【Spark-core学习之一】 Spark初识
环境
虚拟机:VMware 10
Linux版本:CentOS-6.5-x86_64
客户端:Xshell4
FTP:Xftp4
jdk1.8
scala-2.10.4(依赖jdk1.8)
spark-1.6
一、什么是Spark
Apache Spark 是专为大规模数据处理而设计的快速通用的计算引擎。Spark是UC Berkeley AMP lab (加州大学伯克利分校的AMP实验室)所开源的类Hadoop MapReduce的通用并行计算框架,Spark拥有Hadoop MapReduce所具有的优点;但不同于MapReduce的是Job中间输出结果可以保存在内存中,从而不再需要读写HDFS,因此Spark能更好地适用于数据挖掘与机器学习等需要迭代的MapReduce的算法。
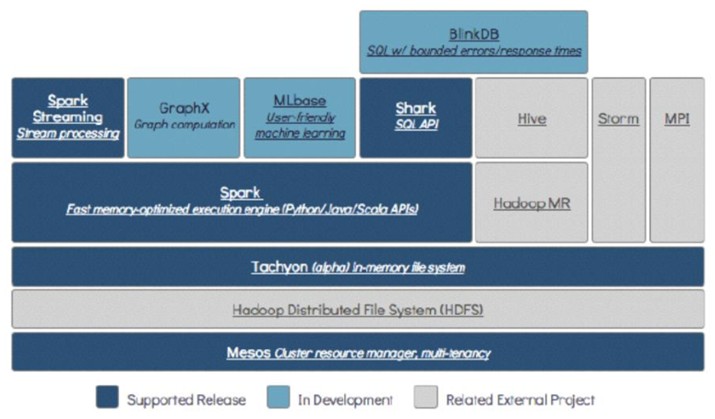
(1)Spark是Scala编写,方便快速编程。
(2)Spark与MapReduce的区别
都是分布式计算框架,Spark基于内存,MR基于HDFS;
Spark处理数据的能力一般是MR的十倍以上;
有DAG有向无环图来切分任务的执行先后顺序;
(3)Spark运行模式
Local:多用于本地测试,如在eclipse,idea中写程序测试等。
Standalone:Standalone是Spark自带的一个资源调度框架,它支持完全分布式。
Yarn:Hadoop生态圈里面的一个资源调度框架,Spark实现了AppalicationMaster接口,所以可以基于Yarn来计算的,国内用yarn的多。
Mesos:资源调度框架,国内用的少。
二、Spark-wordcount
1、java版
package com.wjy.wc;
import java.util.Arrays; import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.FlatMapFunction;
import org.apache.spark.api.java.function.Function2;
import org.apache.spark.api.java.function.PairFunction;
import org.apache.spark.api.java.function.VoidFunction; import scala.Tuple2; public class JavaSparkWordCount { public static void main(String[] args) { /**
* conf
* 1.可以设置spark的运行模式
* 2.可以设置spark在webui中显示的application的名称。
* 3.可以设置当前spark application 运行的资源(内存+core)
*
* Spark运行模式:
* 1.local --在eclipse ,IDEA中开发spark程序要用local模式,本地模式,多用于测试
* 2.stanalone -- Spark 自带的资源调度框架,支持分布式搭建,Spark任务可以依赖standalone调度资源
* 3.yarn -- hadoop 生态圈中资源调度框架。Spark 也可以基于yarn 调度资源
* 4.mesos -- 资源调度框架
*/ SparkConf conf = new SparkConf();
conf.setMaster("local");//运行模式
conf.setAppName("JavaSparkWordCount");//webui中显示的application的名称 //SparkContext 是通往集群的唯一通道
JavaSparkContext sc = new JavaSparkContext(conf);
//读取文件 返回的是一行一行的数据
JavaRDD<String> lines = sc.textFile("./data/words.txt"); /**
* FlatMap 将一条数据转换为 一组数据 (迭代器),主要用于将一条记录转换为多条记录的场景,如对 每行文章中的单词进行切分,返回每行中所有单词。
* 对lines的每一条数据应用FlatMapFunction,然后返回一个迭代,然后把这个迭代里数据转化成一堆数据
* org.apache.spark.api.java.function.FlatMapFunction<T.R>
* A function that returns zero or more output records from each input record.
* T 是入参 R是出参
* public Iterable<R> call(T)
*
*/
JavaRDD<String> words = lines.flatMap(new FlatMapFunction<String,String>(){
private static final long serialVersionUID = 1L;
@Override
public Iterable<String> call(String line) throws Exception {
return Arrays.asList(line.split(" "));
}
}); /**
* MAP操作
* 在java中 如果想让某个RDD转换成K,V格式 使用xxxToPair
* K,V格式的RDD:JavaPairRDD<String, Integer>
* 对每一个单词 返回一个计数1
* org.apache.spark.api.java.function.PairFunction<T,K,V>
* A function that returns key-value pairs (Tuple2<K, V>), and can be used to construct PairRDDs.
*
* public Tuple2<String, Integer> call(String T)
* call方法的入参就是PairFunction的T
*
*/
JavaPairRDD<String,Integer> pairwords = words.mapToPair(new PairFunction<String,String,Integer>() {
private static final long serialVersionUID = 1L;
//返回二元元组
@Override
public Tuple2<String, Integer> call(String word) throws Exception {
return new Tuple2<String,Integer>(word,1);
}
}); /**
* reduce操作
* reduceByKey处理对象是key, value 形式的RDD,对相同key的数据进行处理,最终每个key只保留一条记录
* 1.先将相同的key分组
* 2.对每一组的key对应的value去按照你的逻辑去处理
*
* org.apache.spark.api.java.function.Function2<T1,T2,R>
* A two-argument function that takes arguments of type T1 and T2 and returns an R.
* 使用两个参数的函数,T1和T2作为入参,返回R
* public Integer call(Integer T1, Integer T2)
* 上面T1 T2作为call的入参
*/
JavaPairRDD<String,Integer> reduce = pairwords.reduceByKey(new Function2<Integer,Integer,Integer>() {
private static final long serialVersionUID = 1L; @Override
public Integer call(Integer T1, Integer T2) throws Exception {
return T1+T2;
}
} ); //调个 按数量排序
JavaPairRDD<Integer, String> mapToPair = reduce.mapToPair(new PairFunction<Tuple2<String,Integer>,Integer,String>() { private static final long serialVersionUID = 1L; @Override
public Tuple2<Integer, String> call(Tuple2<String, Integer> tuple) throws Exception {
//使用构造方法
//return new Tuple2<Integer, String>(tuple._2,tuple._1);
//使用换位方法
return tuple.swap();
}
});
//排序 false降序排列
JavaPairRDD<Integer, String> sortByKey = mapToPair.sortByKey(false);
//排完序之后 再调过来
JavaPairRDD<String, Integer> result = sortByKey.mapToPair(new PairFunction<Tuple2<Integer,String>,String,Integer>() {
private static final long serialVersionUID = 1L; @Override
public Tuple2<String, Integer> call(Tuple2<Integer, String> tuple) throws Exception {
return tuple.swap();
}
}); //遍历打印输出结果
result.foreach(new VoidFunction<Tuple2<String,Integer>>(){
private static final long serialVersionUID = 1L; @Override
public void call(Tuple2<String, Integer> tuple) throws Exception {
System.out.println(tuple);
}
}); sc.stop();
sc.close();
} }
2、scala版
package com.wjy
import org.apache.spark.SparkConf;
import org.apache.spark.SparkContext
import org.apache.spark.rdd.RDD object ScalaWordCount { def main(args: Array[String]): Unit = {
//spark配置
val conf = new SparkConf();
//设置集群模式 应用名
conf.setMaster("local").setAppName("ScalaWordCount");
//获取spark上下文
val sc = new SparkContext(conf);
//使用上下文读取文件:一行一行的数据
val lines : RDD[String] = sc.textFile("./data/words.txt");
//将一行一行的数据转成一个个单词
val words :RDD[String] = lines.flatMap(line=>{
line.split(" ")
}); //Map操作
val pairwords : RDD[(String,Int)] = words.map(word=>{
new Tuple2(word,1)
});
//Reduce操作
val reduce:RDD[(String,Int)] = pairwords.reduceByKey((V1:Int,V2:Int)=>{
V1+V2
});
//排序打印出来
val rdd1:RDD[(Int,String)] = reduce.map(tuple=>{tuple.swap});
rdd1.sortByKey(false).map(tuple=>{tuple.swap}).foreach(tuple=>{
println(tuple)
}); sc.stop(); }
}
参考:
Spark:https://www.cnblogs.com/qingyunzong/category/1202252.html
Spark初识:https://www.cnblogs.com/qingyunzong/p/8886338.html
Spark2.3 HA集群的分布式安装:https://www.cnblogs.com/qingyunzong/p/8888080.html
【Spark-core学习之一】 Spark初识的更多相关文章
- spark SQL学习(spark连接 mysql)
spark连接mysql(打jar包方式) package wujiadong_sparkSQL import java.util.Properties import org.apache.spark ...
- 【spark core学习---算子总结(java版本) (第1部分)】
map算子 flatMap算子 mapParitions算子 filter算子 mapParttionsWithIndex算子 sample算子 distinct算子 groupByKey算子 red ...
- Spark Core源代码分析: Spark任务运行模型
DAGScheduler 面向stage的调度层,为job生成以stage组成的DAG,提交TaskSet给TaskScheduler运行. 每个Stage内,都是独立的tasks,他们共同运行同一个 ...
- Spark Core源代码分析: Spark任务模型
概述 一个Spark的Job分为多个stage,最后一个stage会包含一个或多个ResultTask,前面的stages会包含一个或多个ShuffleMapTasks. ResultTask运行并将 ...
- spark SQL学习(spark连接hive)
spark 读取hive中的数据 scala> import org.apache.spark.sql.hive.HiveContext import org.apache.spark.sql. ...
- 【Spark Core】任务运行机制和Task源代码浅析1
引言 上一小节<TaskScheduler源代码与任务提交原理浅析2>介绍了Driver側将Stage进行划分.依据Executor闲置情况分发任务,终于通过DriverActor向exe ...
- 大数据笔记(二十七)——Spark Core简介及安装配置
1.Spark Core: 类似MapReduce 核心:RDD 2.Spark SQL: 类似Hive,支持SQL 3.Spark Streaming:类似Storm =============== ...
- Spark 3.x Spark Core详解 & 性能优化
Spark Core 1. 概述 Spark 是一种基于内存的快速.通用.可扩展的大数据分析计算引擎 1.1 Hadoop vs Spark 上面流程对应Hadoop的处理流程,下面对应着Spark的 ...
- Spark学习(一) Spark初识
一.官网介绍 1.什么是Spark 官网地址:http://spark.apache.org/ Apache Spark™是用于大规模数据处理的统一分析引擎. 从右侧最后一条新闻看,Spark也用于A ...
- Spark Streaming揭秘 Day35 Spark core思考
Spark Streaming揭秘 Day35 Spark core思考 Spark上的子框架,都是后来加上去的.都是在Spark core上完成的,所有框架一切的实现最终还是由Spark core来 ...
随机推荐
- 一次基于Vue.Js的用户体验优化 (vue drag)
一.写在前面 半年以前,第一次在项目上实践VueJs,由于在那之前,没有Angular,avalon等框架的实践经验,所以在Vue的使用上,没有给自己总结出更多的经验和体验.随着项目进行和优化改版,无 ...
- python让实例作用于for循环并当做list来使用
python如果想让一个类被用于for....in 循环,类型list和tuple那样,可以实现__iter__方法. 这个方法返回一个迭代对象,python的for循环就会不断调用该迭代对象的ne ...
- 第一篇:你不一定了解的"推荐系统"
前言 [推荐系统 - 基础教程]可能是穆晨的所有博文里,最有趣最好玩的一个系列了^ ^. 作为该系列的[入门篇],本文将轻松愉快地向读者介绍推荐系统这项大数据领域中的热门技术. 为什么要有推荐系统? ...
- Android的TextView设置加粗对汉字无效
//not work textView.setTypeface(Typeface.defaultFromStyle(Typeface.BOLD)); //work! static public voi ...
- PHP 合并有序数组
<?php //两个有序数组合并 $arr1 = [1,5,7,44,66,89]; $arr2 = [4,5,6,88,99,105,111]; $arr3 = []; $l1 = count ...
- [Codis] Codis3部署流程
#0 前言 最近因为项目需要,研究了一下传说中的Codis.下面跟大家分享Codis3的搭建流程 https://github.com/CodisLabs/codis #1 Codis是什么 官方的介 ...
- 在VS中为C/C++源代码文件生成对应的汇编代码文件(.asm)
以VS2017为例 然后重新生成工程,在工程目录中就会有对应的汇编代码文件.
- 关于linux下ntp时间同步服务的安装与配置
1.安装ntp服务,要使用时间同步.那么服务端与客户端都需要使用如下命令安装NTP软件包 [root@ ~]# yum install ntp -y 2.如果只是作为客户端的话,配置则可以非常简单,编 ...
- java模拟http请求(代理ip)
java实现动态切换上网IP (ADSL拨号上网) java动态设置IP java模拟http的Get/Post请求 自动生成IP模拟POST访问后端程序 JAVA 动态替换代理IP并模拟POST
- layui实现左侧菜单点击右侧内容区显示
https://segmentfault.com/a/1190000014617129