day21:包和异常处理
1,复习
- # 序列化模块
- # json
- # dumps
- # loads
- # dump 和文件有关
- # load load不能load多次
- # pickle
- # 方法和json的一样
- # dump和load的时候 文件是rb或者wb打开的
- # 支持Python所有的数据类型
- # 序列化和反序列化需要相同的环境
- # shelve
- # 操作方法和字典类似
- # open方法
- # open方法获取了一个文件句柄
2,json的格式化输出,这个感兴趣的话了解一下就好,直接copy老师的博客
- Serialize obj to a JSON formatted str.(字符串表示的json对象)
- Skipkeys:默认值是False,如果dict的keys内的数据不是python的基本类型(str,unicode,int,long,float,bool,None),设置为False时,就会报TypeError的错误。此时设置成True,则会跳过这类key
- ensure_ascii:,当它为True的时候,所有非ASCII码字符显示为\uXXXX序列,只需在dump时将ensure_ascii设置为False即可,此时存入json的中文即可正常显示。)
- If check_circular is false, then the circular reference check for container types will be skipped and a circular reference will result in an OverflowError (or worse).
- If allow_nan is false, then it will be a ValueError to serialize out of range float values (nan, inf, -inf) in strict compliance of the JSON specification, instead of using the JavaScript equivalents (NaN, Infinity, -Infinity).
- indent:应该是一个非负的整型,如果是0就是顶格分行显示,如果为空就是一行最紧凑显示,否则会换行且按照indent的数值显示前面的空白分行显示,这样打印出来的json数据也叫pretty-printed json
- separators:分隔符,实际上是(item_separator, dict_separator)的一个元组,默认的就是(‘,’,’:’);这表示dictionary内keys之间用“,”隔开,而KEY和value之间用“:”隔开。
- default(obj) is a function that should return a serializable version of obj or raise TypeError. The default simply raises TypeError.
- sort_keys:将数据根据keys的值进行排序。
- To use a custom JSONEncoder subclass (e.g. one that overrides the .default() method to serialize additional types), specify it with the cls kwarg; otherwise JSONEncoder is used.
- import json
- data = {'username':['李华','二愣子'],'sex':'male','age':16}
- json_dic2 = json.dumps(data,sort_keys=True,indent=2,separators=(',',':'),ensure_ascii=False)
- print(json_dic2)
- # 平时查看可以这样看,会显得很清晰,但是写到文件里面是,最好还是紧凑着写,节省空间
- 输出结果:
- {
- "age":16,
- "sex":"male",
- "username":[
- "李华",
- "二愣子"
- ]
- }
3,包,把解决一类问题的模块放在同一个文件夹里就是包,我们之前接触的那些模块re,sys,其实都是包,只不过我们是直接import进来,没有关注过内部的结构。
4,如何创建一个包?pycharm里面project--》new--》Python package,上面还有一个是directory,创建的时候二者的图标稍有不同,两个的区别是包里面每个文件夹都有一个__init__双下init方法。
5,Python2里面只有带上__init__.py这个文件才叫做包,但是Python3里面没有也可以,
- # 代码创建包
- import os
- os.makedirs('glance/api')
- os.makedirs('glance/cmd')
- os.makedirs('glance/db')
- l = [] # 这个列表是为了后面批量关闭
- # 两个包下有同名模块也不会冲突,因为来自两个不同的命名空间
- l.append(open('glance/__init__.py','w'))
- l.append(open('glance/api/__init__.py','w'))
- l.append(open('glance/api/policy.py','w'))
- l.append(open('glance/api/versions.py','w'))
- l.append(open('glance/cmd/__init__.py','w'))
- l.append(open('glance/cmd/manage.py','w'))
- l.append(open('glance/db/__init__.py','w'))
- l.append(open('glance/db/models.py','w'))
- map(lambda f:f.close(),l)
6,关于包的导入分为import和from...import...但是二者无论何时何位置,都必须遵循一个原则就是:凡是在导入时带点的,点的左边都必须是一个包,否则非法。可以带有一连串的点,但是必须遵循这个原则。
7,模块名区分大小写,foo.py和FOO.py是两个模块
8,可以用点来调用的有包,模块,函数和类
- # 可以有很多的点,但是点的左边必须是一个包
- # as 另外一个用起来很方便的地方
- import glance.api.policy as policy
- policy.get()
9,包也可以用from...import...来进行导入,这样import的话,import后面是不允许有点的
- from glance.api import policy
- policy.get()
- from glance import api.policy # 这是错误的,pycharm也会给报错的,后面不允许出现点
10,
- # 直接这样写,是找不到的
- # import glance # 如果要这样写,还需要一些操作,除了找不到的问题,还需要解决一些其他问题,下文会细讲
- from part.glance.api import policy # 这就可以了或者把glance文件夹的路径添加到path里面也可以的
- from glance.api import policy 把glance路径加到path里面就可以这样写了
- import sys
- policy.get()
- # ["/Users/guolixiao/PycharmProjects/lisa's_practise/boys/part", "/Users/guolixiao/PycharmProjects/lisa's_practise/boys",
- sys.path.append("/Users/guolixiao/PycharmProjects/lisa's_practise/boys/part/glance")
- # 这样添加完成之后,虽然上面还是飘红,但是其实已经生效了
- print(sys.path)
11,python2里面如果没有双下__init__方法,那么根本没有办法来做这些导入操作的,Python3没有限制
- import glance
- # 这样写只有glance 大文件下的__init__会执行,子文件夹下的不会执行
- # 模块和包还是有一点不一样的,模块一导入相当于执行了这个py文件
- # 那问题来了,你这样导入包得话,他会去执行啥呢?啥也没执行,只有空的__init__函数
- # 导入包的话,默认会执行包里面的__init__文件,这个是一定的,所以我们可以在__init__文件里面加代码
- # glance.api.policy.get() # AttributeError: module 'glance' has no attribute 'api'
12,其实也不是所有的内置模块,都可以直接用import 包名 这样的方式来导入,当然大部分是可以的,有一个例外就是urllib
- import urllib
- urllib.urlopen() # 这样是找不到的
- # 这可以用from的方式来导入,这其实也就是说,他其实也是一个包,但是他没有对这个包进行任何的处理
- # 只有进行过特殊处理的,来可以像导入一个模块那样直接import 包名
- from urllib import urlopen
13,照搬老师的博客
- 什么是模块?
- # 常见的场景:一个模块就是一个包含了python定义和声明的文件,文件名就是模块名字加上.py的后缀。
- # 但其实import加载的模块分为四个通用类别:
- #
- # 1 使用python编写的代码(.py文件)
- #
- # 2 已被编译为共享库或DLL的C或C++扩展
- #
- # 3 包好一组模块的包
- #
- # 4 使用C编写并链接到python解释器的内置模块
- #
- 为何要使用模块?
- # 如果你退出python解释器然后重新进入,那么你之前定义的函数或者变量都将丢失,因此我们通常将程序写到文件中以便永久保存下来,需要时就通过python test.py方式去执行,此时test.py被称为脚本script。
- #
- # 随着程序的发展,功能越来越多,为了方便管理,我们通常将程序分成一个个的文件,这样做程序的结构更清晰,方便管理。这时我们不仅仅可以把这些文件当做脚本去执行,还可以把他们当做模块来导入到其他的模块中,实现了功能的重复利用,
14,绝对路径情况,从外到内,这些都是操作怎么直接import 包名的,我们也希望直接导入包名会把里面所有的变量和函数加载到内存里,这样我调用的时候就能调用到了,相当于是一个连续出发的动作。
- import glance 调用的文件
- # 绝对路径的时候,要给全路径,不然找不到,外面执行就能找到
- print(sys.path) # 写内层和外层都要以这里面有的路径为基准,他有的路径就是glance的上层和上上层,才可以找到
- print("glance***************")
- from part.glance import api
- from part.glance import cmd
- from part.glance import db
- print("glance-api******")
- # import policy # 这个只可以在当前文件执行的时候会找到,到外面就找不到了,其实是没有什么意义的,因为我们不会再包的内部做什么操作,都是在外面操作
- # import versions
- from part.glance.api import policy # 我们需要import然后把变量和函数加载到内存,然后才可以使用
- from part.glance.api import versions
15包的进阶,绝对路径有个问题,就是我的包一旦移动了路径,前面写的就都得修改,这不是我们想要的,所以我们引入了相对路径,绝对路径修改后的绝对路径
- # 我在part目录下新建一个dir文件夹,然后把整个glance文件,拖进去,当然pycharm会自动给我们修改绝对路径
- # 但是我们不想用绝对路径了,相对路径怎么解决呢
- # import glance # 因为glance变成了当前执行文件的下一层,所以这样肯定是找不到了
- from dir import glance
- # 绝对路径的时候,要给全路径,不然找不到,外面执行就能找到
- glance.db.models.register_models('sql')
- glance.api.policy.get()
- from dir.glance import db # glance 目录的init文件
- from dir.glance import api
- from part.dir.glance import cmd
- from dir.glance.api import versions
- from dir.glance.api import policy
16,相对路径写法,这种情况下改变包的路径也不用去管,这是相对路径的优点,只要相对位置不变就可以,可以随意移动包,只要能找到包的位置,就能找到包里面的模块,缺点是不能再包里面使用,但是绝对路径里面外面都可以使用的,绝对路径只要写全,path里面能找到的就可以内部外部都执行
- import glance
- glance.db.models.register_models('sql')
- glance.api.policy.get()
- from . import db
- from . import api
- from . import cmd
- from . import versions
- from . import policy
17,相对路径得话,外面调用不会报错,里面调用就会报错,因为你用点的方式去找的话,只有在外面的角度才能找到的,这是机制决定的,点和点点都不行,只要有相对路径,内部就不可以
- # 总结
- # 使用绝对路径,
- # 不管在包内还是外部,导入了就能用
- # 不能挪动,但是直观
- # 使用相对路径
- # 可以随意移动包,只要能找到包的位置,就可以使用包里面的模块
- # 不能在包里直接使用模块了,包里的模块如果想使用其他模块的内容只能使用相对路径,使用了相对路径就不能再包内直接执行了
18,一般我们也不需要修改包内部的内容,包都是直接拿来用就行。一般你能做一个很厉害的包的时候,就用相对路径,其他时候,就用绝对路径就可以了
目前大部分还没有达到能制作包的程度,另外包和包之间不可以相互依赖,极少的情况下可以,这种情况下,两个包需要一起安装的。最好是独立包,自己做的包,可以引用Python本身的内置模块,一般不需要引用扩展模块或者自己写的其他模块
19,包里面的__all__,all方法是和星号来配合使用的,第三种可以直接调用包的方法,这个不用glance来调用的话,目前我没有尝试成功, 从glance开始调用是成功的。先记住相对和绝对路径的吧
- import glance
- glance.db.models.register_models('sql')
- glance.api.policy.get()
- # policy.get() 这样一直不成功
- from .api import *
- from .cmd import *
- from .db import *
- __all__ = ['policy','versions']
20,软件开发代码规范,以后所有的非web项目作业,都要用下面的格式来写,六个目录,bin,conf,core,db,lib,log,web项目他还有一个其他的规范
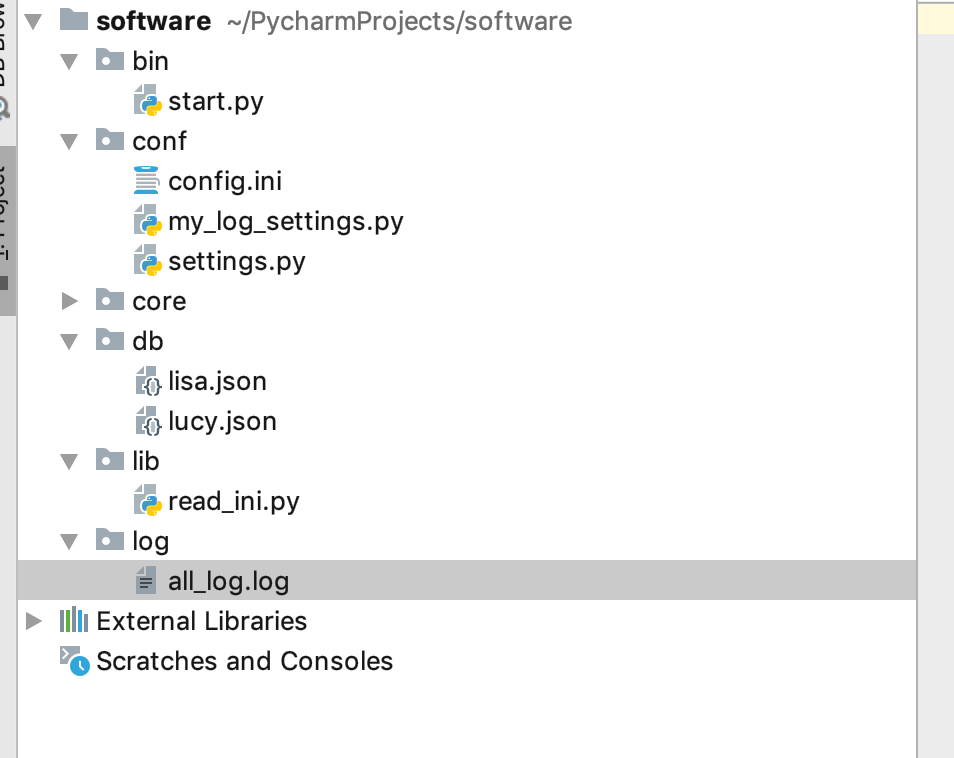
21,bin 目录下就写一个开始文件start.py,程序入口,你写的程序,其实99.9%不是你维护的,这个程序可能就交给运维,如果做运维的话,接触的就不止是Python代码,还有可以有Java,PHP,C++,C语言,go语言,PHP,都需要接触,可能都不精,那我就我规定好,所有的语言写的,我都有一个叫bin的目录,这里面存的都是我的程序入口,这里面就一个文件,Python里面叫start.py,PHP里面叫做start.php,只要执行start.py整个程序就执行起来了,我也不知道中间是怎么走的,这就是我们需要要的效果,只要执行他,整个程序就跑起来。所以这个文件里面的逻辑,不宜复杂,应该是非常简短的。有可能只有一句if __name__ =='__main__': core.main,当然不包括import啥的。假如你写了20几个py文件,不指定入口文件的话,别人看起来是非常痛苦的。
- import sys
- import os
- sys.path.append(os.path.dirname(os.getcwd()))
- # 拿到当前路径的上一层目录,并把它放入到path里面,这是一个定式,只要每次执行前都把它这句话拿过来执行一下就好
- from core import core # 这句话只有在pycharm里面执行没有问题,因为他会自动把路径加入到sys.path
- # print(sys.path) 会自动添加当前路径和pycharm的项目路径,这个项目路径是只有在pycharm里面才会添加的
- if __name__ =='__main__':
- core.main()
22,core目录下的core.py,这个文件里面存的是你写的代码,整个目录结构中,只有这一个是和代码相关的文件,假如我在这个文件写一个main方法,这个方法才是我们程序真正的入口,这里面可能有调用了其他的方法,
- from core import login
- # 由于项目路径直接加到了path里面,所以直接从core文件夹来导入就可以了,login还是在和core同级的文件login.py里面
- def main():
- print('main')
- login.login()
23,conf文件夹,配置文件文件夹,配置文件是给运维人员看的,运维人员虽然不懂代码,但是他却可以给你去调一些参数,比方说,IP地址,端口号,用户名,密码,文件路径,等等,后期可能会有数据库的名称,mysql还是Oracle呢等等。还能去配置一些程序的功能,但是我可以通过去修改配置项去增加或者修改一个功能。
24,db文件夹,主要放一些数据;lib里面主要放一些自己写的模块和包,通用的一些模块,每次写都可以用的,单是没有自动安装在Python解释器里面,他是你自己写的一些通用模块。比方说,你把你的计算器写成一个通用模块;log文件夹是你执行程序的过程中,你希望记录的一些过程。把中间的一些结果记录下来,后面我们还会去学习一个专门记录LOG文件的一个模块,现在先了解就好。
25, 异常处理,重要,但是不难,异常主要有两大类,程序的逻辑错误,语法错误,我们在程序中就要尽量去规避掉,程序中的语法错误,逻辑错误很多,也是我们真正要处理的一部分,如下
- # 1/0 # ZeroDivisionError: division by zero
- # name # NameError: name 'name' is not defined
- # 2+'3' # TypeError: unsupported operand type(s) for +: 'int' and 'str'
- # [][3] # IndexError: list index out of range
- # {}['k'] # KeyError: 'k'
- ret = int(input('number >>>')) # 加入输入'a'
- print(ret * '*')
- # ValueError: invalid literal for int() with base 10: 'a'
26,遇到错误,程序就停下来不执行了,这不是我们我需要的,我们希望程序可以忽略掉错误,继续往下执行,或者是说,发生错误后,我们可以针对错误去做一些处理,能不是直接抛出错误,结束运行。那么久可以用try...catch...来处理。把你想要处理的,捕捉错误的代码放入到try里面,如果有错误就会被except捕捉到。try里面的代码是一定会执行的,除非遇到错误,except里面的代码,没有错误不会去执行。捕捉except后面指定的错误类型。一般情况下我们会把你认为可能会有问题的,或者你预估到客户可能会输入错误的的,但是你却没有办法处理的,放入到try...catch...里面。
- try:
- ret = int(input('number >>>')) # 加入输入'a'
- print(ret * '*')
- except ValueError:
- print("您输入的内容有误,请输入一个数字")
- 运行结果:
- number >>>aaa
- 您输入的内容有误,请输入一个数字
27,except 支持多分支
- try:
- [][3]
- ret = int(input('number >>>')) # 加入输入'a'
- print(ret * '*')
- except ValueError:
- print("您输入的内容有误,请输入一个数字")
- except IndexError:
- print("index error,list index out of range")
28,有没有一个万能的可以捕获所有错误的类型呢?有,就是exception
- try:
- [][3]
- ret = int(input('number >>>')) # 加入输入'a'
- print(ret * '*')
- except ValueError:
- print("您输入的内容有误,请输入一个数字")
- except IndexError:
- print("index error,list index out of range")
- except Exception:
- print("你错了,老铁")
29,总结
- # 总结:
- # 程序一旦发生错误,就从错误大的位置停下来了,不再继续执行后面的内容
- # 使用try和except就能处理异常
- # try使我们需要处理的代码
- # except后面跟一个错误类型,当代码发生错误且错误类型符合的时候,就会执行except中的代码
- # except支持多分支
- #有没有一个能处理所有错误的类型:exception
- # 有了万能的处理机制仍然需要把能预测到的问题单独处理
- # 单独处理的所有内容都应该卸载万能异常之前
# else:没有异常的时候执行else中的代码
finally:不管代码是否异常,都会执行
30,try...except...else...
- try:
- ret = int(input('number >>>')) # 加入输入'a'
- print(ret * '*')
- print("没有被错误中断得话,这里面的代码就会全部执行")
- except ValueError:
- print("您输入的内容有误,请输入一个数字")except Exception:
- print("except里面,捕捉到指定错误是会执行")
- else:
- print("没有捕捉到错误的时候,执行这一步") # 类似循环的else分支,没有被break打断就会去执行
31,except后面直接加冒号,指的是捕捉所有错误类型
32,finally分支,因为我们希望在最后有一段代码,不管是否有异常都希望去执行,比如下面的例子
- def func():
- try:
- f = open('file','w') # 这儿只是举个例子是操作文件,也有可能是操作数据库,和网络,而且并不是所有都有with语法
- '''
- 中间自己写的一些代码,可能会有错,也可能没错,但是不管有错没错,我打开的文件,都需要关闭的
- '''
- # f.close() 加在这儿的话,程序遇到错误,就没有办法关闭了,所以不可以
- print("try")
- return # 加上这句即使return,finnally也会执行
- except:
- # f.close() # 这儿也不合适,只有发生错误才会关,没错呢?
- print("except")
- # else:
- # f.close() # 也不合适,发生错误关不了
- finally:
- f.close() # 只有加在这儿是可以的
- f.close() # 加在外面为什么不行呢?如果前面有return得话,这句话就不执行了,但是finally里面即使前面return了,还是会执行。
- print(func())
33,finally和return相遇的时候还是会执行,一般用作函数里做异常处理时,不管是否异常,去做一些收尾工作。一般else里面都是结论,就是没有错误的话我就是做什么,或者去触发一个什么任务。
34,什么时候用异常处理?try...except...应该尽量少用,因为他本身就是附加给程序的一种异常处理的逻辑,与你的主要工作是没有关系的,加多了,会导致代码可读性变差,只有在有些程序无法预知时,才应该加上try...except...,其他的逻辑错误,应该尽量修正。在代码没有成型之前,不要加这些,尽量先修正自己能够杜绝的,无法杜绝的再用try...except...去处理。
35,except打印具体错误,
- try:
- '''
- 你的代码
- '''
- 1/0
- except Exception as e: # 这个名字随便起,要有意义
- print('你错了',e) # 你错了 division by zero
36,三级菜单
- menu = {
- '北京':{
- '海淀':{
- '五道口':{
- 'soho':{},
- '网易':{},
- 'google':{}
- },
- '中关村':{
- '爱奇艺':{},
- '汽车之家':{},
- 'youku':{},
- },
- '上地':{
- '百度':{},
- }
- },
- '昌平':{
- '沙河':{
- '老男孩':{},
- '北航':{}
- },
- '天通源':{},
- '回龙观':{}
- },
- '朝阳':{},
- '东城':{}
- },
- '上海':{
- '闵行':{},
- '闸北':{},
- '浦东':{}
- },
- '山东':{},
- }
- # 此处的b 是比较难理解的地方,利用循环,实现返回上一层
- # 此处的q 需要给每一层都要返回一个q 知道最上一层
- # 最后层为空是,继续打印这一层的key,除非输入q或者是b
- # 递归实现
- def threeLM(dic):
- while True:
- for k in dic:print(k)
- key = input('input>>').strip() # 北京
- if key == 'b' or key == 'q' :return key
- elif key in dic.keys() and dic[key]:
- ret = threeLM(dic[key])
- if ret == 'q':return 'q' # 加上这就会就会一直return到最后,不加这句话其实只是return了一层而已
- print(ret)
- # elif (not dic.get(key)) or (not dic[key]):
- # continue
- # 最后两行不写也是continue的效果
- # 列表实现,我觉得列表更好理解,堆栈的
- l =[menu]
- while l:
- for key in l[-1]:print(key)
- k = input('input>>').strip()
- if k in l[-1].keys() and l[-1][k]:
- l.append(l[-1][k]) # 每次把用户输入key对应的小字典,放入列表的最后一个
- if k == 'b':
- l.pop()
- if k == 'q':
- break
- else:continue
- threeLM(menu)
37,大作业 select name age where age > 12
- column_dic = {'id':0,'name':1,'age':2,'phone':3,'job':4}
- # 去文件里面拿符合age > 22这个条件的行
- def filter_hander(operate,con):
- selected_lst = []
- col,val = con.split(operate)
- col = col.strip()
- val = val.strip()
- # 文件中取到的值,和22来比较,所以要用整形
- # 如果是like的话 ==,这个比较字符串就可以了,不用强转,我不在意你是否是int
- judge = 'int(line_lst[column_dic[col]]) %s int(val)' %operate if operate=='<' or operate=='>' else \
- 'line_lst[column_dic[col]] %s val'%operate
- f = open('users',encoding='utf-8')
- for line in f:
- line_lst = line.strip().split(',')
- if eval(judge):
- selected_lst.append(line_lst)
- f.close()
- return selected_lst
- # 去文件里面拿符合age > 22这个条件的行
- def get_selected_line(con):
- if '>' in con:
- selected_lst = filter_hander('>',con)
- elif '<' in con:
- selected_lst = filter_hander('<', con)
- elif '=' in con:
- selected_lst = filter_hander('==',con.replace('=','==')) # =换成==
- elif 'like' in con:
- selected_lst = filter_hander('in',con) # like转换成in
- return selected_lst
- # 这个函数的提高再用应用了列表生成时
- # 这个函数拿到了你想显示的参数,name 和 age 返回值是一个列表
- # 这个处理的是你像要哪些参数
- def get_show_list(col_condition):
- col_info_lst = col_condition.strip().split('select')
- col_info_lst = [col_info_item for col_info_item in col_info_lst if col_info_lst.strip()]
- if col_info_lst:
- col_info = col_info_lst[0].strip()
- if '*' == col_info:
- return column_dic.keys()
- elif col_info:
- ret = col_info.strip(',')
- return [item.strip() for item in ret]
- else:print(col_info) # 空的时候
- # 返回符合条件行的指定参数
- def show(selected_lst,show_lst):
- for selected_item in selected_lst:
- for col in show_lst:
- print(selected_item[column_dic[col]],end = '')
- print('') # 打印一个空
- # condition = input('>>>')
- condition = 'select name age where age > 22'
- ret = condition.split('where')
- con = ret[1].strip()
- print(con) # age > 22
- show_lst = get_show_list(ret[0])
- selected_lst = get_selected_line(con)
- show(selected_lst,show_lst)
day21:包和异常处理的更多相关文章
- day 21 - 1 包,异常处理
创建目录代码 1. 无论是 import 形式还是 from...import 形式,凡是在导入语句中(而不是在使用时)遇到带点的,都要第一时间提高警觉:这是关于包才有的导入语法2. 包是目录级的(文 ...
- python学习之老男孩python全栈第九期_day021知识点总结——包、异常处理
一. 包 # 把解决一类问题的模块放在同一个文件夹里 -- 包 # 创建目录代码# import os# os.makedirs('glance/api')# os.makedirs('glance/ ...
- python:包与异常处理
一.包 1,什么是包? 把解决一类问题的模块放在同一个文件夹里-----包 2,包是一种通过使用‘.模块名’来组织python模块名称空间的方式. 1. 无论是import形式还是from...imp ...
- python------模块和包及异常处理
一.模块 所有的模块导入都应该尽量往上写,且顺序为: a:内置模块 b:扩展模块 c:自定义模块 #my_module.py print('from the my_module.py') money= ...
- 编程小白入门分享三:Spring AOP统一异常处理
Spring AOP统一异常处理 简介 在Controller层,Service层,可能会有很多的try catch代码块.这将会严重影响代码的可读性."美观性".怎样才可以把更多 ...
- 【10-25】intelliji ide 学习笔记
快捷键 /** alter+enter 导包,异常处理等提示 psvm 快速main函数 sout 快速sysout语句 fi 快速for循环 ctrl+d 重复一行 Ctrl+X 删除行 Ctrl+ ...
- [黑马程序员] I/O
---------------------- ASP.Net+Android+IO开发..Net培训.期待与您交流! ---------------------- 0. IO流概述: Java对数据的 ...
- Atitit s2018.2 s2 doc list on home ntpc.docx \Atiitt uke制度体系 法律 法规 规章 条例 国王诏书.docx \Atiitt 手写文字识别 讯飞科大 语音云.docx \Atitit 代码托管与虚拟主机.docx \Atitit 企业文化 每日心灵 鸡汤 值班 发布.docx \Atitit 几大研发体系对比 Stage-Gat
Atitit s2018.2 s2 doc list on home ntpc.docx \Atiitt uke制度体系 法律 法规 规章 条例 国王诏书.docx \Atiitt 手写文字识别 ...
- 学习笔记——AOP
以下纯属个人刚了解点皮毛,一知半解情况下的心得体会: ==================================================================== AOP( ...
随机推荐
- 先从一个 libev 的 demo 入手
最近想研究下 libev 这个网络库,所以先从官方文档一个最简单的 demo 开始,代码如下: //io.c // a single header file is required #include ...
- Android Studio集成到Genymotion模拟器
环境:Mac Android Studio 一.下载Android Studio 下载地址:http://www.android-studio.org/ 这个的安装没啥好说的了,基本的. 二.下载Ge ...
- sshpass 实现shell脚本直接加载密登录服务器
主要命令:sshpass 这个命不是系统自带的,需要安装: # which sshpass/usr/bin/sshpass[root@666 tools]# rpm -qf /usr/bin/sshp ...
- Python之string
1.string模块支持哪些字符形式?分别是什么. string支持的字符形式有: ('_re', '====>', <module 're' from 'C:\Python25\lib\ ...
- 刨根问底 | Elasticsearch 5.X集群多节点角色配置深入详解【转】
转自:https://blog.csdn.net/laoyang360/article/details/78290484 1.问题引出 ES5.X节点类型多了ingest节点类型. 针对3个节点.5个 ...
- c++ 条件变量
.条件变量创建 静态创建:pthread_cond_t cond=PTHREAD_COND_INITIALIZER; 动态创建:pthread_cond _t cond; pthread_cond_i ...
- permutohedral lattice理解
[完结]saliency filters精读之permutohedral lattice 2012年09月28日 22:40:08 工长山 阅读数:12432 版权声明:本文为博主原创文章,未经 ...
- 第四百零三节,python网站在线支付,支付宝接口集成与远程调试,
第四百零三节,python网站在线支付,支付宝接口集成与远程调试, windows系统安装Python虚拟环境 首先保证你的系统已经安装好了Python 安装virtualenv C:\WINDOWS ...
- 项目中 2个或者多个EF模型 表名称相同会导致生成的实体类 覆盖的解决方法
场景: 2个数据库, 一个新,一个旧, 把旧的 数据库中的数据,导入到新的数据库中, 使用到了2个 EF实体模型, 新数据库 和 旧数据库中的表,有的名称是相同的 (但是结构是不同的) 旧的数据 ...
- 最新Java基础面试题及答案整理
最近在备战面试的过程中,整理一下面试题.大多数题目都是自己手敲的,网上也有很多这样的总结.自己感觉总是很乱,所以花了很久把自己觉得重要的东西总结了一下. 面向对象和面向过程的区别 面向过程: 优 ...