词向量可视化--[tensorflow , python]
#!/usr/bin/env python
# -*- coding: utf-8 -*-
"""
----------------------------------
Version : ??
File Name : visual_vec.py
Description :
Author : xijun1
Email :
Date : 2018/12/25
-----------------------------------
Change Activiy : 2018/12/25
-----------------------------------
"""
__author__ = 'xijun1'
from tqdm import tqdm
import numpy as np
import tensorflow as tf
from tensorflow.contrib.tensorboard.plugins import projector
import os
import codecs
words, embeddings = [], []
log_path = 'model'
with codecs.open('/Users/xxx/github/python_demo/vec.txt', 'r') as f:
header = f.readline()
vocab_size, vector_size = map(int, header.split())
for line in tqdm(range(vocab_size)):
word_list = f.readline().split(' ')
word = word_list[0]
vector = word_list[1:-1]
if word == "":
continue
words.append(word)
embeddings.append(np.array(vector))
assert len(words) == len(embeddings)
print(len(words))
with tf.Session() as sess:
X = tf.Variable([0.0], name='embedding')
place = tf.placeholder(tf.float32, shape=[len(words), vector_size])
set_x = tf.assign(X, place, validate_shape=False)
sess.run(tf.global_variables_initializer())
sess.run(set_x, feed_dict={place: embeddings})
with codecs.open(log_path + '/metadata.tsv', 'w') as f:
for word in tqdm(words):
f.write(word + '\n')
# with summary
summary_writer = tf.summary.FileWriter(log_path, sess.graph)
config = projector.ProjectorConfig()
embedding_conf = config.embeddings.add()
embedding_conf.tensor_name = 'embedding:0'
embedding_conf.metadata_path = os.path.join('metadata.tsv')
projector.visualize_embeddings(summary_writer, config)
# save
saver = tf.train.Saver()
saver.save(sess, os.path.join(log_path, "model.ckpt"))
结果:
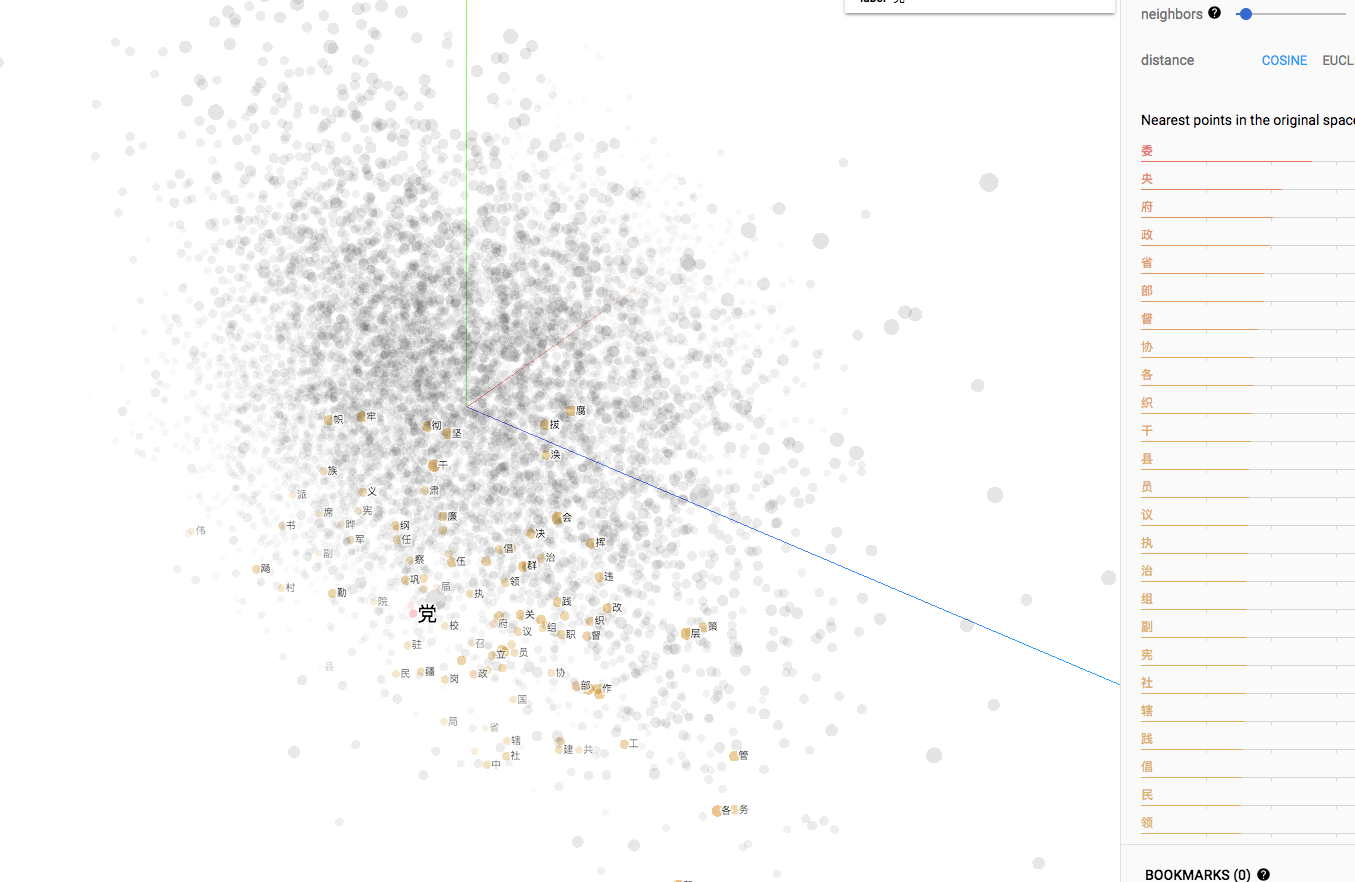
词向量可视化--[tensorflow , python]的更多相关文章
- 文本分布式表示(二):用tensorflow和word2vec训练词向量
看了几天word2vec的理论,终于是懂了一些.理论部分我推荐以下几篇教程,有博客也有视频: 1.<word2vec中的数学原理>:http://www.cnblogs.com/pegho ...
- 斯坦福NLP课程 | 第2讲 - 词向量进阶
作者:韩信子@ShowMeAI,路遥@ShowMeAI,奇异果@ShowMeAI 教程地址:http://www.showmeai.tech/tutorials/36 本文地址:http://www. ...
- 词向量模型word2vector详解
目录 前言 1.背景知识 1.1.词向量 1.2.one-hot模型 1.3.word2vec模型 1.3.1.单个单词到单个单词的例子 1.3.2.单个单词到单个单词的推导 2.CBOW模型 3.s ...
- NLP︱词向量经验总结(功能作用、高维可视化、R语言实现、大规模语料、延伸拓展)
R语言由于效率问题,实现自然语言处理的分析会受到一定的影响,如何提高效率以及提升词向量的精度是在当前软件环境下,比较需要解决的问题. 笔者认为还存在的问题有: 1.如何在R语言环境下,大规模语料提高运 ...
- NLP︱高级词向量表达(一)——GloVe(理论、相关测评结果、R&python实现、相关应用)
有很多改进版的word2vec,但是目前还是word2vec最流行,但是Glove也有很多在提及,笔者在自己实验的时候,发现Glove也还是有很多优点以及可以深入研究对比的地方的,所以对其进行了一定的 ...
- tensorflow如何正确加载预训练词向量
使用预训练词向量和随机初始化词向量的差异还是挺大的,现在说一说我使用预训练词向量的流程. 一.构建本语料的词汇表,作为我的基础词汇 二.遍历该词汇表,从预训练词向量中提取出该词对应的词向量 三.初始化 ...
- gensim的word2vec如何得出词向量(python)
首先需要具备gensim包,然后需要一个语料库用来训练,这里用到的是skip-gram或CBOW方法,具体细节可以去查查相关资料,这两种方法大致上就是把意思相近的词映射到词空间中相近的位置. 语料库t ...
- 用Python做词云可视化带你分析海贼王、火影和死神三大经典动漫
对于动漫爱好者来说,海贼王.火影.死神三大动漫神作你肯定肯定不陌生了.小编身边很多的同事仍然深爱着这些经典神作,可见"中毒"至深.今天小编利用Python大法带大家分析一下这些神作 ...
- 机器学习之路: python 实践 word2vec 词向量技术
git: https://github.com/linyi0604/MachineLearning 词向量技术 Word2Vec 每个连续词汇片段都会对后面有一定制约 称为上下文context 找到句 ...
随机推荐
- Maya mayapy.exe 安装 Cython,编译 pyd
Maya mayapy.exe 安装 Cython,编译 pyd 前言 在 Python 2.7 cython cythonize py 编译成 pyd 谈谈那些坑 中最后提到,使用 VCForPy ...
- 将linux系统目录挂载到其他分区,扩大系统可用空间
刚看到有小白用户说linux系统盘分区太小,不够用,问是不是要重装系统? 其实是不需要重装系统的,可以考虑把一些系统目录挂载到单独的分区. 比如将用户目录 /home 挂载到单独的分区: 1.首先打开 ...
- Kmeans:利用Kmeans实现对多个点进行自动分类—Jason niu
import numpy as np def kmeans(X, k, maxIt): numPoints, numDim = X.shape dataSet = np.zeros((numPoint ...
- ubuntu安装虚拟环境
首先 sudo pip install virtualenv sudo pip install virtualenvwrapper 然后进行配置 sudo gedit /.bashrc export ...
- gdb windbg and od use
gdb aslr -- 显示/设置 gdb 的 ASLR asmsearch -- Search for ASM instructions in memory asmsearch "int ...
- vs2008单元测试
调试是解决错误的过程,测试是发现软件缺陷的过程.每一个软件在交付使用时前都必须经过测试.软件测试是软件开发的重要组成部分,现在已经发展成专门的技术. 在消除了程序中的语法错误和运行错误后,程序仍然不能 ...
- UVA 277 Puzzle
题意:输入5x5的字符串,输入操作,要求输出完成操作后的字符串. 注意:①输入的操作执行可能会越界,如果越界则按题目要求输出不能完成的语句. ②除了最后一次的输出外,其他输出均要在后面空一行. ③操作 ...
- 给有C或C++基础的Python入门 :Python Crash Course 1 - 3
暑假ACM集训结束,预习下个学期要学习的Python. 前几章比较基础,玩玩学学很快学完了,这里随意写点收获. 第一章 搭建编译环境 用的是最新的Python3.编译器用的是推荐的Geany..具 ...
- 洛谷.3369.[模板]普通平衡树(fhq Treap)
题目链接 第一次(2017.12.24): #include<cstdio> #include<cctype> #include<algorithm> //#def ...
- .net缓存的应用研究(读篇)
目前,缓存主要有两种技术:分布式缓存和进程级别的内容缓存.两种缓冲具体的差异就不废话了. 1.在技术上 数据库降压的最好方式就是缓存.在缓存的性能上,进程级别的内存缓存性能有明显优于分布式缓存,内存缓 ...