潭州课堂25班:Ph201805201 爬虫高级 第十课 Scrapy-redis分布 (课堂笔记)
利用 redis 数据库,做 request 队列,去重,多台数据共享,
scrapy 调度 基于文件每户,默认只能在单机运行,
scrapy-redis 默认把数据放到 redis 中,实现数据共享,
安装: pip install scrapy-redis
命令与 scrapy 没有不同

在该文件下导入 scrapy_redis

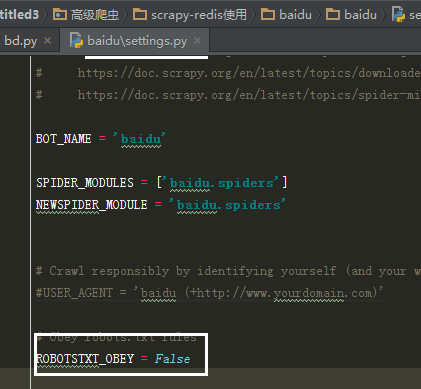
在配置文件中添加内容
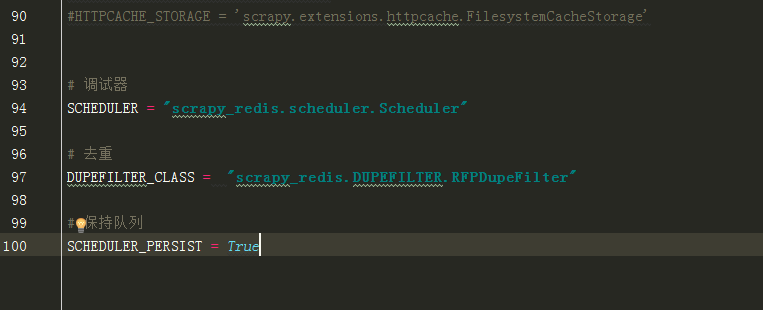
1(必须). 使用了scrapy_redis的去重组件,在redis数据库里做去重
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
2(必须). 使用了scrapy_redis的调度器,在redis里分配请求
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
3(可选). 在redis中保持scrapy-redis用到的各个队列,从而True允许暂停和暂停后恢复,也就是不清理redis queues
SCHEDULER_PERSIST = True
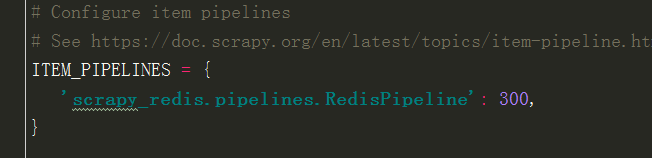
4(必须). 通过配置RedisPipeline将item写入key为 spider.name : items 的redis的list中,供后面的分布式处理item
这个已经由 scrapy-redis 实现,不需要我们写代码,直接使用即可
ITEM_PIPELINES = {
'scrapy_redis.pipelines.RedisPipeline': 100
}
5(必须). 指定redis数据库的连接参数
REDIS_HOST = '127.0.0.1'
REDIS_PORT = 6379
这里要改下

改成
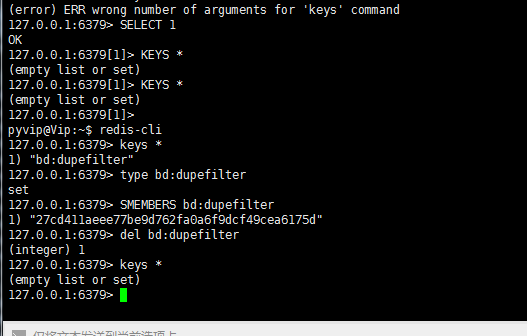

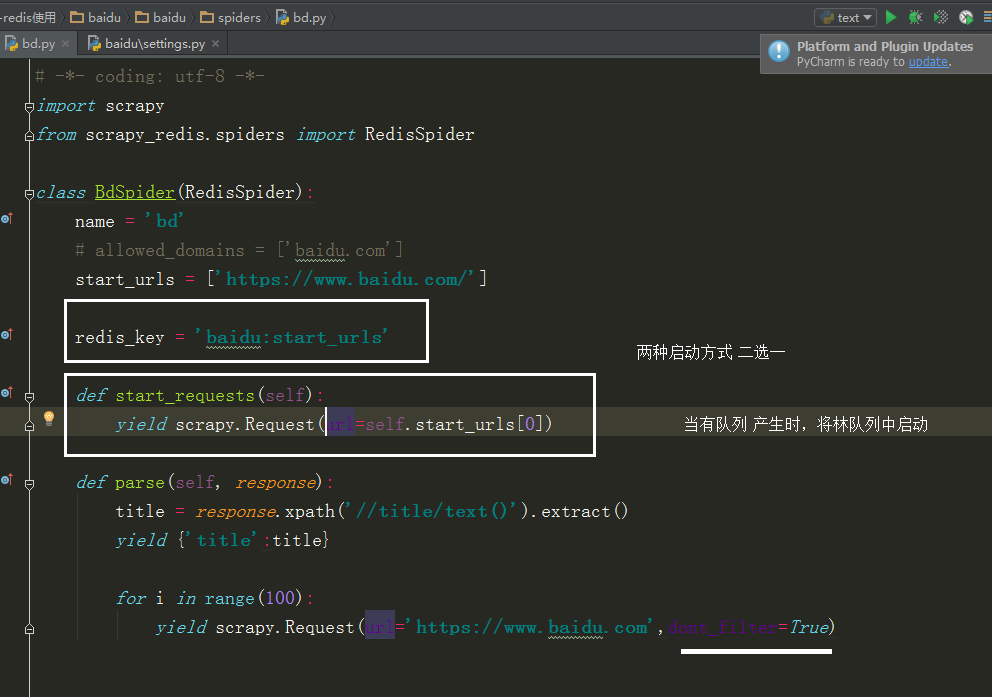
当选择 redis_key 启动时,会从 redis 中获取 url
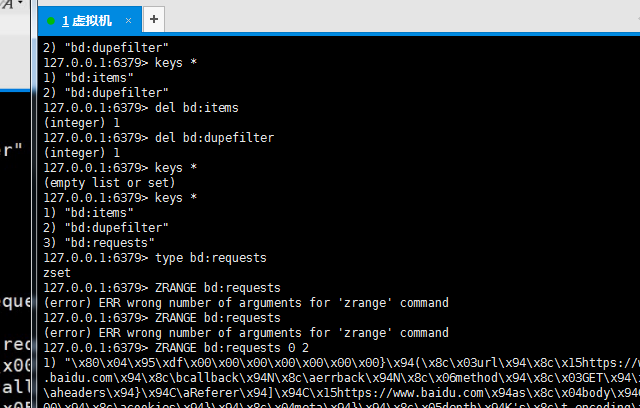
所以在 redis 中用到下面这个命令,才会启动

redis 中查队列

潭州课堂25班:Ph201805201 爬虫高级 第十课 Scrapy-redis分布 (课堂笔记)的更多相关文章
- 潭州课堂25班:Ph201805201 爬虫高级 第十三 课 代理池爬虫检测部分 (课堂笔记)
1,通过爬虫获取代理 ip ,要从多个网站获取,每个网站的前几页2,获取到代理后,开进程,一个继续解析,一个检测代理是否有用 ,引入队列数据共享3,Queue 中存放的是所有的代理,我们要分离出可用的 ...
- 潭州课堂25班:Ph201805201 爬虫高级 第十二 课 Scrapy-redis分布 项目实战 (课堂笔记)
建代理池, 1,获取多个网站的免费代理IP, 2,对免费代理进行检测,>>>>>携带IP进行请求, 3,检测到的可用IP进行存储, 4,实现api接口,方便调用, 5,各 ...
- 潭州课堂25班:Ph201805201 爬虫高级 第十一课 Scrapy-redis分布 项目实战 (课堂笔
- 潭州课堂25班:Ph201805201 爬虫高级 第八课 AP抓包 SCRAPY 的图片处理 (课堂笔记)
装好模拟器设置代理到 Fiddler 中, 代理 IP 是本机 IP, 端口是 8888, 抓包 APP斗鱼 用 format 设置翻页
- 潭州课堂25班:Ph201805201 爬虫高级 第七课 sclapy 框架 爬前程网 (课堂笔)
定时对该网页数据采集,所以每次只爬第一个页面就可以, 创建工程 scrapy startproject qianchen 创建运行文件 cd qianchenscrapy genspider qian ...
- 潭州课堂25班:Ph201805201 爬虫高级 第六课 sclapy 框架 中间建 与selenium对接 (课堂笔记)
因为每次请求得到的响应不一定是正常的, 也可以在中间建中与个类的方法,自动更换头自信,代理Ip, 在设置文件中添加头信息列表, 在中间建中导入刚刚的列表,和随机函数 class UserAgent ...
- 潭州课堂25班:Ph201805201 爬虫高级 第五课 sclapy 框架 日志和 settings 配置 模拟登录(课堂笔记)
当要对一个页面进行多次请求时, 设 dont_filter = True 忽略去重 在 scrapy 框架中模拟登录 创建项目 创建运行文件 设请求头 # -*- coding: utf-8 ...
- 潭州课堂25班:Ph201805201 爬虫高级 第四课 sclapy 框架 crawispider类 (课堂笔记)
以上内容以 spider 类 获取 start_urls 里面的网页 在这里平时只写一个,是个入口,之后 通过 xpath 生成 url,继续请求, crawispider 中 多了个 rules ...
- 潭州课堂25班:Ph201805201 爬虫高级 第三课 sclapy 框架 腾讯 招聘案例 (课堂笔记)
到指定目录下,创建个项目 进到 spiders 目录 创建执行文件,并命名 运行调试 执行代码,: # -*- coding: utf-8 -*- import scrapy from ..items ...
随机推荐
- VS和IIS的一些问题
运行所有MVC一直502,重启了iis服务, 之后弹出这个框: 之后的解决办法: 1. If you open the applicationhost,config file in VS while ...
- 解决notepad++64位没有plugin manager的问题
安装了最新的notepad++版本发现没有插件管理器,很难受. 后来上官网发现了这样一句话 Note that the most of plugins (including Plugin Manage ...
- 设置git记住用户和密码
git config --global credential.helper store
- php函数xml转化数组
/** * xml转数组 * @param $xml * @return array */ function xml_to_array( $xml ) { $reg = "/<(\\w ...
- php处理IOS图片旋转
$picAddr = $url; $exif = exif_read_data($picAddr); $image = imagecreatefromjpeg($picAddr); if($exif[ ...
- 5336: [TJOI2018]party
题解: 比较水啦..dp套dp f[i][j][k]表示枚举了前i位,最大公共子序列匹配状态为j,noi匹配到了第k位 因为g[j]和g[j+1]最多差1 所以可以状压成j 然后内层再dp一下搞出下一 ...
- bzoj2969矩形粉刷
题解: 和前面那个序列的几乎一样 容斥之后变成求不覆盖的 然后再像差分的矩形那样 由于是随便取的所以这里不用处理前缀和直接求也可以 代码: #include <bits/stdc++.h> ...
- 支付宝 app支付 沙盘使用
文档说明 沙箱测试: App支付沙箱接入注意点 1.app支付支持沙箱接入:在沙箱调通接口后,必须在线上进行测试与验收,所有返回码及业务逻辑以线上为准:2.app支付只支持余额支付,不支持银行卡.余额 ...
- MUI组件四:选择器、滚动条、单选框、区域滚动和轮播组件
目录(?)[+] 1.picker(选择器) mui框架扩展了pipcker组件,可用于弹出选择器,在各平台上都有统一表现.poppicker和dtpicker是对picker的具体实现.*pop ...
- 【AtCoder】AGC032
AGC032 A - Limited Insertion 这题就是从后面找一个最靠后而且当前可以放的,可以放的条件是它的前面正好放了它的数值-1个数 如果不符合条件就退出 #include <b ...