Zenlayer如何将万台设备监控从Zabbix迁移到Flashcat
作为全球首家以超连接为核心的云服务商,Zenlayer 致力于将云计算、内容服务和边缘技术融合,为客户提供全面的解决方案。通过构建可靠的网络架构和高效的数据传输,Zenlayer 帮助客户实现更快速、更可靠的连接,提升用户体验和业务效率。Zenlayer 在全球范围内运营着超过 290 个边缘节点, 骨干网带宽超过 50Tbps, 10000+ 的数据中心接入点,快速连接全球公有云与数据中心。
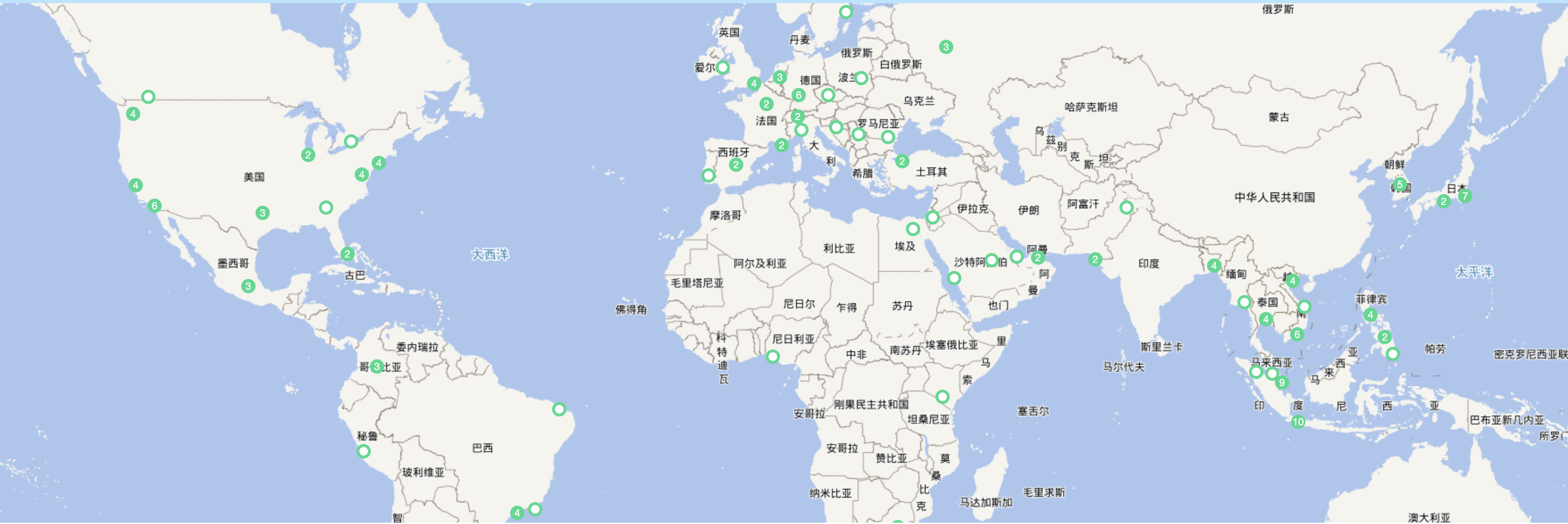
监控现状
Zenlayer 运营着全球数百个边缘机房和庞大的骨干网网络,我们的监控目标主要包括:
- 各种硬件设备,如交换机、裸金属
- 超大大规模网络的连通性和质量
- Kubernetes 云原生技术栈
在 Zenlayer,监控系统不仅仅是作为一个内部工具服务于运维和研发团队,我们的售后团队高度依赖监控系统为客户提供高水平的技术支持服务,监控系统是 Zenlayer 最重要的基础服务和产品之一,是我们交付用户价值的关键所在。
目前我们使用的监控工具有:Zabbix、Prometheus、夜莺 Nightingale、ClickHouse:
- 采用 Zabbix 监控各种网络设备,将全球各个边缘节点的监控数据,汇聚到中心统一处理。
- 采用 Prometheus 收集 Zenlayer 的云原生技术栈的监控数据,统一使用夜莺 Nightingale 来配置和管理告警规则。
- 使用 ClickHouse 对系统日志进行分析。
痛点和挑战
考虑到 Zenlayer 的设备数量(近万台网络设备)、设备种类、全球化布局,Zabbix 逐渐接近性能瓶颈:
- 海量数据的查询、看图、报警,对 Zabbix 数据库有很大的写入和查询压力,且无法有效扩展。
- 全球的监控数据汇总一处,会有频繁的监控数据中断、时延等问题,影响报警的及时性和准确性。
- 对网络专线强依赖,若专线发生异常,会导致相应边缘节点的监控报警完全不可用,产生监控盲区。
- 数据合规性要求,某些边缘节点的数据不允许汇聚到中心,目前的架构难以有效应对。
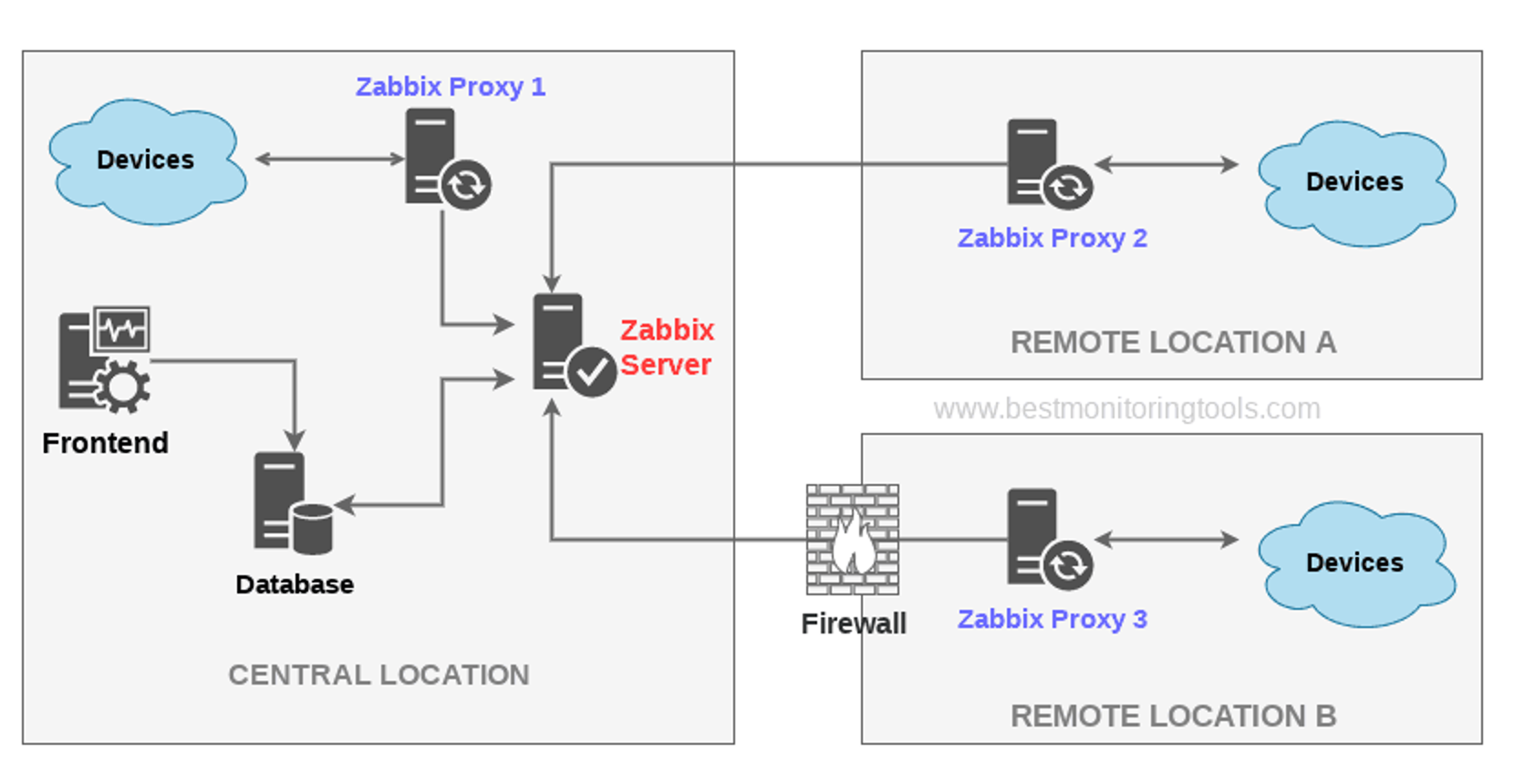
鉴于我们在 Zabbix 之外,也用到了另外多种监控工具:
- 工具多,体验不一致,技术团队学习成本很高。
- 数据孤岛现象严重,关联分析成本高,效率低(比如 Zabbix 、Prometheus、夜莺之间的数据难以有效串联)。
- 日志分析的能力较为不足,比如缺少高效便捷的日志报警等功能。
我们迫切需要对现有的监控方案做出改进,以支撑不断增长的业务、适应不断变化的用户需求,提供可持续的服务能力,具体而言,有以下三个目标:
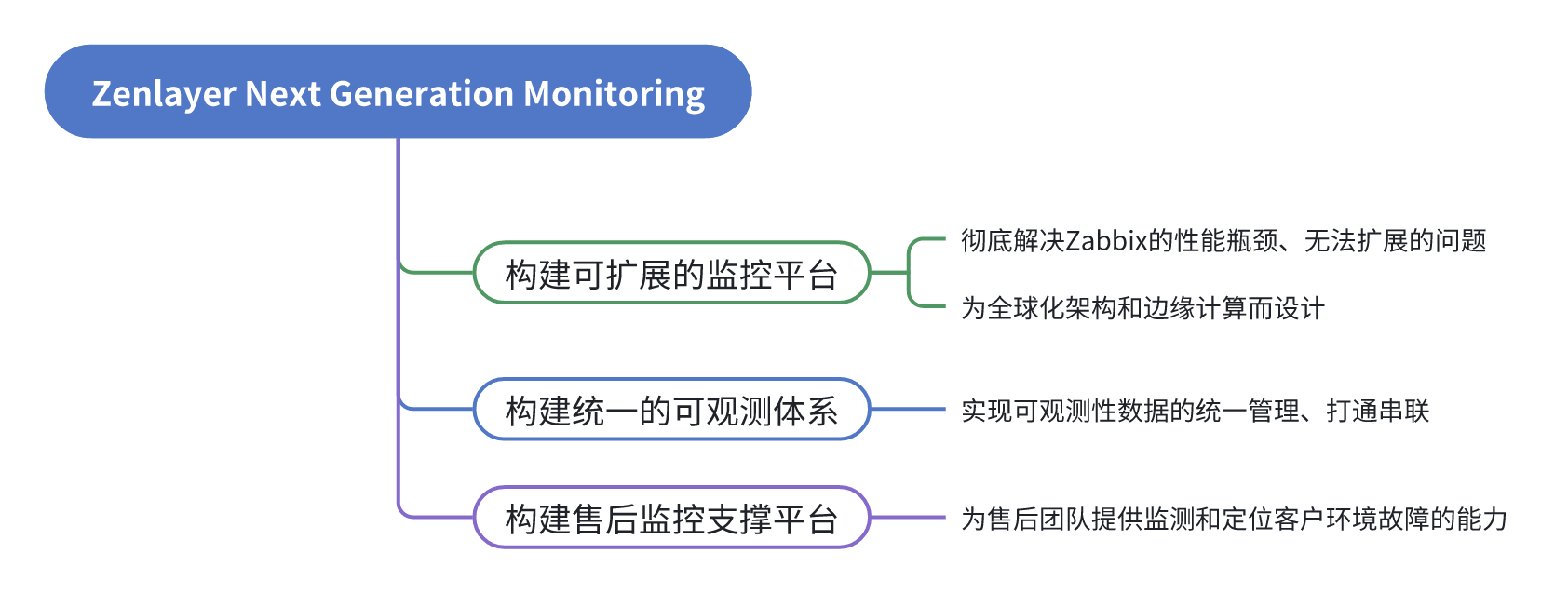
解决方案
Zenlayer 技术团队在调研技术方案的时候,关注到了快猫星云的 Flashcat 平台。使用 Flashcat,可以在一个平台上完成指标、日志、链路追踪数据的统一采集、可视化、告警、分析和 OnCall, 免去搭建和维护多套 Prometheus/Zabbix/Grafana/ELK/Jaeger 的工作量,屏蔽多云监控的复杂度。Flashcat 平台的定位和特点,与 Zenlayer 新一代监控方案的设计目标极为吻合:
- 水平扩展的架构,高性能高可用,有上千家企业使用,经受了严苛的生产实践检验。
- 支持边缘节点部署模式,可以在中心端高效、便捷的监控众多边缘节点,契合 Zenlayer 边缘计算的业务特点。
- 内置了故障处理的最佳实践,当业务受损时,Flashcat 能第一时间发现,并辅助技术团队快速展开调查,特别适合我们构建售后监控支撑平台的目标。
- 支持物理机、网络设备、容器、K8s,微服务、主流云产品,完全覆盖我们的监控场景。
Zenlayer 与快猫星云技术专家一起,重点从全球化架构、边缘计算、网络监控、Zabbix 替代等方面出发,根据 Zenlayer 自身的业务特点,结合快猫星云在统一监控和稳定性保障方向的最佳实践,构建起了「Zenlayer新一代的统一监控方案」,最终也实现了对 Zabbix 的完美替代,解除了困扰已久的难题。
落地效果
边缘部署模式
首先,我们测试了 Flashcat 的边缘节点部署模式,将 Zenlayer 全球划分为 7 大 Region,其中以 HK 为中心 Region,其余为边缘端,我们采用了如下部署架构:
- 在每个边缘端,本地保存监控数据,即使网络中断,本地仍然能够闭环工作,独立告警。
- 中心端进行告警规则、仪表盘、数据采集策略的集中式管理、集中查询,降低多 region 运维成本,用户只需要面对 Flashcat 中心端。
- 中心端、边缘端均采用集群方式部署,可横向扩展,以满足本区域不断增长的监控需求。
- 当前主要采集存储 Metrics 指标,接下来可在边缘机房部署日志组件,不适合传输到中心端的数据,可以本地化处理。
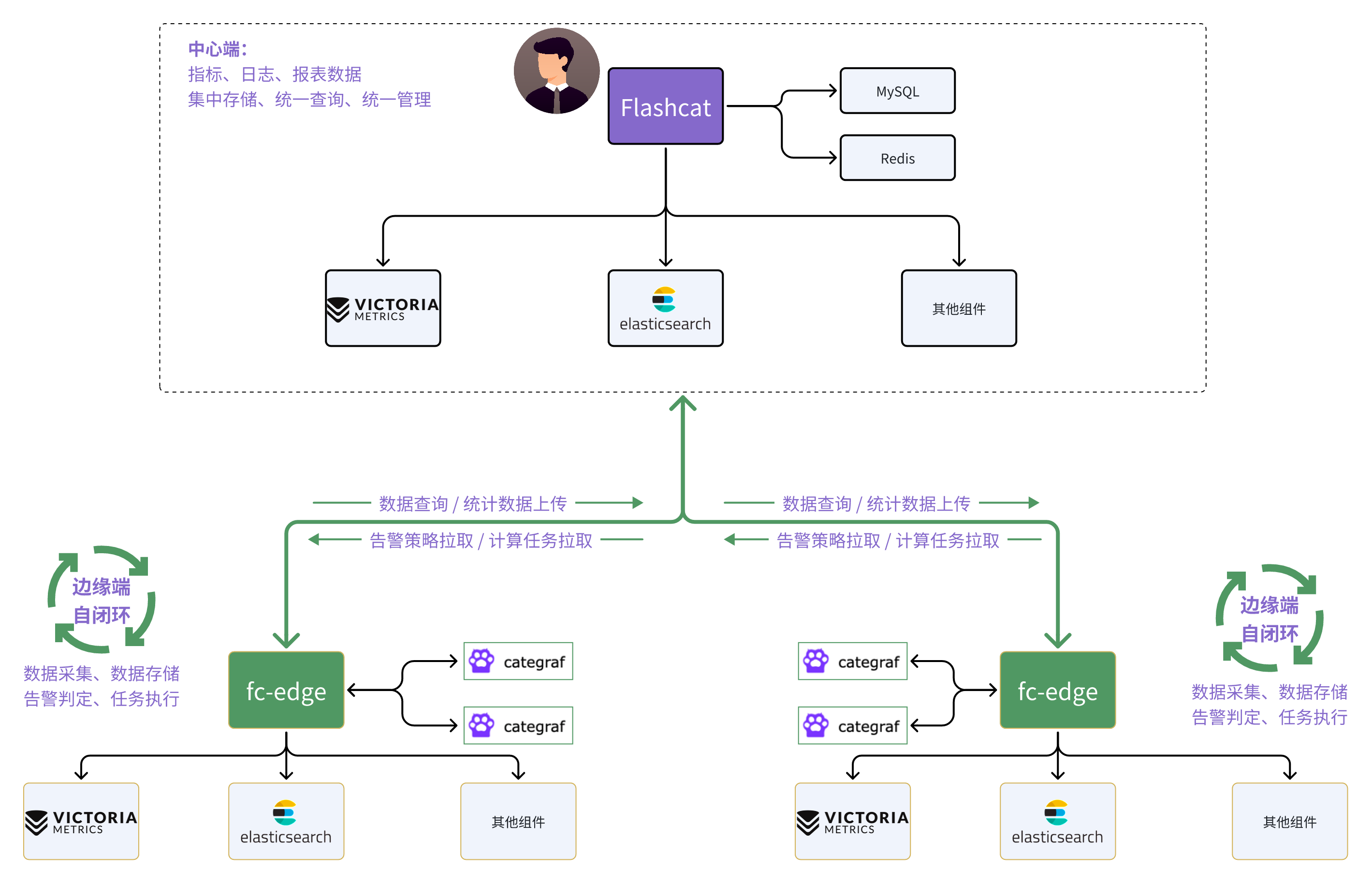
利用 Flashcat 的边缘部署模式,有效的解决了 Zenlayer 全球节点监控数据汇聚带来的问题,提升了监控数据的时效性、可靠性,降低了监控数据汇聚带来的网络传输成本,同时还减轻了整个监控系统的维护和配置成本。
Zabbix 替换
在 Zenlayer,我们深度使用 Zabbix,特别的,我们本质上是一家网络公司,背后有近万台各种型号的网络设备,分布在全球范围内,所以重度依赖 Zabbix 对网络设备的数据采集和报警能力,比如:
- Zabbix 对网络设备的自动发现能力
- Zabbix 对各种网络设备SNMP采集的配置模板
- Zabbix 采集所支持的设备型号更全面
- Zabbix 报警中的宏模式
- …
此外,我们的技术团队对于 Zabbix 使用时间久,如果迁移到新的工具有一定的迁移成本。带着以上的问题出发,我们对 Flashcat 进行了细致的测试,发现 Flashcat 对 Zabbix 能力的兼容性非常不错,以网络设备的监控数据采集为例,介绍如下。
网络设备采集配置模板化
Flashcat 针对特定型号的网络设备,支持用户将采集该设备 Metrics 的 SNMP 配置,以模板的形式在 WebUI 上管理和配置,然后下发给指定的采集器 Categraf。比如:
通过SNMP采集华为某型号交换机 uptime 和 sysname 指标的采集模板
oid = "RFC1213-MIB::sysUpTime.0"
name = "uptime"
[[instances.field]]
oid = "RFC1213-MIB::sysName.0"
name = "sysname"
is_tag = true采集内存总量和使用量的采集模板
...
[[instances.field]]
oid = ".1.3.6.1.2.1.25.2.3.1.5.1"
name = "memsize"
[[instances.field]]
oid = ".1.3.6.1.2.1.25.2.3.1.6.1"
name = "memuse"
...Zabbix 用户,尤其是深度用户, 之前在 Zabbix 中已经积累了很多模板,这个模板如果按照 Flashcat 的格式去人工配置一遍也是一个很大的工作量。为了减轻这方面的工作量,Flashcat 支持将 Zabbix 的 XML 格式转换为 Flashcat 格式的采集模板,这样就可以加速从 Zabbix 采集模板往 Flashcat 采集模板迁移的过程。在测试中,我们和快猫星云的技术专家,在 Flashcat 中创建了30多种网络采集模板。
- Arista Device Status
- Juniper Device Status
- Juniper BGP
- Nokia Device Status
- Huawei BGP
- Arista BGP
- Ciena Optical
- Juniper Optical
- Ruijie Device Status
- Sintai Optical
- Ruijie Optical
- H3C Optical
- IDC Interface
- Network Status
- ...报警支持宏模式
宏变量是 Zabbix 中很强大的一个特性,告警阈值可以通过宏变量来设置,这样不同角色的设备就可以分别设置自己的阈值了。Flashcat 平台对宏变量也进行了支持。在测试中,我们从 Zabbix 中迁移了上百条告警规则到 Flashcat 中。
Pingmesh
Pingmesh 是一种用于测量和监控网络性能的技术,通过在一组通信对等体之间执行 Ping 测试来评估网络的可用性和延迟。Flashcat中的 Pingmesh 功能,提供了 TCP、UDP、ICMP 三种协议,在设备之间进行互相探测,并绘制各个层面的连通性视图,从全局视角观测整个网络的连通性,这对于我们的全球化布局特别有价值,能够帮助我们一目了然的看清楚不同的边缘节点之间、不同的机柜之间的网络连通质量。如果你想了解更多 Pingmesh 的技术细节,请查阅网络问题排查必备利器:Pingmesh。
SNMP采集支持多进制转化
在网络设备中,有些 OID 对应的值可能并不是数值,需要从 string 或者 hex-string 格式进行转换。比如,某些设备其 MAC 地址和 IP 地址都是以 hex-string 形式存储和展示的,如果直接采集,在 Flashcat 平台上展示的话会是乱码形式。下面的示例就是演示如何配置将 BGP 对端的 IP 地址作为 tag 附加到指标上的。如果指定conversion="hwaddr"则是进行 MAC 地址转换,指定conversion="float"则是将字符转为 float 类型,还支持转为 int、 hextoint 等。
[[instances.table.field]]
oid = ".1.3.6.1.4.1.2636.5.1.1.2.1.1.1.11"
name = "peer_addr"
conversion = "ipaddr"
is_tag = trueSNMP采集支持返回多值
绝大部分 OID 返回值都是单值的,只需要考虑将返回值转换为合适的格式即可。但是光模块功率是一个典型的多值返回,Flashcat 针对光模块采集做了扩展。比如下面这段配置是将返回值中4个部分分别对应rx_0_lane0 rx_0_lane1 rx_0_lane2 rx_0_lane3 这4个返回值,都按照 float 类型进行了转换。
[[instances.table.field]]
oid = ".1.3.6.1.4.1.2011.5.25.31.1.1.3.1.32"
name = "rx_0"
conversion="lane0:float,lane1:float,lane2:float,lane3:float"支持relabel/rename
比如 index 原始值如下, 想把这两个字段前3位1.1.4.和1.2.16.去掉,生成新标签 peer_addr
index="1.2.16.36.4.255.64.0.1.0.99.0.0.0.0.0.0.0.2"
index="1.1.4.103.140.146.151"增加如下配置即可:
[[instances.relabel_configs]]
source_labels = ["index"]
target_label = "peer_addr"
#separator = "/"
regex = "\\d+\\.\\d+\\.\\d+\\.(.*)"
action = "replace"
replacement = "$1"如果不想保留老的index label那么配置如下:
[[instances.relabel_configs]]
regex = "index"
action = "labeldrop"BGP监控数据采集
假设有两张表需要做关联 , 比如 BGP 中 peer_index 对应的 OID 是 .1.3.6.1.4.1.2636.5.1.1.2.1.1.1.1.14, 另一张 receive 表对应的 OID 是 .1.3.6.1.4.1.2636.5.1.1.2.6.2.1.7,想对两张表做关联,peer_index 表的 index 中第一位作为 receive 表的 index 的一部分。
先看peer_index的返回:
.1.3.6.1.4.1.2636.5.1.1.2.1.1.1.1.14.0.1.128.1.130.176.1.128.1.130.178 = 0
.1.3.6.1.4.1.2636.5.1.1.2.1.1.1.1.14.0.1.128.1.130.176.1.128.1.130.179 = 1
.1.3.6.1.4.1.2636.5.1.1.2.1.1.1.1.14.0.1.128.1.130.176.1.128.1.130.180 = 2
.1.3.6.1.4.1.2636.5.1.1.2.1.1.1.1.14.0.2.38.4.9.128.224.5.47.255.0.0.0.0.0.0.0.1.2.38.4.9.128.224.5.47.255.0.0.0.0.0.2 = 3
.1.3.6.1.4.1.2636.5.1.1.2.1.1.1.1.14.0.2.38.4.9.128.224.5.47.255.0.0.0.0.0.0.0.1.2.38.4.9.128.224.5.47.255.0.0.0.0.0.3 = 4
.1.3.6.1.4.1.2636.5.1.1.2.1.1.1.1.14.0.2.38.4.9.128.224.5.47.255.0.0.0.0.0.0.0.1.2.38.4.9.128.224.5.47.255.0.0.0.0.0.4 = 5再看receive表的返回:
.1.3.6.1.4.1.2636.5.1.1.2.6.2.1.7.0.1.1 = 2071
.1.3.6.1.4.1.2636.5.1.1.2.6.2.1.7.3.2.1 = 0这两张表关联查询,那就用 peer_index 对应的值 0/1/2/3/4/5 和 receive 表中的 index 0.1.1/3.2.1 关联匹配,但是因为他们长度不同(peer_index的值只有一位),所以长度对齐就用到了一个 oid_index_length 配置。 比如 oid_index_length=1 表示 receive 表的 index 的第一位只要匹配到 0/1/2/3/4/5 中任意一位就认为匹配成功。peer_index的配置如下:
[[instances.table.field]]
oid = ".1.3.6.1.4.1.2636.5.1.1.2.1.1.1.1.14"
name = "peer_index"
is_tag = true
secondary_index_table = true # 这个表的index对应的值要被其他表使用receive表配置如下:
[[instances.table.field]]
oid = ".1.3.6.1.4.1.2636.5.1.1.2.6.2.1.7"
name = "receive_total_prefix"
oid_index_length=1 # 只取关联index的第一位
secondary_index_use = true # 使用上面指定的index这样最终取到的指标,只有一个:
snmp_juniper_bgp_prefix_receive_total_prefix{index="0.1.128.1.130.176.1.128.1.130.178"} 2017从监控走向可观测
除过对 Zabbix 替换的需求,突破扩展性瓶颈限制等问题。Zenlayer 对于建立全面的可观测性体系,在过去的工作中,或多或少都有一些建设了,比如:
- 我们使用 ClickHouse 存储和分析日志,制作报表
- 我们使用 Prometheus 收集多套 K8s/K3s 云原生技术栈的数据,并使用夜莺 Nightingale 管理告警规则
- 我们构建了网络层面的立体化的监测
- 在某些特定场景下,我们借助智能监控提升效率,降低维护成本
- 我们使用 on-call 工具管理告警的全生命周期过程,提高告警的处理效率,降低工作失误
- …
客观讲,我们不缺少工具,也不是缺少数据,困扰我们的反而是工具太多了,数据太多了!更多的工具意味着更多的学习成本,面对更多的数据,如果缺乏高效的分析能力,数据只能是负担。我们在测试 Flashcat 的过程中,充分调研了 Flashcat 的多数据源接入功能,包括 Metrics 源、Logging 源、Tracing 源、事件源四大类。在对接数据源后,用户就可以在 Flashcat 平台上,对这些数据源背后的数据,进行集中的查询、可视化分析、告警等。并借助 Flashcat 的北极星和灭火图,我们构建起了面向业务场景、层层下钻的故障发现、定位体系。
比如,在故障发现层面,我们利用 Flashcat 提供的智能检测算法,对骨干网络流量进行实时监测,当流量出现异常波动,1分钟就可以被检测到,并发送我们的技术团队知晓和应急。
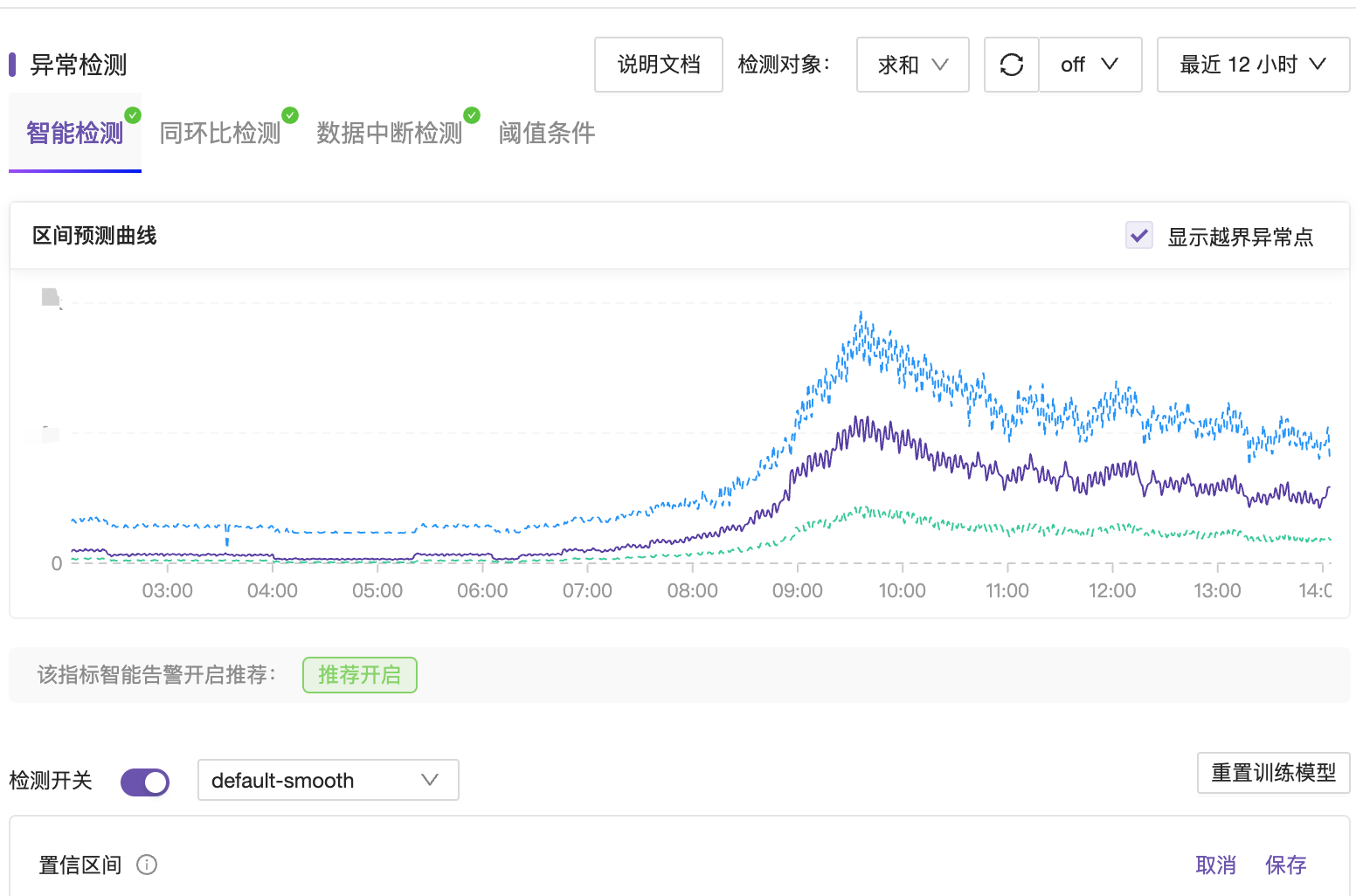
总结
Zenlayer 与快猫星云技术专家一起,重点从全球化架构、边缘计算、网络监控、Zabbix 替代等方面出发,根据 Zenlayer 自身的业务特点,结合快猫星云在统一监控和稳定性保障方向的最佳实践,构建起了 Zenlayer 新一代的统一监控方案,最终也实现了对 Zabbix 的完美替代,解除了困扰已久的难题。
Zenlayer如何将万台设备监控从Zabbix迁移到Flashcat的更多相关文章
- 【阿里聚安全·安全周刊】500万台Android设备受感染|YouTube封杀枪支组装视频
本周的七个关键词: 500万Android 设备受感染丨 黑客将矛头指向无线传输协议 丨 YouTube封杀枪支视频 丨 AMD将发布补丁 丨 Gooligan Android 僵尸网络 丨 N ...
- Qbot回归,已感染5.4万台计算机
Qbot回归,已感染5.4万台计算机 近日,BAESystems的安全人员发表了一篇关于Qbot网络感知蠕虫回归的调查报告,指出已经感染了5.4万台计算机. FreeBuf百科 Qbot蠕虫,也叫Qa ...
- Facebook 运维内幕曝光:一人管理2万台服务器
Facebook 运维内幕曝光:一人管理2万台服务器 oschina 发布于: 2013年11月23日 (29评) 分享到 新浪微博腾讯微博 收藏+32 11月30日 珠海 源创会,送U盘,先到先得 ...
- [转帖]“腾百万”之后,腾讯的云操作系统VStation单集群调度达10万台
“腾百万”之后,腾讯的云操作系统VStation单集群调度达10万台 https://www.leiphone.com/news/201909/4BsKCJtvvUCEb66c.html 腾讯有超过1 ...
- [转帖]黑客通过 Rootkit 恶意软件感染超 5 万台 MS-SQL 和 PHPMyAdmin 服务器
黑客通过 Rootkit 恶意软件感染超 5 万台 MS-SQL 和 PHPMyAdmin 服务器 https://www.cnbeta.com/articles/tech/852141.htm 病毒 ...
- 搭建jumperserver堡垒机管理万台服务器-2
搭建jumperserver堡垒机管理万台服务器-2 1 Jumpserver堡垒机概述-部署Jumpserver运行环境 2 安装Coco组件 3 安装Web-Terminal前端-Luna组 ...
- 搭建jumperserver堡垒机管理万台服务器-1
搭建jumperserver堡垒机管理万台服务器-1 1 Jumpserver堡垒机概述-部署Jumpserver运行环境 2 安装Coco组件 3 安装Web-Terminal前端-Luna组 ...
- vivo 万台规模 HDFS 集群升级 HDFS 3.x 实践
vivo 互联网大数据团队-Lv Jia Hadoop 3.x的第一个稳定版本在2017年底就已经发布了,有很多重大的改进. 在HDFS方面,支持了Erasure Coding.More than 2 ...
- 万台规模下的SDN控制器集群部署实践
目前在网络世界里,云计算.虚拟化.SDN.NFV这些话题都非常热.今天借这个机会我跟大家一起来一场SDN的深度之旅,从概念一直到实践一直到一些具体的技术. 本次分享分为三个主要部分: SDN & ...
- Forbidden Attack:7万台web服务器陷入被攻击的险境
一些受VISA HTTPS保护的站点,因为存在漏洞容易受到Forbidden攻击,有将近70,000台服务器处于危险之中. 一种被称为"Forbidden攻击"的新攻击技术揭露许多 ...
随机推荐
- 【ASPLOS 2022】机器学习访存密集计算编译优化框架AStitch,大幅提升任务执行效率
简介: 近日,关于机器学习访存密集计算编译优化框架的论文<AStitch: Enabling A New Multi-Dimensional Optimization Space for Mem ...
- Cloudera CDP 企业数据云测试开通指导
简介:基于阿里云部署的 Cloudera CDP 企业数据云平台已经进入公测阶段,本文详细介绍了相关试用/试用流程. 基于阿里云部署的 Cloudera CDP 企业数据云平台已经进入公测阶段,如对 ...
- 如何用 Nacos 构建服务网格生态
简介: Nacos 在阿里巴巴起源于 2008 年五彩石项目(该项目完成微服务拆分和业务中台建设),成长于十年的阿里双十一峰值考验,这一阶段主要帮助业务解决微服务的扩展性和高可用问题,解决了百万实例 ...
- IIncrementalGenerator 判断程序集之间可见关系
本文告诉大家如何在使用 IIncrementalGenerator 进行增量的 Source Generator 生成代码时,如何判断两个程序集之间是否存在 InternalsVisibleTo 关系 ...
- 支持 dotnet 6 的 dnSpy 神器版本
官方的 dnSpy 在 2021 时,由于某些吃瓜的原因 wtfsck 将 dnSpy 给 Archived 掉,在大佬被哄好之前,预计是不再更新.最新官方版本对 dotnet 6 的支持较弱,对于很 ...
- Java Spring项目中的CORS跨域开启的几种方式
引 在服务器端开启跨域的原理,一般都是通过在HTTP Headers中的响应头的Access-Control-Allow-Origin指定放行的域,来完成的. Access-Control-Allow ...
- K8s控制器(8)---Deployment
一.Deployment控制器概念.原理解读 1.1 Deployment概述 # Deployment官方文档 https://kubernetes.io/docs/concepts/workloa ...
- DOM操作学习
一.DOM对象-查找元素 # 1.直接查找 # 获取标签对象的方式: document.getElementById('#id') #根据ID获取一个标签(获取的是单独的对象) document.ge ...
- 第一章 Jenkins安装配置
Jenkins官网 # 官网: https://www.jenkins.iohttps://www.jenkins.io/zh/ # docker安装: https://www.jenkins.io/ ...
- QT MySQL连接自动断开
参考链接 MySQL链接10天后自动断开解决方案:<https://blog.csdn.net/xiaoxiao133/article/details/123006881 方式一 QT中可以通过 ...