目标检测(三)Fast R-CNN
该论文提出的目标检测算法Fast Region-based Convolutional Network(Fast R-CNN)能够single-stage训练,并且可以同时学习对object proposals的分类与目标空间位置的确定,与以往的算法相比该方法在训练和测试速度、检测精度上均有较大提升。
目标检测算法比较复杂主要是因为检测需要确定目标的准确位置,这样的话就面临着两个主要的问题:首先,大量的candidate object locations(proposals)必须被处理;其次,candidate widows仅仅提供了目标的大概位置,必须重新确定以获得准确位置。虽然R-CNN和SPPnet在目标检测方面效果显著,但是仍有诸多缺陷。下面将要介绍的Fast R-CNN则可以在一定程度上弥补二者的缺点,并且带来更快的速度和更高的精度。
1.2 contributions
Fast R-CNN有如下优点:
- Higher detection quality (mAP) than R-CNN, SPPnet
- Training is single-stage, using a multi-task loss
- Training can update all network layers
- No disk storage is required for feature caching
2. Fast R-CNN architecture and training
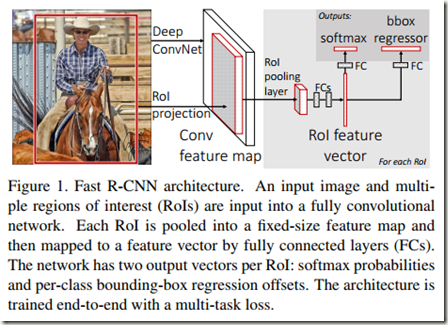
Fig.1 展示了Fast R-CNN的结构。Fast R-CNN的输入是一幅entire image和一系列object proposals。先是整个image通过该网络的卷积和池化层得到一个feature map,然后一个region of interest(RoI)池化层从feature map中为每个Object proposal提取对应的固定长度特征向量,最后将所有proposals的特征向量输入若干层全连接层。全连接层后面有两路并行输出:其中一路产生softmax
probability 用来估计K+1类;另一路为K个object classes中的每一类输出4个实值数字,用来为所在类重新确定bounding-box positions
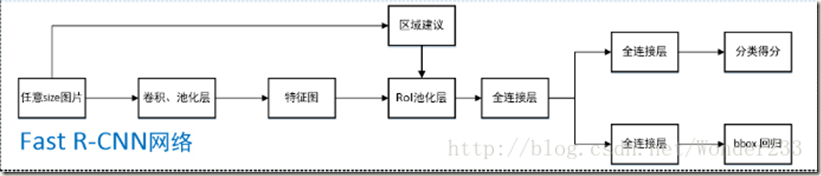

2.1 The RoI pooling layer
Regions of interest(RoI) 是feature map中的一个矩形窗口,每个RoI的位置由一个元组确定(r,c,h,w),其中(r,c)指定了窗口左上角的坐标,(h,w)表示窗口的高和宽。RoI pooling layer的作用是对feature map中的RoIs进行max pooling操作,生成固定空间尺寸的small feature maps(e.g. HxW),其中的H,W是超参数。、
RoI max pooling layer将尺寸为h*w的RoI windows 划分成尺寸为H*W的网格,然后在网格内进行max pooling。这里的池化指的是标准的池化。另外,这里的RoI layer是SPPnet中spatial pyramid pooling layer的特例,相当于只有一级的spatial pyramid pooling layer,即只对RoI windows 划分一次。
2.2 Initializing from pre-trained networks
将预训练好的深度卷积神经网络初始化成一个Fast R-CNN网络需要三步:
- The last max pooling layer is replaced by a RoI pooling layer that is configured by setting H and W to be compatible with the net’s first fully connected layer (e.g.H=W = 7 for VGG16)
- The network’s last fully connected layer and softmax(which were trained for 1000-way ImageNet classification) are replaced with the two sibling layers described earlier(a fully connected layer and softmax over K+1 categories and category-specific bounding-box regressors)
- The network is modified to take two data inputs: a list of images and a list of RoIs in those images
2.3 Fine-tuning for detection 即Fast R-CNN的训练
Fast R-CNN网络中的所有权重都可以使用反向传播算法进行训练,这项能力使得Fast R-CNN的测量精度更高,因为在微调时可以更新卷积层的参数。
SPPnet也使用了spatial pyramid pooling layer,但是微调时并没有对卷积层的参数进行训练,这是因为作者(Kaiming He等)认为卷积层在预训练时已经训练过,微调时无需再训练,只需训练全连接层。而该论文的作者认为如果按照SPPnet论文中选择的batch(batch中RoIs来自于不同images,R-CNN和SPPnet均是如此)进行训练的话,对空间池化层及之前的网络进行参数更新的效率会非常低,就认为SPPnet中不能更新卷积层参数。我认为这是因为在前向过程中需要计算多个Images的feature maps,使得计算耗时严重(如果SPPnet使用multi-scale feature extraction的话这种计算代价会更加高昂);另外,在反向传播过程中空间金字塔池化层会导致参数更新比较复杂。为此,提出了一种更加有效的训练方法,能够在训练时利用特征共享,那就是分层采样得到batches。具体做法是先采N幅images,然后从N幅images中的每幅图像中采R/N个RoIs(单尺度训练和测试)。很明显,来自同一个Image的RoIs在前向和反向传播过程中共享计算和内存。同时减小N会降低一个batch内的计算。比如当使用N=2和R=128时,训练速度是从128个不同images中采样RoI计算的64倍快。
至于是否会因为来自于同一个image的RoIs之间的关联性较高而导致训练收敛缓慢,作者通过实验证明该问题并不存在,相反,使用作者提出的batch训练时所需的迭代次数比R-CNN更少。
除了分层采样,Fast R-CNN还使用streamlined training process,只有优化softmax classifier和bounding-box regressors这一步,而不是像R-CNN和SPPnet那样将训练分为训练softmax classifier、SVMs和regressors三个独立的步骤。下面将介绍Fast训练过程中的几个问题:
- Multi-task loss 多任务损失
顾名思义,多任务损失即多个任务的损失之和。多任务指的是分类和bounding-box regression两个tasks,在网络上对应两路输出。一路输出每个RoI的概率p=(p0,…..pk),另一路为K个object classes中的每一类输出bounding-box regression偏移量tk=(tkx,tky,tkw,tkh)。
每个RoI根据一个ground-truth的类别u标记,并且一个ground-truth bounding-box regression target是v,那么每个带标签RoI的多任务损失可定义如下:
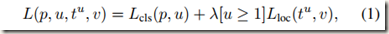
式中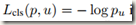 是真实类别u的log loss。第二个任务损失定义了bounding-bx regression target v=(vx,vy,vw,vh)与预测的元组tk=(tkx,tky,tkw,tkh)之间的误差。另外,u>=1表明当类别不为0时才计算Lloc,这是因为一般将背景类标记为第0类。关于Lloc(tu,v)的定义如下:
是真实类别u的log loss。第二个任务损失定义了bounding-bx regression target v=(vx,vy,vw,vh)与预测的元组tk=(tkx,tky,tkw,tkh)之间的误差。另外,u>=1表明当类别不为0时才计算Lloc,这是因为一般将背景类标记为第0类。关于Lloc(tu,v)的定义如下:

smoothL1(x)是一个robust L1 loss,它没有R-CNN和SPPnet中使用的L2损失对离群点敏感。如果regression target v很大,那么使用L2训练时需要仔细调整学习速率以防止梯度爆炸。smoothL1(x)可以消除这种敏感性。
超参数λ控制两个任务损失之间的平衡,论文中全部取λ=1。计算时也会将ground-truth regression target vi 进行归一化处理(0均值,单位方差)。
- Mini-batch sampling
作者在微调时的每个mini-batch由2幅images和从每幅image中采得的64个ROIs构成。而且,在训练时,每个Image会以0.5的概率被水平翻转以增强数据。除此之外再也没有使用数据增强。
- Back-propagation through RoI pooling layers 参见论文
- SGD hyper-parameters
使用softmax classifier和bounding-box regression的全连接层分别使用均值为0标准差为0.01和0.001的高斯分布初始化;偏置都会初始化为0;针对PASCAL VOC 2007和2012训练集,前30k次迭代全局学习率为0.001,每层权重学习率为1倍,偏置学习率为2倍,后10k次迭代全局学习率更新为0.0001;动量设置为0.9,权重衰减设置为0.0005。
2.4 Scale invariance
作者论文中提到了两种实现尺度不变检测的方法:
- brute force learning
在训练和测试时每幅图像被预先处理成事先确定的尺寸
- image pyramid
多尺度方法,通过图像金字塔实现近似的尺度不变。类似于SPPne中的multi-scale,可以参考
3. Fast R-CNN detection
训练好的网络会输入一个Image(或者使用image pyramid时产生的 list of images)和 a list of R object proposals 然后打分。在test-time,R一般是2000左右。当使用image pyramid时,每一个RoI会从缩放后尺寸最接近224*224的RoI所在的尺度中选取(同SPPnet)。
对于每一个RoI r,前向传播输出一个类别概率p和一些列预测到的边界框offsets,然后对每个类独立使用和R-CNN中一样的非极大值抑制。
3.1 Truncated SVD for faster detection
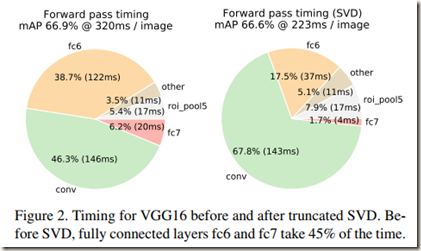
在整幅图片的分类过程中,全连接层的时间消耗与卷积层相比是非常小的。但是在Fast R-CNN中因为卷积计算共享,使得卷积计算耗时很短,而全连接层的计算耗时几乎占到前向传播用时的一半。为了缩短全连接层的计算用时,作者使用了截断SVD来压缩全连接层以加速计算。
首先,一层全连接层的权重矩阵W(尺寸为u x v)可以SVD分解为:

在该分解中,U=u x t,其中t是W的左奇异向量;Σt(t x t)是W最大的t个奇异值构成的对角阵;V=v x t,其中t是W的右奇异向量。Truncated SVD将参数的数量从uv减少到了(u+v),当t比min(u,v)小得多时,参数个数减少能降低很大的计算量。
为了压缩网络,可以将W对应的单层全连接层替换为两个全连接层,且二者之间没有non-linearity。第一层“全连接层”使用权重矩阵ΣtVT(并且没有biases);第二层“全连接层”使用权重矩阵U(使用原先的biases,即W对应的偏置)。作者说当RoIs的数量很大时,这种简单的压缩方法能够带来较好的加速效果。
实验中作者发现使用truncated SVD虽然mAP会稍微降低(0.3%),但是检测时间缩短了30%。可见,可以以小幅降低mAP为代价换取速度的大幅提升。另外,使用SVD后可能还能再加速,只需要在压缩后再微调一次,不过mAP会再稍微降低一些。
4.1 Experimental setup
论文中的所有实验均使用single-scale训练和测试(s=600),即网络的输入只有一个固定尺度s。虽然Fast R-CNN使用单尺度训练和测试,但是依靠微调卷积层参数仍然对mAP带来了很大的提升(63.1% – 66.9%)。
4.5 Which layers to fine-tune?
为了验证微调卷积层对网络的影响,作者将卷积层参数固定,只训练全连接层。结果发现在单尺度训练下,此时mAp从66.9%降低到61.4%。这证明,微调时对卷积层参数进行训练对深度网络来说是非常有意义的。
但是这并不意味着所有conv layers都应该进行微调。在比Fast R-CNN小一点的网络中,我们发现conv1(第一个卷积层)是generic and independent(a well-known fact)。因此是否对conv1进行微调没有太大意义。比如对于VGG16,我们发现只需要更新conv3_1及以上的layers。部分结果如Table 5.

论文中所有关于Fast R-CNN(使用VGG16)的实验都是微调conv3_1及以上层;所有使用model S and M的实验均微调conv2及以上层
5.1 Does multi-task training help?
作者经过三个网络的实验发现,多任务训练相比纯粹的分类训练提高了分类精度
5.2 Scale invariance: to brute force or finesse?
作者比较了两种实现尺度不变目标检测的方法:brute-force learning(single scale) 和 image pyramid(multi-scale)。在每一种方法中作者都定义了每幅图像最短边应该达到的scales的集合s
经过实验得到下表:
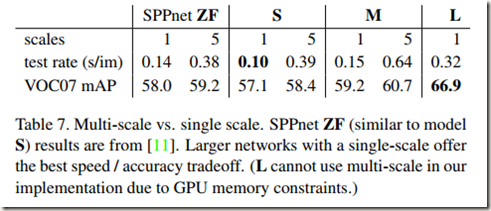
可见,multi-scale方法对mAP的提高作用很有限,相反,使用多尺度方法的话计算会消耗大量时间,有点得不偿失。而single-scale能够在速度和精度之间取得很好的平衡,尤其对非常深的模型而言。这是显而易见的,因为使用single-scale时计算耗时较短。
5.4 Do SVMs outperform softmax?
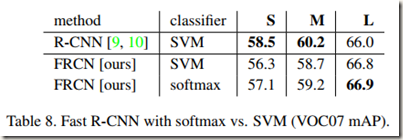
从表中可见,在所有的网络中softmax都稍微优于SVM。虽然softmax相对SVM而言效果提升有限,但是证明了single stage fine-tuning与以前的multi-stage fine-tunig相比是有效的。而且,与one-vs-rest SVMs不同的是,在给RoI打分时softmax会在classes之间引入竞争。
Fast R-CNN 与 SPPNet 区别就在于: Fast R-CNN 不再使用 SVM进行分类,而是使用一个网络同时完成了提取特征、判断类别 、 框回归三项工作;Fast R-CNN微调时会更新深度卷积网络的参数,使得精度进一步提高,而SPPnet仅训练空间金字塔池化层后面的部分。
参考文章:
目标检测(三)Fast R-CNN的更多相关文章
- 目标检测(三) Fast R-CNN
引言 之前学习了 R-CNN 和 SPPNet,这里做一下回顾和补充. 问题 R-CNN 需要对输入进行resize变换,在对大量 ROI 进行特征提取时,需要进行卷积计算,而且由于 ROI 存在重复 ...
- 第三十节,目标检测算法之Fast R-CNN算法详解
Girshick, Ross. “Fast r-cnn.” Proceedings of the IEEE International Conference on Computer Vision. 2 ...
- Faster-rcnn实现目标检测
Faster-rcnn实现目标检测 前言:本文浅谈目标检测的概念,发展过程以及RCNN系列的发展.为了实现基于Faster-RCNN算法的目标检测,初步了解了RCNN和Fast-RCNN实现目标检 ...
- 论文笔记:目标检测算法(R-CNN,Fast R-CNN,Faster R-CNN,FPN,YOLOv1-v3)
R-CNN(Region-based CNN) motivation:之前的视觉任务大多数考虑使用SIFT和HOG特征,而近年来CNN和ImageNet的出现使得图像分类问题取得重大突破,那么这方面的 ...
- 深度学习笔记之目标检测算法系列(包括RCNN、Fast RCNN、Faster RCNN和SSD)
不多说,直接上干货! 本文一系列目标检测算法:RCNN, Fast RCNN, Faster RCNN代表当下目标检测的前沿水平,在github都给出了基于Caffe的源码. • RCNN RCN ...
- 基于深度学习的目标检测技术演进:R-CNN、Fast R-CNN、Faster R-CNN
object detection我的理解,就是在给定的图片中精确找到物体所在位置,并标注出物体的类别.object detection要解决的问题就是物体在哪里,是什么这整个流程的问题.然而,这个问题 ...
- 第三十五节,目标检测之YOLO算法详解
Redmon, J., Divvala, S., Girshick, R., Farhadi, A.: You only look once: Unified, real-time object de ...
- 第三十四节,目标检测之谷歌Object Detection API源码解析
我们在第三十二节,使用谷歌Object Detection API进行目标检测.训练新的模型(使用VOC 2012数据集)那一节我们介绍了如何使用谷歌Object Detection API进行目标检 ...
- 第三十三节,目标检测之选择性搜索-Selective Search
在基于深度学习的目标检测算法的综述 那一节中我们提到基于区域提名的目标检测中广泛使用的选择性搜索算法.并且该算法后来被应用到了R-CNN,SPP-Net,Fast R-CNN中.因此我认为还是有研究的 ...
随机推荐
- Nginx的location匹配规则
一 Nginx的location语法 location [=|~|~*|^~] /uri/ { … } = 严格匹配.如果请求匹配这个location,那么将停止搜索并立即处理此请求 ...
- AWS免费套餐服务器部署NETCORE网站
之前的linode充了5美元,一个月就用完了,还是创建的最便宜的服务器的!!! 以前一直想用用aws的所谓的免费套餐服务器的,现在linode过期了,可以试着用用了 下面是我的操作流程,包含错误及解决 ...
- 每天进步一点点——mysql——mysqlbinlog
一. 简单介绍 mysqlbinlog:用于查看server生成的二进制日志的工具. 二. 命令格式 mysqlbinlog 选项日志文件1 三. 经常使用參数 ...
- 【iCore4 双核心板_ARM】例程二十九:SD_IAP_FPGA实验——更新升级FPGA
实验现象及操作说明: 1.烧写程序成功,绿色ARM·LED灯点亮,三色FPGA·LED灯循环点亮,烧写失败,如果挂载SD卡失败,红灯快闪,如果打开文件失败,蓝灯快闪,读取文件指针移动失败,白灯点亮,升 ...
- spring boot+mybatis+mysql
spring boot整合mybatis,曾经的几个小困惑和踩的坑. 一.mybatis的结构 mybatis和spring boot的整合,网上无数的教程,都是教你一步步集成,照着做没问题,但做下来 ...
- GraphX学习笔记——可视化
首先自己造了一份简单的社交关系的图 第一份是人物数据,id和姓名,person.txt 1 孙俪 2 邓超 3 佟大为 4 冯绍峰 5 黄晓明 6 angelababy 7 李冰冰 8 范冰冰 第二份 ...
- tensorflow中一种融合多个模型的方法
1.使用场景 假设我们有训练好的模型A,B,C,我们希望使用A,B,C中的部分或者全部变量,合成为一个模型D,用于初始化或其他目的,就需要融合多个模型的方法 2.如何实现 我们可以先声明模型D,再创建 ...
- GoLang之反射
反射 反射(reflect) 所谓反射(reflect)就是能检查程序在运行时的状态. 使用反射的三条定律: 反射可以将“接口类型变量”转换为“反射类型对象”: 反射可以将“反射类型对象”转换为“接口 ...
- 【ORACLE】解锁scott帐号
sqlplus / as sysdba;SQL> alter user scott account unlock;SQL> conn scott/grace
- php处理数据分组问题
很简单的一个需求,将数据库取出的二维数组进行按照id分组,同组的数据用逗号连接,例如: 处理为 就是按照id分组,name进行逗号拼接. 那么按照数据库的思路来说,采用group_concat即可,如 ...