Apache Spark源码走读之23 -- Spark MLLib中拟牛顿法L-BFGS的源码实现
欢迎转载,转载请注明出处,徽沪一郎。
概要
本文就拟牛顿法L-BFGS的由来做一个简要的回顾,然后就其在spark mllib中的实现进行源码走读。
拟牛顿法
数学原理









代码实现
L-BFGS算法中使用到的正则化方法是SquaredL2Updater。
算法实现上使用到了由scalanlp的成员项目breeze库中的BreezeLBFGS函数,mllib中自定义了BreezeLBFGS所需要的DiffFunctions.
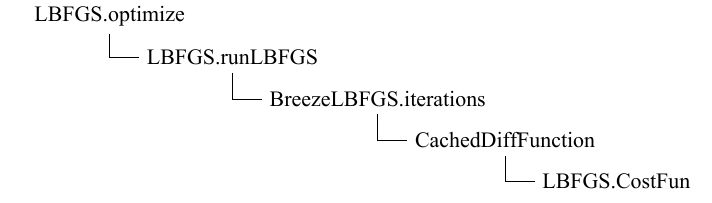
runLBFGS函数的源码实现如下
def runLBFGS(data: RDD[(Double, Vector)],gradient: Gradient,updater: Updater,numCorrections: Int,convergenceTol: Double,maxNumIterations: Int,regParam: Double,initialWeights: Vector): (Vector, Array[Double]) = {val lossHistory = new ArrayBuffer[Double](maxNumIterations)val numExamples = data.count()val costFun =new CostFun(data, gradient, updater, regParam, numExamples)val lbfgs = new BreezeLBFGS[BDV[Double]](maxNumIterations, numCorrections, convergenceTol)val states =lbfgs.iterations(new CachedDiffFunction(costFun), initialWeights.toBreeze.toDenseVector)/*** NOTE: lossSum and loss is computed using the weights from the previous iteration* and regVal is the regularization value computed in the previous iteration as well.*/var state = states.next()while(states.hasNext) {lossHistory.append(state.value)state = states.next()}lossHistory.append(state.value)val weights = Vectors.fromBreeze(state.x)logInfo("LBFGS.runLBFGS finished. Last 10 losses %s".format(lossHistory.takeRight(10).mkString(", ")))(weights, lossHistory.toArray)}
costFun函数是算法实现中的重点
private class CostFun(data: RDD[(Double, Vector)],gradient: Gradient,updater: Updater,regParam: Double,numExamples: Long) extends DiffFunction[BDV[Double]] {private var i = 0override def calculate(weights: BDV[Double]) = {// Have a local copy to avoid the serialization of CostFun object which is not serializable.val localData = dataval localGradient = gradientval (gradientSum, lossSum) = localData.aggregate((BDV.zeros[Double](weights.size), 0.0))(seqOp = (c, v) => (c, v) match { case ((grad, loss), (label, features)) =>val l = localGradient.compute(features, label, Vectors.fromBreeze(weights), Vectors.fromBreeze(grad))(grad, loss + l)},combOp = (c1, c2) => (c1, c2) match { case ((grad1, loss1), (grad2, loss2)) =>(grad1 += grad2, loss1 + loss2)})/*** regVal is sum of weight squares if it's L2 updater;* for other updater, the same logic is followed.*/val regVal = updater.compute(Vectors.fromBreeze(weights),Vectors.dense(new Array[Double](weights.size)), 0, 1, regParam)._2val loss = lossSum / numExamples + regVal/*** It will return the gradient part of regularization using updater.** Given the input parameters, the updater basically does the following,** w' = w - thisIterStepSize * (gradient + regGradient(w))* Note that regGradient is function of w** If we set gradient = 0, thisIterStepSize = 1, then** regGradient(w) = w - w'** TODO: We need to clean it up by separating the logic of regularization out* from updater to regularizer.*/// The following gradientTotal is actually the regularization part of gradient.// Will add the gradientSum computed from the data with weights in the next step.val gradientTotal = weights - updater.compute(Vectors.fromBreeze(weights),Vectors.dense(new Array[Double](weights.size)), 1, 1, regParam)._1.toBreeze// gradientTotal = gradientSum / numExamples + gradientTotalaxpy(1.0 / numExamples, gradientSum, gradientTotal)i += 1(loss, gradientTotal)}}}
Apache Spark源码走读之23 -- Spark MLLib中拟牛顿法L-BFGS的源码实现的更多相关文章
- Apache Spark源码走读之16 -- spark repl实现详解
欢迎转载,转载请注明出处,徽沪一郎. 概要 之所以对spark shell的内部实现产生兴趣全部缘于好奇代码的编译加载过程,scala是需要编译才能执行的语言,但提供的scala repl可以实现代码 ...
- Apache Spark源码走读之9 -- Spark源码编译
欢迎转载,转载请注明出处,徽沪一郎. 概要 本来源码编译没有什么可说的,对于java项目来说,只要会点maven或ant的简单命令,依葫芦画瓢,一下子就ok了.但到了Spark上面,事情似乎不这么简单 ...
- Apache Spark源码走读之8 -- Spark on Yarn
欢迎转载,转载请注明出处,徽沪一郎. 概要 Hadoop2中的Yarn是一个分布式计算资源的管理平台,由于其有极好的模型抽象,非常有可能成为分布式计算资源管理的事实标准.其主要职责将是分布式计算集群的 ...
- Apache Spark源码走读之1 -- Spark论文阅读笔记
欢迎转载,转载请注明出处,徽沪一郎. 楔子 源码阅读是一件非常容易的事,也是一件非常难的事.容易的是代码就在那里,一打开就可以看到.难的是要通过代码明白作者当初为什么要这样设计,设计之初要解决的主要问 ...
- twitter storm源码走读之4 -- worker进程中线程的分类及用途
欢迎转载,转载请注明出版,徽沪一郎. 本文重点分析storm的worker进程在正常启动之后有哪些类型的线程,针对每种类型的线程,剖析其用途及消息的接收与发送流程. 概述 worker进程启动过程中最 ...
- Apache Spark源码走读之7 -- Standalone部署方式分析
欢迎转载,转载请注明出处,徽沪一郎. 楔子 在Spark源码走读系列之2中曾经提到Spark能以Standalone的方式来运行cluster,但没有对Application的提交与具体运行流程做详细 ...
- Apache Spark源码走读之13 -- hiveql on spark实现详解
欢迎转载,转载请注明出处,徽沪一郎 概要 在新近发布的spark 1.0中新加了sql的模块,更为引人注意的是对hive中的hiveql也提供了良好的支持,作为一个源码分析控,了解一下spark是如何 ...
- Apache Spark源码走读之22 -- 浅谈mllib中线性回归的算法实现
欢迎转载,转载请注明出处,徽沪一郎. 概要 本文简要描述线性回归算法在Spark MLLib中的具体实现,涉及线性回归算法本身及线性回归并行处理的理论基础,然后对代码实现部分进行走读. 线性回归模型 ...
- Apache Spark源码走读之15 -- Standalone部署模式下的容错性分析
欢迎转载,转载请注明出处,徽沪一郎. 概要 本文就standalone部署方式下的容错性问题做比较细致的分析,主要回答standalone部署方式下的包含哪些主要节点,当某一类节点出现问题时,系统是如 ...
随机推荐
- jQuery-插件,优化
jQuery应用: 1.表单验证: A:jQuery Validation插件:有时需要将验证的属性写在class中,有时需要将验证信息写在属性中,例如: <input id="cem ...
- 简单的css 菜单
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/ ...
- ccc let
let,其实就是块级作用域申明变量的var.之前JS的var关键字是非块级作用域的,而是函数级的. 例如arr=[0,1,2],我们经常写循环 for(var i=0,len=arr.length; ...
- Codeforces Round #353 (Div. 2)Restoring Painting
Vasya works as a watchman in the gallery. Unfortunately, one of the most expensive paintings was sto ...
- <fieldset>
legend{text-align:center;} <fieldset> <legend>爱好<legend>(为fieldset定义标题) <input ...
- ACM 谁获得了最高奖学金
谁获得了最高奖学金 时间限制:1000 ms | 内存限制:65535 KB 难度:2 描述 某校的惯例是在每学期的期末考试之后发放奖学金.发放的奖学金共有五种,获取的条件各自不同: ...
- 关于CCSprite不能及时显示的问题
今天在利用AFNetworking做网络请求时总是能看到添加的CCSprite精灵总是延迟一会才显示,google了半天没有找到答案, 考虑到CCSprite要被渲染才能显示,于是直接在场景中的CCL ...
- 【hdu】p1754I Hate It
I Hate It Time Limit: 9000/3000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Others)Total S ...
- iOS 开发小结
一,经历 1> 在编写以前有过的类似的新功能时,如果以前的开发人员没有写明明确的注释和开发需求,一定要仔细阅读所有代码,每一句代码都有它存在的意义. 2> 例如,只以为是[self.ful ...
- js小效果-双色球
<!DOCTYPE html><html><head lang="en"> <meta charset="UTF-8" ...