java后端面试
背景:最近在找工作,但是发现每次找的时候都需要整理一些基础知识,这些点又是面试过程中经常被问到的,每次都进行整理很麻烦,所以有打算好好总结下。
转载自:https://www.cnblogs.com/think90/p/8146312.html
Nginx负载均衡
轮询、轮询是默认的,每一个请求按顺序逐一分配到不同的后端服务器,如果后端服务器down掉了,则能自动剔除
ip_hash、个请求按访问IP的hash结果分配,这样来自同一个IP的访客固定访问一个后端服务器,有效解决了动态网页存在的session共享问题。
weight、weight是设置权重,用于后端服务器性能不均的情况,访问比率约等于权重之比
fair(第三方)、这是比上面两个更加智能的负载均衡算法。此种算法可以依据页面大小和加载时间长短智能地进行负载均衡,也就是根据后端服务器的响应时间来分配请求,响应时间短的优先分配。Nginx本身是不支持fair的,如果需要使用这种调度算法,必须下载Nginx的upstream_fair模块。
url_hash(第三方)此方法按访问url的hash结果来分配请求,使每个url定向到同一个后端服务器,可以进一步提高后端缓存服务器的效率。Nginx本身是不支持url_hash的,如果需要使用这种调度算法,必须安装Nginx 的hash软件包。
Nginx采用反向代理实现
代理的概念
正向代理,也就是传说中的代理, 简单的说,我是一个用户,我访问不了某网站,但是我能访问一个代理服务器,这个代理服务器呢,他能访问那个我不能访问的网站,于是我先连上代理服务器,告诉他我需要那个无法访问网站的内容,代理服务器去取回来,然后返回给我。从网站的角度,只在代理服务器来取内容的时候有一次记录,有时候并不知道是用户的请求,也隐藏了用户的资料,这取决于代理告不告诉网站。
反向代理: 结论就是,反向代理正好相反,对于客户端而言它就像是原始服务器,并且客户端不需要进行任何特别的设置。客户端向反向代理的命名空间(name-space)中的内容发送普通请求,接着反向代理将判断向何处(原始服务器)转交请求,并将获得的内容返回给客户端,就像这些内容原本就是它自己的一样。
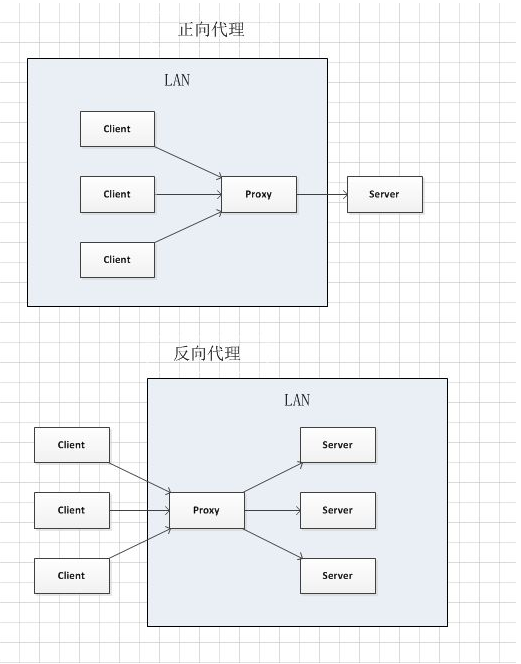
反向代理中,proxy和server同属一个LAN,对client透明。
实际上proxy在两种代理中做的事都是代为收发请求和响应,不过从结构上来看正好左右互换了下,所以把后出现的那种代理方式叫成了反向代理。
Volatile
Volatile的特征:
A、原子性 :对任意单个volatile变量的读/写具有原子性,但类似于volatile++这种复合操作不具有原子性。
B、可见性:对一个volatile变量的读,总是能看到(任意线程)对这个volatile变量最后的写入。
volatile变量是一种比sychronized关键字更轻量级的同步机制。
synchronized和volatile比较
简单的说就是synchronized的代码块是确保可见性和原子性的, volatile只能确保可见性 当且仅当下面条件全部满足时, 才能使用volatile
- 对变量的写入操作不依赖于变量的当前值, (++i/i++这种肯定不行), 或者能确保只有单个线程在更新
- 该变量不会与其他状态变量一起纳入不变性条件中
- 访问变量时不需要加锁
Volatile的内存语义:
当写一个volatile变量时,JMM会把线程对应的本地内存中的共享变量值刷新到主内存。
当读一个volatile变量时,JMM会把线程对应的本地内存置为无效,线程接下来将从主内存中读取共享变量。
Volatile的重排序
重排序是指编译器和处理器为了优化程序性能而对指令序列进行排序的一种手段。
1、当第二个操作为volatile写操做时,不管第一个操作是什么(普通读写或者volatile读写),都不能进行重排序。这个规则确保volatile写之前的所有操作都不会被重排序到volatile之后;
2、当第一个操作为volatile读操作时,不管第二个操作是什么,都不能进行重排序。这个规则确保volatile读之后的所有操作都不会被重排序到volatile之前;
3、当第一个操作是volatile写操作时,第二个操作是volatile读操作,不能进行重排序。
这个规则和前面两个规则一起构成了:两个volatile变量操作不能够进行重排序;
除以上三种情况以外可以进行重排序。
比如:
1、第一个操作是普通变量读/写,第二个是volatile变量的读;
2、第一个操作是volatile变量的写,第二个是普通变量的读/写;
内存屏障/内存栅栏
内存屏障(Memory Barrier,或有时叫做内存栅栏,Memory Fence)是一种CPU指令,用于控制特定条件下的重排序和内存可见性问题。Java编译器也会根据内存屏障的规则禁止重排序。(也就是让一个CPU处理单元中的内存状态对其它处理单元可见的一项技术。)
内存屏障可以被分为以下几种类型:
LoadLoad屏障:对于这样的语句Load1; LoadLoad; Load2,在Load2及后续读取操作要读取的数据被访问前,保证Load1要读取的数据被读取完毕。
StoreStore屏障:对于这样的语句Store1; StoreStore; Store2,在Store2及后续写入操作执行前,保证Store1的写入操作对其它处理器可见。
LoadStore屏障:对于这样的语句Load1; LoadStore; Store2,在Store2及后续写入操作被刷出前,保证Load1要读取的数据被读取完毕。
StoreLoad屏障:对于这样的语句Store1; StoreLoad; Load2,在Load2及后续所有读取操作执行前,保证Store1的写入对所有处理器可见。它的开销是四种屏障中最大的。
在大多数处理器的实现中,这个屏障是个万能屏障,兼具其它三种内存屏障的功能。
内存屏障阻碍了CPU采用优化技术来降低内存操作延迟,必须考虑因此带来的性能损失。为了达到最佳性能,最好是把要解决的问题模块化,这样处理器可以按单元执行任务,然后在任务单元的边界放上所有需要的内存屏障。采用这个方法可以让处理器不受限的执行一个任务单元。合理的内存屏障组合还有一个好处是:缓冲区在第一次被刷后开销会减少,因为再填充改缓冲区不需要额外工作了。
happens-before原则
如果一个操作执行的结果需要对另一个操作可见,那么这两个操作之间必须要存在happens-before关系。
Java是如何实现跨平台的?
跨平台是怎样实现的呢?这就要谈及Java虚拟机(JavaVirtual Machine,简称 JVM)。
JVM也是一个软件,不同的平台有不同的版本。我们编写的Java源码,编译后会生成一种 .class 文件,称为字节码文件。Java虚拟机就是负责将字节码文件翻译成特定平台下的机器码然后运行。也就是说,只要在不同平台上安装对应的JVM,就可以运行字节码文件,运行我们编写的Java程序。
而这个过程中,我们编写的Java程序没有做任何改变,仅仅是通过JVM这一”中间层“,就能在不同平台上运行,真正实现了”一次编译,到处运行“的目的。(同样的字节码,不同的jvm,不同的机器码)
JVM是一个”桥梁“,是一个”中间件“,是实现跨平台的关键,Java代码首先被编译成字节码文件,再由JVM将字节码文件翻译成机器语言,从而达到运行Java程序的目的。
注意:编译的结果不是生成机器码,而是生成字节码,字节码不能直接运行,必须通过JVM翻译成机器码才能运行。不同平台下编译生成的字节码是一样的,但是由JVM翻译成的机器码却不一样。
所以,运行Java程序必须有JVM的支持,因为编译的结果不是机器码,必须要经过JVM的再次翻译才能执行。即使你将Java程序打包成可执行文件(例如 .exe),仍然需要JVM的支持。
注意:跨平台的是Java程序,不是JVM。JVM是用C/C++开发的,是编译后的机器码,不能跨平台,不同平台下需要安装不同版本的JVM。
ps:编译后生成字节码文件,jvm翻译字节码成机器码
垃圾搜集器
- 按照线程数量来分:
- 串行 串行垃圾回收器一次只使用一个线程进行垃圾回收
- 并行 并行垃圾回收器一次将开启多个线程同时进行垃圾回收。
- 按照工作模式来分:
- 并发 并发式垃圾回收器与应用程序线程交替工作,以尽可能减少应用程序的停顿时间
- 独占 一旦运行,就停止应用程序中的其他所有线程,直到垃圾回收过程完全结束
- 按照碎片处理方式:
- 压缩式 压缩式垃圾回收器会在回收完成后,对存活对象进行压缩整消除回收后的碎片;
- 非压缩式 非压缩式的垃圾回收器不进行这步操作。
- 按工作的内存区间 可分为新生代垃圾回收器和老年代垃圾回收器
新生代串行收集器 serial 它仅仅使用单线程进行垃圾回收;第二,它独占式的垃圾回收。使用复制算法。
老年代串行收集器 serial old 年代串行收集器使用的是标记-压缩算法。和新生代串行收集器一样,它也是一个串行的、独占式的垃圾回收器
并行收集器 parnew 并行收集器是工作在新生代的垃圾收集器,它只简单地将串行回收器多线程化。它的回收策略、算法以及参数和串行回收器一样 并行回收器也是独占式的回收器,在收集过程中,应用程序会全部暂停。但由于并行回收器使用多线程进行垃圾回收,因此,在并发能力比较强的 CPU 上,它产生的停顿时间要短于串行回收器,而在单 CPU 或者并发能力较弱的系统中,并行回收器的效果不会比串行回收器好,由于多线程的压力,它的实际表现很可能比串行回收器差。
新生代并行回收 (Parallel Scavenge) 收集器 新生代并行回收收集器也是使用复制算法的收集器。从表面上看,它和并行收集器一样都是多线程、独占式的收集器。但是,并行回收收集器有一个重要的特点:它非常关注系统的吞吐量。
老年代并行回收收集器 parallel old 老年代的并行回收收集器也是一种多线程并发的收集器。和新生代并行回收收集器一样,它也是一种关注吞吐量的收集器。老年代并行回收收集器使用标记-压缩算法,JDK1.6 之后开始启用。
CMS 收集器 CMS 收集器主要关注于系统停顿时间。CMS 是 Concurrent Mark Sweep 的缩写,意为并发标记清除,从名称上可以得知,它使用的是标记-清除算法,同时它又是一个使用多线程并发回收的垃圾收集器。
CMS 工作时,主要步骤有:初始标记、并发标记、重新标记、并发清除和并发重置。其中初始标记和重新标记是独占系统资源的,而并发标记、并发清除和并发重置是可以和用户线程一起执行的。因此,从整体上来说,CMS 收集不是独占式的,它可以在应用程序运行过程中进行垃圾回收。
根据标记-清除算法,初始标记、并发标记和重新标记都是为了标记出需要回收的对象。并发清理则是在标记完成后,正式回收垃圾对象;并发重置是指在垃圾回收完成后,重新初始化 CMS 数据结构和数据,为下一次垃圾回收做好准备。并发标记、并发清理和并发重置都是可以和应用程序线程一起执行的。
G1 收集器 G1 收集器是基于标记-压缩算法的。因此,它不会产生空间碎片,也没有必要在收集完成后,进行一次独占式的碎片整理工作。G1 收集器还可以进行非常精确的停顿控制。
并发与并行
你吃饭吃到一半,电话来了,你一直到吃完了以后才去接,这就说明你不支持并发也不支持并行。
你吃饭吃到一半,电话来了,你停了下来接了电话,接完后继续吃饭,这说明你支持并发。
你吃饭吃到一半,电话来了,你一边打电话一边吃饭,这说明你支持并行。
并发的关键是你有处理多个任务的能力,不一定要同时。
并行的关键是你有同时处理多个任务的能力。
网络基本概念
OSI模型
OSI 模型(Open System Interconnection model)是一个由国际标准化组织
java后端面试的更多相关文章
- Java后端面试的一切技巧和常见的问题经验总结
原文地址:cnblogs.com/JavaArchitect/p/10011253.html 上周,密集面试了若干位Java后端候选人,工作经验在3到5年间.我的标准其实不复杂(适用90%小小小公司, ...
- 转:Java后端面试自我学习
引自:https://www.cnblogs.com/JavaArchitect/p/10011253.html 最近面试java后端开发的感受:如果就以平时项目经验来面试,通过估计很难——再论面试前 ...
- 三年半Java后端面试经历
经过半年的沉淀,加上对MySQL,redis和分布式这块的补齐,终于开始重拾面试信心,再次出征. 鹅厂 面试职位:go后端开发工程师,接受从Java转语言 都知道鹅厂是cpp的主战场,而以cpp为背景 ...
- 三年半Java后端面试鹅厂,三面竟被虐的体无完肤
经过半年的沉淀,加上对MySQL,redis和分布式这块的补齐,终于开始重拾面试信心,再次出征. 鹅厂 面试职位: go后端开发工程师,接受从Java转语言 都知道鹅厂是cpp的主战场,而以cpp为背 ...
- java 面试,java 后端面试,数据库方面对初级和高级程序员的要求
本内容摘自 java web轻量级开发面试教程 对于合格的程序员,需要有基本的数据库操作技能,具体体现在以下三个方面. l 第一,针对一类数据库(比如MySQL.Oracle.SQL Server等 ...
- 2018年Java后端面试经历
楼主16年毕业,16年三月份进入上一家公司到今年3月底,所以这是一份两年工作经验面经分享. 都说金三银四,往些年都是听着过没啥特别的感觉.今年自己倒是确确实实体验了一把银四,从3月26裸辞到4月17号 ...
- 腾讯,华为,阿里…7家Java后端面试经验大公开!
感觉面试还是主要围绕简历来问的,所以不熟悉的东西最好不要随便写上去.项目和基础都很重要,整体的基础知识的框架可以参考GitHub 上 CYC2018的博客,分类很全,但是深入的学习还是要自己去看书,写 ...
- 逻辑思维面试题-java后端面试-遁地龙卷风
(-1)写在前面 最近参加了一次面试,对笔试题很感兴趣,就回来百度一下.通过对这些题目的思考让我想起了建模中的关联,感觉这些题如果没接触就是从0到1,考验逻辑思维的话从1到100会更好,并且编程简易模 ...
- Java后端面试经验总结分享(一)
今天下午两点的时候,我去面了一家招Java开发的公司,本人工作经验2年多一丢丢. 跟大部分公司类似,先做一份笔试题,题目都比较简单,基本都写完了.我把题目以及答案列在下面一下,给自己做一下总结的,也分 ...
随机推荐
- C#_委托与事件
委托: 把方法当作参数进行传递 public delegate void AddDelegate(string name); public class Ad{ //addDelegate就是委托的一个 ...
- Java Mongo 自定义序列化笔记
从insert方法入手 1. org.springframework.data.mongodb.repository.support.SimpleMongoRepository.java inse ...
- 置换群 Burnside引理 Pólya定理(Polya)
置换群 设\(N\)表示组合方案集合.如用两种颜色染四个格子,则\(N=\{\{0,0,0,0\},\{0,0,0,1\},\{0,0,1,0\},...,\{1,1,1,1\}\}\),\(|N|= ...
- 个人博客作业Week2(代码规范,代码复审)
Q:是否需要有代码规范 首先我们来搞清楚什么是“代码规范”,它和“代码风格”又有什么关系.依据个人的审美角度,我可能更喜欢在函数与函数之间空出一行,可能在命名习惯和代码注释上更加的internatio ...
- 【个人博客作业Week7】软件工程团队项目一轮迭代感想与反思
(发布晚原因:发到团队博客了 一.关于银弹 在佛瑞德·布鲁克斯于1986年发布的<没有银弹:软件工程的本质性与附属性工作>这篇软件工程的经典论文中,作者向我们讲述了软件工程没有银弹这样的理 ...
- #科委外文文献发现系统——导出word模板1.0
ps:该篇文档由实验室ljg提供. Crowdsourcing 一. 技术简介 Crowdsourcing, a modern business term coined in ...
- 个人git链接和git学习心得总结
个人git链接和git学习心得总结 个人git链接: https://github.com/hanzhaoyan Git 是 Linux 的创始人 Linus Torvalds 开发的开源和免费的版本 ...
- 第三个Sprint冲刺总结
第三个Sprint冲刺总结 1.燃尽图 2.本阶段总结: 本阶段主要是对产品进行完善和美化,所以工作量不是很多.但要做精,做好并非是一件简单的事情.我们各组员都安排了各自的任务,如参考各行业的优秀ap ...
- Cron Expression的用途
对于一些MIS系统,DeadLine,需要用户自己制定事件规则,Cron Expression应该可以派上用场. Cron Maker: http://www.cronmaker.com/
- Golang的位运算操作符的使用
& 位运算 AND | 位运算 OR ^ 位运算 XOR &^ 位清空 (AND NOT) << 左移 >> 右移 感觉位运算操作符虽然在平时用得并不多,但是在 ...