Java集合---ConcurrentHashMap原理分析
一、背景:
线程不安全的HashMap
效率低下的HashTable容器
锁分段技术
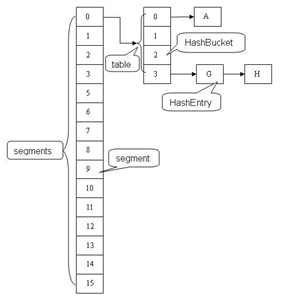
二、应用场景
三、源码解读
/**
* The segments, each of which is a specialized hash table
*/
final Segment<K,V>[] segments;
不变(Immutable)和易变(Volatile)
static final class HashEntry<K,V> {
final K key;
final int hash;
volatile V value;
final HashEntry<K,V> next;
}
其它
定位操作:
final Segment<K,V> segmentFor(int hash) {
return segments[(hash >>> segmentShift) & segmentMask];
}
final Segment<K,V> segmentFor(int hash) {
return segments[(hash >>> segmentShift) & segmentMask];
}
数据结构
static final class Segment<K,V> extends ReentrantLock implements Serializable {
/**
* The number of elements in this segment's region.
*/
transient volatileint count;
/**
* Number of updates that alter the size of the table. This is
* used during bulk-read methods to make sure they see a
* consistent snapshot: If modCounts change during a traversal
* of segments computing size or checking containsValue, then
* we might have an inconsistent view of state so (usually)
* must retry.
*/
transient int modCount;
/**
* The table is rehashed when its size exceeds this threshold.
* (The value of this field is always <tt>(int)(capacity *
* loadFactor)</tt>.)
*/
transient int threshold;
/**
* The per-segment table.
*/
transient volatile HashEntry<K,V>[] table;
/**
* The load factor for the hash table. Even though this value
* is same for all segments, it is replicated to avoid needing
* links to outer object.
* @serial
*/
final float loadFactor;
}
删除操作remove(key)
public V remove(Object key) {
hash = hash(key.hashCode());
return segmentFor(hash).remove(key, hash, null);
}
V remove(Object key, int hash, Object value) {
lock();
try {
int c = count - 1;
HashEntry<K,V>[] tab = table;
int index = hash & (tab.length - 1);
HashEntry<K,V> first = tab[index];
HashEntry<K,V> e = first;
while (e != null && (e.hash != hash || !key.equals(e.key)))
e = e.next;
V oldValue = null;
if (e != null) {
V v = e.value;
if (value == null || value.equals(v)) {
oldValue = v;
// All entries following removed node can stay
// in list, but all preceding ones need to be
// cloned.
++modCount;
HashEntry<K,V> newFirst = e.next;
*for (HashEntry<K,V> p = first; p != e; p = p.next)
*newFirst = new HashEntry<K,V>(p.key, p.hash,
newFirst, p.value);
tab[index] = newFirst;
count = c; // write-volatile
}
}
return oldValue;
} finally {
unlock();
}
}


get操作
V get(Object key, int hash) {
if (count != 0) { // read-volatile 当前桶的数据个数是否为0
HashEntry<K,V> e = getFirst(hash); 得到头节点
while (e != null) {
if (e.hash == hash && key.equals(e.key)) {
V v = e.value;
if (v != null)
return v;
return readValueUnderLock(e); // recheck
}
e = e.next;
}
}
returnnull;
}
V readValueUnderLock(HashEntry<K,V> e) {
lock();
try {
return e.value;
} finally {
unlock();
}
}
put操作
V put(K key, int hash, V value, boolean onlyIfAbsent) {
lock();
try {
int c = count;
if (c++ > threshold) // ensure capacity
rehash();
HashEntry<K,V>[] tab = table;
int index = hash & (tab.length - 1);
HashEntry<K,V> first = tab[index];
HashEntry<K,V> e = first;
while (e != null && (e.hash != hash || !key.equals(e.key)))
e = e.next;
V oldValue;
if (e != null) {
oldValue = e.value;
if (!onlyIfAbsent)
e.value = value;
}
else {
oldValue = null;
++modCount;
tab[index] = new HashEntry<K,V>(key, hash, first, value);
count = c; // write-volatile
}
return oldValue;
} finally {
unlock();
}
}
- 是否需要扩容。在插入元素前会先判断Segment里的HashEntry数组是否超过容量(threshold),如果超过阀值,数组进行扩容。值得一提的是,Segment的扩容判断比HashMap更恰当,因为HashMap是在插入元素后判断元素是否已经到达容量的,如果到达了就进行扩容,但是很有可能扩容之后没有新元素插入,这时HashMap就进行了一次无效的扩容。
- 如何扩容。扩容的时候首先会创建一个两倍于原容量的数组,然后将原数组里的元素进行再hash后插入到新的数组里。为了高效ConcurrentHashMap不会对整个容器进行扩容,而只对某个segment进行扩容。
boolean containsKey(Object key, int hash) {
if (count != 0) { // read-volatile
HashEntry<K,V> e = getFirst(hash);
while (e != null) {
if (e.hash == hash && key.equals(e.key))
returntrue;
e = e.next;
}
}
returnfalse;
}
size()操作
参考:
Java集合---ConcurrentHashMap原理分析的更多相关文章
- Java 中 ConcurrentHashMap 原理分析
一.Java并发基础 当一个对象或变量可以被多个线程共享的时候,就有可能使得程序的逻辑出现问题. 在一个对象中有一个变量i=0,有两个线程A,B都想对i加1,这个时候便有问题显现出来,关键就是对i加1 ...
- ConcurrentHashMap原理分析(1.7与1.8)-put和 get 需要执行两次Hash
ConcurrentHashMap 与HashMap和Hashtable 最大的不同在于:put和 get 两次Hash到达指定的HashEntry,第一次hash到达Segment,第二次到达Seg ...
- Java 集合源码分析(一)HashMap
目录 Java 集合源码分析(一)HashMap 1. 概要 2. JDK 7 的 HashMap 3. JDK 1.8 的 HashMap 4. Hashtable 5. JDK 1.7 的 Con ...
- java集合源码分析(三):ArrayList
概述 在前文:java集合源码分析(二):List与AbstractList 和 java集合源码分析(一):Collection 与 AbstractCollection 中,我们大致了解了从 Co ...
- java集合源码分析(六):HashMap
概述 HashMap 是 Map 接口下一个线程不安全的,基于哈希表的实现类.由于他解决哈希冲突的方式是分离链表法,也就是拉链法,因此他的数据结构是数组+链表,在 JDK8 以后,当哈希冲突严重时,H ...
- Java Reference核心原理分析
本文转载自Java Reference核心原理分析 导语 带着问题,看源码针对性会更强一点.印象会更深刻.并且效果也会更好.所以我先卖个关子,提两个问题(没准下次跳槽时就被问到). 我们可以用Byte ...
- Java 线程池原理分析
1.简介 线程池可以简单看做是一组线程的集合,通过使用线程池,我们可以方便的复用线程,避免了频繁创建和销毁线程所带来的开销.在应用上,线程池可应用在后端相关服务中.比如 Web 服务器,数据库服务器等 ...
- Java集合源码分析(四)Vector<E>
Vector<E>简介 Vector也是基于数组实现的,是一个动态数组,其容量能自动增长. Vector是JDK1.0引入了,它的很多实现方法都加入了同步语句,因此是线程安全的(其实也只是 ...
- Java集合源码分析(三)LinkedList
LinkedList简介 LinkedList是基于双向循环链表(从源码中可以很容易看出)实现的,除了可以当做链表来操作外,它还可以当做栈.队列和双端队列来使用. LinkedList同样是非线程安全 ...
随机推荐
- CMS模板应用调研问卷
截止目前,已经有数十家网站与我们合作,进行了MIP化改造,在搜索结果页也能看到"闪电标"的出现.除了改造方面的问题,MIP项目组被问到最多的就是:我用了wordpress,我用了织 ...
- 隐私泄露杀手锏 —— Flash 权限反射
[简版:http://weibo.com/p/1001603881940380956046] 前言 一直以为该风险早已被重视,但最近无意中发现,仍有不少网站存在该缺陷,其中不乏一些常用的邮箱.社交网站 ...
- AutoMapper
什么是AutoMapper? AutoMapper是一个对象和对象间的映射器.对象与对象的映射是通过转变一种类型的输入对象为一种不同类型的输出对象工作的.让AutoMapper有意思的地方在于它提供了 ...
- Expression Blend创建自定义按钮
在 Expression Blend 中,我们可以在美工板上绘制形状.路径和控件,然后修改其外观和行为,从而直观地设计应用程序.Button按钮也是Expression Blend最常用的控件之一,在 ...
- 【NLP】前戏:一起走进条件随机场(一)
前戏:一起走进条件随机场 作者:白宁超 2016年8月2日13:59:46 [摘要]:条件随机场用于序列标注,数据分割等自然语言处理中,表现出很好的效果.在中文分词.中文人名识别和歧义消解等任务中都有 ...
- 玩转spring boot——MVC应用
如何快速搭建一个MCV程序? 参照spring官方例子:https://spring.io/guides/gs/serving-web-content/ 一.spring mvc结合thymeleaf ...
- C# 对象实例化 用json保存 泛型类 可以很方便的保存程序设置
参考页面: http://www.yuanjiaocheng.net/webapi/test-webapi.html http://www.yuanjiaocheng.net/webapi/web-a ...
- Yeoman 学习笔记
yoeman 简介:http://www.infoq.com/cn/news/2012/09/yeoman yeoman 官网: http://yeoman.io/ yeoman 是快速创建骨架应用程 ...
- Xamarin和微软发起.NET基金会
新闻<微软宣布成立.NET基金会全面支持开源项目 包括C#编译器Roslyn>,看到大家对微软的开放都很兴奋.在此之前在.NET社区也有了大量的开源项目,所列的24个项目也是早就开源,这次 ...
- ASP.NET MVC 视图(三)
ASP.NET MVC 视图(三) 前言 上篇对于Razor视图引擎和视图的类型做了大概的讲解,想必大家对视图的本身也有所了解,本篇将利用IoC框架对视图的实现进行依赖注入,在此过程过会让大家更了解的 ...