火山引擎 DataTester:5 个优化思路,构建高性能 A/B 实验平台
导读:DataTester 是由火山引擎推出的 A/B 测试平台,覆盖推荐、广告、搜索、UI、产品功能等业务应用场景,提供从 A/B 实验设计、实验创建、指标计算、统计分析到最终评估上线等贯穿整个 A/B 实验生命周期的服务。DataTester 经过了字节跳动业务的多年打磨,在字节内部已累计完成 150 万次 A/B 实验,在外部也应用到了多个行业领域。
指标查询的产品高性能是 DataTester 的一大优势。作为产品最复杂的功能模块之一,DataTester 的指标查询能够在有限资源的前提下,发挥出最极致的 A/B 实验数据查询体验,而在这背后是多次的技术方案的打磨与迭代。
本文将分享 DataTester 在查询性能提升过程中的 5 个优化思路。
01
现状及问题
1. 挑战 1:版本管理
实验指标报告页是 DataTester 系统最核心的功能之一,报告页的使用体验直接决定了 DataTester 作为数据增长和实验评估引擎在业界的竞争力。该功能具有以下特点:
① 牵连系统多、链路长:报告页涉及到控制台(Console)、科学计算模块、查询引擎、OLAP 存储引擎。整个链路包括了:DSL 到 sql 转化、后端查询结果缓存处理、查询结果的加工计算、前端查询接口的组装和数据渲染。
② 实现复杂:实验指标有多种算子,在查询引擎侧中都有一套定制 SQL,通过 DSL 将算子转换成 SQL。这是 DataTester 中最复杂的功能模块之一。
02
优化思路
从一条 SQL 说起。
举一个例子,在 DataTester 中一次 AB 测试的查询分三部分逻辑。
① 实时扫描事件表,做过滤
② 根据用户首次进组时间过滤出用户
③ 做聚合运算
需要查询详细的 SQL 代码,也可以点击展开查看详情。
printf("hello world!");SELECT event_date,
count(DISTINCT uc1) AS uv,
sum(value) AS sum_value,
sum(pow(value, 2)) AS sum_value_square
FROM
(SELECT uc1,
event_date,
count(s) AS value
FROM
(SELECT hash_uid AS uc1,
TIME,
server_time,
event,
event_date,
TIME AS s
FROM rangers.tob_apps_all et
WHERE tea_app_id = 249532
AND ((event = 'purchase'))
AND (event_date >= '2021-05-10'
AND event_date <= '2021-05-19'
AND multiIf(server_time < 1609948800, server_time, TIME > 2000000000, toUInt32(TIME / 1000), TIME) >= 1620576000
AND multiIf(server_time < 1609948800, server_time, TIME > 2000000000, toUInt32(TIME / 1000), TIME) <= 1621439999)
AND (event in ('rangers_push_send',
'rangers_push_workflow')
OR ifNull(string_params{'$inactive'},'null')!='true') ) et GLOBAL ANY
INNER JOIN
(SELECT min(multiIf(server_time < 1609948800, server_time, TIME > 2000000000, toUInt32(TIME / 1000), TIME)) AS first_time,
hash_uid AS uc2
FROM rangers.tob_apps_all et
WHERE tea_app_id = 249532
AND arraySetCheck(ab_version, (29282))
AND event_date >= '2021-05-10'
AND event_date <= '2021-05-19'
AND multiIf(server_time < 1609948800, server_time, TIME > 2000000000, toUInt32(TIME / 1000), TIME) >= 1620651351
AND multiIf(server_time < 1609948800, server_time, TIME > 2000000000, toUInt32(TIME / 1000), TIME) <= 1621439999
AND (event in ('rangers_push_send',
'rangers_push_workflow')
OR ifNull(string_params{'$inactive'},'null')!='true')
GROUP BY uc2) tab ON et.uc1=tab.uc2
WHERE multiIf(server_time < 1609948800, server_time, TIME > 2000000000, toUInt32(TIME / 1000), TIME)>=first_time
AND first_time>0
GROUP BY uc1,
event_date)
GROUP BY event_date
DataTester 底层 OLAP 引擎采用的是 clickhouse,根据 clickhouse 引擎的特点,主要有两个优化方向:
① 减少 clickhouse 的 join,因为 clickhouse 最擅长的是单表查询和多维度分析,如果做一些轻量级聚合把结果做到单表上,性能可以极大提升。也就是把 join 提前到数据构建阶段,构建好的数据就是 join 好的数据。
② 需要 join 的场景,则通过减小右表大小来加速查询。因为 join 的时候会把右表拉到本地构建 hash 表,所以必然会占用大量内存,影响性能。
1. 重点优化方案

2. 方案一:预聚合,压缩查询事件量


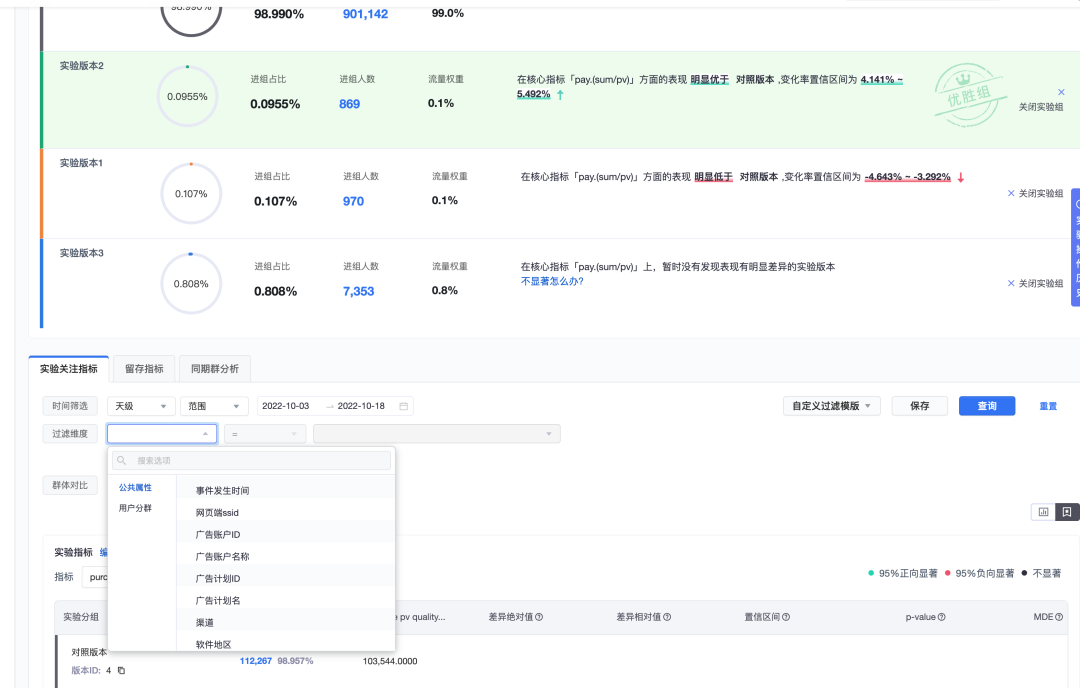
虽然指标很灵活,但是大多数场景用户进入报告页只会查看进组信息,实验结论,指标天级统计数据等,很少实时带条件去查询。因此,天级查询是我们主要使用场景。天级查询可以通过「预计算」加速。为了支持置信度的计算,「预计算」可以从人的粒度着手,即每天保存一条人的聚合后结果,记录下这个人在所有实验下进组之后各指标下的累积值。这样每天数据量与日活量相当,可以大大压缩总体查询量。
(1)方案详情
总体流程图:
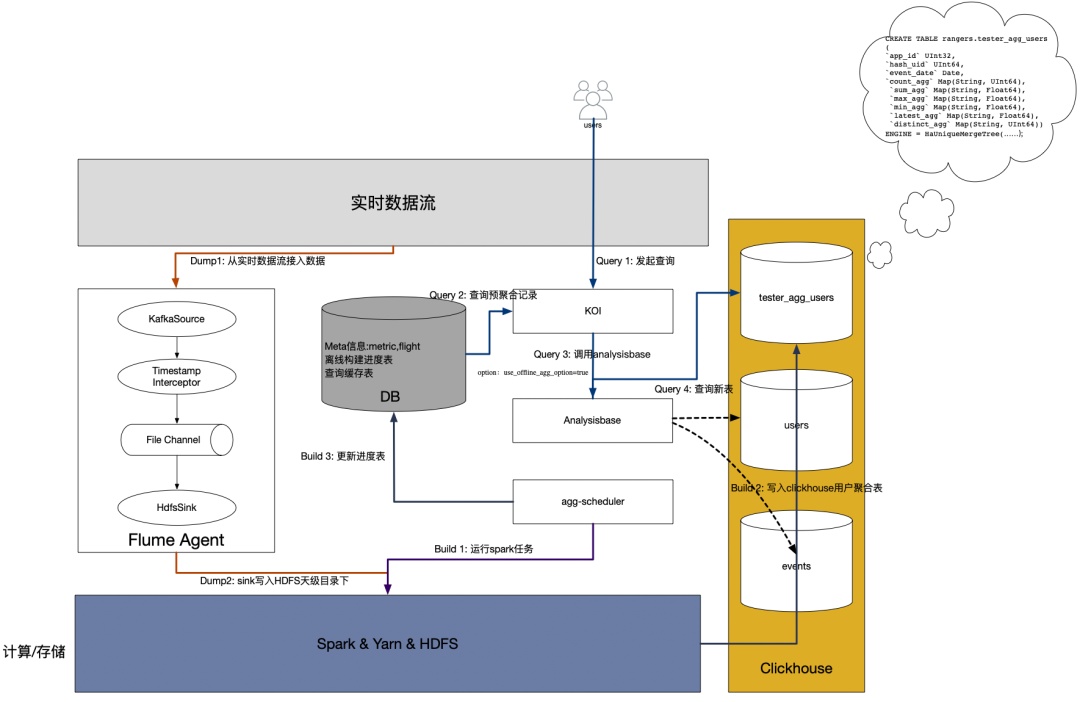
分为如下几个关键步骤:Dump、Parse、Build、Query
Dump
即把事件 dump 到离线存储中。私有化采用 flume 来实现:
a. 自定义 timestamp interceptor 防止数据漂移
b. 使用 file channel 文件缓冲保证数据不丢失
Parse
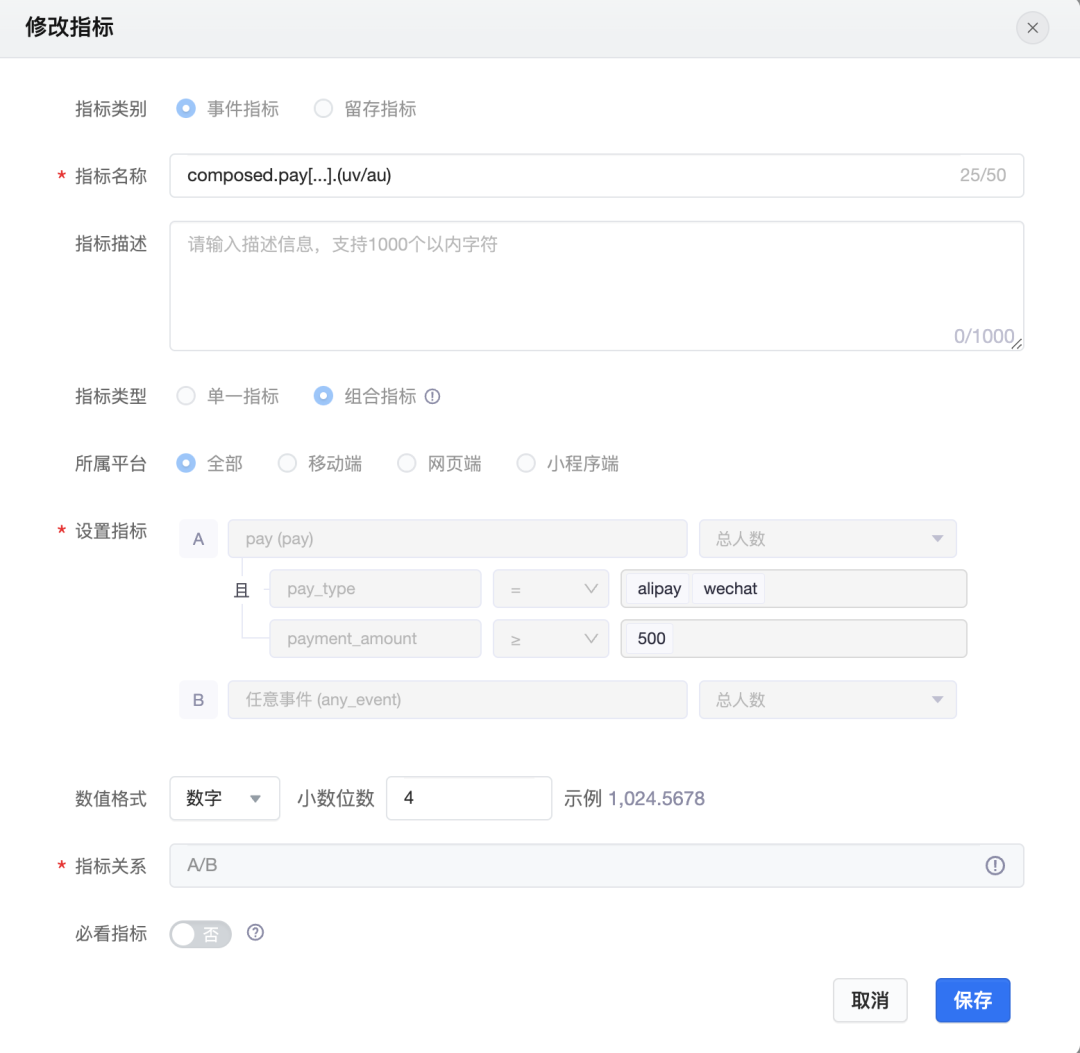
从指标 DSL 中解析出聚合字段、聚合类型,事件名、过滤条件指标四要素,再根据这些信息生成 md5 作为 clickhouse 存储的 key。考虑到不同指标配置可能会配置相同的聚合字段、聚合类型,事件名、过滤条件,生成 md5 的目的是保证唯一防止多次聚合。聚合类型包括 count,sum,max,min,latest,distinct(暂不支持),任何算子都可以用这几个基础聚合结果计算出来。如 avg 可以通过 sum/count 来计算。
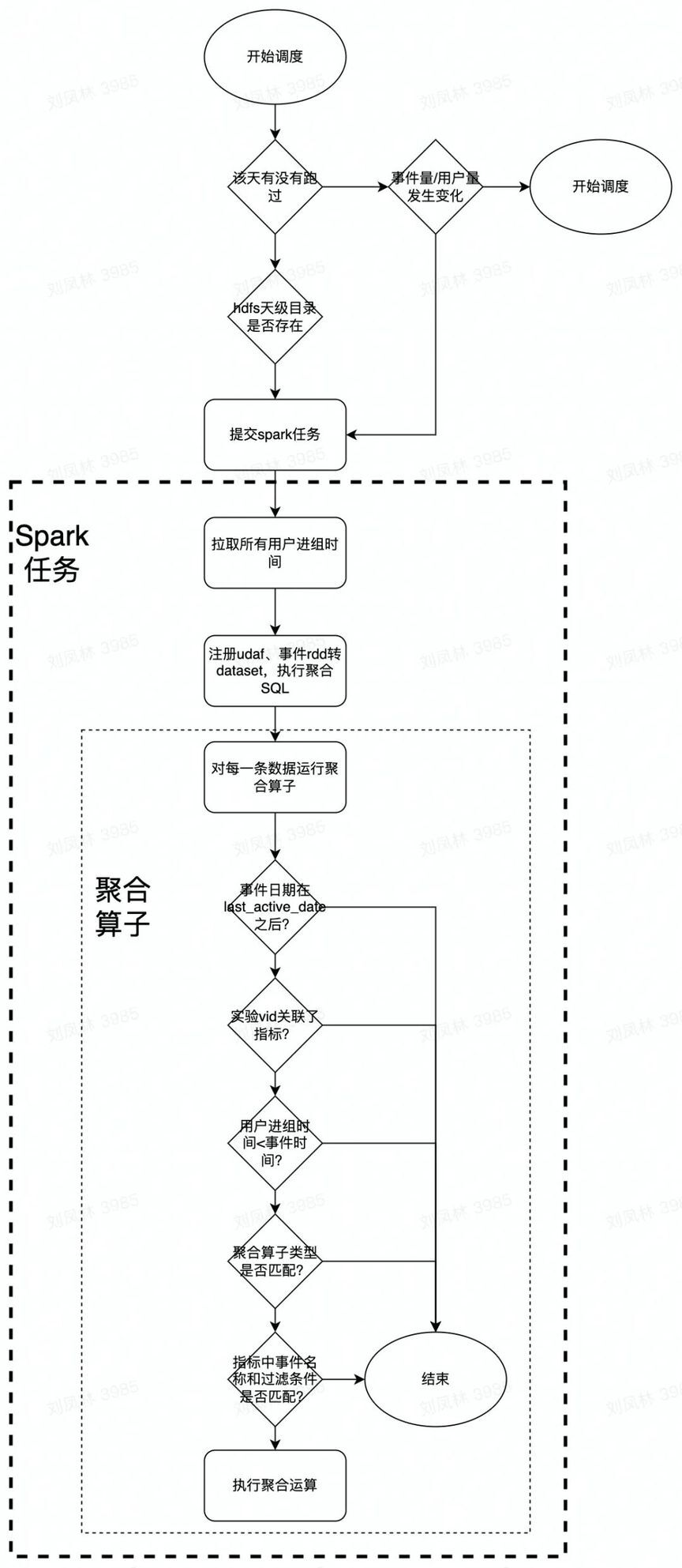
Build
离线构建最核心的部分在于自定义聚合函数(UDAF),自带的聚合函数无法满足我们的要求。
Query
即数据如何查询,通过对查询引擎增加参数控制是否走预聚合逻辑,同时针对预聚合定制了查询实现。
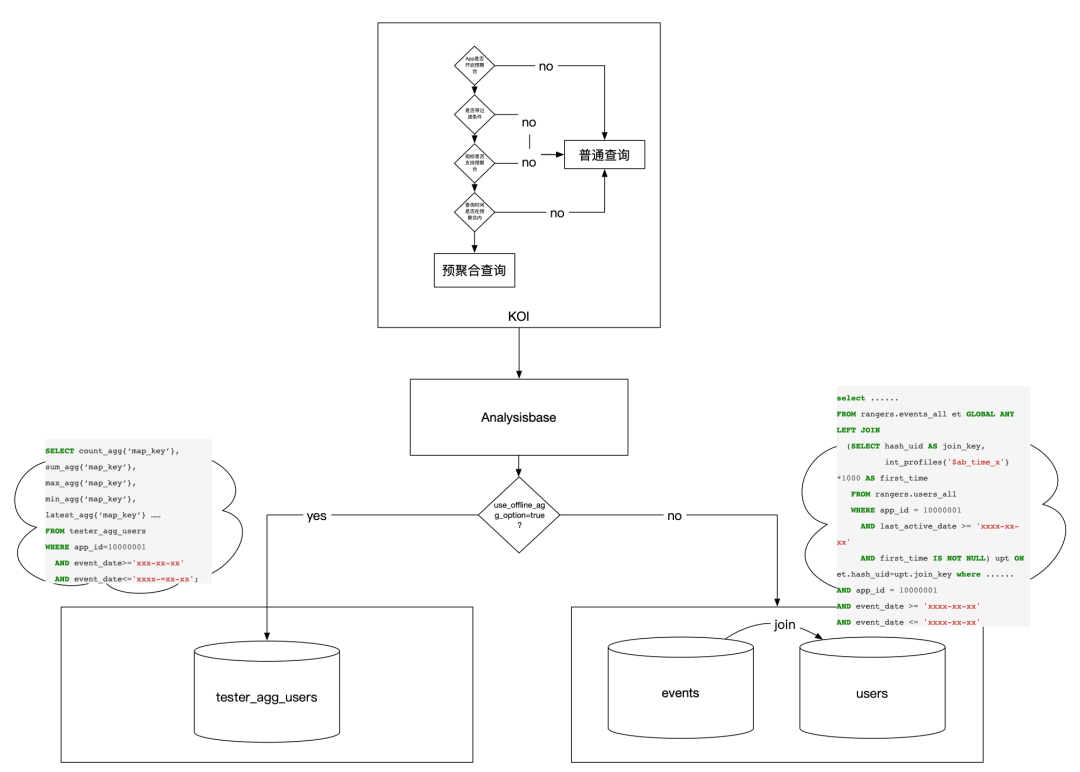
(2)资源使用限制
私有化场景用户机器资源是非常宝贵的,夜间也有很多定时任务在执行会争抢资源。为了保证不占用太多资源,提交任务时会对 spark 参数做控制。
以如下参数为基准,对 spark.dynamicAllocation.maxExecutors 进行控制:
driver-memory:4g
executor-memory:2g
executor-cores:2
配置梯度表:

(3)性能提升表现
4 亿事件量,100w 用户量,查询提升超过 4 倍。
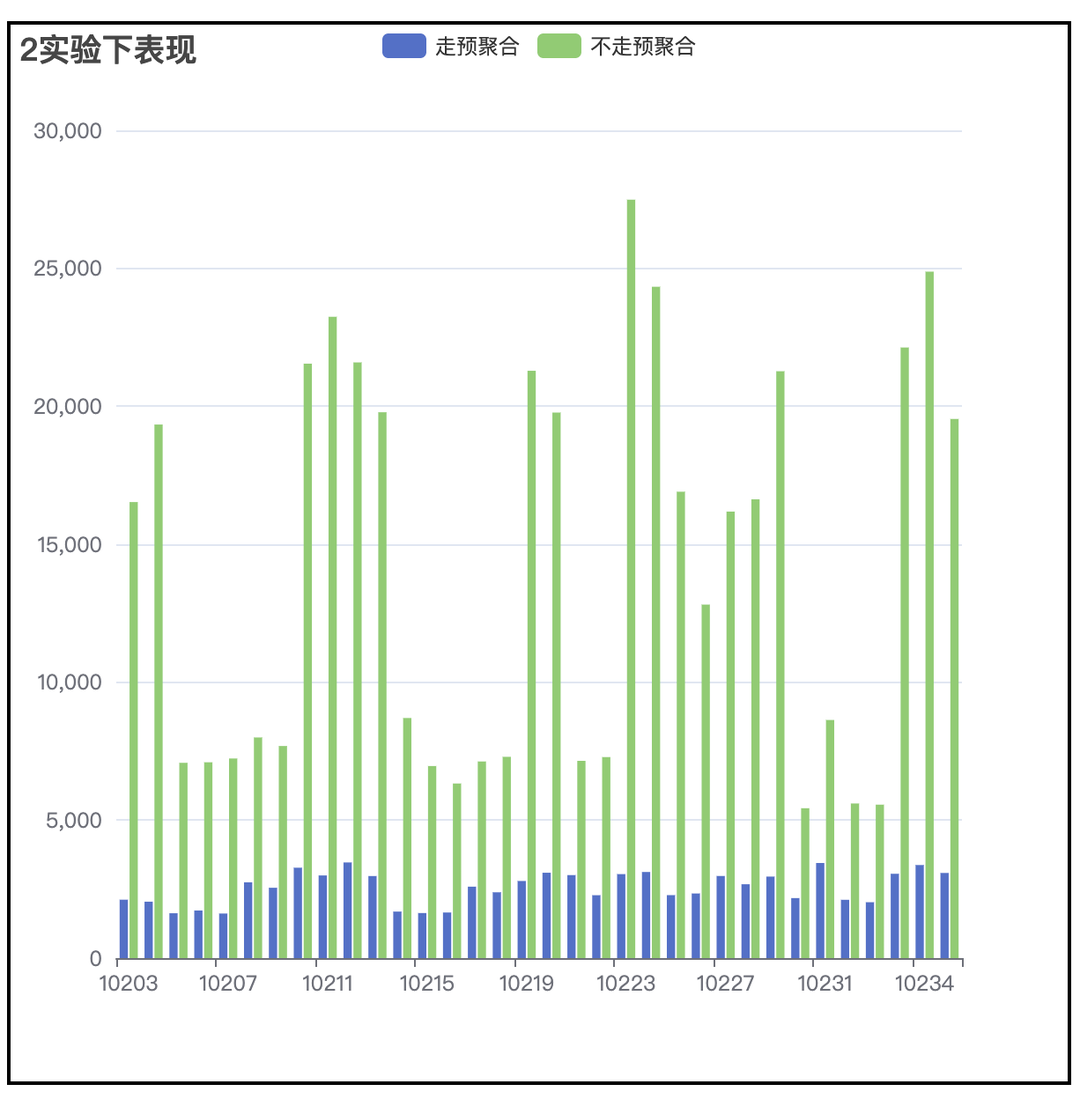
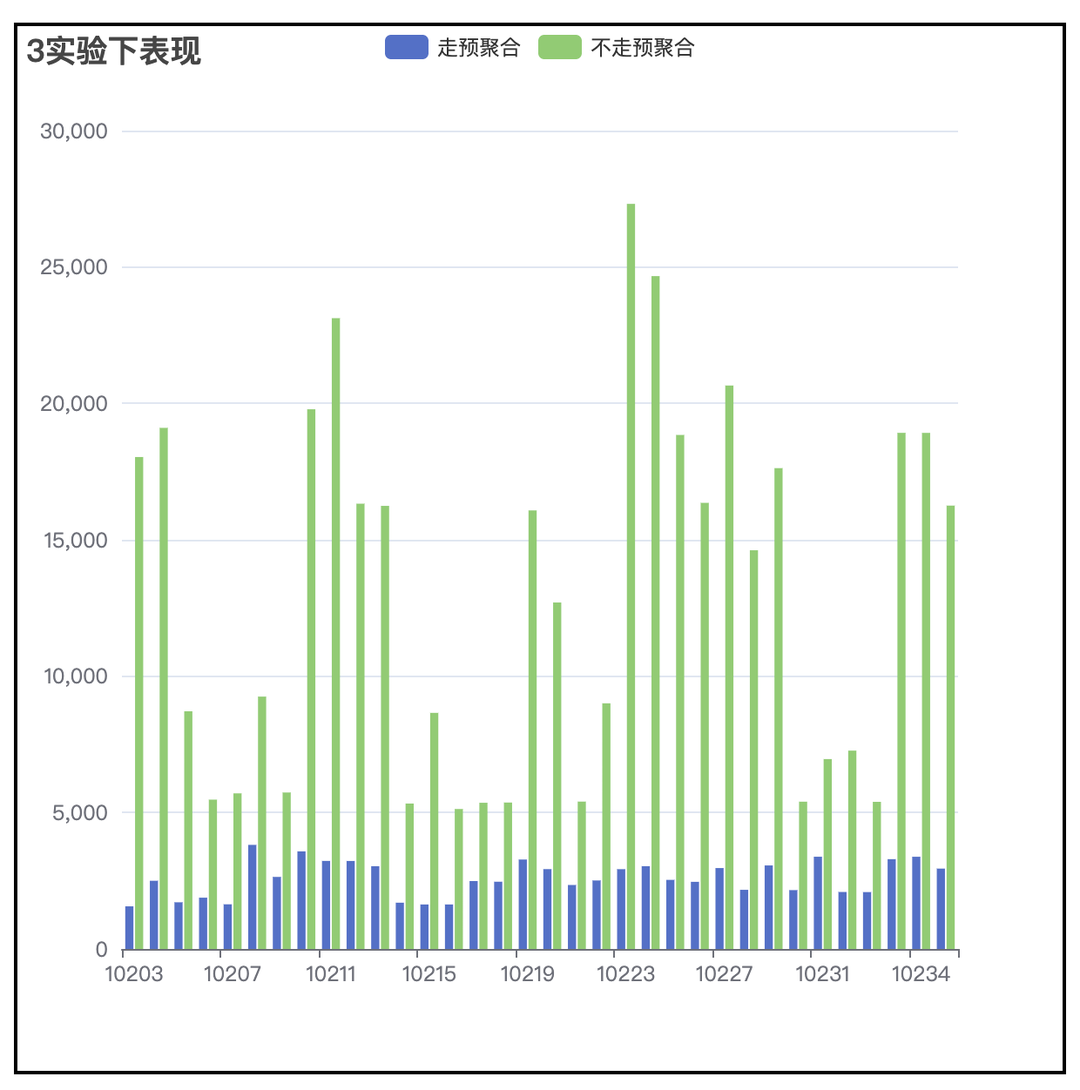
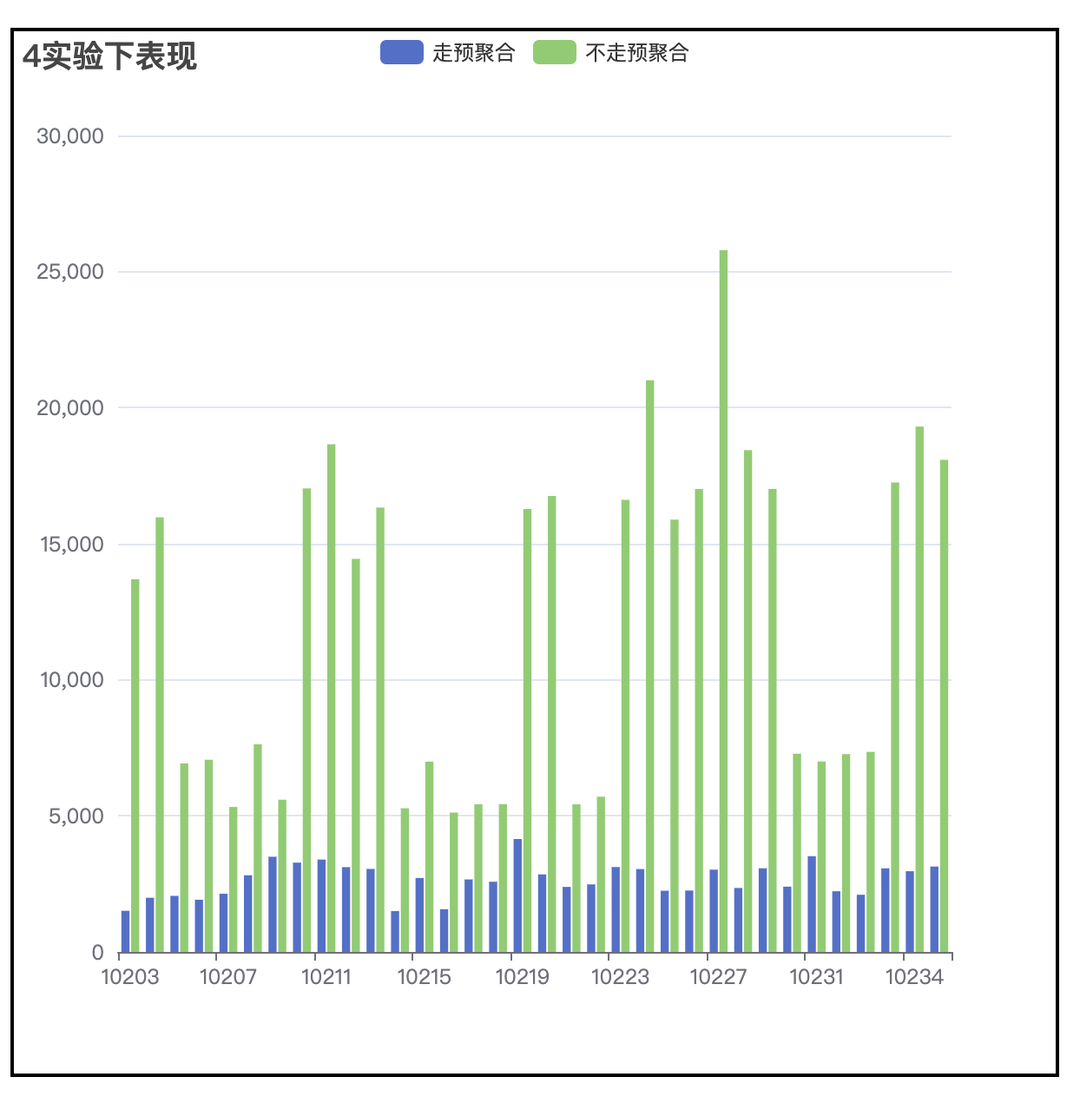
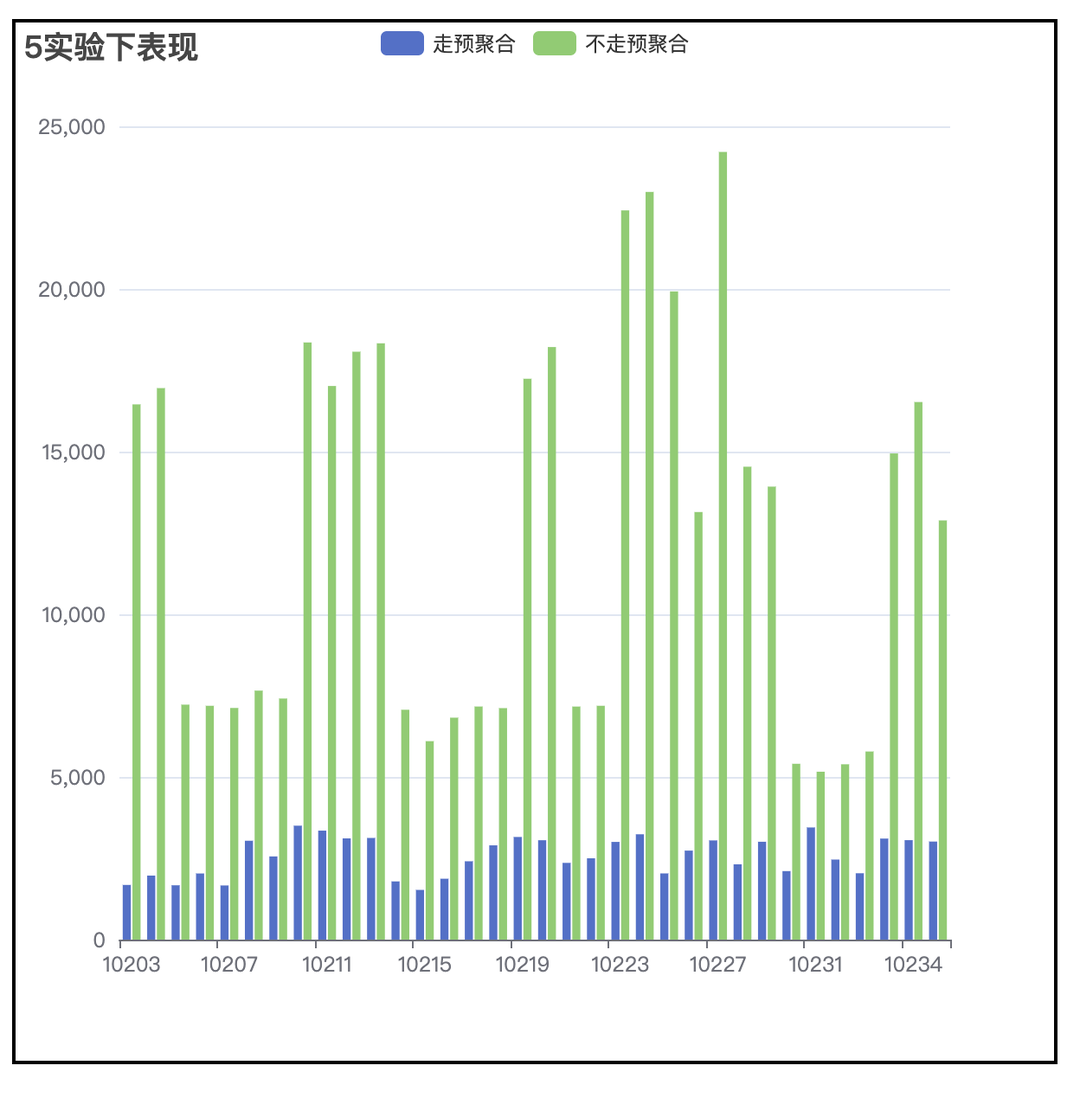
3. 方案二:ab_log,减小 join 时右表的大小
(1)背景

(2)方案概览
① 从实时流中过滤出曝光事件,把用户和进组时间写进实时 clickhouse 表。
② 从 clickhouse 实时表中构建出天粒度的离线用户进组信息表,每天每个用户仅有 1 条进组记录,记录了该用户该天最早的进组时间。
③ 查询的时候,为了获得用户首次进组时间,取 min(「实时表中该用户当天的进组时间」,「离线表实验开始到 T-1 天数据中该用户进组时间」)。
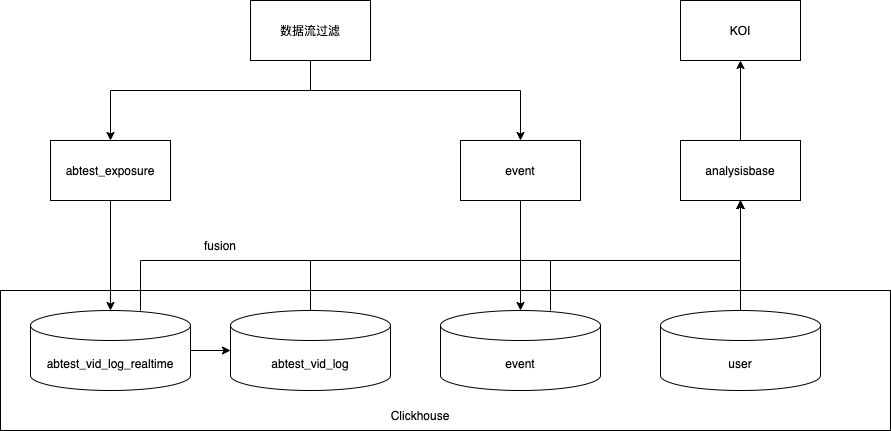
(3)提升效果
① 通过天级进组表大大加速服务端实验进组人群的圈选。
② 彻底解决私有化进组用户属性的隐患。
③ 在私有化环境可以一定程度上减少曝光事件量。在某些客户下,可减少 30%以上事件量。
4. 方案三:GroupBy 查询优化
(1)背景
DataTester 的数据查询和其他数据应用产品不同,DataTester 在数据查询时,所有的查询都会针对每一个实验版本都查一遍,而过程中中唯一的区别就在于实验版本 ID,所以和 SQL 中 GroupBy 的应用场景特别契合,通过 GroupBy 查询不仅可以极大的减少查询的数量,也可以降低多次查询造成的重复扫表,提高查询效率。
(2)优化方案
DataTester 对每个实验版本的查询语句都是类似的,只是版本 id 不同。对 DataTester 用到的所有查询类型和算子做 GroupBy 的改造,实现细节这里不做过多展开。
(3)提升效果
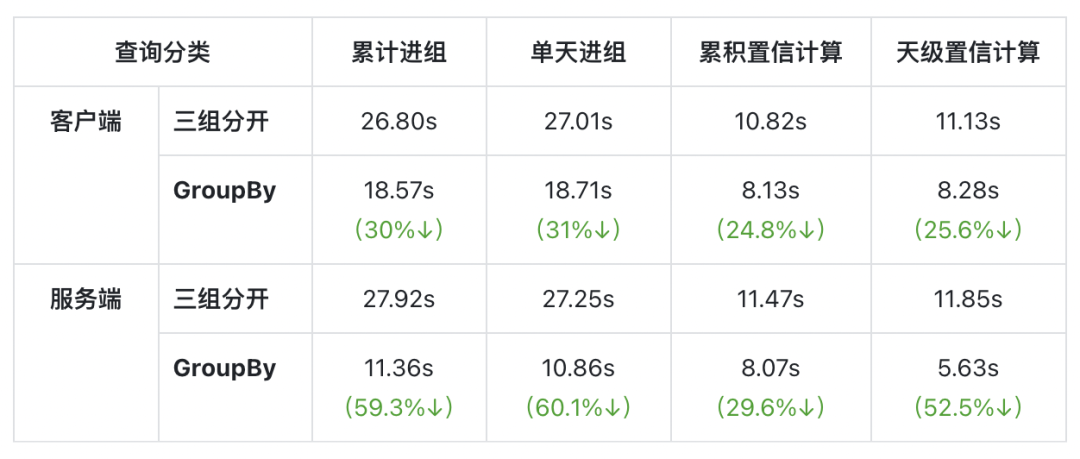
测试数据规模为日均一亿,7 天,3 个实验版本
查询引擎接口响应时长(取 10 次平均):
5. 方案四:au 类指标优化,减少重复查询次数
(1)背景
指标查询引擎对 DataTester 的 au 类型算子都做了定制,一个指标查询会产生两条 sql,一条正常指标的查询 sql,另一条是对 any_event 的 au 的查询,在最后结果处理的时候对两条 sql 的查询结果做了一个合并,一起返回到 DataTester 的科学计算模块。但是,每次打开报告页都必定会查进组人数,它和 any_event 的 au 是同一个值,au 类型算子查询的时候无法复用进组人数的结果,而 au 查询又可以算是最慢的查询之一,降低了报告页打开的速度。
对有进组指标的算子做了缓存优化,减少重复查询。
(2)优化方案
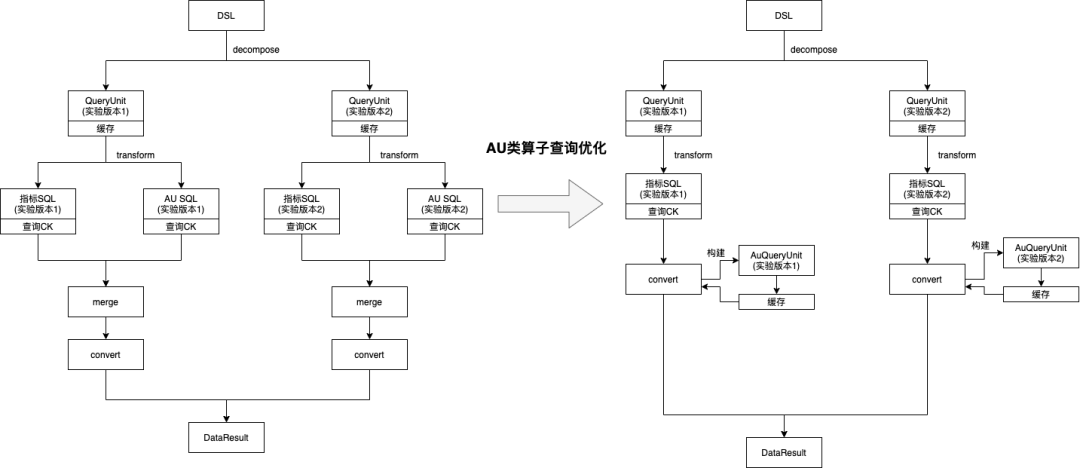
6. 方案五:异步查询优化,解决页面超时问题
(1)背景
DataTester 报告页等一些查询数据的接口本身确实比较耗时,需要实时计算,而大部分网关都有超时限制,这个问题在私有化中尤为明显,所以对报告页的整体交互做了优化改造。
(2)方案介绍
前后端交互
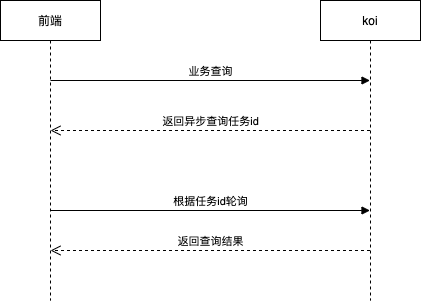
服务端架构设计
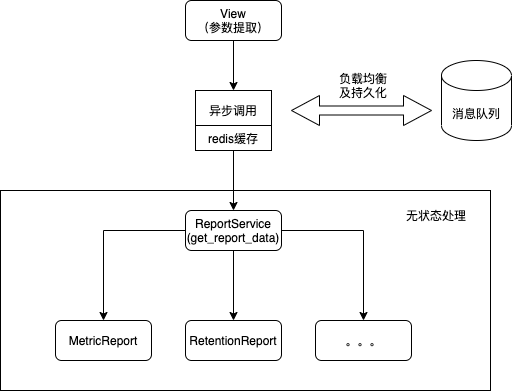
(3)用户体验改进效果
① 大幅缩短请求延时,避免出现页面请求失败的情况
② 通过增加 redis 缓存,同页面的多次刷新响应时间可以控制在 100ms 左右
7. 其他优化方案
① 业务逻辑优化,报告概览核心指标显著性和进组共用查询结果,去除实验版本按照核心指标显著性的排序,14 个 SQL 降至 10 个,降低 28.5%️
② 多维度并发控制,限制资源使用
③ 默认使用备查询,充分利用备节点的算力
④ 灵活开关多种报告的缓存,保证核心链路正常运行
03
总结
作为一站式 A/B 测试平台,火山引擎 DataTester 最核心的功能之一就是指标查询部分,它关系到产品体验和资源占用情况。而作为 TOB 领域的数据产品,DataTester 能在有限的资源下发挥最极致的产品数据体验,也是产品最为重要的竞争力之一。
本次分享了 DataTester 在报告页查询优化过程中的 5 个技术方案落地。预聚合和 ablog 是从数据构建角度减少查询数据量的角度的优化,groupby 和 au 类指标的优化是从减少并发的角度,异步查询是从产品体验角度。
查询和数据构建密不可分,DataTester 未来的产品优化也会按照“去肥”和“增瘦”两个方向进行,“去肥”是优化科学计算模块和查询引擎的整体架构,优化业务逻辑,使得报告页查询逻辑更加清晰和简洁;另一方面“增瘦”就是通过合理的数据构建和数据模型优化加速查询,同时定向对部分难点问题重点优化,比如留存、盒须快照、同期群等等。
点击跳转火山引擎A/B测试DataTester官网了解详情!
扫码进入「字节跳动数据平台」官方交流群,领取更多 A/B 测试学习资料。

火山引擎 DataTester:5 个优化思路,构建高性能 A/B 实验平台的更多相关文章
- 火山引擎 DataTester:让企业“无代码”也能用起来的 A/B 实验平台
更多技术交流.求职机会,欢迎关注字节跳动数据平台微信公众号,回复[1]进入官方交流群 当数字化变革方兴未艾,无代码正受到前所未有的关注.Salesforce 的数据显示,52%的 IT 部门表示,公司 ...
- 还原火山引擎 A/B 测试产品——DataTester 私有化部署实践经验
作为一款面向ToB市场的产品--火山引擎A/B测试(DataTester)为了满足客户对数据安全.合规问题等需求,探索私有化部署是产品无法绕开的一条路. 在面向ToB客户私有化的实际落地中,火 ...
- 【原创】构建高性能ASP.NET站点 第六章—性能瓶颈诊断与初步调优(下前篇)—简单的优化措施
原文:[原创]构建高性能ASP.NET站点 第六章-性能瓶颈诊断与初步调优(下前篇)-简单的优化措施 构建高性能ASP.NET站点 第六章—性能瓶颈诊断与初步调优(下前篇)—简单的优化措施 前言:本篇 ...
- 火山引擎 A/B 测试产品——DataTester 私有化架构分享
作为一款面向 ToB 市场的产品--火山引擎A/B测试(DataTester)为了满足客户对数据安全.合规问题等需求,探索私有化部署是产品无法绕开的一条路. 在面向 ToB 客户私有化的实际落地中,火 ...
- 火山引擎DataLeap数据调度实例的 DAG 优化方案
更多技术交流.求职机会,欢迎关注字节跳动数据平台微信公众号,并进入官方交流群 实例 DAG 介绍 DataLeap 是火山引擎自研的一站式大数据中台解决方案,集数据集成.开发.运维.治理.资产管理能力 ...
- 火山引擎 DataLeap:3 个关键步骤,复制字节跳动一站式数据治理经验
更多技术交流.求职机会,欢迎关注字节跳动数据平台微信公众号,并进入官方交流群 DataLeap 是火山引擎数智平台 VeDI 旗下的大数据研发治理套件产品,帮助用户快速完成数据集成.开发.运维.治理. ...
- 火山引擎MARS-APM Plus x 飞书 |降低线上OOM,提高App性能稳定性
通过使用火山引擎MARS-APM Plus的memory graph功能,飞书研发团队有效分析定位问题线上case多达30例,线上OOM率降低到了0.8‰,降幅达到60%.大幅提升了用户体验,为飞书的 ...
- 火山引擎 DataLeap 的 Data Catalog 系统公有云实践
Data Catalog 通过汇总技术和业务元数据,解决大数据生产者组织梳理数据.数据消费者找数和理解数的业务场景.本篇内容源自于火山引擎大数据研发治理套件 DataLeap 中的 Data Ca ...
- JuiceFS 在火山引擎边缘计算的应用实践
火山引擎边缘云是以云计算基础技术和边缘异构算力结合网络为基础,构建在边缘大规模基础设施之上的云计算服务,形成以边缘位置的计算.网络.存储.安全.智能为核心能力的新一代分布式云计算解决方案. 01- 边 ...
- 火山引擎 DataLeap:一家企业,数据体系要怎么搭建?
更多技术交流.求职机会,欢迎关注字节跳动数据平台微信公众号,回复[1]进入官方交流群 导读:经过十多年的发展,数据治理在传统行业以及新兴互联网公司都已经产生落地实践.字节跳动也在探索一种分布式的数据治 ...
随机推荐
- 生产真实案例:震惊,几条SQL把服务器干崩了,事后还大言不惭!
大家好,我是冰河~~ 今天跟大家分享一个发生在今天凌晨的真实案例,这篇文章也是我事后临时写出来的,处理事情的过程有点无语,又有点气愤! 事件背景 事情的背景是这样的:一个朋友今年年初新开了一家公司,自 ...
- 深度解析NLP文本摘要技术:定义、应用与PyTorch实战
在本文中,我们深入探讨了自然语言处理中的文本摘要技术,从其定义.发展历程,到其主要任务和各种类型的技术方法.文章详细解析了抽取式.生成式摘要,并为每种方法提供了PyTorch实现代码.最后,文章总结了 ...
- 打造我的 Windows 开发环境
@charset "UTF-8"; .markdown-body { line-height: 1.75; font-weight: 400; font-size: 15px; o ...
- hci0 command 0xfc20 tx timeout(Realtek 8761B Chipset, Bluetooth 5.0)
当前使用的Linux内核版本: 4.4.189 插上USB Bluetooth 5.0 Adapter后,dmesg显示如下log: [ 240.348480] usb 3-1.2: new full ...
- Hadoop学习(一) 搭建伪分布式集群
文章结构 1.准备工作 1.1 配置IP 1.2 关闭防火墙 1.3 修改主机名并与IP绑定 1.4 创建新用户 1.5 配置免密匙 2.安装并配置Hadoop伪分布式集群 2.1 安装Java 2. ...
- [ABP] PostgreSQL在.NET 6.0使用DateTime类型抛出异常:timestamp with time zone
今晚操起久违的 ABP 框架搭了个新项目: .NET 运行时版本:6.0.3 ABP 版本:v5.2.0-rc.2 版本. 数据库:PostgreSQL v10.x 一顿操作猛如虎,直接用 dotne ...
- 🔥🔥Java开发者的Python快速进修指南:面向对象基础
当我深入学习了面向对象编程之后,我首先感受到的是代码编写的自由度大幅提升.不同于Java中严格的结构和约束,Python在面向对象的实现中展现出更加灵活和自由的特性.它使用了一些独特的关键字,如sel ...
- 期望最大化(EM)算法:从理论到实战全解析
本文深入探讨了期望最大化(EM)算法的原理.数学基础和应用.通过详尽的定义和具体例子,文章阐释了EM算法在高斯混合模型(GMM)中的应用,并通过Python和PyTorch代码实现进行了实战演示. 关 ...
- 小心C#中的只读结构体成员
示例 我们先来看一段结构体的代码 (基于 VS2022 + .NET 8.0) public struct MyStruct(int number) { public int Number = num ...
- 叮咚,你的微信年度聊天报告请查收「GitHub 热点速览」
本周热点项目 WeChatMsg 是一个微信记录提取工具,据说它还能帮你分析聊天记录.生成你的年度聊天报告.而又到了年底,部分不幸的小伙伴要开始写年度总结了,这时候 self-operating-co ...