0,则这个字节单独就是一个字符;如果第一位是1,则连续有多少个1,就表示当前字符占用多少个字节。
下面,还是以汉字"严"为例,演示如何实现UTF-8编码。
已知"严"的unicode是4E25(100111000100101),根据上表,可以发现4E25处在第三行的范围内(0000 0800-0000 FFFF),因此"严"的UTF-8编码需要三个字节,即格式是"1110xxxx 10xxxxxx 10xxxxxx"。然后,从"严"的最后一个二进制位开始,依次从后向前填入格式中的x,多出的位补0。这样就得到了,"严"的UTF-8编码是"11100100 10111000 10100101",转换成十六进制就是E4B8A5。
为什么会出现乱码?
由于字符编码不同,一种编码无法兼容另一种编码,就会出现乱码。
举个简单例子,ASCII编码转为UTF8是没问题的,但是当UTF8转ASCII码就可能出问题。
举个简单例子:
你如果是一个会英语的中国人,当一个英国人给你说话时,你明白他的意思,但回答的是中文,他估计不会听懂的。
通过以下例子,来对具体的编码规则以及乱码情况进行比较吧:
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text; namespace EncodingSample
{
class Program
{
/// <summary>
///
/// </summary>
/// <param name="args"></param>
static void Main(string[] args)
{
//英文字符串
string str_en = "Welcome to the Encoding world.";
//简体中文
string str_cn = "欢迎来到编码世界!";
//繁体中文
string str_tw = "歡迎來到編碼世界"; Encoding defaultEncoding = Encoding.Default;
Console.WriteLine("默认编码:{0}", defaultEncoding.BodyName); Encoding dstEncoding = null;
//ASCII码
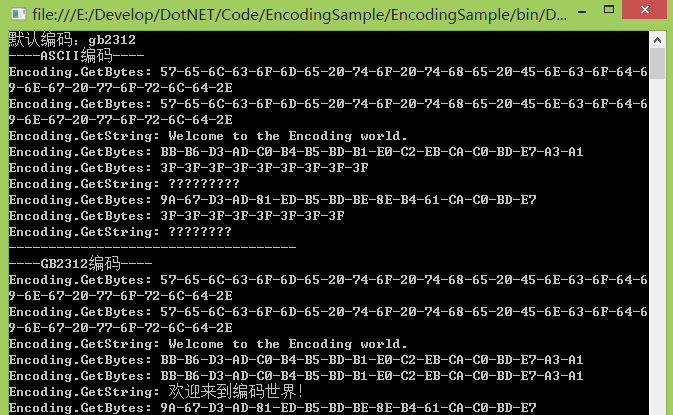
Console.WriteLine("----ASCII编码----");
dstEncoding = Encoding.ASCII;
OutputByEncoding(defaultEncoding, dstEncoding, str_en);
OutputByEncoding(defaultEncoding, dstEncoding, str_cn);
OutputByEncoding(defaultEncoding, dstEncoding, str_tw); OutputBoundary(); //GB2312
Console.WriteLine("----GB2312编码----");
dstEncoding = Encoding.GetEncoding("GB2312");
OutputByEncoding(defaultEncoding, dstEncoding, str_en);
OutputByEncoding(defaultEncoding, dstEncoding, str_cn);
OutputByEncoding(defaultEncoding, dstEncoding, str_tw); OutputBoundary(); //BIG5
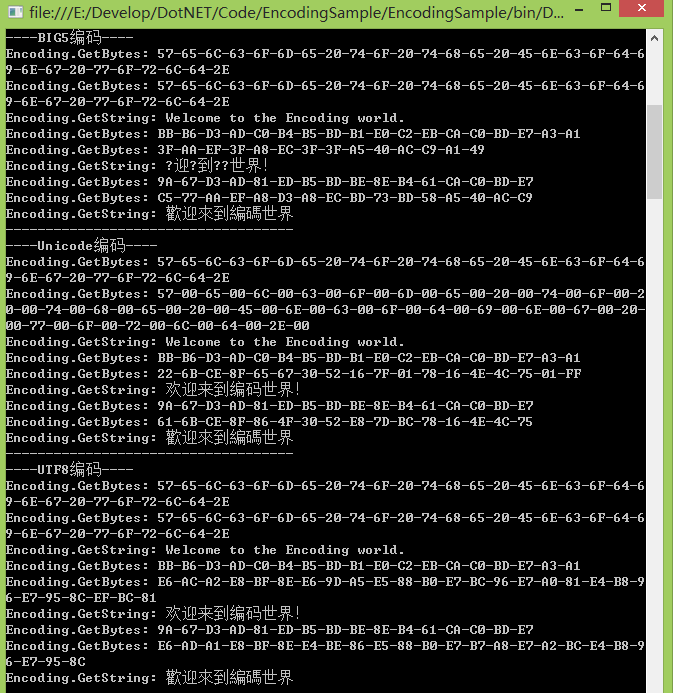
Console.WriteLine("----BIG5编码----");
dstEncoding = Encoding.GetEncoding("BIG5");
OutputByEncoding(defaultEncoding, dstEncoding, str_en);
OutputByEncoding(defaultEncoding, dstEncoding, str_cn);
OutputByEncoding(defaultEncoding, dstEncoding, str_tw); OutputBoundary(); //Unicode
Console.WriteLine("----Unicode编码----");
dstEncoding = Encoding.Unicode;
OutputByEncoding(defaultEncoding, dstEncoding, str_en);
OutputByEncoding(defaultEncoding, dstEncoding, str_cn);
OutputByEncoding(defaultEncoding, dstEncoding, str_tw); OutputBoundary(); //UTF8
Console.WriteLine("----UTF8编码----");
dstEncoding = Encoding.UTF8;
OutputByEncoding(defaultEncoding, dstEncoding, str_en);
OutputByEncoding(defaultEncoding, dstEncoding, str_cn);
OutputByEncoding(defaultEncoding, dstEncoding, str_tw); Console.ReadKey(); }
/// <summary>
///
/// </summary>
/// <param name="srcEncoding">原编码</param>
/// <param name="dstEncoding">目标编码</param>
/// <param name="srcBytes">原</param>
public static void OutputByEncoding(Encoding srcEncoding,Encoding dstEncoding,string srcStr)
{
byte[] srcBytes = srcEncoding.GetBytes(srcStr);
Console.WriteLine("Encoding.GetBytes: {0}", BitConverter.ToString(srcBytes));
byte[] bytes = Encoding.Convert(srcEncoding, dstEncoding, srcBytes);
Console.WriteLine("Encoding.GetBytes: {0}", BitConverter.ToString(bytes));
string result = dstEncoding.GetString(bytes);
Console.WriteLine("Encoding.GetString: {0}", result);
}
/// <summary>
/// 分割线
/// </summary>
public static void OutputBoundary()
{
Console.WriteLine("------------------------------------");
}
}
}
执行结果:
C#编程总结(九)字符编码的更多相关文章
- Python编程笔记二进制、字符编码、数据类型
Python编程笔记二进制.字符编码.数据类型 一.二进制 bin() 在python中可以用bin()内置函数获取一个十进制的数的二进制 计算机容量单位 8bit = 1 bytes 字节,最小的存 ...
- day03 set集合,文件操作,字符编码以及函数式编程
嗯哼,第三天了 我们来get 下新技能,集合,个人认为集合就是用来list 比较的,就是把list 转换为set 然后做一些列表的比较啊求差值啊什么的. 先看怎么生成集合: list_s = [1,3 ...
- Python基础编程:字符编码、数据类型、列表
目录: python简介 字符编码介绍 数据类型 一.Python简介 Python的创始人为Guido van Rossum.1989年圣诞节期间,在阿姆斯特丹,Guido为了打发圣诞节的无趣,决心 ...
- Python编程Day7——字符编码、字符与字节、文件操作
一.字符编码 重点 ***** 1. 什么是字符编码:将人识别的字符转换计算机能识别的01,转换的规则就是字符编码表2. 常用的编码表:ascii.unicode.GBK.Shift_JIS.Euc- ...
- Python编程笔记(第二篇)二进制、字符编码、数据类型
一.二进制 bin() 在python中可以用bin()内置函数获取一个十进制的数的二进制 计算机容量单位 8bit = 1 bytes 字节,最小的存储单位,1bytes缩写为1B 1KB = 10 ...
- python编程笔记--字符编码
ASCII码.Unicode.utf-8 ASCII(American Standard Code for Information Interchange,美国标准信息交换代码)是基于拉丁字母的一套电 ...
- 一篇文章详解python的字符编码问题
一:什么是编码 将明文转换为计算机可以识别的编码文本称为“编码”.反之从计算机可识别的编码文本转回为明文为“解码”. 那么什么是明文呢,首先我们从一段信息说起,消息以人们可以理解,易懂的表示存在,我们 ...
- python基础1之python介绍、安装、变量和字符编码、数据类型、输入输出、数据运算、循环
开启python之路 内容概要: 一.python介绍 二.安装 三.第一个python程序 四.变量和字符编码 五.用户输入 六.数据类型 七.一切皆对象 八.数据运算 九.if else 流程判断 ...
- 详解python的字符编码问题
一:什么是编码 将明文转换为计算机可以识别的编码文本称为“编码”.反之从计算机可识别的编码文本转回为明文为“解码”. 那么什么是明文呢,首先我们从一段信息说起,消息以人们可以理解,易懂的表示存在,我们 ...
随机推荐
- 删除xcode 里的多余证书
删除xcode 里的多余证书 方法一: command+shift+G 前往文件夹: ~/Library/MobileDevice/Provisioning Profiles 方法二: 进入xcode ...
- Bootstrap~Panel和Table
回到目录 在我们对一个页面进行设计时,分块是必须的,没有一个网站是一栏而下的,除非你是在看小说,否则你的页面设计一定是分块的,即它由于多个panel组件,在bootstrap里叫到栅格系统,而在每行每 ...
- PHP 基础
var_dump(empty($a)); 判断变量是否为空 var_dump(isset($a)); 判断变量是否定义 $a=10;unset($a); 删除变量 var_d ...
- iOS-性能优化2
性能优化总结2 iOS应用是非常注重用户体验的,不光是要求界面设计合理美观,也要求各种UI的反应灵敏,我相信大家对那种一拖就卡卡卡的 TableView 应用没什么好印象.还记得12306么,那个速度 ...
- 简述移动端IM开发的那些坑:架构设计、通信协议和客户端
1.前言 有过移动端开发经历的开发者都深有体会:移动端IM的开发,与传统PC端IM有很大的不同,尤其无线网络的不可靠性.移动端硬件设备资源的有限性等问题,导致一个完整的移动端IM架构设计和实现都充满着 ...
- DataGrid--多记录CRUD
最近在做一个datagrid,但因为引用的Jquery,加上初学者,所以难免费尽周折.现在将完整版贴出来,跟大家分享,一起切磋,也方便自己回顾学习. ps:第一次发帖,不知排版效果如何,瑕疵勿怪. 首 ...
- 纯CSS实现JS效果研究
利用CSS3:checked选择器和~配合实现tab切换 效果: 代码: <style> body,div,input,label{ margin:0; padding:0; } #tab ...
- Git使用命令
git init 初始化仓库 git init --bare 初始化一个裸仓库 git branch 查看本地分支 git branch -a 查看全部分支 git remote 远程仓库管理 add ...
- C# yeild使用
C# yeild的两种形式的yield语句: yield return <expression>; yield break; 使用 yield return 语句每一次返回每个元素. 将使 ...
- java简单词法分析器(源码下载)
java简单词法分析器 : http://files.cnblogs.com/files/hujunzheng/%E7%AE%80%E5%8D%95%E8%AF%8D%E6%B3%95%E5%88%8 ...