Scrapy-Splash的介绍、安装以及实例
scrapy-splash的介绍
在前面的博客中,我们已经见识到了Scrapy的强大之处。但是,Scrapy也有其不足之处,即Scrapy没有JS engine, 因此它无法爬取JavaScript生成的动态网页,只能爬取静态网页,而在现代的网络世界中,大部分网页都会采用JavaScript来丰富网页的功能。所以,这无疑Scrapy的遗憾之处。
那么,我们还能愉快地使用Scrapy来爬取动态网页吗?有没有什么补充的办法呢?答案依然是yes!答案就是,使用scrapy-splash模块!
scrapy-splash模块主要使用了Splash. 所谓的Splash, 就是一个Javascript渲染服务。它是一个实现了HTTP API的轻量级浏览器,Splash是用Python实现的,同时使用Twisted和QT。Twisted(QT)用来让服务具有异步处理能力,以发挥webkit的并发能力。Splash的特点如下:
- 并行处理多个网页
- 得到HTML结果以及(或者)渲染成图片
- 关掉加载图片或使用 Adblock Plus规则使得渲染速度更快
- 使用JavaScript处理网页内容
- 使用Lua脚本
- 能在Splash-Jupyter Notebooks中开发Splash Lua scripts
- 能够获得具体的HAR格式的渲染信息
scrapy-splash的安装
由于Splash的上述特点,使得Splash和Scrapy两者的兼容性较好,抓取效率较高。
听了上面的介绍,有没有对scrapy-splash很心动呢?下面就介绍如何安装scrapy-splash,步骤如下:
1. 安装scrapy-splash模块
pip3 install scrapy-splash
2. scrapy-splash使用的是Splash HTTP API, 所以需要一个splash instance,一般采用docker运行splash,所以需要安装docker。不同系统的安装命令会不同,如笔者的CentOS7系统的安装方式为:
sudo yum install docker
安装完docker后,可以输入命令‘docker -v’来验证docker是否安装成功。
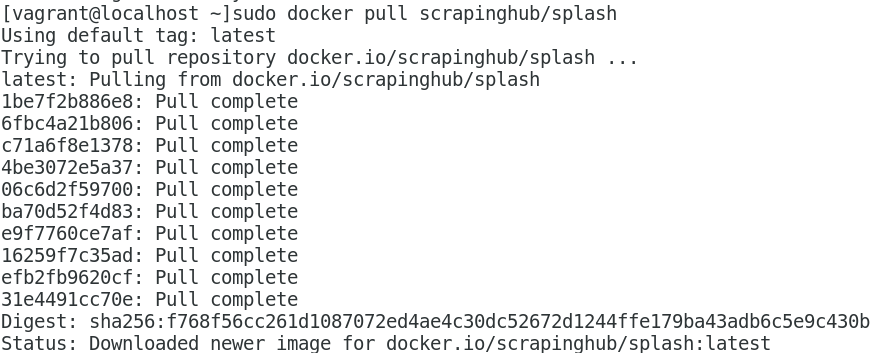
3. 开启docker服务,拉取splash镜像(pull the image):
sudo service docker start
sudo dock pull scrapinghub/splash
运行结果如下:
4. 开启容器(start the container):
sudo docker run -p 8050:8050 scrapinghub/splash
此时Splash以运行在本地服务器的端口8050(http).在浏览器中输入'localhost:8050', 页面如下:

在这个网页中我们能够运行Lua scripts,这对我们在scrapy-splash中使用Lua scripts是非常有帮助的。以上就是我们安装scrapy-splash的全部。
scrapy-splash的实例
在安装完scrapy-splash之后,不趁机介绍一个实例,实在是说不过去的,我们将在此介绍一个简单的实例,那就是利用百度查询手机号码信息。比如,我们在百度输入框中输入手机号码‘159********’,然后查询,得到如下信息:
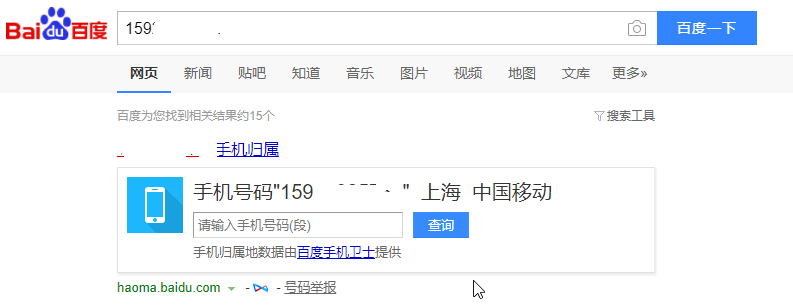
我们将利用scrapy-splash模拟以上操作并获取手机号码信息。
1. 创建scrapy项目phone
2. 配置settings.py文件,配置的内容如下:
ROBOTSTXT_OBEY = False
SPIDER_MIDDLEWARES = {
'scrapy_splash.SplashDeduplicateArgsMiddleware': 100,
}
DOWNLOADER_MIDDLEWARES = {
'scrapy_splash.SplashCookiesMiddleware': 723,
'scrapy_splash.SplashMiddleware': 725,
'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware': 810
}
SPLASH_URL = 'http://localhost:8050'
DUPEFILTER_CLASS = 'scrapy_splash.SplashAwareDupeFilter'
HTTPCACHE_STORAGE = 'scrapy_splash.SplashAwareFSCacheStorage'
具体的配置说明可以参考: https://pypi.python.org/pypi/scrapy-splash .
3. 创建爬虫文件phoneSpider.py, 代码如下:
# -*- coding: utf-8 -*-
from scrapy import Spider, Request
from scrapy_splash import SplashRequest
# splash lua script
script = """
function main(splash, args)
assert(splash:go(args.url))
assert(splash:wait(args.wait))
js = string.format("document.querySelector('#kw').value=%s;document.querySelector('#su').click()", args.phone)
splash:evaljs(js)
assert(splash:wait(args.wait))
return splash:html()
end
"""
class phoneSpider(Spider):
name = 'phone'
allowed_domains = ['www.baidu.com']
url = 'https://www.baidu.com'
# start request
def start_requests(self):
yield SplashRequest(self.url, callback=self.parse, endpoint='execute', args={'lua_source': script, 'phone':'159*******', 'wait': 5})
# parse the html content
def parse(self, response):
info = response.css('div.op_mobilephone_r.c-gap-bottom-small').xpath('span/text()').extract()
print('='*40)
print(''.join(info))
print('='*40)
4. 运行爬虫,scrapy crawl phone, 结果如下:

实例展示到此结束,欢迎大家访问这个项目的Github地址: https://github.com/percent4/phoneSpider .当然,有什么问题,也可以载下面留言评论哦~~
Scrapy-Splash的介绍、安装以及实例的更多相关文章
- Python -- Scrapy 框架简单介绍(Scrapy 安装及项目创建)
Python -- Scrapy 框架简单介绍 最近在学习python 爬虫,先后了解学习urllib.urllib2.requests等,后来发现爬虫也有很多框架,而推荐学习最多就是Scrapy框架 ...
- [Python爬虫] scrapy爬虫系列 <一>.安装及入门介绍
前面介绍了很多Selenium基于自动测试的Python爬虫程序,主要利用它的xpath语句,通过分析网页DOM树结构进行爬取内容,同时可以结合Phantomjs模拟浏览器进行鼠标或键盘操作.但是,更 ...
- scrapy splash 之一二
scrapy splash 用来爬取动态网页,其效果和scrapy selenium phantomjs一样,都是通过渲染js得到动态网页然后实现网页解析, selenium + phantomjs ...
- 一个完整的Installshield安装程序实例—艾泽拉斯之海洋女神出品(四) --高级设置二
原文:一个完整的Installshield安装程序实例-艾泽拉斯之海洋女神出品(四) --高级设置二 上一篇:一个完整的安装程序实例—艾泽拉斯之海洋女神出品(三) --高级设置一4. 根据用户选择的组 ...
- 爬虫--Scrapy框架课程介绍
Scrapy框架课程介绍: 框架的简介和基础使用 持久化存储 代理和cookie 日志等级和请求传参 CrawlSpider 基于redis的分布式爬虫 一scrapy框架的简介和基础使用 a) ...
- 一个完整的Installshield安装程序实例-转
一个完整的Installshield安装程序实例—艾泽拉斯之海洋女神出品(一)---基本设置一 前言 Installshield可以说是最好的做安装程序的商业软件之一,不过因为功能的太过于强大,以至于 ...
- [转]一个完整的Installshield安装程序实例
@import url("http://files.cnblogs.com/files/go-jzg/vs.css"); --> Installshield安装程序实例—基本 ...
- scrapy+splash 爬取京东动态商品
作业来源:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE1/homework/3159 splash是容器安装的,从docker官网上下载windows下的 ...
- Scrapy学习1:安装
Install Scrapy 熟悉PyPI的话,直接一句 pip install Scrapy 但是有时候需要处理安装依赖,不能直接一句命令就安装结束,这个和系统有关. 我用的Ubuntu,这里仅介绍 ...
随机推荐
- Collision (hdu-5114
题意:你有一个以(0, 0), (x, 0), (0, y), (x, y)为边界点的四边形,给你两个点从(x1, y1), (x2, y2)的点发射,以(1, 1)的速度走,碰到边界会反射,问你最终 ...
- 序列化与Json
序列化: 将数据结构或对象转换成二进制串的过程. 反序列化:将在序列化过程中所生成的二进制串转换成数据结构或者对象的过程. 首先我们通过复制文件举例,这里面就包含序列化与反序列化的过程: public ...
- Note | LaTeX
目录 一.TeX家族 1. TeX - LaTeX 2. pdfTeX - pdfLaTeX 3. XeTeX - XeLaTeX 4. CTeX - MiKTeX - TeX Live 二.入门 1 ...
- ScriptOJ-safeGet#99
const safeGet = (data, path) => { if(!path) return undefined; const pathArr = path.split('.'); le ...
- array_flip()函数
array_flip() 函数用于反转/交换数组中所有的键名以及它们关联的键值. array_flip() 函数返回一个反转后的数组,如果同一值出现了多次,则最后一个键名将作为它的值,所有其他的键名都 ...
- MySQL与SQL语句的操作
MySQL与SQL语句的操作 Mysql比较轻量化,企业用的是Oracle,基本的是熟悉对数据库,数据表,字段,记录的更新与修改 1. mysql基本信息 特殊数据库:information_sche ...
- 2-postman批量执行接口
1.postman环境设置与使用 1)点击设置,添加按钮 2)填写环境名称,参数 3)切换环境 4)使用环境变量,使用格式为:{{变量名}} 2.postman批量执行接口 1)选择要执行的文件夹,点 ...
- 参数签名ascii码排序的坑
参数签名中通常是按键值对中键名称的ASCII按从小到大的顺序排序后进行hash为签名字符串.不要直接使用 SortedDictionary<string, string> 有坑的,他是按数 ...
- kaldi实例脚本运行
Getting started, and prerequisites. rm/s5/run.sh Data preparation 如果有GridEngine, train_cmd="que ...
- Javascript高级编程学习笔记(12)—— 引用类型(1)Object类型
前面的文章中我们知道JS中的值分为两种类型 基础类型的值和引用类型的值 基础类型的值我已经大概介绍了一下,今天开始后面几天我会为大家介绍一下引用类型的值 Object类型 对象是引用类型的值的实例,在 ...