MapReduce编程job概念原理
在Hadoop中,每个MapReduce任务都被初始化为一个job,每个job又可分为两个阶段:map阶段和reduce阶段。这两个阶段分别用两个函数来表示。Map函数接收一个<key,value>形式的输入,然后同样产生一个<ey,value>形式的中间输出,Hadoop会负责将所有具有相同中间key值的value集合在一起传递给reduce函数,reduce函数接收一个如<key,(list of values)>形式的输入,然后对这个value集合进行处理,每个reduce产生0或1个输出,reduce的输出也是<key,value>形式。

简易代码:
public static class Map extends MapReduceBase implments Mapper<LongWritable,Text,Text,IntWritable>{
//设置常量1,用来形成<word,1>形式的输出
private fianll static IntWritable one = new IntWritable(1)
private Text word = new Text();
public void map(LongWritable key,Text value,OutputCollector<Text,output,Reporter reporter) throws IOException{
//hadoop执行map函数时为是一行一行的读取数据处理,有多少行,就会执行多少次map函数
String line = value.toString();
//进行单词的分割,可以多传入进行分割的参数
StringTokenizer tokenizer = new StringTokenizer(line);
//遍历单词
while(tokenizer.hasMoreTokens()){
//往Text中写入<word,1>
word.set(tokenizer.nextToken());
output.collect(word,one);
}
}
}
//需要注意的是,reduce将相同key值(这里是word)的value值收集起来,形成<word,list of 1>的形式,再将这些1累加
public static class Reduce extends MapReduceBase implements Reducer<Text IntWritable,Text,IntWritable>{
public void reduce(Text key,Iterator<IntWritable> values,OutputCollector<Text,IntWritable> output,Reporter reporter) throws IOException{
//初始word个数设置
int sum = 0;
while(values,hasNext()){
//单词个数相加
sum += value.next().get();
}
output.collect(key,new IntWritbale(sum));
}
}
执行概念总结:
job.setInputFormatClass(TextInputFormat.class);
1.InputFormat()和inputSplit
inputSplit是Hadoop定义的用来传送给每个单独的map的数据,InputSplit存储的并非数据本身,而是一个分片长度和一个记录数据位置的数组,生成InputSplit的方法可以通过InputFormat(I)来设置。当数据传送给map时,map会将输入分片传送到inputFormat上,InputFormat则调用getREcordReduer()方法生成RecordReader,RecordReader再通过createKey()、createValue()方法创建可供map处理的<key,value>对,即<k1,v1>,简而言之InputFormat方法是用来生成可供map处理的<key,value>对的。
在这里如果不设置的话,TextInputFormat会是Hadoop默认的输入方法,在TextInputFormat中,每个人间(或其一部分)都会单独地作为map的输入,继承自FileInputFormat,之后,每行数据都会生成一条记录,每条记录则表示成<key,value>形式:
其中,key值是每个数据的记录在数据分片中的字节偏移量,数据类型是LongWritable.
value值是每行的内容,数据类型是Text。
job.setOutputValueClass(TextInputFormat.class);
2、OutputFormat
每一种输入格式都有一种输出格式与其对应。同样,默认的输出格式是TextOutputFormat,这种输出方式与输入类似,会将每条记录以一行的形式存入文本文件。不过它的键和值都可以以任意形式的,因为程序内部会调用toString()方法将键和值转换为String类型再输出。
3、map和reduce
map函数接收经过inputFormat处理产生的<k1,v1>,然后输出<k2,v2>,map函数老的版本写法是继承MapReduceBase然后实现Mapper接口,但是现在可以直接继承Mapper接口,此接口是一个泛型类型,有4种形式的参数,分别用来指定map的输入key值类型(LongWritable key),输入value值类型(Text value)、输出key值类型和(Text)输出value值类型(IntWritable,本例是reporter)。
reduce函数以map的输出作为输入,因此reduce的输入类型是<Text,IntWritable>.而reduce的输出是单词和它的数目,因此,它的输出类型是<Text,IntWritable>
4、任务调度
计算方面:Hadoop总会有限将任务分配给空闲的机器,使所有的任务能公平地分享系统资源,I/O方面:Hadoop会尽量将map任务分配给InputSplit所在机器,以减少网络I/O的消耗。
5、数据预处理与InputSplit的大小。
Hadoop会在处理每个block后将其作为一个InputSplit,因此合理地甚至block块大小是很重要的。也可通过合理地设置map任务的数量来调节map任务的数据输入。
6、map和reduce任务的数量
设置map任务槽和reduce任务槽,map/reduce任务槽是这个集群能够同时运行的map/reduce任务的最大数量。可以通过hadoop的配置文件设置每台机器最多可以同时运行map任务和reduce任务的个数,比如有10台机器,设置每台最多可以同时运行10个map任务和5个reduce任务,那么这个集群的map任务槽就是1000,reduce任务槽就是500.一般来说,设置的reduce任务数量应该是reduce任务槽的0.95或是1.75倍
7、combine函数
combine函数是用于在本地合并数据的函数,从wordcount程序中,词频是一个接近于zipf分布的,每个map任务可能会产生成千上万个<the,i>记录,若将这些记录一一传给reduce任务是很耗时的,所以可以设置一个combine函数,用于本地合并,大大减少网络I/O操作的消耗。
job.setCombinerClass(combine.class);
//指定reduce函数为combine函数
job.setReducerClass(Reduce.class);
8、Hadoop流的工作原理
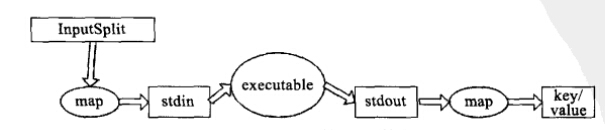
当一个可执行文件作为Mapper时,每个map任务会以一个独立的进程启动这个可执行文件,然后在map任务运行时,会把输入切分成行提供给可执行文件,并作为它的标准输入(stdin)内容。当可执行文件运行处结果时,map从标准输出(stdout)中手机数据,并将其转化为<key,value>对,作为map的输出。
参考:<Hadoop实战>
MapReduce编程job概念原理的更多相关文章
- 暴力破解MD5的实现(MapReduce编程)
本文主要介绍MapReduce编程模型的原理和基于Hadoop的MD5暴力破解思路. 一.MapReduce的基本原理 Hadoop作为一个分布式架构的实现方案,它的核心思想包括以下几个方面:HDFS ...
- MapReduce/Hbase进阶提升(原理剖析、实战演练)
什么是MapReduce? MapReduce是一种编程模型,用于大规模数据集(大于1TB)的并行运算.概念"Map(映射)"和"Reduce(归约)",和他们 ...
- MapReduce API 基本概念
在正式分析新旧 API 之前, 先要介绍几个基本概念. 这些概念贯穿于所有 API 之中,因此, 有必要单独讲解. 1.序列化 序列化是指将结构化对象转为字节流以便于通过网络进行传输或写入持久存储的过 ...
- 批处理引擎MapReduce编程模型
批处理引擎MapReduce编程模型 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. MapReduce是一个经典的分布式批处理计算引擎,被广泛应用于搜索引擎索引构建,大规模数据处理 ...
- [Hadoop入门] - 1 Ubuntu系统 Hadoop介绍 MapReduce编程思想
Ubuntu系统 (我用到版本号是140.4) ubuntu系统是一个以桌面应用为主的Linux操作系统,Ubuntu基于Debian发行版和GNOME桌面环境.Ubuntu的目标在于为一般用户提供一 ...
- 初步掌握MapReduce的架构及原理
目录 1.MapReduce定义 2.MapReduce来源 3.MapReduce特点 4.MapReduce实例 5.MapReduce编程模型 6.MapReduce 内部逻辑 7.MapRed ...
- 指导手册05:MapReduce编程入门
指导手册05:MapReduce编程入门 Part 1:使用Eclipse创建MapReduce工程 操作系统: Centos 6.8, hadoop 2.6.4 情景描述: 因为Hadoop本身 ...
- MapReduce编程解析
MapReduce编程模型之案例 wordcount 输入数据 atguigu atguiguss sscls clsjiaobanzhangxuehadoop 输出数据 atguigu 2banzh ...
- MapReduce编程基础
MapReduce编程基础 1. WordCount示例及MapReduce程序框架 2. MapReduce程序执行流程 3. 深入学习MapReduce编程(1) 4. 参考资料及代码下载 & ...
随机推荐
- junit高级篇(参数化、打包测试)-实例代码
工程目录: 参数化测试,SquareTest.java: import static org.junit.Assert.*; import java.util.Arrays; import java. ...
- opencv中的.at方法
opencv中的.at方法是用来获取图像像素值得函数: interpolation:差值 histogram:直方图
- PDF 补丁丁 0.4.2.905 测试版发布:智能合并功能减小合并文件的大小
之前的测试版在合并文件功能处添加两个相同的PDF文件,程序会重复写入该文件的内容,导致文件体积膨胀,浪费存储空间. 例如:使用者需要在原 PDF 文件(设文件为1.pdf)第2和第3页中间插入几张图片 ...
- Positive-definite kernel
Definition Let be a sequence of (complex) Hilbert spaces and be the bounded operators from Hi to Hj. ...
- volatile简介
volatile简介 java语言提供了一种稍弱的内存同步机制,即volatile变量.用来确保将变量的更新操作通知到其它线程,保证了新值能立即同步到主内存,以及每次使用前立即从内存刷新.当变量声明为 ...
- C# .net windows服务启动多个服务 ServiceBase
在windows服务中想要启动多个服务 ServiceBase[] ServicesToRun; ServicesToRun = new ServiceBase[] { // new SyncServ ...
- CSS总结 最后的选择符和字体、元素常见样式
在伪类选择符中,还有很多,其中比较有意思的是E:target 当我们想做出点击超链接后链接变色且其他链接变回原来的颜色时,就可以用到这个选择符 <a href="#a1" i ...
- SqlServer性能优化:创建性能监视器(二)
添加三个选项: 下一步就可以了 Sql跟踪的模板: 跟踪Sql 语句的执行情况: 使用刚才的新建的模板: 用到的Sql语句: select * from [Sales].[SalesOrderDeta ...
- jsp连接mysql数据库
1.新建一个Java web项目. 2.导入mysql驱动包.(这个跟上一篇写的Java连接mysql类似) 3.编写测试代码 <%@ page contentType="text/h ...
- M6: 使用摄像头(CameraCaptureUI)
本小节介绍UWP中摄像头的使用,使用CameraCaptureUI来拍照,不仅能够获得图像,还能够对图像进行剪裁 (目前Mobile设备还上不支持). 在本例中, 单击Camera按钮调用摄像头来拍摄 ...