Windows下Eclipse提交MR程序到HadoopCluster
作者:Syn良子 出处:http://www.cnblogs.com/cssdongl 欢迎转载,转载请注明出处.
以前Eclipse上写好的MapReduce项目经常是打好包上传到Hadoop测试集群来直接运行,运行遇到问题的话查看日志和修改相关代码来解决。找时间配置了Windows上Eclispe远程提交MR程序到集群方便调试.记录一些遇到的问题和解决方法.
系统环境:Windows7 64,Eclipse Mars,Maven3.3.9,Hadoop2.6.0-CDH5.4.0.
一.配置MapReduce Maven工程
新建一个Maven工程,将CDH集群的相关xml配置文件(主要是core-site.xml,hdfs-site.xml,mapred-site.xml和yarn-site.xml)拷贝到src/main/java下,因为需要连接的是CDH集群,所以配置pom.xml文件主要内容如下
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<repositories>
<repository>
<id>cloudera</id>
<url>https://repository.cloudera.com/artifactory/cloudera-repos/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>3.8.1</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.6.0-cdh5.4.0</version>
<type>jar</type>
<exclusions>
<exclusion>
<artifactId>kfs</artifactId>
<groupId>net.sf.kosmosfs</groupId>
</exclusion>
</exclusions>
<scope>provided</scope>
</dependency> <dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.6.0-cdh5.4.0</version>
<type>jar</type>
<scope>provided</scope>
</dependency> <dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs-nfs</artifactId>
<version>2.6.0-cdh5.4.0</version>
<type>jar</type>
<scope>provided</scope>
</dependency> <dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-yarn-api</artifactId>
<version>2.6.0-cdh5.4.0</version>
<type>jar</type>
<scope>provided</scope>
</dependency> <dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-yarn-applications-distributedshell</artifactId>
<version>2.6.0-cdh5.4.0</version>
<type>jar</type>
<scope>provided</scope>
</dependency> <dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-yarn-server-resourcemanager</artifactId>
<version>2.6.0-cdh5.4.0</version>
<type>jar</type>
<scope>provided</scope>
</dependency> <dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-yarn-applications-unmanaged-am-launcher</artifactId>
<version>2.6.0-cdh5.4.0</version>
<type>jar</type>
<scope>provided</scope>
</dependency> <dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hbase-hadoop2-compat</artifactId>
<version>1.0.0-cdh5.4.0</version>
<type>jar</type>
<scope>provided</scope>
</dependency> <dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-common</artifactId>
<version>2.6.0-cdh5.4.0</version>
<type>jar</type>
<scope>provided</scope>
</dependency> <dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-jobclient</artifactId>
<version>2.6.0-cdh5.4.0</version>
<type>jar</type>
<scope>provided</scope>
</dependency> <dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-app</artifactId>
<version>2.6.0-cdh5.4.0</version>
<type>jar</type>
<scope>provided</scope>
</dependency> <dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-hs</artifactId>
<version>2.6.0-cdh5.4.0</version>
<type>jar</type>
<scope>provided</scope>
</dependency> <dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-hs-plugins</artifactId>
<version>2.6.0-cdh5.4.0</version>
<type>jar</type>
<scope>provided</scope>
</dependency> <dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hbase-client</artifactId>
<version>1.0.0-cdh5.4.0</version>
<type>jar</type>
<scope>provided</scope>
</dependency> <dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hbase-common</artifactId>
<version>1.0.0-cdh5.4.0</version>
<type>jar</type>
<scope>provided</scope>
</dependency> <dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hbase-server</artifactId>
<version>1.0.0-cdh5.4.0</version>
<type>jar</type>
<scope>provided</scope>
</dependency> <dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hbase-protocol</artifactId>
<version>1.0.0-cdh5.4.0</version>
<type>jar</type>
<scope>provided</scope>
</dependency> <dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hbase-prefix-tree</artifactId>
<version>1.0.0-cdh5.4.0</version>
<type>jar</type>
<scope>provided</scope>
</dependency> <dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hbase-hadoop-compat</artifactId>
<version>1.0.0-cdh5.4.0</version>
<type>jar</type>
<scope>provided</scope>
</dependency> <dependency>
<groupId>jdk.tools</groupId>
<artifactId>jdk.tools</artifactId>
<version>1.7</version>
<scope>system</scope>
<systemPath>${JAVA_HOME}/lib/tools.jar</systemPath>
</dependency> <dependency>
<groupId>org.apache.maven.surefire</groupId>
<artifactId>surefire-booter</artifactId>
<version>2.12.4</version>
</dependency> </dependencies>
如果CDH是其他版本,请参考CDH官方Maven Artifacts,配置好对应的dependency(修改version之类的属性).如果是原生Hadoop,remove掉上面Cloudera的repositroy,配置好对应的dependency.
配置好以后保存pom文件,等待相关jar包下载完成.
二.配置Eclipse提交MR到集群
最简单的莫过于WordCount了,贴代码先.
package org.ldong.test; import java.io.File;
import java.io.IOException;
import java.util.StringTokenizer; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapred.JobConf;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
import org.apache.hadoop.yarn.conf.YarnConfiguration; public class WordCount1 extends Configured implements Tool { public static class TokenizerMapper extends Mapper<LongWritable, Text, Text, IntWritable> { private final static IntWritable one = new IntWritable(1);
private Text word = new Text(); public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
} public static class IntSumReducer extends Reducer<Text, IntWritable, Text, IntWritable> { public void reduce(Text key, Iterable<IntWritable> values, Context context)
throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
context.write(key, new IntWritable(sum));
}
} public static void main(String[] args) throws Exception {
System.setProperty("hadoop.home.dir", "C:\\hadoop-2.6.0");
ToolRunner.run(new WordCount1(), args);
} public int run(String[] args) throws Exception {
String input = "hdfs://littleNameservice/test/input";
String output = "hdfs://littleNameservice/test/output"; Configuration conf = new YarnConfiguration();
conf.addResource("core-site.xml");
conf.addResource("hdfs-site.xml");
conf.addResource("mapred-site.xml");
conf.addResource("yarn-site.xml"); Job job = Job.getInstance(conf, "word count");
job.setJarByClass(WordCount1.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class); job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setNumReduceTasks(1); FileInputFormat.addInputPath(job, new Path(input));
FileSystem fs = FileSystem.get(conf);
if (fs.exists(new Path(output))) {
fs.delete(new Path(output), true);
} String classDirToPackage = "D:\\workspace\\performance-statistics-mvn\\target\\classes";
File jarFile = EJob.createTempJar(classDirToPackage);
ClassLoader classLoader = EJob.getClassLoader();
Thread.currentThread().setContextClassLoader(classLoader);
((JobConf) job.getConfiguration()).setJar(jarFile.toString()); FileOutputFormat.setOutputPath(job, new Path(output));
return job.waitForCompletion(true) ? 0 : 1;
} }
ok,这里主要配置好代码中标红部分的configuration(和自己的连接集群保持一致),开始运行该程序,直接run as java application ,不出意外的话,肯定报错如下
java.io.IOException: Could not locate executable null\bin\winutils.exe in the Hadoop binaries.
这个错误很常见,在windows下运行MR就会出现,主要是hadoop需要的一些native library在windows上找不到.作为强迫症患者肯定不能视而不见了,解决方式如下:
1.去官网下载hadoop2.6.0-.tar.gz解压到windows本地,配置环境变量,指向解压以后的hadoop根目录下bin文件夹;
2.将本文最后链接中的压缩包下载解压,将其中的文件都解压到步骤1中hadoop的bin目录下.
3.如果没有立刻生效的,加上临时代码,如上面代码中 System.setProperty("hadoop.home.dir", "C:\\hadoop-2.6.0"),下次重启生效后好可以去掉这行
重新运行,该错误消失.出现另外一个错误
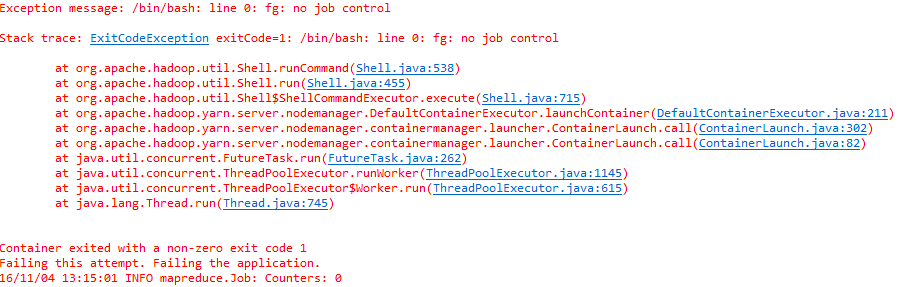
其实这个异常是Hadoop2.4之前的一个windows提交MR任务到Hadoop Cluster的严重bug,跟不同系统的classes path有关系,已经在hadoop2.4修复了,见如下链接
http://hadoop.apache.org/docs/r2.4.1/hadoop-project-dist/hadoop-common/releasenotes.html
其中 MAPREDUCE-4052 :“Windows eclipse cannot submit job from Windows client to Linux/Unix Hadoop cluster.”
如果有同学是Hadoop2.4之前版本的,解决方式参考下面几个链接(其实4052和5655是duplicate的):
https://issues.apache.org/jira/browse/MAPREDUCE-4052
https://issues.apache.org/jira/browse/MAPREDUCE-5655
https://issues.apache.org/jira/browse/YARN-1298
http://www.aboutyun.com/thread-8498-1-1.html
http://blog.csdn.net/fansy1990/article/details/22896249
而我的环境是Hadoop2.6.0-CDH5.4.0的,解决方式没有上面这么麻烦,直接修改工程下mapred-site.xml文件,修改属性如下(如没有则添加)
<property>
<name>mapreduce.app-submission.cross-platform</name>
<value>true</value>
</property>
继续运行,上面那个”no job control”错误消失,出现如下错误
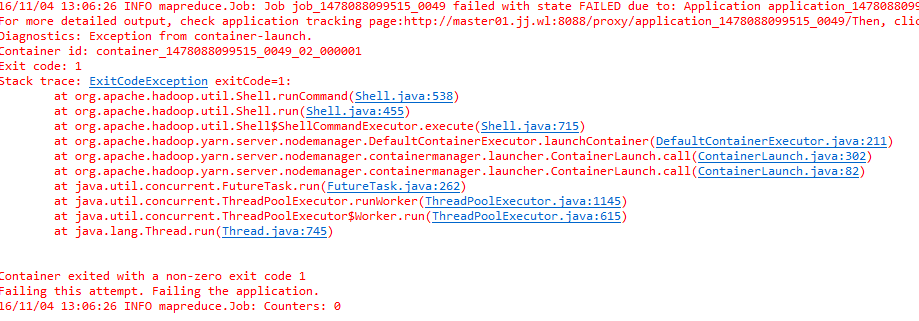
没完没了了,肯定还是配置的问题,最后查阅资料发现还是直接修改工程的配置文件
对于mapred-site.xml,添加或者修改属性如下,注意自己的集群保持一一致,如下
<property>
<name>mapreduce.application.classpath</name>
<value>$HADOOP_MAPRED_HOME/*,$HADOOP_MAPRED_HOME/lib/*,$MR2_CLASSPATH</value>
</property>
对于yarn-site.xml,添加或者修改属性如下,注意自己的集群保持一一致,如下
<property>
<name>yarn.application.classpath</name>
<value>$HADOOP_CLIENT_CONF_DIR,$HADOOP_CONF_DIR,$HADOOP_COMMON_HOME/*,$HADOOP_COMMON_HOME/lib/*,$HADOOP_HDFS_HOME/*,$HADOOP_HDFS_HOME/lib/*,$HADOOP_YARN_HOME/*,$HADOOP_YARN_HOME/lib/*</value>
</property>
重新运行MR,上面错误消失,出现新的错误找不到MR的class.汗了一地,好吧,2种方式,一种就是我代码中标黄的部分自动把MR打成jar包上传到集群分布式运行
String classDirToPackage = "D:\\workspace\\performance-statistics-mvn\\target\\classes";
这个地方请改成自己工程下的classes文件夹(如果是maven工程,请暂时删除classes下META-INF文件夹,否则后续无法打包),随后的代码用EJob类来打成Jar包,最终提交给集群来运行.EJob类如下
package org.ldong.test; import java.io.File;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
import java.net.URL;
import java.net.URLClassLoader;
import java.util.ArrayList;
import java.util.List;
import java.util.jar.JarEntry;
import java.util.jar.JarOutputStream;
import java.util.jar.Manifest; public class EJob { private static List<URL> classPath = new ArrayList<URL>(); public static File createTempJar(String root) throws IOException {
if (!new File(root).exists()) {
return null;
}
Manifest manifest = new Manifest();
manifest.getMainAttributes().putValue("Manifest-Version", "1.0");
final File jarFile = File.createTempFile("EJob-", ".jar", new File(
System.getProperty("java.io.tmpdir"))); Runtime.getRuntime().addShutdownHook(new Thread() {
public void run() {
jarFile.delete();
}
}); JarOutputStream out = new JarOutputStream(
new FileOutputStream(jarFile), manifest);
createTempJarInner(out, new File(root), "");
out.flush();
out.close();
return jarFile;
} private static void createTempJarInner(JarOutputStream out, File f,
String base) throws IOException {
if (f.isDirectory()) {
File[] fl = f.listFiles();
if (base.length() > 0) {
base = base + "/";
}
for (int i = 0; i < fl.length; i++) {
createTempJarInner(out, fl[i], base + fl[i].getName());
}
} else {
out.putNextEntry(new JarEntry(base));
FileInputStream in = new FileInputStream(f);
byte[] buffer = new byte[1024];
int n = in.read(buffer);
while (n != -1) {
out.write(buffer, 0, n);
n = in.read(buffer);
}
in.close();
}
} public static ClassLoader getClassLoader() {
ClassLoader parent = Thread.currentThread().getContextClassLoader();
System.out .println(parent);
URL[] urls = classPath.toArray(new URL[0]);
for( URL url : urls)
{
System.out .println(url);
}
System.out.println(classPath.toArray(new URL[0]));
if (parent == null) {
parent = EJob.class.getClassLoader();
}
if (parent == null) {
parent = ClassLoader.getSystemClassLoader();
}
return new URLClassLoader(classPath.toArray(new URL[0]), parent);
} public static void addClasspath(String component) { if ((component != null) && (component.length() > 0)) {
try {
File f = new File(component); if (f.exists()) {
URL key = f.getCanonicalFile().toURL();
if (!classPath.contains(key)) {
classPath.add(key);
}
}
} catch (IOException e) {
}
}
} }
另外一种方式就是直接手动将MR工程打包,放到集群每个节点上可以加载到的class path下,执行eclipse中程序触发MR分布式运行,也可以实现.
好吧,接着运行,这次没什么问题成功了,如下图
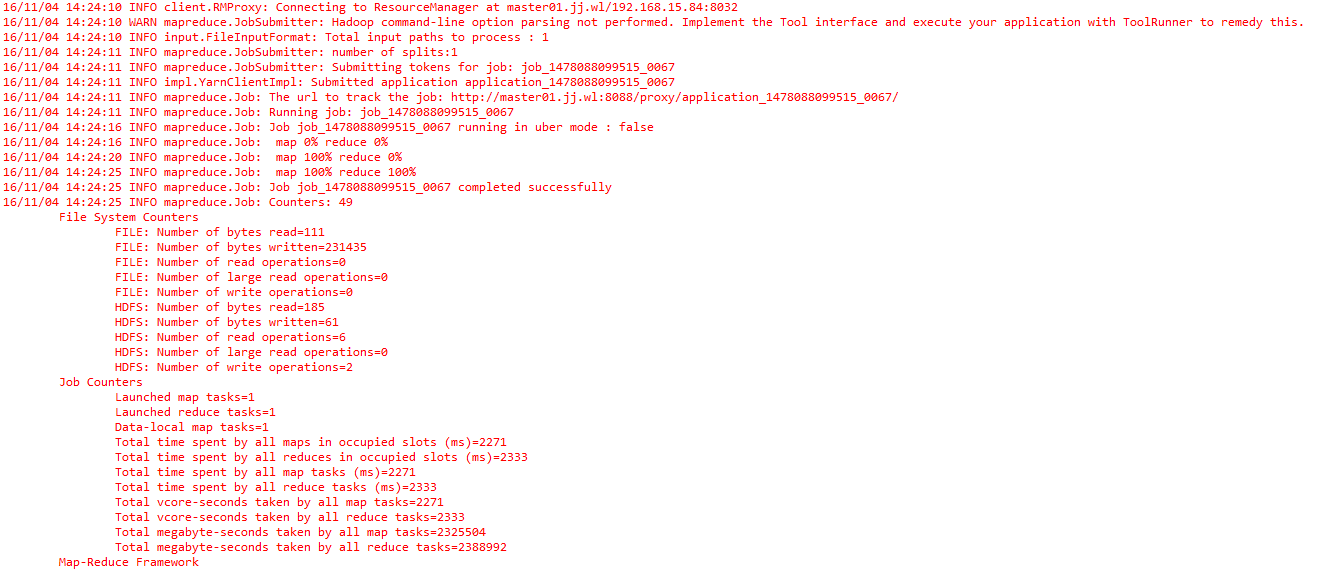
去集群上验证jobhistory和hdfs输出目录,结果正确.
其他可能会遇到的错误如
org.apache.hadoop.security.AccessControlException: Permission denied….
其实就是没有hdfs权限,解决方法有以下几种
1.在系统环境变量中增加HADOOP_USER_NAME,其值为hadoop;或者通过java程序动态添加,如下:System.setProperty("HADOOP_USER_NAME", "hadoop"),这里hadoop为对hdfs具有读写权限的hadoop用户.
2.或者对需要操作的目录开放权限,例如 hadoop fs -chmod 777 /test.
3.或者修改hadoop的配置文件:hdfs-site.xml,添加或者修改 dfs.permissions 的值为 false.
4.或者将Eclipse所在机器的用户的名称修改为hadoop,即与服务器上运行hadoop的用户一致,这里hadoop为对hdfs具有读写权限的hadoop用户.
三.配置MR程序本地运行
如果仅仅是需要本地调试测试MR逻辑来读写HDFS,不提交MR到集群运行,那配置比上面简单很多
同样新建一个Maven工程,这次不需要拷贝那些*-site.xml,直接简单配置pom文件主要内容如下
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<repositories>
<repository>
<id>cloudera</id>
<url>https://repository.cloudera.com/artifactory/cloudera-repos/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>3.8.1</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.6.0-cdh5.4.0</version>
<type>jar</type>
<exclusions>
<exclusion>
<artifactId>kfs</artifactId>
<groupId>net.sf.kosmosfs</groupId>
</exclusion>
</exclusions>
<scope>provided</scope>
</dependency> <dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.6.0-cdh5.4.0</version>
<type>jar</type>
<scope>provided</scope>
</dependency> <dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-core</artifactId>
<version>2.6.0-mr1-cdh5.4.0</version>
<type>jar</type>
<scope>provided</scope>
</dependency> <dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-yarn-api</artifactId>
<version>2.6.0-cdh5.4.0</version>
<type>jar</type>
<scope>provided</scope>
</dependency> <dependency>
<groupId>jdk.tools</groupId>
<artifactId>jdk.tools</artifactId>
<version>1.7</version>
<scope>system</scope>
<systemPath>${JAVA_HOME}/lib/tools.jar</systemPath>
</dependency> <dependency>
<groupId>org.apache.maven.surefire</groupId>
<artifactId>surefire-booter</artifactId>
<version>2.12.4</version>
</dependency> </dependencies>
编写WordCount如下
import java.io.IOException;
import java.util.StringTokenizer; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
import org.apache.hadoop.yarn.conf.YarnConfiguration; public class WordCount extends Configured implements Tool { public static class TokenizerMapper extends Mapper<LongWritable, Text, Text, IntWritable> { private final static IntWritable one = new IntWritable(1);
private Text word = new Text(); public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
} public static class IntSumReducer extends Reducer<Text, IntWritable, Text, IntWritable> { public void reduce(Text key, Iterable<IntWritable> values, Context context)
throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
context.write(key, new IntWritable(sum));
}
} public static void main(String[] args) throws Exception {
System.setProperty("hadoop.home.dir", "C:\\hadoop-2.6.0");
ToolRunner.run(new WordCount(), args);
} public int run(String[] args) throws Exception {
String input = "hdfs://master01.jj.wl:8020/test/input";
String output = "hdfs://master01.jj.wl:8020/test/output"; Configuration conf = new YarnConfiguration();
conf.set("fs.defaultFS", "hdfs://master01.jj.wl:8020");
conf.set("mapreduce.framework.name", "yarn");
conf.set("yarn.resourcemanager.address", "master01.jj.wl:8032");
Job job = new Job(conf, "word count");
job.setJarByClass(WordCount.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class); job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class); FileInputFormat.addInputPath(job, new Path(input));
FileSystem fs = FileSystem.get(conf);
if (fs.exists(new Path(output))) {
fs.delete(new Path(output), true);
}
FileOutputFormat.setOutputPath(job, new Path(output));
return job.waitForCompletion(true) ? 0 : 1;
} }
配置好集群的连接,如标红部分,然后运行,报错如下
Could not locate executable null\bin\winutils.exe in the Hadoop binaries
和上面的解决方式一样,不废话,解决掉,接着运行,成功
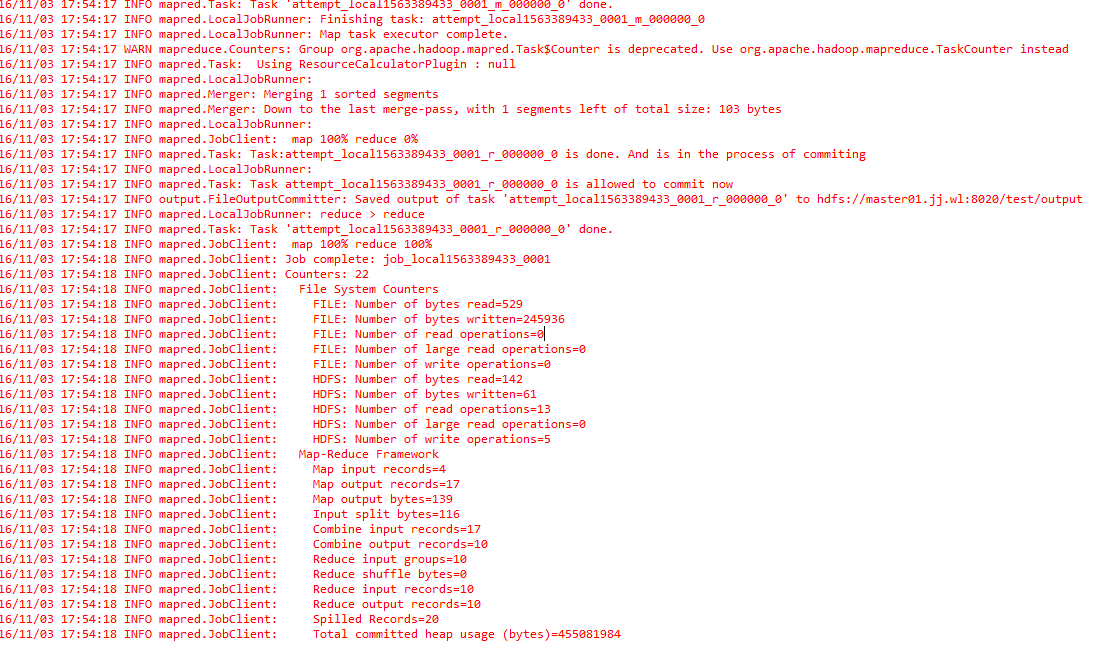
眼尖的同学应该会发现这次MR调用了LocalJobRunner来运行,阅读源码会发现其实就是一个本地的JVM在运行MR程序,根本没有提交到集群,但是读写的是集群的HDFS,所以去集群上检查依然能看到output的输出结果,但是去Web UI上查看集群的任务列表会发现根本找不到刚才运行成功的任务.
winutils相关文件下载链接:http://files.cnblogs.com/files/cssdongl/hadoop2.6%28x64%29.zip
Windows下Eclipse提交MR程序到HadoopCluster的更多相关文章
- [b0007] windows 下 eclipse 开发 hdfs程序样例
目的: 学习使用hdfs 的java命令操作 相关: 进化: [b0010] windows 下 eclipse 开发 hdfs程序样例 (二) [b0011] windows 下 eclipse 开 ...
- [b0011] windows 下 eclipse 开发 hdfs程序样例 (三)
目的: 学习windows 开发hadoop程序的配置. [b0007] windows 下 eclipse 开发 hdfs程序样例 太麻烦 [b0010] windows 下 eclipse 开发 ...
- [b0010] windows 下 eclipse 开发 hdfs程序样例 (二)
目的: 学习windows 开发hadoop程序的配置 相关: [b0007] windows 下 eclipse 开发 hdfs程序样例 环境: 基于以下环境配置好后. [b0008] Window ...
- Win下Eclipse提交Hadoop程序出错:org.apache.hadoop.security.AccessControlException: Permission denied: user=D
描述:在Windows下使用Eclipse进行Hadoop的程序编写,然后Run on hadoop 后,出现如下错误: 11/10/28 16:05:53 INFO mapred.JobClient ...
- windows下eclipse远程连接hadoop集群开发mapreduce
转载请注明出处,谢谢 2017-10-22 17:14:09 之前都是用python开发maprduce程序的,今天试了在windows下通过eclipse java开发,在开发前先搭建开发环境.在 ...
- windows环境下Eclipse开发MapReduce程序遇到的四个问题及解决办法
按此文章<Hadoop集群(第7期)_Eclipse开发环境设置>进行MapReduce开发环境搭建的过程中遇到一些问题,饶了一些弯路,解决办法记录在此: 文档目的: 记录windows环 ...
- windows下调用外部exe程序 SHELLEXECUTEINFO
本文主要介绍两种在windows下调用外部exe程序的方法: 1.使用SHELLEXECUTEINFO 和 ShellExecuteEx SHELLEXECUTEINFO 结构体的定义如下: type ...
- windows下eclipse+hadoop2
windows下eclipse+hadoop2.4开发手册 1.解压下载的hadoop2.4,到任意盘符,例如D:\hadoop-2.4.0. 2.设置环境变量 ①新建系统变量,如下所示. ②将新建的 ...
- windows下Eclipse安装Perl插件教程
windows下Eclipse安装Perl插件教程 想用eclipse编写perl.网上看了很多资料.但EPIC插件的下载连接都失效了.无奈,只好自己动手写个教程记录一下. 准备工作: 安装好Ecli ...
随机推荐
- [ASE]项目介绍及项目跟进——TANK BATTLE·INFINITE
童年的记忆,大概是每周末和小伙伴们围坐在电视机前,在20来寸的电视机屏幕里守卫着这个至今都不知道是什么的白色大鸟. 当年被打爆的坦克数量估计也能绕地球个三两圈了吧. 十几年过去了,游戏从2D-3D,画 ...
- CSS 禁止浏览器滚动条的方法(转)
1.完全隐藏 在<boby>里加入scroll="no",可隐藏滚动条: <boby scroll="no"> 这个我用的时候完全没效果 ...
- asp.net WebApi and protobuff
protobuff 是谷歌开发的,在性能上要比Json xml好很多,对性能要求比较高的时候这个是一个不错的选择,但是这个目前只是一个序列化反序列化的东西,以前原生的只有几种语言的现在在github ...
- 从分布式一致性谈到CAP理论、BASE理论
问题的提出 在计算机科学领域,分布式一致性是一个相当重要且被广泛探索与论证问题,首先来看三种业务场景. 1.火车站售票 假如说我们的终端用户是一位经常坐火车的旅行家,通常他是去车站的售票处购买车票,然 ...
- 【T-SQL基础】02.联接查询
概述: 本系列[T-SQL基础]主要是针对T-SQL基础的总结. [T-SQL基础]01.单表查询-几道sql查询题 [T-SQL基础]02.联接查询 [T-SQL基础]03.子查询 [T-SQL基础 ...
- Wix 安装部署教程(十五) --CustomAction的七种用法
在WIX中,CustomAction用来在安装过程中执行自定义行为.比如注册.修改文件.触发其他可执行文件等.这一节主要是介绍一下CustomAction的7种用法. 在此之前要了解InstallEx ...
- [nRF51822] 4、 图解nRF51 SDK中的Schedule handling library 和Timer library
:nRF51822虽然是一个小型的单片机,但是能真正达到任意调用其官方驱动以及BLE协议栈的人还是奇缺的.据我所见,大都拿官方给的一个冗长的蓝牙低功耗心率计工程改的.之前我对于这个工程进行log跟踪, ...
- android:onClick vs setOnClickListener
为Android Widgets添加点击事件处理函数又两种方法,一个是在Xml文件中添加onClick属性,然后在代码中添加对应的函数.另一个是直接在代码中添加setOnClickListener函数 ...
- 自制Unity小游戏TankHero-2D(5)声音+爆炸+场景切换+武器弹药
自制Unity小游戏TankHero-2D(5)声音+爆炸+场景切换+武器弹药 我在做这样一个坦克游戏,是仿照(http://game.kid.qq.com/a/20140221/028931.htm ...
- cmd 下通过NTML代理访问Maven 库
公司用web代理,NTLM验证的,这样在普通CMD下无法使用mvn命令访问网上的maven库,使用CNTLM工具解决. 下载CNTLM工具,安装,修改安装路径下的cntlm.ini,改成实际的ntlm ...