03Hadoop的TopN的问题
TopN的问题分为两种:一种是建是唯一的,还有是建非唯一。我们这边做的就是建是唯一的。
这里的建指得是:下面数据的第一列。
有一堆数据,想根据第一列找出里面的Top10.
如下:
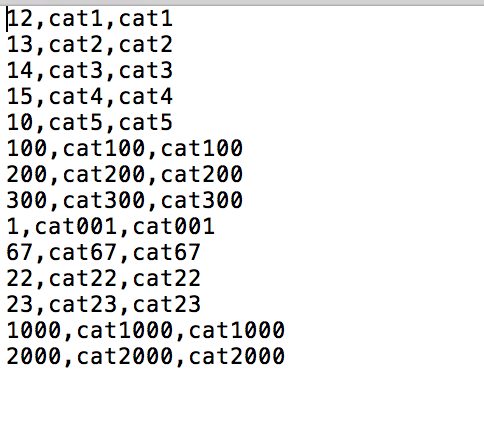
关键:在map和reduce阶段都使用了TreeMap这个数据结构,他有从小到大的排序功能,所以排第一的最小,依次增大。限定大小为10 ,只要超过十,就把排在第一个的值给删除。
代码如下:
package com.book.topn; import java.io.IOException;
import java.util.Iterator;
import java.util.Set;
import java.util.SortedMap;
import java.util.TreeMap; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class TopN { static class Mapper1 extends Mapper<LongWritable, Text, NullWritable, Text> {
public SortedMap<Double, Text> top10cats = new TreeMap<Double, Text>();
public int N = 10; @Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, NullWritable, Text>.Context context)
throws IOException, InterruptedException { String[] lines = value.toString().split(",");
Double weight = Double.parseDouble(lines[0]);
// 一行读完,然后把数据
top10cats.put(weight, new Text(value)); // 如果Map
if (top10cats.size() > N) {
top10cats.remove(top10cats.firstKey());
}
} // 待执行完map的读取比较操作后,就把TreeMap里面的数据打印出来。
@Override
protected void cleanup(Mapper<LongWritable, Text, NullWritable, Text>.Context context)
throws IOException, InterruptedException { Set<Double> set = top10cats.keySet(); Iterator<Double> iterator = set.iterator(); while (iterator.hasNext()) { context.write(NullWritable.get(), top10cats.get(iterator.next()));
} } } static class reduce1 extends Reducer<NullWritable, Text, NullWritable, Text> { SortedMap<Double, Text> finalTop = new TreeMap<Double, Text>();
private int N = 10; @Override
protected void reduce(NullWritable arg0, Iterable<Text> values,
Reducer<NullWritable, Text, NullWritable, Text>.Context context)
throws IOException, InterruptedException { for (Text value : values) { String[] finalresult = value.toString().split(","); finalTop.put(Double.parseDouble(finalresult[0]), new Text(value));
if (finalTop.size() > N) {
finalTop.remove(finalTop.firstKey());
}
; } Set<Double> set = finalTop.keySet(); Iterator<Double> iterator = set.iterator(); // 依次写入到文件中
while (iterator.hasNext()) { context.write(NullWritable.get(), finalTop.get(iterator.next()));
} } } public static void main(String[] args) throws Exception, IOException { Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
job.setJarByClass(TopN.class); job.setMapperClass(Mapper1.class);
job.setReducerClass(reduce1.class); job.setMapOutputKeyClass(NullWritable.class);
job.setMapOutputValueClass(Text.class); job.setOutputValueClass(NullWritable.class);
job.setOutputKeyClass(Text.class); // 指定输入的数据的目录
FileInputFormat.setInputPaths(job, new Path("/Users/mac/Desktop/TopN.txt")); FileOutputFormat.setOutputPath(job, new Path("/Users/mac/Desktop/flowresort")); boolean result = job.waitForCompletion(true);
System.exit(result ? 0 : 1); } }
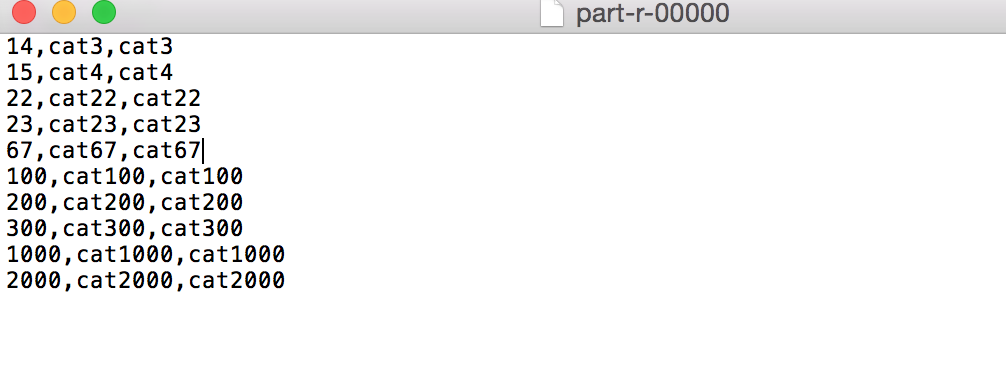
结果:
注意点:
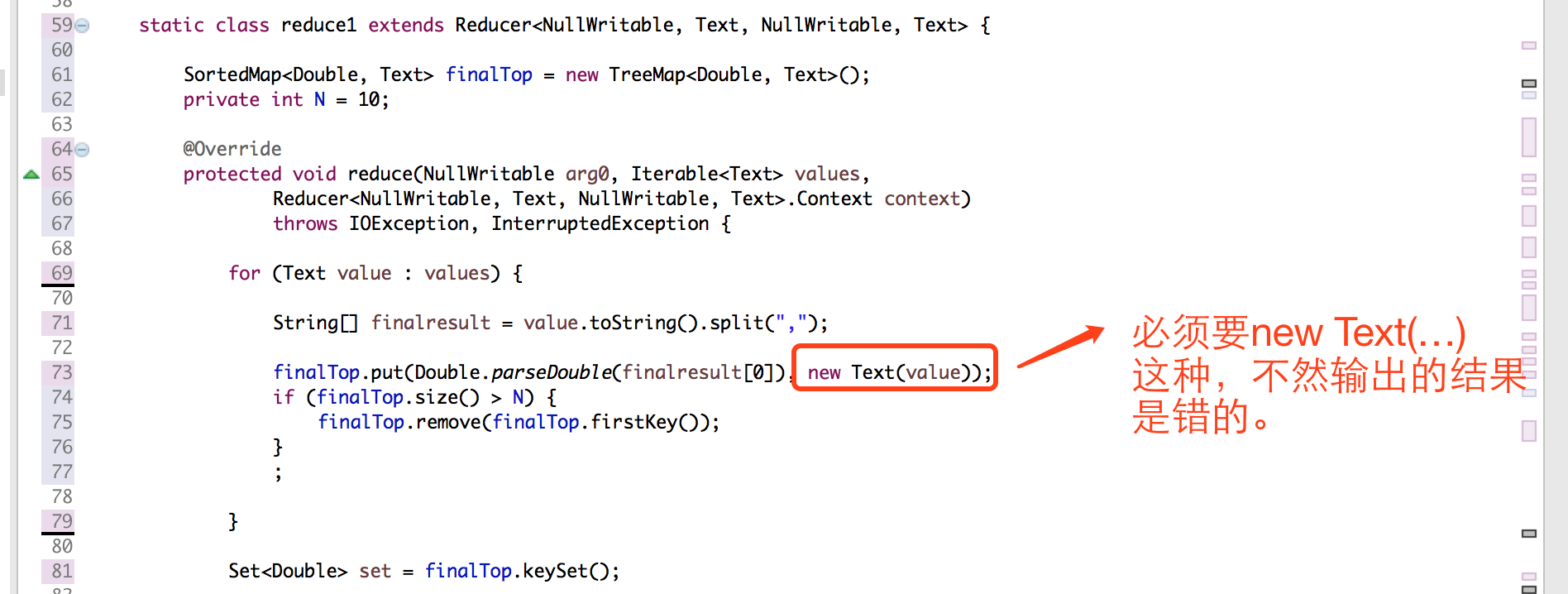
上面的注意点一定要切记。
03Hadoop的TopN的问题的更多相关文章
- storm入门(二):关于storm中某一段时间内topN的计算入门
刚刚接触storm 对于滑动窗口的topN复杂模型有一些不理解,通过阅读其他的博客发现有两篇关于topN的非滑动窗口的介绍.然后转载过来. 下面是第一种: Storm的另一种常见模式是对流式数据进行所 ...
- 【mysql】一维数据TopN的趋势图
创建数据表语句 数据表数据 对上述数据进行TopN排名 select severity,sum(count) as sum from widgt_23 where insertTstamp>=' ...
- 【转载】使用LFM(Latent factor model)隐语义模型进行Top-N推荐
最近在拜读项亮博士的<推荐系统实践>,系统的学习一下推荐系统的相关知识.今天学习了其中的隐语义模型在Top-N推荐中的应用,在此做一个总结. 隐语义模型LFM和LSI,LDA,Topic ...
- QL查询案例:取得分组 TOP-N
[转]SQL查询案例:取得分组 TOP-N CREATE TABLE TopnTest ( name VARCHAR(10), --姓名 procDate DATETIME, ...
- 使用LFM(Latent factor model)隐语义模型进行Top-N推荐
最近在拜读项亮博士的<推荐系统实践>,系统的学习一下推荐系统的相关知识.今天学习了其中的隐语义模型在Top-N推荐中的应用,在此做一个总结. 隐语义模型LFM和LSI,LDA,Topic ...
- 大数据算法设计模式(1) - topN spark实现
topN算法,spark实现 package com.kangaroo.studio.algorithms.topn; import org.apache.spark.api.java.JavaPai ...
- topN 算法 以及 逆算法(随笔)
topN 算法 以及 逆算法(随笔) 注解:所谓的 topN 算法指的是 在 海量的数据中进行排序从而活动 前 N 的数据. 这就是所谓的 topN 算法.当然你可以说我就 sort 一下 排序完了直 ...
- pyspark进行词频统计并返回topN
Part I:词频统计并返回topN 统计的文本数据: what do you do how do you do how do you do how are you from operator imp ...
- TOP-N类查询
Top-N查询 --Practices_29:Write a query to display the top three earners in the EMPLOYEES table. Displa ...
随机推荐
- curl获取结果乱码的解决方法之CURLOPT_ENCODING(curl/Post请求)
//php脚本开始 /*POST请求远程内容函数*/ function ppost($url,$data,$ref){ // 模拟提交数据函数 $curl = curl_init( ...
- Linux安装Redis和Redis基本操作命令
01Redis简介 REmote DIctionary Server(Redis) 是一个由Salvatore Sanfilippo写的key-value存储系统. Redis是一个开源的使用ANSI ...
- 初窥Java--1(下载JADK,搭建环境变量)
window系统安装java 首先我们需要下载java开发工具包JDK,下载地址:http://www.oracle.com/technetwork/java/javase/downloads/ind ...
- React Native小白入门学习路径——二
万万没想到,RN组仅剩的一个学长也走了,刚进实验室没几天就被告知这样的事情,一下子还真的有点接受不了,现在RN组就成了为一个没有前辈带的组了,以后学习就更得靠自己了吧.唉,看来得再努力一点了. 这一周 ...
- UltralEdit 替换回车换行符
打开 Ue 工具,写下内容,如下图: 然后按 Ctrl + r,输入 ^p,点击按钮 “全部替换”, 如下图:
- lettcode笔记--Valid Parentheses
20.Valid Parentheses Given a string containing just the characters '(', ')', '{', '}', '[' and ']', ...
- Tornado-cookie
cookie 服务端在客户端的中写一个字符串,下一次客户端再访问时只要携带该字符串,就认为其是合法用户. tornado中的cookie有两种,一种是未加密的,一种是加密的,并且可以配置生效域名.路径 ...
- thymeleaf学习笔记
1.${@dict.hello().fatherName} 显示对象的属性2.${@dict.hello()[0].fatherName} 显示列表对象的属性3.<div th:object=& ...
- SharePoint每日小贴士Web部件
SharePoint每日小贴士Web部件 项目描写叙述 此Web部件从指定SP自己定义列表或一个选定的 RSS源选择一个随机项目.并显示一张图片.标题和一个Tip. 适 ...
- 1.3 java8新特性总结
java8中重要的4个新特性: Lambda Stream Optional 日期时间API 接口方法(default和static方法,jdk9可定义private方法) 一.Lambda impo ...